













许多公司选择转向AWS MSK,以避免管理Apache Kafka集群所带来的运营头痛。
在本教程中,我们将探讨AWS MSK的特性、优势和最佳实践。我们还将介绍设置AWS MSK的基本步骤,并看看它与其他流行服务(如Kinesis和Confluent)的比较。
什么是AWS MSK?
首先,让我们了解Apache Kafka以及为什么它对于数据流如此有用。
Apache Kafka是一个开源的分布式流处理平台,处理实时数据流并能构建事件驱动的应用程序。它可以在数据流发生时摄取和处理流数据。
根据<Kafka官网,超过80%的财富100强公司信任并使用Kafka。
最重要的是,Kafka 可扩展且非常快速。这意味着它可以处理比单台机器所能容纳的数据多得多,并且延迟极低。
如果您想学习如何为数据流创建、管理和排除故障 Kafka,请考虑参加 Kafka 入门 课程。
使用 Apache Kafka 的最佳时机是什么?
- 当您需要实时处理大量数据时,例如处理物联网设备数据流。
- 当您需要即时数据处理和分析时,例如实时用户活动跟踪或欺诈检测系统。
- 在事件溯源场景中,您需要满足合规要求和法规的审计追踪。
然而,管理 Kafka 实例可能会带来很多麻烦。这就是 AWS MSK 的用武之地。
![]()
作者提供的图片
AWS MSK(托管流媒体服务)是一项完全托管的服务,处理Kafka集群的配置、扩展和维护。您可以使用它构建能够即时响应数据流的应用程序。
Kafka通常作为更大数据处理设置的一部分,而AWS MSK使创建在不同系统之间移动数据的实时数据管道变得更加容易。
Amazon MSK的工作原理。图片来源:AWS
如果您是AWS新手,可以考虑参加我们的AWS入门课程,以熟悉基础知识。当您准备好后,可以继续参加我们的AWS云技术与服务课程,探索企业所依赖的完整服务套件。
AWS MSK的特点
AWS MSK因其完全托管的服务而在竞争中脱颖而出。您无需担心设置服务器或处理更新。
然而,这并不仅仅是这些。AWS MSK的五个关键特点使其成为值得投资的选择:
- MSK具有高可用性,AWS保证严格遵守服务水平协议(SLA)。它会在不影响应用程序的情况下自动替换故障组件。
- MSK 提供了自动扩展存储的选项,因此它可以根据您的需求自动增长。您还可以根据需要快速扩大或缩小存储或添加更多代理。
- 在安全性方面,MSK 是一个全面的解决方案,提供静态和传输中的加密。它还与 AWS IAM 集成以进行访问控制。
- 如果您已经在使用 Kafka,您可以无缝迁移到 MSK,而无需更改代码,因为 MSK 支持所有常规的 Kafka API 和工具。
- MSK 是一个具有成本效益的选项,无需雇佣整个工程团队来监控和管理集群。AWS 甚至声称它可以比自管理的 Kafka 便宜多达 40%。
使用 AWS MSK 的好处
正如我们已经看到的,由于其可用性、可扩展性、安全性和易集成性,AWS MSK提供了即时价值。这些核心优势使其成为在云中运行Kafka工作负载的首选。
AWS MSK解决了每个数据流项目面临的四个关键挑战:
- MSK是一个完全托管的服务,让您可以专注于构建应用程序,而不是管理基础设施。
- MSK具有高可用性和可靠性,这在当今变得越来越关键,因为用户期望全天候访问服务和应用程序。
- MSK具有关键的全面安全功能。
- MSK具有原生的AWS集成,使得在AWS生态系统内构建完整的流数据解决方案变得更加容易。
设置AWS MSK
要开始使用AWS MSK,首先需要创建您的AWS账户。如果这是您第一次使用AWS,可以通过我们全面的教程了解如何设置和配置您的AWS账户。
登录到AWS管理控制台并打开MSK控制台。点击“创建集群”开始设置过程。

开始使用AWS MSK。图片来源自:AWS
选择“快速创建”以使用默认设置,然后输入描述性的集群名称。
从那里,您有许多额外的选择,这些选择都取决于您对集群的具体要求。以下是选择的快速概述:
- 集群类型:“预配置”或“无服务器”
- Apache Kafka 版本
- 代理类型:“标准”或“快速”
- 代理大小
- EBS 存储卷
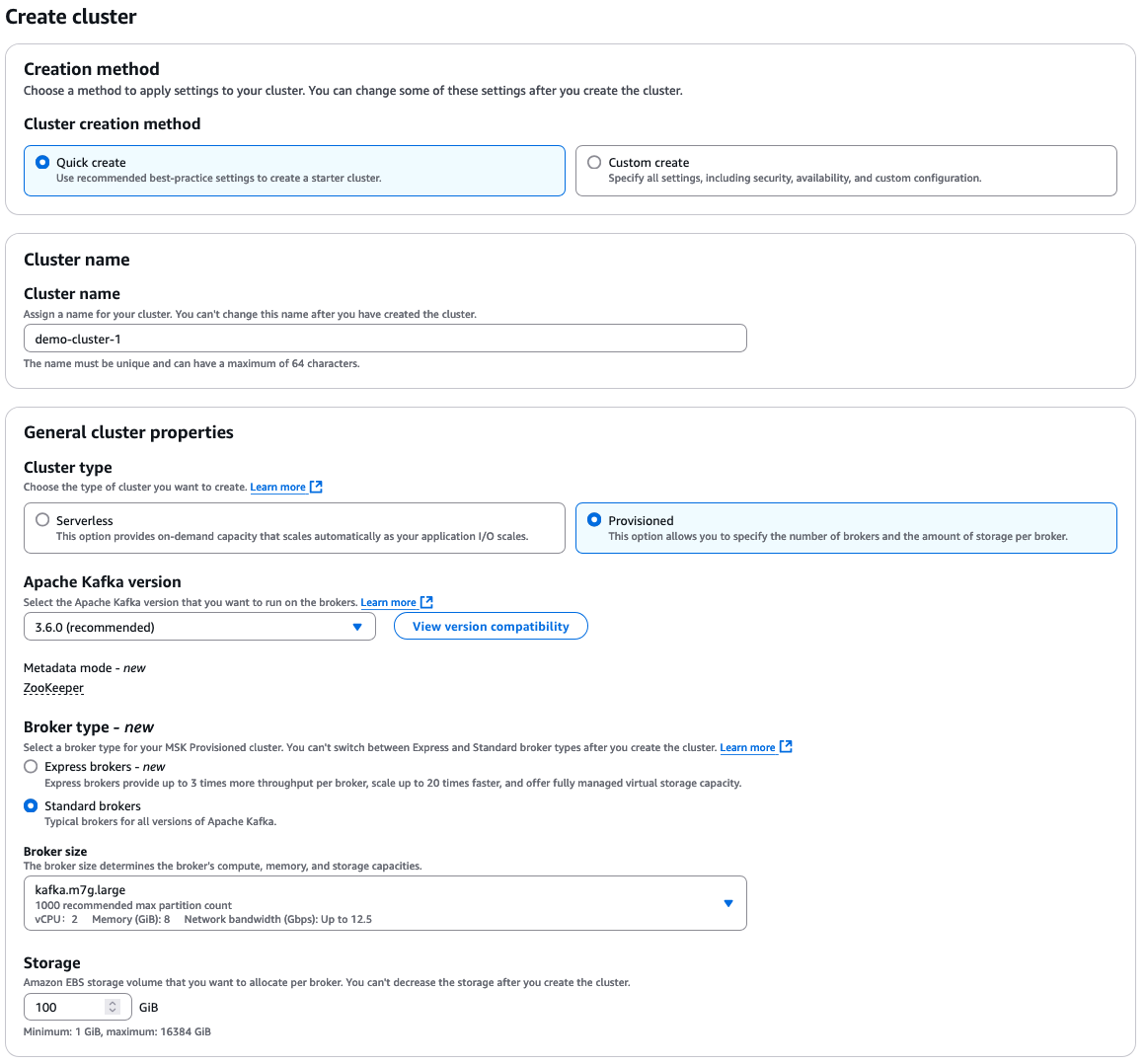
AWS MSK 配置选项
集群始终在 Amazon VPC 内创建。您可以选择使用默认 VPC 或配置并指定自定义 VPC。
现在,您只需等待集群激活,这可能需要 15 到 30 分钟。您可以从集群摘要页面监控集群的状态,您将看到状态从“创建中”变为“活动”。
使用 AWS MSK 进行数据摄取和处理
一旦您的 MSK 集群设置完成,您需要创建一个客户端机器,以便在一个或多个主题上生成和消费数据。由于 Apache Kafka 与许多数据生产者(例如网站、物联网设备、Amazon EC2 实例等)集成良好,因此 MSK 也享有这一优势。
Apache Kafka将数据组织成称为主题的结构。每个主题由一个或多个分区组成。分区是Apache Kafka中的并行度。数据通过数据分区在经纪人之间分布。
处理Apache Kafka集群时需要了解的关键术语:
- 主题是在Kafka中组织数据的基本方式。
- 生产者是将数据发布到主题的应用程序——它们生成并将数据写入Kafka。它们在特定主题和分区上写入数据。
- 消费者是从主题中读取和处理数据的应用程序。它们从它们订阅的主题中拉取数据。
在使用AWS MSK构建事件驱动架构时,您需要配置多个层,其中MSK是主要的数据摄取组件。以下是可能需要的层的概述:
- 数据摄取设置
- 处理层
- 存储层
- 分析层
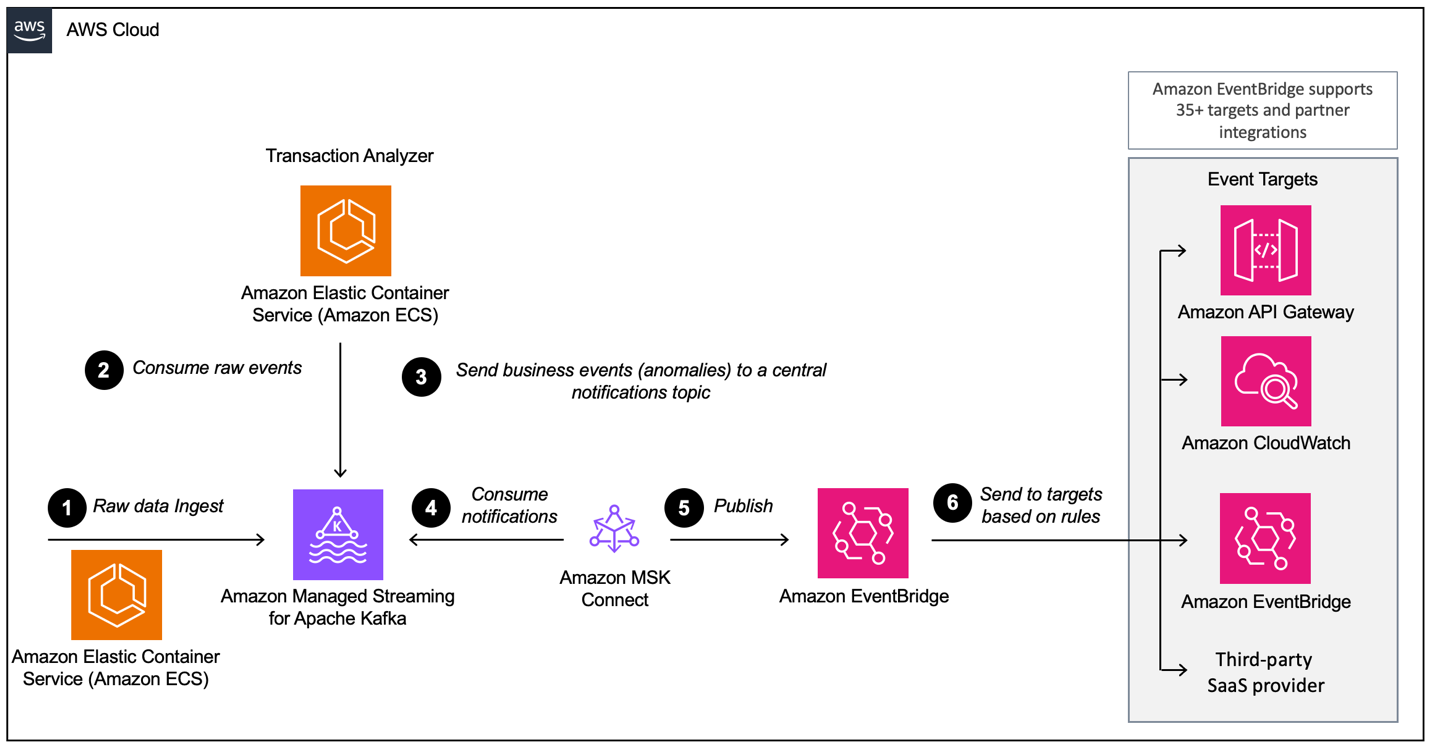
使用Amazon MSK和Amazon EventBridge的事件驱动架构示例。 图片来源:AWS
如果您有兴趣在数据管道工作流中使用Python,请查看我们的AWS Boto在Python中的介绍课程。
使用AWS MSK的最佳实践
AWS MSK相对简单,您可以立即设置并开始使用。然而,一些基本的最佳实践将提高您集群的性能,并为您节省后续的时间。
合理配置集群大小
您需要选择每个代理的合适分区数量和每个集群的合适代理数量。
有多个因素可能会影响您在此的决策;然而,AWS 提供了一些便捷的 建议和资源 来指导您完成此过程。
此外,AWS 提供了一个易于使用的 大小和定价电子表格,帮助您估算集群的合适大小以及使用 AWS MSK 与类似的自管理 EC2 Kafka 集群的相关成本。
构建高可用集群
AWS 建议您将集群设置为高可用。这在进行更新(例如更新 Apache Kafka 版本)或 AWS 替换代理时尤其重要。
为了确保您的集群高可用,您必须做三件事情:
- 在三个可用区部署您的集群(也称为三AZ集群)。
- 将复制因子设置为3或更多。
- 将最小的同步副本数量设置为RF-1。
使用AWS的一个很大的优点是它们对多AZ部署承诺严格的SLA;否则,您将获得积分返还。
监控磁盘和CPU使用情况
通过AWS CloudWatch监控的两个关键指标是磁盘和CPU使用率。这样做不仅可以确保系统运行顺利,还有助于降低成本。
管理磁盘使用情况及相关存储成本的最佳方法是设置一个 CloudWatch 警报,当磁盘使用率超过某个数值(例如 85%)时会通知您,并调整保留策略。为日志中的消息设置保留时间可以帮助自动释放磁盘空间。
此外,为了维护集群的性能并避免瓶颈,AWS 建议保持经纪人的总 CPU 使用率在 60% 以下。您可以使用 AWS CloudWatch 进行监控,然后通过更新经纪人大小等方式进行纠正。
使用传输加密保护您的数据
默认情况下,AWS 在 MSK 集群中的经纪人之间加密传输数据。如果系统出现高 CPU 使用率或延迟,您可以禁用此功能。然而,强烈建议您始终保持传输加密功能开启,并寻找其他改善性能的方法,如果这对您来说是个问题。
查看我们的 AWS 安全和成本管理 课程,了解如何保护和优化您的 AWS 云环境,并在 AWS 中管理成本和资源。
将 AWS MSK 与其他流处理工具进行比较
在决定项目中最适合的工具时,我们经常需要评估几个选项。以下是与AWS MSK最常见的替代方案以及它们的比较。
AWS MSK与在EC2上使用Apache Kafka的比较
MSK和在EC2上自行托管选项之间的主要权衡是便利性和控制力之间的权衡:MSK让您需要管理的东西更少,但灵活性更差,而EC2让您完全控制,但需要更多工作。
AWS MSK处理所有复杂的运维任务,具有自动提供和配置。其中的好处是没有前期基础设施成本。还可以与其他AWS服务无缝集成,并具有强大的安全功能。
在EC2上使用Kafka需要更多手动设置和配置,您还需要自行处理所有维护和更新工作。这提供了更大的灵活性,但可能伴随着更多的复杂性和运维成本,并且可能需要更高技能水平的团队。
AWS MSK与Kinesis比较
使用Kinesis可以获得简单性和深度的AWS集成,使用MSK可以获得Kafka兼容性或更多对流处理设置的控制。
Kinesis是一个完全无服务器架构,使用分片进行数据流处理。AWS为您管理一切。但是,需要注意数据保留限制。Kinesis是简单数据流处理需求的绝佳解决方案。
AWS MSK依赖于Kafka的主题和分区模型,具有几乎无限的数据保留期,取决于您的存储。这是一个更灵活、可定制的解决方案,如果需要,您可以迁移离开AWS。
如果您不熟悉 Kinesis,我们有一个课程可以指导您使用 AWS Kinesis 和 Lambda 处理流数据。
AWS MSK 与 Confluent
如果您需要全面的功能和支持,请选择 Confluent;如果您深度投资于 AWS 并且拥有 Kafka 专业知识,请选择 MSK。
Confluent 具有丰富的功能集和许多内置连接器。总体而言,它是一个更昂贵的选择,但确实提供了具有有限功能的免费层。Confluent 非常适合波动的工作负载,并且部署过程更简单。
相比之下,AWS 更加简化,专注于核心 Kafka 功能。要访问更广泛的功能集,AWS MSK 必须与其他 AWS 服务集成。幸运的是,这种集成是无缝的。AWS MSK 的基础成本较低,对于稳定的工作负载来说是一个不错的选择。
以下表格提供了 AWS MSK 及其替代方案的比较:
|
功能 |
AWS MSK |
Apache Kafka on EC2 |
Kinesis |
Confluent |
|
部署 |
完全托管 |
自助托管在EC2上 |
完全托管 |
完全托管或自助托管 |
|
易用性 |
易于设置和管理 |
需要手动设置和扩展 |
简单设置;AWS原生 |
用户友好的UI和高级工具 |
|
可扩展性 |
具有手动调整的自动扩展 |
手动扩展 |
无缝扩展 |
灵活的自动扩展 |
|
延迟 |
低延迟 |
低延迟 |
小负载的更低延迟 |
与MSK可比 |
|
协议支持 |
与Kafka API兼容 |
与Kafka API兼容 |
专有Kinesis协议 |
Kafka API及其他协议 |
|
数据保留 |
可配置(默认最多7天) |
可配置 |
可配置(最多365天) |
高度可配置 |
|
监控和指标 |
与CloudWatch集成 |
需要自定义设置 |
与CloudWatch集成 |
高级监控工具 |
|
成本 |
按使用量付费 |
基于EC2实例定价 |
按使用量付费 |
基于订阅的 |
|
安全性 |
内置的AWS安全功能 |
必须手动配置安全性 |
集成了AWS IAM |
全面的安全功能 |
|
使用情况适宜性 |
最适合AWS生态系统中的Kafka用户 |
灵活,但维护成本高 |
最适合AWS原生应用程序 |
高级Kafka用户和企业 |
总结思考
Apache Kafka 是在需要大规模、可靠解决方案且不能承受数据丢失的情况下的首选,同时需要连接多个数据源或构建复杂数据流水线。AWS MSK 可以避免许多设置和配置 Kafka 集群时的麻烦,让开发人员能够更专注于构建和改进应用程序,而不是基础架构。
获得一个 AWS 认证 是开始 AWS 职业生涯的绝佳途径。您可以通过查看我们的 课程目录 来提升 AWS 技能,并通过项目获得 实践经验!