













Muchas empresas están optando por cambiar a AWS MSK para evitar los dolores de cabeza operativos asociados con la gestión de clústeres de Apache Kafka.
En este tutorial, exploraremos las características, beneficios y mejores prácticas de AWS MSK. También repasaremos los pasos básicos para configurar AWS MSK y veremos cómo se compara con otros servicios populares como Kinesis y Confluent.
¿Qué es AWS MSK?
Primero, veamos qué es Apache Kafka y por qué es tan útil para la transmisión de datos.
Apache Kafka es una plataforma de transmisión distribuida de código abierto que maneja flujos de datos en tiempo real y puede construir aplicaciones basadas en eventos. Puede ingerir y procesar datos en streaming a medida que ocurren.
Según el sitio web de Kafka, más del 80% de las empresas Fortune 100 confían y utilizan Kafka.
Lo más importante, Kafka es escalable y muy rápido. Esto significa que puede manejar mucha más información de la que cabría en una sola máquina y con una latencia súper baja.
Si deseas aprender a crear, gestionar y solucionar problemas de Kafka para el flujo de datos, considera tomar el curso Introducción a Kafka.
¿Cuándo es el mejor momento para usar Apache Kafka?
- Cuando necesitas manejar grandes cantidades de datos en tiempo real, como el manejo de flujos de datos de dispositivos IoT.
- Cuando necesitas procesamiento y análisis de datos inmediatos, como en el seguimiento de actividad de usuarios en vivo o sistemas de detección de fraudes.
- En escenarios de eventos, donde necesitas registros de auditoría con requisitos de cumplimiento y regulaciones.
Sin embargo, administrar instancias de Kafka puede acarrear muchos dolores de cabeza. Aquí es donde entra AWS MSK.
![]()
Imagen por Autor
AWS MSK (Managed Streaming for Kafka) es un servicio completamente gestionado que se encarga de la aprovisionamiento, configuración, escalado y mantenimiento de clústeres de Kafka. Puedes utilizarlo para construir aplicaciones que reaccionen a flujos de datos al instante.
Kafka se utiliza a menudo como parte de una configuración de procesamiento de datos más amplia, y AWS MSK facilita aún más la creación de canalizaciones de datos en tiempo real que mueven datos entre diferentes sistemas.
Cómo funciona Amazon MSK. Fuente de la imagen:AWS
Si eres nuevo en AWS, considera tomar nuestro curso de Introducción a AWS para familiarizarte con los conceptos básicos. Cuando estés listo, puedes pasar a nuestro curso de Tecnología y Servicios en la Nube de AWS para explorar la gama completa de servicios en los que confían las empresas.
Características de AWS MSK
AWS MSK se destaca de la competencia porque es un servicio completamente gestionado. No tienes que preocuparte por configurar servidores o lidiar con actualizaciones.
Sin embargo, hay más que eso. Estas cinco características clave de AWS MSK hacen que sea una inversión que vale la pena:
- MSK es altamente disponible, y AWS garantiza que se cumplan estrictos SLAs. Reemplaza automáticamente los componentes fallidos sin tiempo de inactividad para tus aplicaciones.
- MSK tiene una opción de escalado automático para almacenamiento, por lo que crece automáticamente con tus necesidades. También puedes escalar rápidamente hacia arriba o hacia abajo tu almacenamiento o añadir más brokers según sea necesario.
- En cuanto a seguridad, MSK es una solución integral que proporciona cifrado en reposo y en tránsito. También se integra con AWS IAM para el control de acceso.
- Si ya estás utilizando Kafka, puedes migrar a MSK sin necesidad de cambiar tu código, ya que MSK es compatible con todas las API y herramientas habituales de Kafka.
- MSK es una opción rentable que no requiere contratar un equipo de ingeniería completo para monitorear y gestionar clusters. Incluso AWS presume que puede ser hasta un 40% más barato que Kafka autoadministrado.
Beneficios de usar AWS MSK
Como ya hemos visto, AWS MSK ofrece un valor inmediato debido a su disponibilidad, escalabilidad, seguridad y facilidad de integración. Estas ventajas fundamentales lo han convertido en la elección preferida para las empresas que ejecutan cargas de trabajo de Kafka en la nube.
AWS MSK resuelve cuatro desafíos críticos que enfrenta cada proyecto de transmisión de datos:
- MSK es un servicio completamente gestionado que te permite centrarte en la creación de aplicaciones en lugar de administrar la infraestructura.
- MSK es altamente disponible y fiable, lo cual es cada vez más crítico en la actualidad, ya que los usuarios esperan acceso 24/7 a servicios y aplicaciones.
- MSK cuenta con capacidades de seguridad críticas y completas.
- MSK tiene integración nativa con AWS, lo que facilita mucho la construcción de soluciones completas de datos en streaming dentro del ecosistema de AWS.
Configuración de AWS MSK
Para comenzar con AWS MSK, primero crea tu cuenta de AWS. Si es la primera vez que utilizas AWS, aprende cómo configurar tu cuenta de AWS con nuestro tutorial completo.
Inicia sesión en la Consola de administración de AWS y abre la consola de MSK. Haz clic en “Crear clúster” para iniciar el proceso de configuración.

Comenzando con AWS MSK. Fuente de la imagen: AWS
Selecciona “Creación rápida” para usar la configuración predeterminada, luego ingresa un nombre descriptivo para el clúster.
A partir de ahí, tienes muchas opciones adicionales para seleccionar, las cuales dependen de tus propios requisitos para tu clúster. Aquí tienes una visión general rápida de las opciones:
- Tipo de clúster: “Provisionado” o “Serverless”
- Versión de Apache Kafka
- Tipo de broker: “Estándar” o “Express”
- Tamaño del broker
- Volumen de almacenamiento EBS
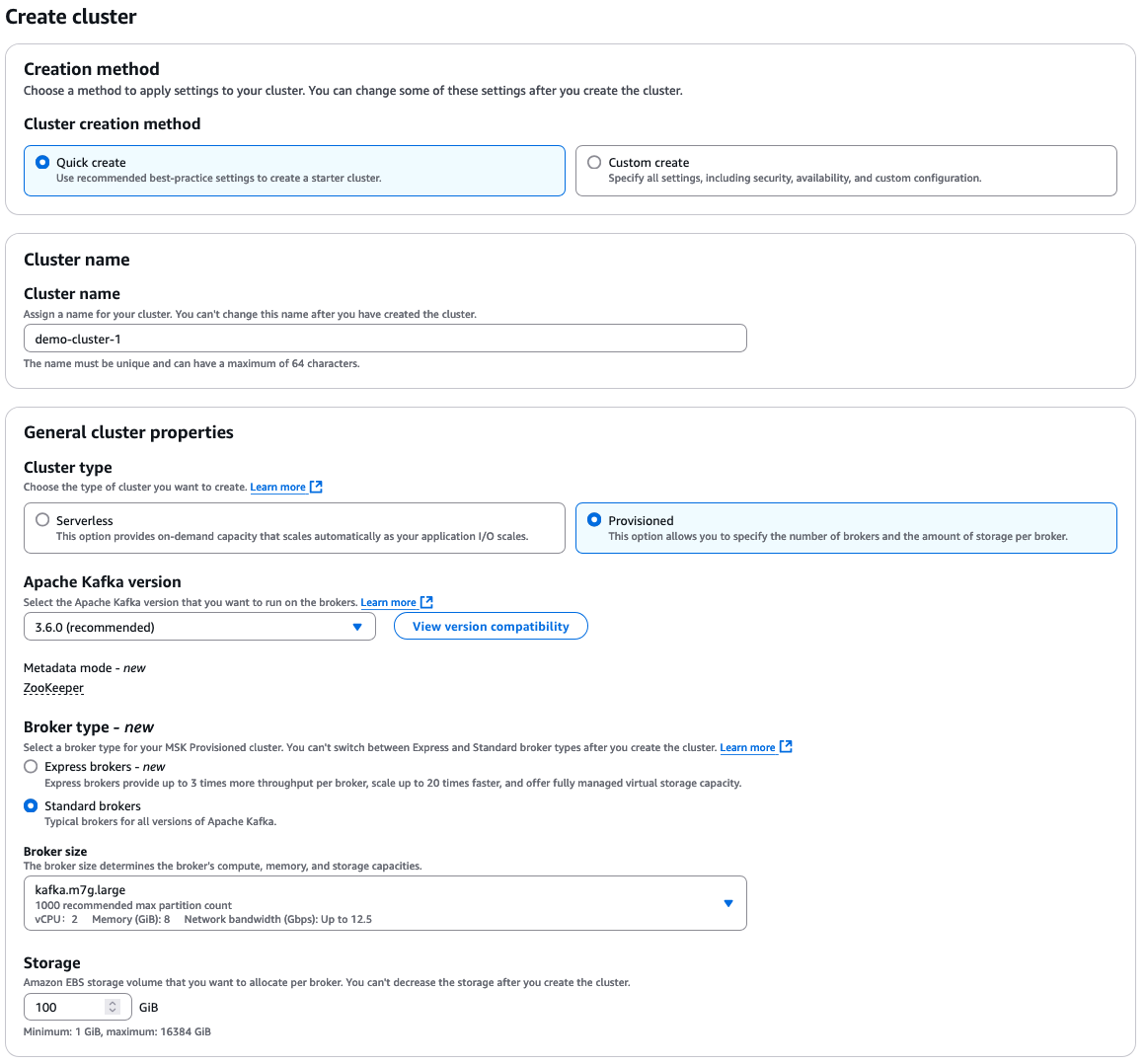
Opciones de configuración de AWS MSK
El clúster siempre se crea dentro de una Amazon VPC. Puedes optar por usar la VPC predeterminada o configurar y especificar una VPC personalizada.
Ahora, solo necesitas esperar a que tu clúster se active, lo cual puede tardar de 15 a 30 minutos. Puedes monitorear el estado de tu clúster desde la página de resumen del clúster, donde verás que el estado cambia de “Creando” a “Activo”.
Ingestión y Procesamiento de Datos con AWS MSK
Una vez configurado tu clúster de MSK, necesitarás crear una máquina cliente para producir y consumir datos a través de uno o más temas. Dado que Apache Kafka se integra tan bien con muchos productores de datos (como sitios web, dispositivos IoT, instancias de Amazon EC2, etc.), MSK también comparte este beneficio.
Apache Kafka organiza datos en estructuras llamadas temas. Cada tema consta de una o muchas particiones. Las particiones son el grado de paralelismo en Apache Kafka. Los datos se distribuyen en los brokers mediante particionamiento de datos.
Términos clave a tener en cuenta al tratar con clústeres de Apache Kafka:
- Temas son la forma fundamental de organizar datos en Kafka.
- Productores son aplicaciones que publican datos en temas, generan y escriben datos en Kafka. Escriben datos en temas y particiones específicos.
- Los consumidores son aplicaciones que leen y procesan datos de temas. Extraen datos de temas a los que están suscritos.
Al construir una arquitectura basada en eventos con AWS MSK, es necesario configurar varias capas, de las cuales MSK es el componente principal de ingestión de datos. Aquí tienes una visión general de las capas que pueden ser necesarias:
- Configuración de ingestión de datos
- Capa de procesamiento
- Capa de almacenamiento
- Capa de análisis
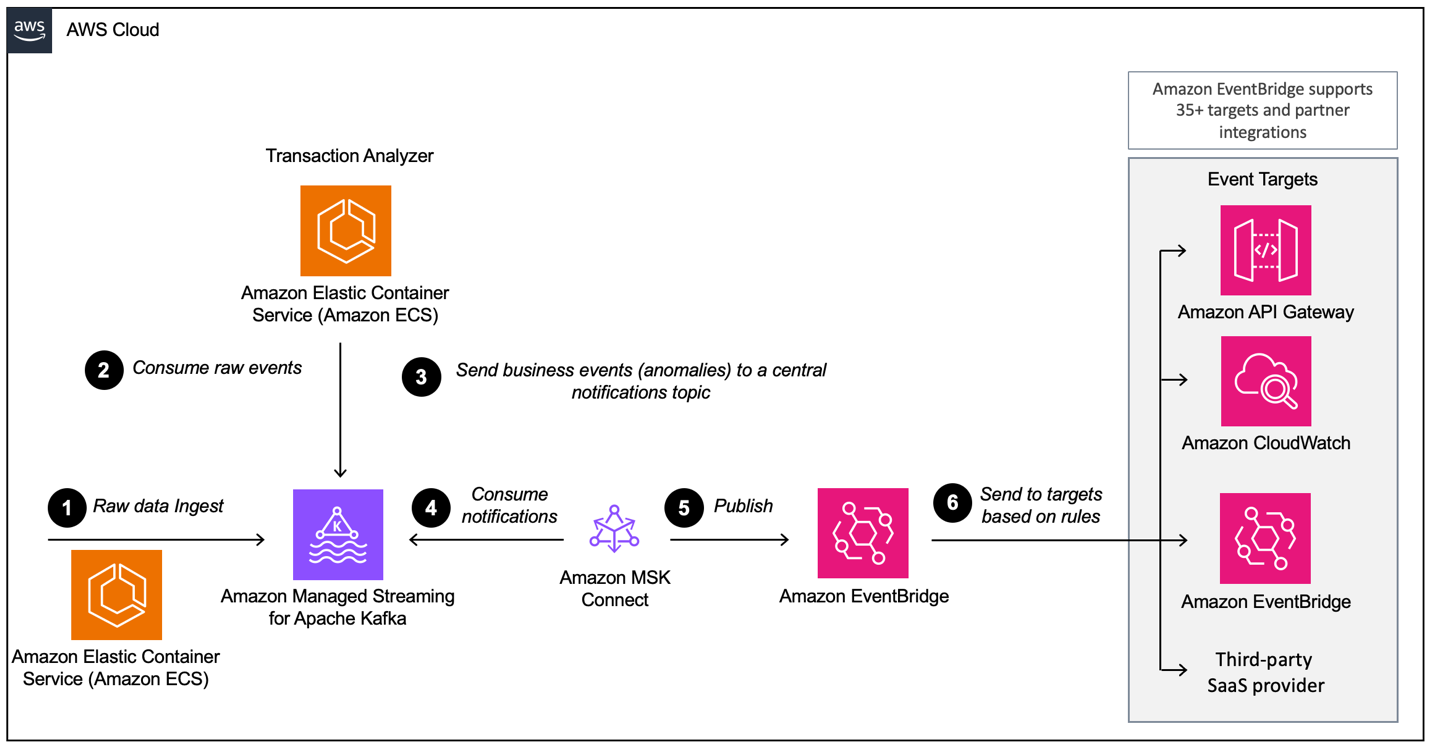
Ejemplo de una arquitectura orientada a eventos con Amazon MSK y Amazon EventBridge. Fuente de la imagen: AWS
Si estás interesado en aprovechar Python en tus flujos de trabajo de canalización de datos, echa un vistazo a nuestro curso Introducción a AWS Boto en Python.
Mejores prácticas para usar AWS MSK
AWS MSK es relativamente fácil de configurar y comenzar a usar de inmediato. Sin embargo, algunas mejores prácticas esenciales mejorarán el rendimiento de tus clústeres y te ahorrarán tiempo más adelante.
Ajusta el tamaño de tu clúster
Necesitarás elegir la cantidad adecuada de particiones por broker y el número correcto de brokers por clúster.
Varios factores pueden influir en tus decisiones aquí; sin embargo, AWS ha proporcionado algunas recomendaciones y recursos útiles para guiarte a través de este proceso.
Además, AWS ofrece una hoja de cálculo de tamaño y precios fácil de usar para ayudarte a estimar el tamaño adecuado de tu clúster y los costos asociados de usar AWS MSK en comparación con un clúster de Kafka en EC2 autogestionado similar.
Construye clústeres altamente disponibles
AWS recomienda que configures tus clústeres para que sean altamente disponibles. Esto es especialmente importante al realizar una actualización (como actualizar la versión de Apache Kafka) o cuando AWS está reemplazando un broker.
Para garantizar que tus clústeres sean altamente disponibles, hay tres cosas que debes hacer:
- Configura tus clústeres en tres zonas de disponibilidad (también llamado clúster de tres zonas de disponibilidad).
- Establece el factor de replicación en 3 o más.
- Establece el número mínimo de réplicas en sincronía en RF-1.
Lo bueno de AWS es que se comprometen con SLAs estrictos para implementaciones en múltiples zonas de disponibilidad; de lo contrario, obtienes tus créditos de vuelta.
Monitorea el uso de disco y CPU
Dos métricas clave para monitorear a través de AWS CloudWatch son el uso de disco y CPU. Hacer esto no solo garantizará que tu sistema funcione sin problemas, sino que también ayudará a reducir costos.
La mejor manera de gestionar el uso del disco y los costos de almacenamiento asociados es configurar una alarma de CloudWatch que te alerte cuando el uso del disco supere un cierto valor, como el 85%, y ajustar tus políticas de retención. Establecer un tiempo de retención para los mensajes en tu registro puede ayudar mucho a liberar espacio en disco automáticamente.
Además, para mantener el rendimiento de tu clúster y evitar cuellos de botella, AWS recomienda que mantengas el uso total de CPU para tus brokers por debajo del 60%. Puedes monitorear esto utilizando AWS CloudWatch y luego tomar acciones correctivas al actualizar el tamaño de tu broker, por ejemplo.
Protege tus datos utilizando cifrado en tránsito
Por defecto, AWS cifra los datos en tránsito entre los brokers en tu clúster de MSK. Puedes desactivar esto si tu sistema está experimentando un alto uso de CPU o latencia. Sin embargo, se recomienda encarecidamente que mantengas el cifrado en tránsito habilitado en todo momento y encuentres otras formas de mejorar el rendimiento si ese es un problema para ti.
Consulta nuestro curso de Seguridad y Gestión de Costos de AWS para aprender más sobre cómo asegurar y optimizar tu entorno en la nube de AWS y gestionar costos y recursos en AWS.
Comparando AWS MSK con otras herramientas de streaming
Cuando decidimos qué herramienta es la mejor para un proyecto, a menudo necesitamos evaluar varias opciones. Aquí están las alternativas más comunes a AWS MSK y cómo se comparan.
AWS MSK vs Apache Kafka en EC2
El principal compromiso entre MSK y una opción auto-alojada usando EC2 es entre conveniencia y control: MSK te da menos que gestionar pero menos flexibilidad, mientras que EC2 te da control total pero requiere más trabajo.
AWS MSK maneja todas las tareas operativas complejas, con aprovisionamiento y configuración automáticos. La ventaja de esto es que no hay costos iniciales de infraestructura. También hay una integración perfecta con otros servicios de AWS y sólidas características de seguridad.
Usar Kafka en EC2, por otro lado, implica una configuración y configuración más manual, y también necesitas encargarte de todo el mantenimiento y actualizaciones tú mismo. Esto ofrece mucha más flexibilidad pero podría venir con más complejidad y costos operativos y puede requerir equipos más altamente calificados.
AWS MSK vs. Kinesis
Usa Kinesis para simplicidad y una integración profunda con AWS y MSK para compatibilidad con Kafka o más control sobre tu configuración de streaming.
Kinesis es una arquitectura completamente sin servidor que utiliza shards para el streaming de datos. AWS administra todo por ti. Sin embargo, hay límites de retención de datos de los que debes ser consciente. Kinesis es una gran solución para requisitos simples de streaming de datos.
AWS MSK se basa en el modelo de temas y particiones de Kafka, con una retención de datos virtualmente ilimitada, dependiendo de tu almacenamiento. Es una solución más flexible y personalizable de la que puedes migrar lejos de AWS si es necesario.
Si no estás familiarizado con Kinesis, tenemos un curso que te guiará sobre cómo trabajar con datos en tiempo real utilizando AWS Kinesis y Lambda.
AWS MSK vs. Confluent
Elige Confluent si necesitas funciones y soporte completos, y elige MSK si estás fuertemente comprometido con AWS y tienes experiencia en Kafka internamente.
Confluent tiene un amplio conjunto de funciones con muchos conectores integrados. Es una opción más costosa en general, pero ofrece un nivel gratuito con funciones limitadas. Confluent funciona bien para cargas de trabajo irregulares y tiene un proceso de implementación más sencillo.
En comparación, AWS es más simplificado y se enfoca en la funcionalidad central de Kafka. Para acceder a un conjunto de funciones más amplio, AWS MSK debe integrarse con otros servicios de AWS. Afortunadamente, esta integración es fluida. AWS MSK tiene un costo base más bajo y puede ser una buena opción para cargas de trabajo consistentes.
La siguiente tabla ofrece una comparación de AWS MSK y sus alternativas:
|
Característica |
AWS MSK |
Apache Kafka en EC2 |
Kinesis |
Confluent |
|
Despliegue |
Completamente gestionado |
Autogestionado en EC2 |
Completamente gestionado |
Completamente gestionado o autogestionado |
|
Facilidad de uso |
Fácil de configurar y gestionar |
Requiere configuración manual y escalado |
Configuración simple; nativo de AWS |
Interfaz de usuario amigable y herramientas avanzadas |
|
Escalabilidad |
Escalado automático con ajustes manuales |
Escalado manual |
Escalado transparente |
Escalado automático con flexibilidad |
|
Latencia |
Baja latencia |
Baja latencia |
Menor latencia para cargas pequeñas |
Comparable a MSK |
|
Soporte de protocolo |
Compatible con la API de Kafka |
Compatible con la API de Kafka |
Protocolo propietario de Kinesis |
API de Kafka y protocolos adicionales |
|
Retención de datos |
Configurable (hasta 7 días por defecto) |
Configurable |
Configurable (máximo 365 días) |
Altamente configurable |
|
Monitoreo y métricas |
Integrado con CloudWatch |
Requiere configuración personalizada |
Integrado con CloudWatch |
Herramientas avanzadas de monitoreo |
|
Costo |
Pago según uso |
Basado en el precio de la instancia EC2 |
Pago según uso |
Basado en suscripción |
|
Seguridad |
Funciones de seguridad integradas de AWS |
Debe configurar la seguridad manualmente |
Integrado con AWS IAM |
Funciones de seguridad completas |
|
Adecuación al caso de uso |
El mejor para usuarios de Kafka en el ecosistema de AWS |
Flexible, pero requiere mucho mantenimiento |
El mejor para aplicaciones nativas de AWS |
Usuarios avanzados de Kafka y empresas |
Cierre
Apache Kafka es la opción preferida para situaciones en las que se necesita una solución fiable a gran escala que no pueda permitirse la pérdida de datos y requiere la conexión de múltiples fuentes de datos o la creación de complejos flujos de datos. AWS MSK evita muchos de los dolores de cabeza al configurar y establecer clústeres de Kafka, permitiendo a los desarrolladores centrarse más en la construcción y mejora de aplicaciones en lugar de en la infraestructura.
Obtener una certificación de AWS es una excelente manera de iniciar tu carrera en AWS. ¡Puedes mejorar tus habilidades en AWS consultando nuestro catálogo de cursos y obteniendo experiencia práctica a través de proyectos!