













Molte aziende stanno scegliendo di passare ad AWS MSK per evitare i problemi operativi associati alla gestione dei cluster Apache Kafka.
In questo tutorial, esploreremo le caratteristiche, i vantaggi e le best practice di AWS MSK. Esamineremo anche i passaggi di base per configurare AWS MSK e vedremo come si confronta con altri servizi popolari come Kinesis e Confluent.
Cos’è AWS MSK?
Prima di tutto, cerchiamo di capire Apache Kafka e perché è così utile per lo streaming di dati.
Apache Kafka è una piattaforma di streaming distribuita open source che gestisce flussi di dati in tempo reale e può costruire app basate sugli eventi. Può ingerire e elaborare dati in streaming mentre si verificano.
Secondo il sito web di Kafka, oltre l’80% delle aziende Fortune 100 si fida e utilizza Kafka.
Kafka è soprattutto scalabile e molto veloce. Ciò significa che può gestire molti più dati di quelli che potrebbero adattarsi su un’unica macchina e con tempi di latenza molto bassi.
Se desideri imparare come creare, gestire e risolvere problemi relativi a Kafka per lo streaming di dati, considera di seguire il corso Introduzione a Kafka.
Qual è il momento migliore per utilizzare Apache Kafka?
- Quando devi gestire enormi quantità di dati in tempo reale, come nel caso della gestione dei flussi di dati dei dispositivi IoT.
- Quando hai bisogno di elaborare e analizzare immediatamente i dati, ad esempio nel tracciamento delle attività degli utenti in tempo reale o nei sistemi di rilevamento delle frodi.
- In scenari di event-sourcing in cui è necessario avere registri di audit conformi ai requisiti normativi.
Tuttavia, gestire le istanze di Kafka può comportare molti problemi. Ecco dove entra in gioco AWS MSK.
![]()
Immagine dell’autore
AWS MSK (Managed Streaming for Kafka) è un servizio completamente gestito che si occupa della fornitura, configurazione, ridimensionamento e manutenzione dei cluster Kafka. Puoi usarlo per creare app che reagiscono istantaneamente ai flussi di dati.
Kafka è spesso utilizzato come parte di un setup più ampio di elaborazione dati, e AWS MSK rende ancora più facile creare pipeline dati in tempo reale che spostano dati tra sistemi diversi.
Come funziona Amazon MSK. Fonte immagine: AWS
Se sei nuovo di AWS, considera di seguire il nostro corso Introduzione ad AWS per familiarizzare con le basi. Quando sei pronto, puoi passare al nostro corso Tecnologia e Servizi Cloud di AWS per esplorare l’intera gamma di servizi di cui le imprese fanno affidamento.
Caratteristiche di AWS MSK
AWS MSK si distingue dalla concorrenza perché è un servizio completamente gestito. Non devi preoccuparti di configurare server o occuparti degli aggiornamenti.
Tuttavia, c’è di più. Queste cinque caratteristiche chiave di AWS MSK lo rendono un investimento valido:
- MSK è altamente disponibile e AWS garantisce che vengano rispettati severi SLA. Sostituisce automaticamente i componenti falliti senza tempi di inattività per le tue app.
- MSK ha un’opzione di autoscaling per lo storage, quindi cresce automaticamente in base alle tue esigenze. Puoi anche scalare rapidamente l’archiviazione verso l’alto o verso il basso o aggiungere più broker se necessario.
- Per quanto riguarda la sicurezza, MSK è una soluzione completa che fornisce crittografia a riposo e in transito. Si integra inoltre con AWS IAM per il controllo degli accessi.
- Se stai già utilizzando Kafka, puoi passare a MSK senza modificare il tuo codice poiché MSK supporta tutte le API e gli strumenti regolari di Kafka.
- MSK è un’opzione conveniente che non richiede di assumere un intero team di ingegneri per monitorare e gestire i cluster. AWS afferma addirittura che può essere fino al 40% più economico rispetto a Kafka autogestito.
Vantaggi dell’utilizzo di AWS MSK
Come abbiamo già visto, AWS MSK offre un valore immediato grazie alla sua disponibilità, scalabilità, sicurezza e facilità di integrazione. Questi vantaggi fondamentali lo hanno reso la scelta preferita per le aziende che gestiscono carichi di lavoro Kafka nel cloud.
AWS MSK risolve quattro sfide critiche che ogni progetto di data streaming affronta:
- MSK è un servizio completamente gestito, che ti permette di concentrarti sulla creazione di applicazioni anziché sulla gestione dell’infrastruttura.
- MSK è altamente disponibile e affidabile, il che sta diventando sempre più critico oggi, poiché gli utenti si aspettano un accesso 24 ore su 24, 7 giorni su 7 ai servizi e alle applicazioni.
- MSK ha importanti capacità di sicurezza complete.
- MSK ha un’integrazione nativa con AWS, rendendo molto più semplice la creazione di soluzioni complete per dati in streaming all’interno dell’ecosistema AWS.
Configurazione di AWS MSK
Per iniziare con AWS MSK, prima crea il tuo account AWS. Se è la prima volta che utilizzi AWS, scopri come configurare e impostare il tuo account AWS con il nostro tutorial esaustivo.
Accedi alla Console di gestione AWS e apri la console MSK. Clicca su “Crea cluster” per avviare il processo di configurazione.

Per iniziare con AWS MSK. Fonte immagine: AWS
Seleziona “Crea rapida” per impostazioni predefinite, poi inserisci un nome descrittivo per il cluster.
A partire da lì, hai molte opzioni aggiuntive tra cui scegliere, che dipendono tutte dai tuoi requisiti per il tuo cluster. Ecco una rapida panoramica delle scelte:
- Tipo di cluster: “Provisioned” o “Serverless”
- Versione di Apache Kafka
- Tipo di broker: “Standard” o “Express”
- Dimensione del broker
- Volume di archiviazione EBS
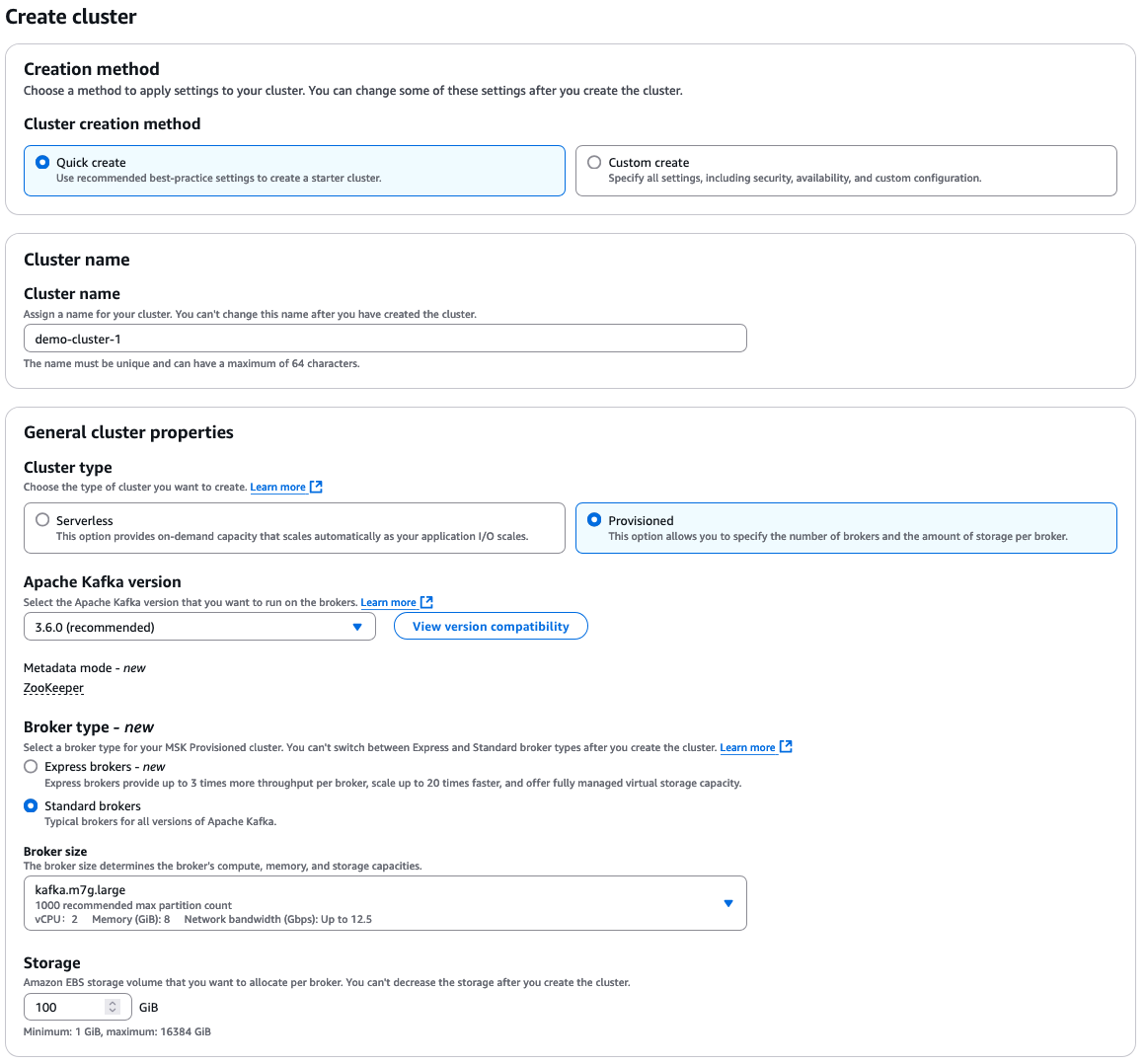
Opzioni di configurazione AWS MSK
Il cluster viene sempre creato all’interno di un Amazon VPC. È possibile scegliere di utilizzare il VPC predefinito o configurare e specificare un VPC personalizzato.
Ora, devi solo attendere l’attivazione del tuo cluster, il che può richiedere da 15 a 30 minuti. È possibile monitorare lo stato del cluster dalla pagina di riepilogo del cluster, dove vedrai lo stato cambiare da “Creazione” a “Attivo”.
Ingestione e Elaborazione dei Dati con AWS MSK
Una volta configurato il tuo cluster MSK, dovrai creare una macchina client per produrre e consumare dati su uno o più argomenti. Poiché Apache Kafka si integra così bene con molti produttori di dati (come siti web, dispositivi IoT, istanze Amazon EC2, ecc.), MSK condivide anche questo vantaggio.
Apache Kafka organizza i dati in strutture chiamate argomenti. Ogni argomento è composto da una o molte partizioni. Le partizioni sono il grado di parallelismo in Apache Kafka. I dati sono distribuiti tra i broker utilizzando la partizione dei dati.
Termini chiave da conoscere quando si lavora con cluster Apache Kafka:
- Argomenti sono il modo fondamentale di organizzare i dati in Kafka.
- Produttori sono applicazioni che pubblicano dati sugli argomenti – generano e scrivono dati su Kafka. Scrivono dati su argomenti e partizioni specifiche.
- I consumatorisono applicazioni che leggono ed elaborano dati dai topic. Estraggono dati dai topic a cui sono iscritti.
Nella costruzione di un’architettura basata sugli eventi con AWS MSK, è necessario configurare diversi livelli, di cui MSK è il componente principale di ingestione dei dati. Ecco una panoramica dei livelli che potrebbero essere richiesti:
- Configurazione dell’ingestione dei dati
- Livello di elaborazione
- Livello di archiviazione
- Livello di analisi
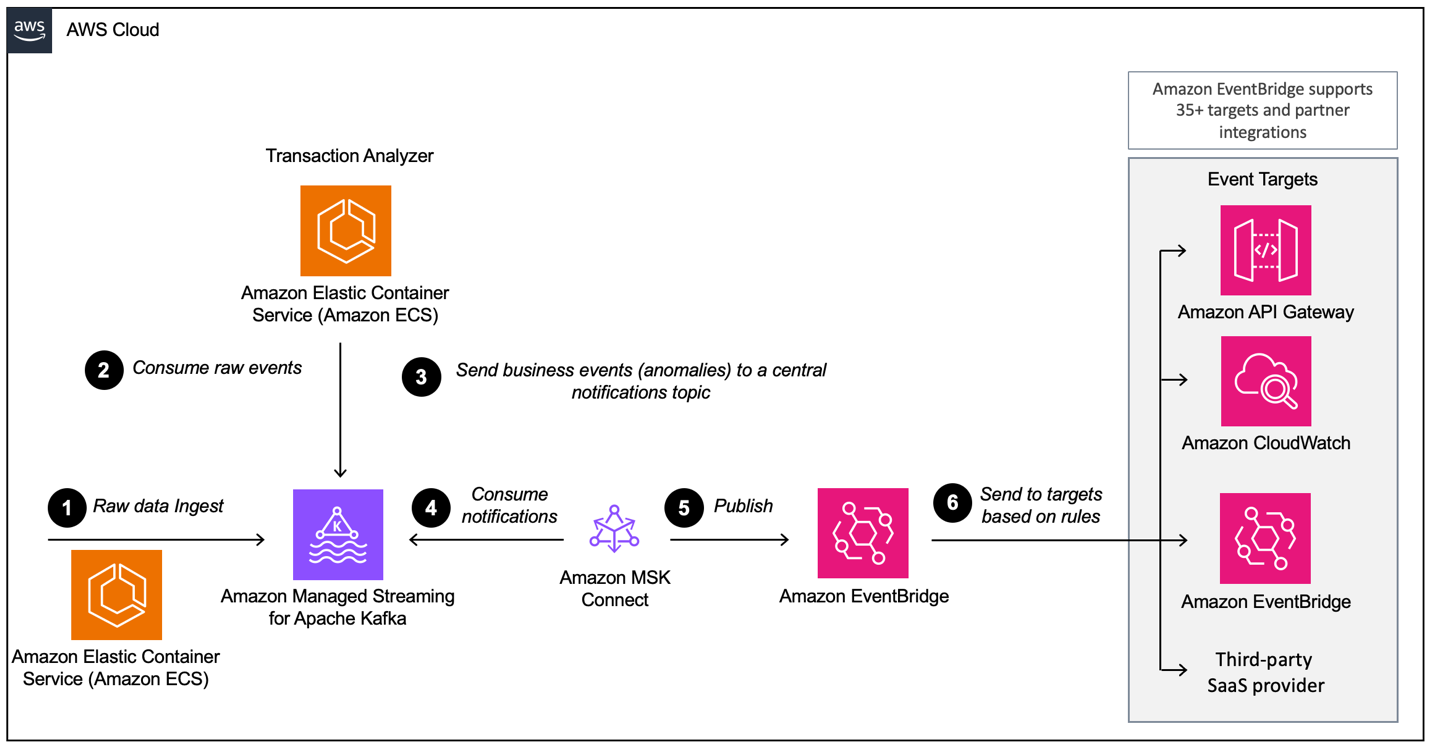
Esempio di architettura basata su eventi con Amazon MSK e Amazon EventBridge. Fonte dell’immagine: AWS
Se sei interessato a sfruttare Python nei tuoi flussi di lavoro di pipeline dati, dai un’occhiata al nostro corso Introduzione a AWS Boto in Python.
Best Practices per l’uso di AWS MSK
AWS MSK è relativamente semplice da configurare e iniziare ad utilizzare subito. Tuttavia, alcune best practices essenziali miglioreranno le prestazioni dei tuoi cluster e ti risparmieranno tempo in seguito.
Ottimizza le dimensioni del tuo cluster
Dovrai scegliere il numero corretto di partizioni per broker e il numero corretto di broker per cluster.
Una serie di fattori possono influenzare le tue decisioni qui; tuttavia, AWS ha fornito utili raccomandazioni e risorse per guidarti attraverso questo processo.
Inoltre, AWS fornisce un foglio di calcolo dimensionamento e prezzi facile da usare per aiutarti a stimare la dimensione corretta del tuo cluster e i costi associati all’utilizzo di AWS MSK rispetto a un cluster Kafka EC2 auto-gestito simile.
Costruisci cluster altamente disponibili
AWS consiglia di configurare i tuoi cluster per essere altamente disponibili. Questo è particolarmente importante durante l’esecuzione di un aggiornamento (come l’aggiornamento della versione di Apache Kafka) o quando AWS sta sostituendo un broker.
Per garantire che i tuoi cluster siano altamente disponibili, ci sono tre cose che devi fare:
- Configura i tuoi cluster su tre zone di disponibilità (chiamato anche cluster a tre AZ).
- Imposta il fattore di replicazione a 3 o più.
- Imposta il numero minimo di repliche in sincronia su RF-1.
Il bello di AWS è che si impegnano per SLA rigorose per le distribuzioni multi-AZ; altrimenti, ricevi indietro i tuoi crediti.
Monitora l’utilizzo del disco e della CPU
Due metriche chiave da monitorare tramite AWS CloudWatch sono l’utilizzo del disco e della CPU. Farlo non solo garantirà che il tuo sistema funzioni senza intoppi, ma ti aiuterà anche a contenere i costi.
Il modo migliore per gestire l’utilizzo del disco e i costi di archiviazione associati è impostare un allarme CloudWatch che ti avvisi quando l’utilizzo del disco supera un certo valore, come l’85%, e adeguare le tue politiche di retention. Impostare un tempo di retention per i messaggi nel tuo log può contribuire notevolmente a liberare automaticamente spazio su disco.
Inoltre, per mantenere le prestazioni del tuo cluster ed evitare colli di bottiglia, AWS raccomanda di mantenere l’utilizzo totale della CPU per i tuoi broker al di sotto del 60%. Puoi monitorare questo utilizzando AWS CloudWatch e poi intraprendere azioni correttive aggiornando, ad esempio, le dimensioni del tuo broker.
Proteggi i tuoi dati utilizzando la crittografia in transito
Per impostazione predefinita, AWS crittografa i dati in transito tra i broker nel tuo cluster MSK. Puoi disabilitarlo se il tuo sistema sta sperimentando un elevato utilizzo della CPU o latenza. Tuttavia, è fortemente raccomandato mantenere la crittografia in transito sempre attiva e trovare altri modi per migliorare le prestazioni se questo rappresenta un problema per te.
Scopri il nostro Corso di Sicurezza e Gestione dei Costi AWS per saperne di più su come proteggere e ottimizzare il tuo ambiente cloud AWS e gestire costi e risorse in AWS.
Confronto tra AWS MSK e altri strumenti di streaming
Quando si decide quale strumento è il migliore per un progetto, spesso è necessario valutare diverse opzioni. Ecco le alternative più comuni a AWS MSK e come si confrontano.
AWS MSK vs Apache Kafka su EC2
Il principale compromesso tra MSK e un’opzione self-hosted usando EC2 riguarda la comodità e il controllo: MSK offre meno da gestire ma meno flessibilità, mentre EC2 offre un controllo completo ma richiede più lavoro.
AWS MSK gestisce tutte le complesse attività operative, con provisioning e configurazione automatici. Il lato positivo di questo è che non ci sono costi di infrastruttura iniziali. Vi è inoltre un’integrazione senza soluzione di continuità con altri servizi AWS e robuste funzionalità di sicurezza.
Utilizzare Kafka su EC2, d’altra parte, comporta una configurazione e un setup più manuali, e è necessario gestire da soli la manutenzione e gli aggiornamenti. Questo offre molta più flessibilità ma potrebbe comportare maggiore complessità e costi operativi e potrebbe richiedere team più altamente qualificati.
AWS MSK vs. Kinesis
Usa Kinesis per la semplicità e l’integrazione profonda con AWS e MSK per la compatibilità con Kafka o per un maggiore controllo sulla tua configurazione di streaming.
Kinesis è un’architettura completamente serverless che utilizza shard per lo streaming di dati. AWS gestisce tutto per te. Tuttavia, ci sono limiti di conservazione dei dati da tenere in considerazione. Kinesis è una ottima soluzione per requisiti di streaming di dati semplici.
AWS MSK si basa sul modello di topic e partizioni di Kafka, con una conservazione dei dati virtualmente illimitata, a seconda del tuo storage. È una soluzione più flessibile e personalizzabile da cui puoi migrare lontano da AWS se necessario.
Se non sei familiare con Kinesis, abbiamo un corso che ti guida nel lavoro con dati in streaming usando AWS Kinesis e Lambda.
AWS MSK vs. Confluent
Scegli Confluent se hai bisogno di funzionalità e supporto completi, e scegli MSK se sei fortemente investito in AWS e hai competenze interne su Kafka.
Confluent ha un ricco set di funzionalità con molti connettori integrati. È un’opzione complessivamente più costosa ma offre un livello gratuito con funzionalità limitate. Confluent funziona bene per carichi di lavoro a picco ed ha un processo di distribuzione più semplice.
In confronto, AWS è più snello e si concentra sulle funzionalità core di Kafka. Per accedere a un set di funzionalità più estese, AWS MSK deve essere integrato con altri servizi AWS. Fortunatamente, questa integrazione è senza problemi. AWS MSK ha un costo base inferiore e può essere una buona opzione per carichi di lavoro consistenti.
La seguente tabella offre un confronto tra AWS MSK e le sue alternative:
|
Funzionalità |
AWS MSK |
Apache Kafka su EC2 |
Kinesis |
Confluent |
|
Distribuzione |
Completamente gestito |
Autogestito su EC2 |
Completamente gestito |
Completamente gestito o autogestito |
|
Facilità d’uso |
Facile da configurare e gestire |
Richiede configurazione e scalabilità manuale |
Configurazione semplice; nativo AWS |
Interfaccia utente intuitiva e strumenti avanzati |
|
Scalabilità |
Auto-scaling con aggiustamenti manuali |
Scaling manuale |
Scaling senza interruzioni |
Auto-scaling con flessibilità |
|
Latenza |
Bassa latenza |
Bassa latenza |
Bassa latenza per piccoli carichi |
Equiparabile a MSK |
|
Supporto di protocollo |
Compatibile con API Kafka |
Compatibile con API Kafka |
Protocollo proprietario Kinesis |
API Kafka e protocolli aggiuntivi |
|
Conservazione dei dati |
Configurabile (fino a 7 giorni di default) |
Configurabile |
Configurabile (massimo 365 giorni) |
Altamente configurabile |
|
Monitoraggio e metriche |
Integrato con CloudWatch |
Richiede configurazione personalizzata |
Integrato con CloudWatch |
Strumenti avanzati di monitoraggio |
|
Costo |
Pagamento in base all’uso |
Basato sulle tariffe delle istanze EC2 |
Pagamento in base all’uso |
Basato su abbonamento |
|
Sicurezza |
Funzionalità di sicurezza integrate di AWS |
Necessario configurare manualmente la sicurezza |
Integrato con AWS IAM |
Funzionalità di sicurezza complete |
|
Idoneità del caso d’uso |
Ideale per gli utenti di Kafka nell’ecosistema AWS |
Flessibile, ma con elevata manutenzione |
Ideale per le app native di AWS |
Utenti avanzati di Kafka e imprese |
Closing Thoughts
Apache Kafka è la scelta principale per situazioni in cui è necessaria una soluzione affidabile su larga scala che non può permettersi perdite di dati e richiede il collegamento di più origini dati o la creazione di complesse pipeline di dati. AWS MSK previene molti dei problemi legati alla configurazione dei cluster Kafka, permettendo agli sviluppatori di concentrarsi maggiormente sulla creazione e miglioramento delle applicazioni anziché sull’infrastruttura.
Ottenere una certificazione AWS è un ottimo modo per avviare la propria carriera AWS. Puoi migliorare le tue competenze AWS consultando il nostro catalogo dei corsi e ottenendo esperienza pratica attraverso progetti!