













Viele Unternehmen entscheiden sich dafür, zu AWS MSK zu wechseln, um die betrieblichen Probleme zu vermeiden, die mit der Verwaltung von Apache Kafka-Clustern verbunden sind.
In diesem Tutorial werden wir die Funktionen, Vorteile und Best Practices von AWS MSK erkunden. Außerdem werden wir die grundlegenden Schritte zur Einrichtung von AWS MSK durchgehen und sehen, wie es im Vergleich zu anderen beliebten Diensten wie Kinesis und Confluent abschneidet.
Was ist AWS MSK?
Zunächst wollen wir Apache Kafka verstehen und warum es so nützlich für das Streaming von Daten ist.
Apache Kafka ist eine quelloffene verteilte Streaming-Plattform, die Echtzeit-Datenströme verarbeitet und ereignisgesteuerte Anwendungen erstellen kann. Es kann Streaming-Daten in Echtzeit erfassen und verarbeiten.
Laut Kafkas Webseite</diy11} vertrauen und nutzen über 80 % der Fortune 100-Unternehmen Kafka.
Am wichtigsten ist, dass Kafka skalierbar und sehr schnell ist. Das bedeutet, dass es viel mehr Daten verarbeiten kann, als auf nur einem Rechner Platz hätte, und das mit extrem niedriger Latenz.
Wenn Sie lernen möchten, wie man Kafka für das Datenstreaming erstellt, verwaltet und Fehler behebt, sollten Sie den Einführung in Kafka Kurs in Betracht ziehen.
Wann ist der beste Zeitpunkt, um Apache Kafka zu verwenden?
- Wenn Sie massive Datenmengen in Echtzeit verarbeiten müssen, wie zum Beispiel bei der Verarbeitung von IoT-Gerätedatenströmen.
- Wenn Sie sofortige Datenverarbeitung und -analyse benötigen, wie bei der Verfolgung von Benutzeraktivitäten in Echtzeit oder bei Betrugserkennungssystemen.
- In Event-Sourcing-Szenarien, in denen Sie Audit-Trails mit Compliance-Anforderungen und Vorschriften benötigen.
Die Verwaltung von Kafka-Instanzen kann jedoch mit vielen Kopfschmerzen verbunden sein. Hier kommt AWS MSK ins Spiel.
![]()
Bild vom Autor
AWS MSK (Managed Streaming for Kafka) ist ein vollständig verwalteter Dienst, der die Bereitstellung, Konfiguration, Skalierung und Wartung von Kafka-Clustern übernimmt. Sie können es verwenden, um Apps zu erstellen, die sofort auf Datenströme reagieren.
Kafka wird oft als Teil eines größeren Datenverarbeitungs-Setups verwendet, und AWS MSK erleichtert es noch weiter, Echtzeit-Datenpipelines zu erstellen, die Daten zwischen verschiedenen Systemen übertragen.
Wie Amazon MSK funktioniert. Bildquelle: AWS
Wenn Sie neu bei AWS sind, sollten Sie unseren Einführung in AWS Kurs in Betracht ziehen, um sich mit den Grundlagen vertraut zu machen. Wenn Sie bereit sind, können Sie zu unserem AWS Cloud-Technologie und -Dienste Kurs wechseln, um die gesamte Palette von Diensten zu erkunden, auf die Unternehmen angewiesen sind.
Funktionen von AWS MSK
AWS MSK hebt sich von der Konkurrenz ab, weil es ein vollständig verwalteter Dienst ist. Sie müssen sich keine Gedanken über die Einrichtung von Servern oder die Durchführung von Updates machen.
Es gibt jedoch noch mehr. Diese fünf Hauptmerkmale von AWS MSK machen es zu einer lohnenswerten Investition:
- MSK ist hochverfügbar, und AWS garantiert, dass strenge SLAs eingehalten werden. Es ersetzt automatisch fehlgeschlagene Komponenten ohne Ausfallzeiten für Ihre Anwendungen.
- MSK bietet eine Auto-Scaling-Option für den Speicher, sodass dieser automatisch mit Ihren Anforderungen wächst. Sie können auch schnell Ihren Speicher erhöhen oder verringern oder bei Bedarf weitere Broker hinzufügen.
- In Bezug auf die Sicherheit ist MSK eine umfassende Lösung, die Verschlüsselung im Ruhezustand und während der Übertragung bietet. Es integriert sich auch mit AWS IAM für die Zugriffskontrolle.
- Wenn Sie bereits Kafka verwenden, können Sie zu MSK wechseln, ohne Ihren Code zu ändern, da MSK alle gängigen Kafka-APIs und -Tools unterstützt.
- MSK ist eine kosteneffektive Option, die nicht erfordert, dass ein ganzes Ingenieurteam eingestellt wird, um Cluster zu überwachen und zu verwalten. AWS prahlt sogar damit, dass es bis zu 40% günstiger als selbstverwaltetes Kafka sein kann.
Vorteile der Verwendung von AWS MSK
Wie wir bereits gesehen haben, bietet AWS MSK aufgrund seiner Verfügbarkeit, Skalierbarkeit, Sicherheit und einfachen Integration sofortigen Mehrwert. Diese Kernvorteile haben es zur ersten Wahl für Unternehmen gemacht, die Kafka-Workloads in der Cloud ausführen.
AWS MSK löst vier kritische Herausforderungen, denen jedes Daten-Streaming-Projekt gegenübersteht:
- MSK ist ein vollständig verwalteter Dienst, der es Ihnen ermöglicht, sich auf die Entwicklung von Anwendungen anstelle des Infrastrukturmanagements zu konzentrieren.
- MSK ist hochverfügbar und zuverlässig, was heutzutage zunehmend wichtig wird, da Benutzer rund um die Uhr Zugriff auf Dienste und Anwendungen erwarten.
- MSK verfügt über wichtige umfassende Sicherheitsfunktionen.
- MSK hat eine native AWS-Integration, die es erheblich einfacher macht, vollständige Streaming-Datenlösungen innerhalb des AWS-Ökosystems zu erstellen.
Einrichten von AWS MSK
Um mit AWS MSK zu beginnen, erstellen Sie zunächst Ihr AWS-Konto. Wenn Sie AWS zum ersten Mal verwenden, erfahren Sie, wie Sie Ihr AWS-Konto einrichten und konfigurieren mit unserem umfassenden Tutorial.
Melden Sie sich bei der AWS Management Console an und öffnen Sie die MSK-Konsole. Klicken Sie auf „Cluster erstellen“, um den Einrichtungsprozess zu starten.

Erste Schritte mit AWS MSK. Bildquelle: AWS
Wählen Sie „Schnell erstellen“ für die Standard-Einstellungen und geben Sie dann einen beschreibenden Clusternamen ein.
Von dort aus haben Sie viele zusätzliche Optionen zur Auswahl, die alle von Ihren eigenen Anforderungen an Ihren Cluster abhängen. Hier ist eine kurze Übersicht über die Auswahlmöglichkeiten:
- Cluster-Typ: „Provisioned“ oder „Serverless“
- Apache Kafka-Version
- Broker-Typ: „Standard“ oder „Express“
- Broker-Größe
- EBS-Speichervolumen
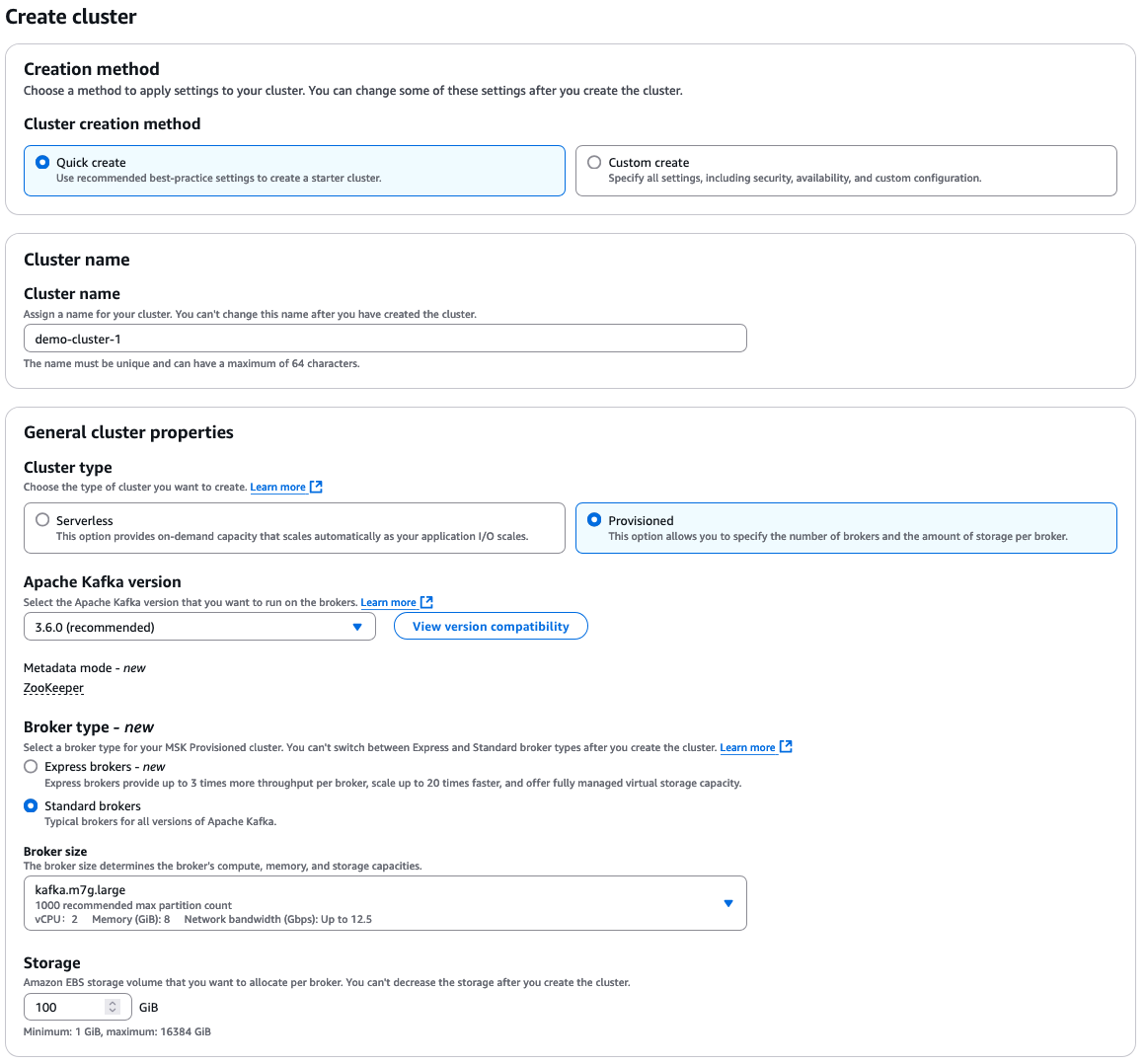
AWS MSK-Konfigurationsoptionen
Der Cluster wird immer innerhalb eines Amazon VPC erstellt. Sie können wählen, ob Sie das Standard-VPC verwenden oder ein benutzerdefiniertes VPC konfigurieren und angeben möchten.
Jetzt müssen Sie nur noch auf die Aktivierung Ihres Clusters warten, was 15 bis 30 Minuten dauern kann. Sie können den Status Ihres Clusters von der Cluster-Zusammenfassungsseite aus überwachen, wo Sie sehen werden, wie sich der Status von „Erstellen“ auf „Aktiv“ ändert.
Daten einfügen und verarbeiten mit AWS MSK
Nachdem Ihr MSK-Cluster eingerichtet ist, müssen Sie eine Client-Maschine erstellen, um Daten über ein oder mehrere Themen zu produzieren und zu konsumieren. Da Apache Kafka so gut mit vielen Datenproduzenten integriert ist (wie Websites, IoT-Geräte, Amazon EC2-Instanzen usw.), bietet MSK auch diesen Vorteil.
Apache Kafka organisiert Daten in Strukturen namens Topics. Jedes Topic besteht aus einem oder vielen Partitionen. Partitionen sind der Grad des Parallelismus in Apache Kafka. Die Daten werden über Broker mithilfe der Datenpartitionierung verteilt.
Wichtige Begriffe, die man bei der Arbeit mit Apache Kafka-Clustern kennen sollte:
- Topics sind die grundlegende Art der Organisation von Daten in Kafka.
- Producers sind Anwendungen, die Daten an Topics veröffentlichen – sie generieren und schreiben Daten in Kafka. Sie schreiben Daten zu bestimmten Topics und Partitionen.
- Verbraucher sind Anwendungen, die Daten aus Themen lesen und verarbeiten. Sie ziehen Daten aus Themen, bei denen sie angemeldet sind.
Beim Aufbau einer ereignisgesteuerten Architektur mit AWS MSK müssen Sie mehrere Schichten konfigurieren, wobei MSK die Hauptkomponente für die Datenerfassung ist. Hier ist eine Übersicht über die möglicherweise erforderlichen Schichten:
- Datenaufnahme-Setup
- Verarbeitungsschicht
- Speicherschicht
- Analyseschicht
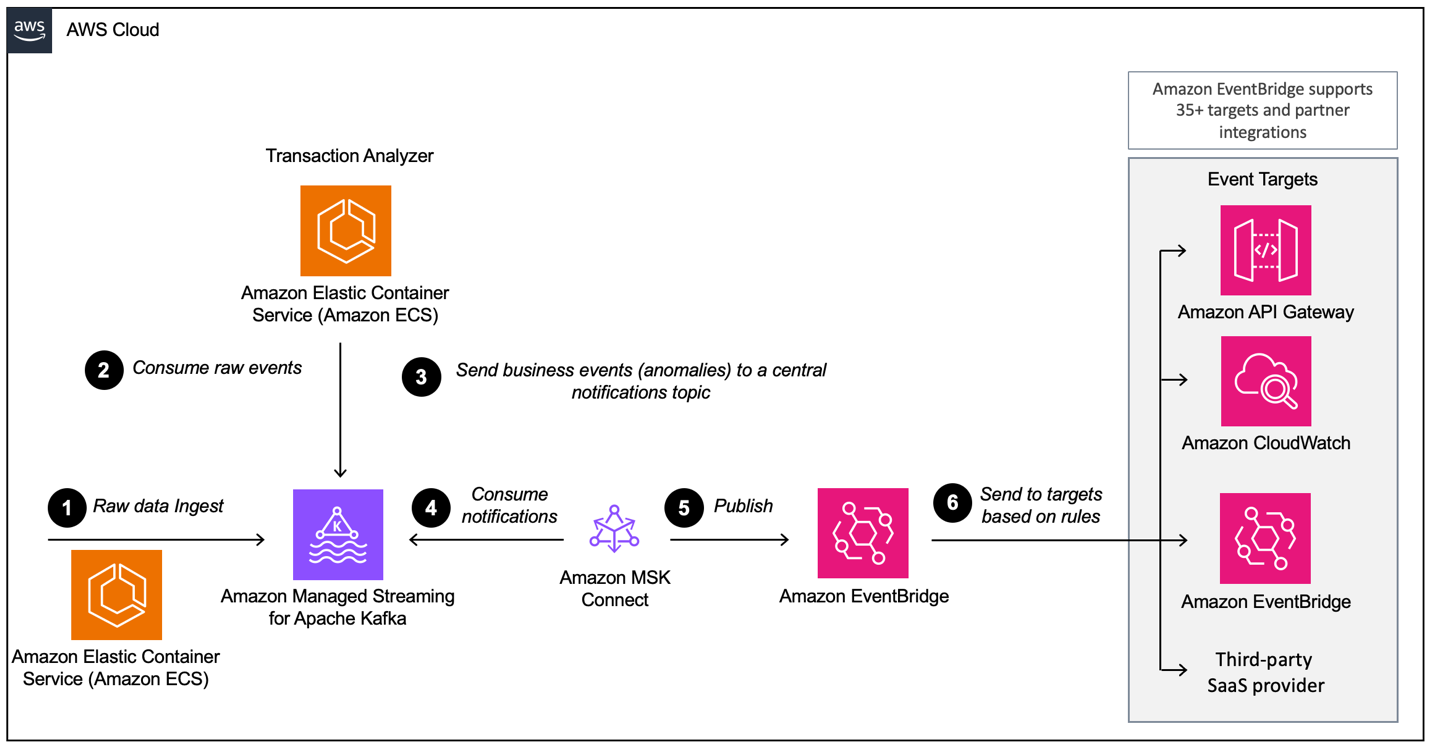
Beispiel einer ereignisgesteuerten Architektur mit Amazon MSK und Amazon EventBridge. Bildquelle: AWS
Wenn Sie Python in Ihren Daten-Pipeline-Workflows einsetzen möchten, werfen Sie einen Blick auf unseren Kurs Einführung in AWS Boto in Python.
Best Practices für die Verwendung von AWS MSK
AWS MSK lässt sich relativ einfach einrichten und sofort verwenden. Einige wesentliche Best Practices verbessern jedoch die Leistung Ihrer Cluster und sparen Ihnen später Zeit.
Richten Sie Ihren Cluster passend ein
Sie müssen die richtige Anzahl von Partitionen pro Broker und die richtige Anzahl von Brokern pro Cluster auswählen.
Eine Reihe von Faktoren kann Ihre Entscheidungen hier beeinflussen; jedoch hat AWS einige nützliche Empfehlungen und Ressourcen bereitgestellt, um Sie durch diesen Prozess zu führen.
Zusätzlich stellt AWS eine benutzerfreundliche Größen- und Preisspalte zur Verfügung, die Ihnen hilft, die richtige Größe Ihres Clusters und die damit verbundenen Kosten der Nutzung von AWS MSK im Vergleich zu einem ähnlichen selbstverwalteten EC2 Kafka-Cluster abzuschätzen.
Hochverfügbare Cluster erstellen
AWS empfiehlt, Ihre Cluster so einzurichten, dass sie hochverfügbar sind. Dies ist besonders wichtig, wenn Sie ein Update durchführen (wie z.B. das Aktualisieren der Apache Kafka-Version) oder wenn AWS einen Broker ersetzt.
Um sicherzustellen, dass Ihre Cluster hochverfügbar sind, müssen Sie drei Dinge tun:
- Richten Sie Ihre Cluster über drei Verfügbarkeitszonen ein (auch als Drei-AZ-Cluster bezeichnet).
- Setzen Sie den Replikationsfaktor auf 3 oder höher.
- Legen Sie die minimale Anzahl an synchronisierten Replikas auf RF-1 fest.
Das Tolle an AWS ist, dass sie sich zu strikten SLAs für Multi-AZ-Bereitstellungen verpflichten; ansonsten erhalten Sie Ihre Gutschriften zurück.
Überwachen Sie die Festplatten- und CPU-Auslastung
Zwei wichtige Metriken zur Überwachung über AWS CloudWatch sind die Festplatten- und CPU-Auslastung. Dadurch wird nicht nur sichergestellt, dass Ihr System reibungslos läuft, sondern auch dazu beigetragen, die Kosten niedrig zu halten.
Der beste Weg, um die Festplattennutzung und die damit verbundenen Speicherkosten zu verwalten, besteht darin, einen CloudWatch-Alarm einzurichten, der Sie alarmiert, wenn die Festplattennutzung einen bestimmten Wert, wie z.B. 85 %, überschreitet, und Ihre Aufbewahrungsrichtlinien anzupassen. Die Festlegung einer Aufbewahrungszeit für Nachrichten in Ihrem Protokoll kann erheblich dazu beitragen, automatisch Speicherplatz freizugeben.
Darüber hinaus empfiehlt AWS, die Gesamt-CPU-Auslastung Ihrer Broker unter 60 % zu halten, um die Leistung Ihres Clusters aufrechtzuerhalten und Engpässe zu vermeiden. Sie können dies mit AWS CloudWatch überwachen und dann Korrekturmaßnahmen ergreifen, indem Sie beispielsweise die Größe Ihres Brokers aktualisieren.
Schützen Sie Ihre Daten mit Verschlüsselung während der Übertragung
Standardmäßig verschlüsselt AWS Daten während der Übertragung zwischen den Brokern in Ihrem MSK-Cluster. Sie können dies deaktivieren, wenn Ihr System eine hohe CPU-Auslastung oder Latenz aufweist. Es wird jedoch dringend empfohlen, die Verschlüsselung während der Übertragung jederzeit aktiviert zu lassen und andere Möglichkeiten zur Leistungsverbesserung zu finden, falls dies ein Problem für Sie darstellt.
Werfen Sie einen Blick auf unseren AWS-Sicherheits- und Kostenmanagement-Kurs, um mehr darüber zu erfahren, wie Sie Ihre AWS-Cloud-Umgebung sichern und optimieren sowie Kosten und Ressourcen in AWS verwalten können.
Vergleich von AWS MSK mit anderen Streaming-Tools
Bei der Entscheidung, welches Tool am besten für ein Projekt geeignet ist, müssen wir oft mehrere Optionen bewerten. Hier sind die häufigsten Alternativen zu AWS MSK und wie sie sich vergleichen.
AWS MSK vs Apache Kafka auf EC2
Der Hauptkompromiss zwischen MSK und einer selbstgehosteten Option mit EC2 liegt zwischen Bequemlichkeit und Kontrolle: MSK gibt Ihnen weniger zu verwalten, bietet jedoch weniger Flexibilität, während EC2 Ihnen vollständige Kontrolle gibt, aber mehr Arbeit erfordert.
AWS MSK übernimmt alle komplexen Betriebsaufgaben, einschließlich automatischer Bereitstellung und Konfiguration. Der Vorteil davon ist, dass es keine anfänglichen Infrastrukturkosten gibt. Es gibt auch eine nahtlose Integration mit anderen AWS-Diensten und robuste Sicherheitsfunktionen.
Die Verwendung von Kafka auf EC2 hingegen erfordert mehr manuelle Einrichtung und Konfiguration, und Sie müssen auch alle Wartungs- und Updateaufgaben selbst übernehmen. Dies bietet zwar weit mehr Flexibilität, kann jedoch mit mehr Komplexität und Betriebskosten verbunden sein und möglicherweise auch erfahrene Teams erfordern.
AWS MSK vs. Kinesis
Verwenden Sie Kinesis für Einfachheit und tiefe Integration in AWS und MSK für Kafka-Kompatibilität oder mehr Kontrolle über Ihr Streaming-Setup.
Kinesis ist eine vollständig serverlose Architektur, die Shards für das Daten-Streaming verwendet. AWS übernimmt alles für Sie. Es gibt jedoch Datenretentionsgrenzen, die beachtet werden müssen. Kinesis ist eine großartige Lösung für einfache Daten-Streaming-Anforderungen.
AWS MSK basiert auf dem Topic- und Partition-Modell von Kafka, mit nahezu unbegrenzter Datenspeicherung, abhängig von Ihrem Speicher. Es ist eine flexiblere und anpassbare Lösung, von der Sie bei Bedarf von AWS weg migrieren können.
Wenn Sie nicht mit Kinesis vertraut sind, haben wir einen Kurs, der Sie durch die Arbeit mit Streaming-Daten mit AWS Kinesis und Lambda führt.
AWS MSK vs. Confluent
Wählen Sie Confluent, wenn Sie umfassende Funktionen und Unterstützung benötigen, und wählen Sie MSK, wenn Sie stark in AWS investiert sind und über Kafka-Expertise im Unternehmen verfügen.
Confluent verfügt über einen umfangreichen Funktionsumfang mit vielen integrierten Connectors. Es ist insgesamt eine teurere Option, bietet jedoch eine kostenlose Stufe mit begrenzten Funktionen. Confluent eignet sich gut für unregelmäßige Workloads und hat einen einfacheren Bereitstellungsprozess.
Im Vergleich dazu ist AWS schlanker und konzentriert sich auf die Kernfunktionalität von Kafka. Um auf einen erweiterten Funktionsumfang zugreifen zu können, muss AWS MSK mit anderen AWS-Diensten integriert werden. Glücklicherweise ist diese Integration nahtlos. AWS MSK hat niedrigere Grundkosten und kann eine gute Option für konsistente Workloads sein.
Die folgende Tabelle bietet einen Vergleich von AWS MSK und seinen Alternativen:
|
Funktion |
AWS MSK |
Apache Kafka auf EC2 |
Kinesis |
Confluent |
|
Bereitstellung |
Vollständig verwaltet |
Self-Managed auf EC2 |
Vollständig verwaltet |
Vollständig verwaltet oder Self-Managed |
|
Benutzerfreundlichkeit |
Einfache Einrichtung und Verwaltung |
Erfordert manuelle Einrichtung und Skalierung |
Einfache Einrichtung; AWS-native |
Benutzerfreundliche Benutzeroberfläche und fortschrittliche Tools |
|
Skalierbarkeit |
Auto-Skalierung mit manuellen Anpassungen |
Manuelles Skalieren |
Nahtlose Skalierung |
Auto-Skalierung mit Flexibilität |
|
Latenz |
Niedrige Latenz |
Niedrige Latenz |
Niedrigere Latenz für kleine Nutzlasten |
Vergleichbar mit MSK |
|
Protokollunterstützung |
Kafka API-kompatibel |
Kafka API-kompatibel |
Eigenes Kinesis-Protokoll |
Kafka API und zusätzliche Protokolle |
|
Datenaufbewahrung |
Konfigurierbar (bis zu 7 Tage standardmäßig) |
Konfigurierbar |
Konfigurierbar (max. 365 Tage) |
Sehr konfigurierbar |
|
Überwachung und Metriken |
Integriert mit CloudWatch |
Erfordert benutzerdefinierte Einrichtung |
Integriert mit CloudWatch |
Erweiterte Überwachungstools |
|
Kosten |
Bezahlen nach Verbrauch |
Basierend auf EC2-Instanzpreisen |
Bezahlen nach Verbrauch |
Abo-basiert |
|
Sicherheit |
Eingebaute AWS-Sicherheitsfunktionen |
Muss Sicherheit manuell konfigurieren |
Integriert mit AWS IAM |
Umfassende Sicherheitsfunktionen |
|
Anwendungsfall Eignung |
Am besten für Kafka-Benutzer im AWS-Ökosystem |
Flexibel, aber aufwendig in der Wartung |
Am besten für AWS-native Apps |
Fortgeschrittene Kafka-Benutzer und Unternehmen |
Schlussgedanken
Apache Kafka ist die erste Wahl für Situationen, in denen Sie eine großflächige, zuverlässige Lösung benötigen, die keinen Datenverlust zulassen kann und die Verbindung mehrerer Datenquellen oder den Aufbau komplexer Datenpipelines erfordert. AWS MSK verhindert viele der Kopfschmerzen beim Einrichten und Konfigurieren von Kafka-Clustern, sodass Entwickler sich mehr auf den Aufbau und die Verbesserung von Anwendungen anstatt auf die Infrastruktur konzentrieren können.
Eine AWS-Zertifizierung zu erwerben, ist eine ausgezeichnete Möglichkeit, Ihre AWS-Karriere zu starten. Sie können Ihre AWS-Fähigkeiten ausbauen, indem Sie unseren Kurskatalog durchsehen und praktische Erfahrungen durch Projekte sammeln!