













Muitas empresas estão optando por mudar para o AWS MSK para evitar as dores de cabeça operacionais associadas à gestão de clusters Apache Kafka.
Neste tutorial, iremos explorar as funcionalidades, benefícios e melhores práticas do AWS MSK. Também iremos passar pelos passos básicos para configurar o AWS MSK e ver como ele se compara a outros serviços populares, como Kinesis e Confluent.
O que é o AWS MSK?
Primeiramente, vamos entender o Apache Kafka e por que ele é tão útil para o streaming de dados.
O Apache Kafka é uma plataforma de streaming distribuída de código aberto que lida com fluxos de dados em tempo real e pode construir aplicativos orientados por eventos. Ele pode ingerir e processar dados em tempo real à medida que ocorrem.
De acordo com o site do Kafka, mais de 80% das empresas da Fortune 100 confiam e usam o Kafka.
Mais importante, o Kafka é escalável e muito rápido. Isso significa que ele pode lidar com muito mais dados do que caberia em apenas uma máquina e com latência super baixa.
Se você deseja aprender como criar, gerenciar e solucionar problemas do Kafka para streaming de dados, considere fazer o curso Introdução ao Kafka.
Qual é o melhor momento para usar o Apache Kafka?
- Quando você precisa lidar com quantidades massivas de dados em tempo real, como o tratamento de fluxos de dados de dispositivos IoT.
- Quando você precisa de processamento e análise imediatos de dados, como no rastreamento de atividades de usuários em tempo real ou em sistemas de detecção de fraudes.
- Em cenários de evento-sourcing nos quais você precisa de trilhas de auditoria com requisitos de conformidade e regulamentações.
No entanto, gerenciar instâncias do Kafka pode trazer muitas dores de cabeça. É aí que entra o AWS MSK.
![]()
Imagem do Autor
AWS MSK (Managed Streaming for Kafka) é um serviço totalmente gerenciado que cuida do provisionamento, configuração, escalonamento e manutenção de clusters Kafka. Você pode usá-lo para construir aplicativos que reagem a fluxos de dados instantaneamente.
Kafka é frequentemente usado como parte de uma configuração maior de processamento de dados, e o AWS MSK torna ainda mais fácil criar pipelines de dados em tempo real que movem dados entre diferentes sistemas.
Como funciona o Amazon MSK. Fonte da imagem: AWS
Se você é novo na AWS, considere fazer nosso curso de Introdução à AWS para se familiarizar com os conceitos básicos. Quando estiver pronto, você pode avançar para nosso curso de Tecnologia e Serviços de Nuvem da AWS para explorar o conjunto completo de serviços nos quais as empresas confiam.
Recursos da AWS MSK
O AWS MSK se destaca da concorrência por ser um serviço totalmente gerenciado. Você não precisa se preocupar em configurar servidores ou lidar com atualizações.
No entanto, há mais do que isso. Esses cinco recursos principais da AWS MSK fazem dela um investimento que vale a pena:
- O MSK é altamente disponível, e a AWS garante que os SLAs rigorosos sejam cumpridos. Ele substitui automaticamente componentes com falha sem interrupções para seus aplicativos.
- O MSK possui uma opção de escalonamento automático para armazenamento, de modo que cresce com suas necessidades automaticamente. Você também pode aumentar ou diminuir rapidamente seu armazenamento ou adicionar mais corretores conforme necessário.
- Em termos de segurança, o MSK é uma solução abrangente que fornece criptografia em repouso e em trânsito. Ele também se integra ao AWS IAM para controle de acesso.
- Se você já está usando o Kafka, pode migrar para o MSK sem alterar seu código, uma vez que o MSK suporta todas as APIs e ferramentas regulares do Kafka.
- O SK é uma opção econômica que não requer a contratação de uma equipe inteira de engenharia para monitorar e gerenciar clusters. A AWS até se orgulha de que pode ser até 40% mais barata do que o Kafka auto-gerenciado.
Benefícios de usar o AWS MSK
Como já vimos, o AWS MSK oferece valor imediato devido à sua disponibilidade, escalabilidade, segurança e facilidade de integração. Essas vantagens principais o tornaram a escolha preferida para empresas que executam cargas de trabalho Kafka na nuvem.
O AWS MSK resolve quatro desafios críticos que todo projeto de streaming de dados enfrenta:
- O MSK é um serviço totalmente gerenciado, permitindo que você se concentre na construção de aplicações em vez de gerenciar infraestrutura.
- O MSK é altamente disponível e confiável, o que se torna cada vez mais crítico atualmente, já que os usuários esperam acesso 24/7 a serviços e aplicações.
- O MSK possui capacidades de segurança abrangentes e críticas.
- O MSK possui integração nativa com a AWS, o que torna muito mais fácil construir soluções completas de dados em streaming dentro do ecossistema da AWS.
Configurando o AWS MSK
Para começar com o AWS MSK, primeiro, crie sua conta na AWS. Se for a primeira vez que estiver usando a AWS, aprenda como configurar e configurar sua conta na AWS com nosso tutorial abrangente.
Entre no Console de Gerenciamento da AWS e abra o console do MSK. Clique em “Criar cluster” para iniciar o processo de configuração.

Começando com o AWS MSK. Fonte da imagem: AWS
Selecione “Criação rápida” para as configurações padrão e, em seguida, insira um nome descritivo para o cluster.
A partir daí, você tem muitas opções adicionais para selecionar, que dependem das suas próprias necessidades para o seu cluster. Aqui está uma visão geral rápida das escolhas:
- Tipo de cluster: “Provisionado” ou “Sem servidor”
- Versão do Apache Kafka
- Tipo de broker: “Padrão” ou “Express”
- Tamanho do broker
- Volume de armazenamento EBS
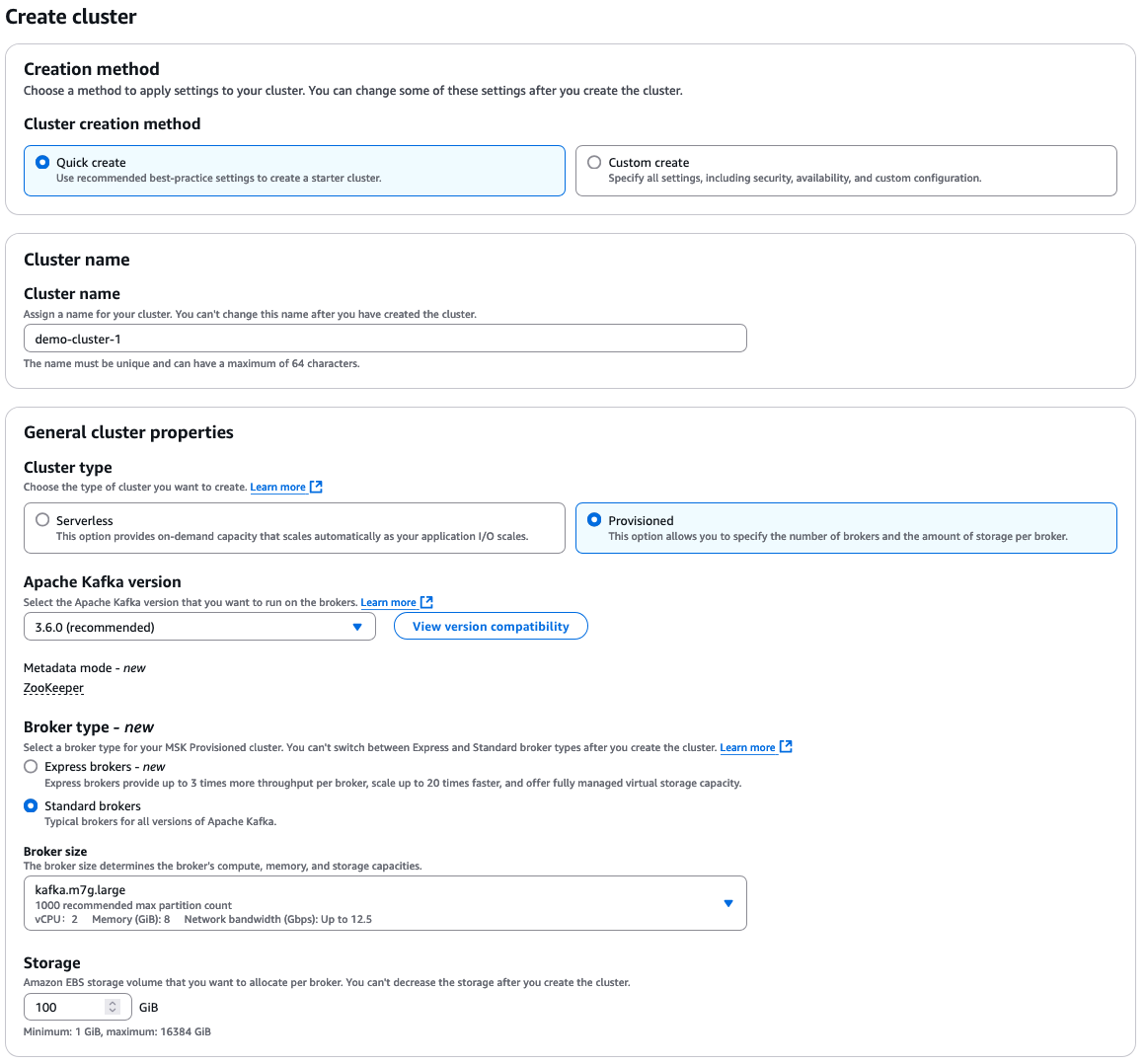
Opções de configuração do AWS MSK
O cluster é sempre criado dentro de uma VPC da Amazon. Você pode optar por usar a VPC padrão ou configurar e especificar uma VPC personalizada.
Agora, você só precisa aguardar a ativação do seu cluster, o que pode levar de 15 a 30 minutos. Você pode monitorar o status do seu cluster na página de resumo do cluster, onde verá o status mudar de “Criando” para “Ativo”.
Ingestão e Processamento de Dados com AWS MSK
Uma vez que seu cluster MSK esteja configurado, você precisará criar uma máquina cliente para produzir e consumir dados em um ou mais tópicos. Como o Apache Kafka se integra tão bem com muitos produtores de dados (como sites, dispositivos IoT, instâncias Amazon EC2, etc.), o MSK também compartilha esse benefício.
O Apache Kafka organiza dados em estruturas chamadas tópicos. Cada tópico é composto por uma ou muitas partições. Partições são o grau de paralelismo no Apache Kafka. Os dados são distribuídos entre os brokers usando particionamento de dados.
Termos-chave a conhecer ao lidar com clusters do Apache Kafka:
- Tópicos são a forma fundamental de organizar dados no Kafka.
- Produtores são aplicações que publicam dados nos tópicos – geram e escrevem dados no Kafka. Eles escrevem dados em tópicos e partições específicos.
- Consumidores são aplicativos que leem e processam dados de tópicos. Eles puxam dados dos tópicos aos quais estão inscritos.
Ao construir uma arquitetura orientada a eventos com AWS MSK, é necessário configurar várias camadas, sendo o MSK o principal componente de ingestão de dados. Aqui está uma visão geral das camadas que podem ser necessárias:
- Configuração de ingestão de dados
- Camada de processamento
- Camada de armazenamento
- Camada de análise
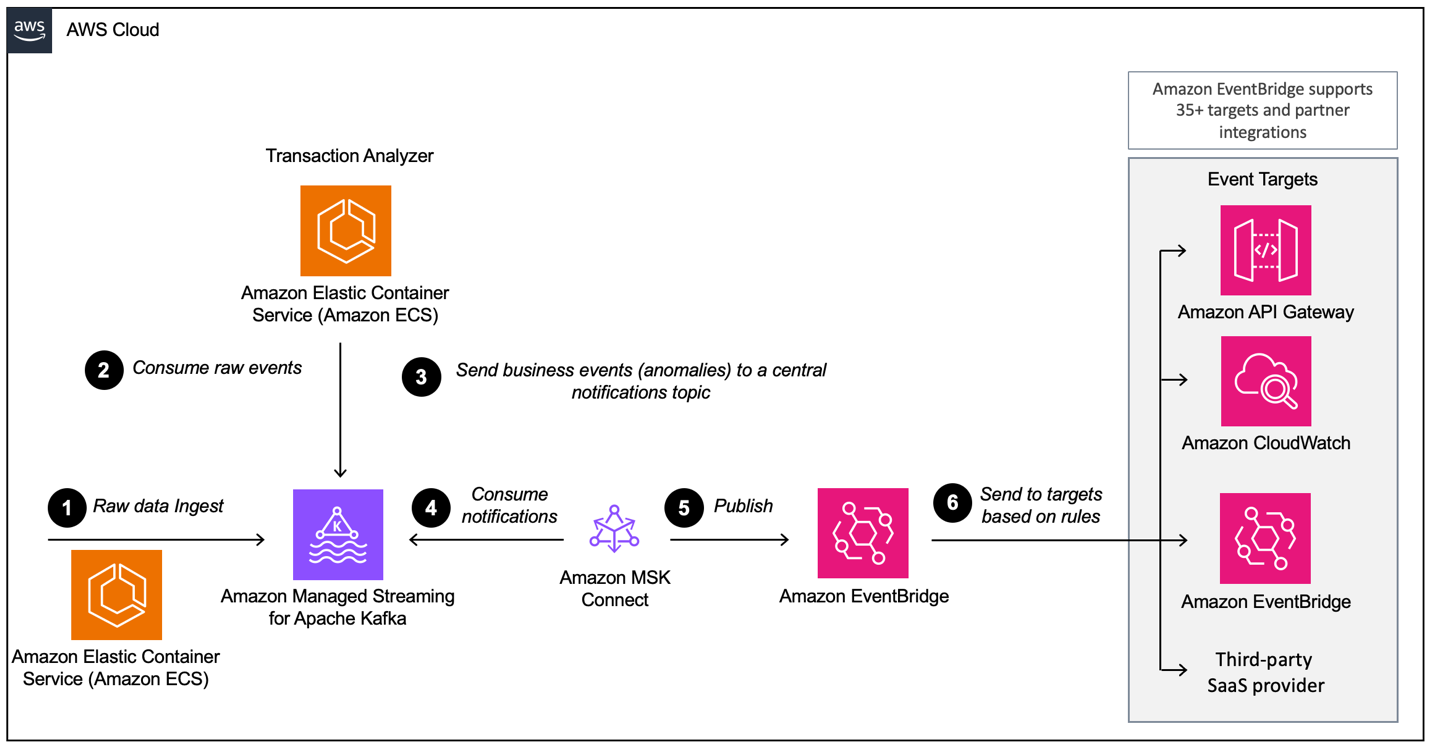
Exemplo de uma arquitetura orientada a eventos com Amazon MSK e Amazon EventBridge. Fonte da imagem: AWS
Se você está interessado em aproveitar o Python em seus workflows de pipeline de dados, confira nosso Introdução ao AWS Boto em Python curso.
Melhores Práticas para Usar AWS MSK
AWS MSK é relativamente simples de configurar e começar a usar imediatamente. No entanto, algumas práticas recomendadas essenciais melhorarão o desempenho de seus clusters e economizarão tempo mais adiante.
Dimensione corretamente seu cluster
Você precisará escolher o número certo de partições por broker e o número certo de brokers por cluster.
Vários fatores podem influenciar suas decisões aqui; no entanto, a AWS forneceu algumas recomendações e recursos úteis para orientá-lo neste processo.
Além disso, a AWS fornece uma planilha de dimensionamento e precificação fácil de usar para ajudá-lo a estimar o tamanho correto do seu cluster e os custos associados ao uso do AWS MSK versus um cluster Kafka EC2 auto-gerenciado semelhante.
Construa clusters altamente disponíveis
A AWS recomenda que você configure seus clusters para serem altamente disponíveis. Isso é especialmente importante ao realizar uma atualização (como atualizar a versão do Apache Kafka) ou quando a AWS está substituindo um broker.
Para garantir que seus clusters sejam altamente disponíveis, há três coisas que você deve fazer:
- Configure seus clusters em três zonas de disponibilidade (também chamado de cluster de três AZ).
- Defina o fator de replicação como 3 ou mais.
- Defina o número mínimo de réplicas em sincronia como RF-1.
A grande vantagem do AWS é que eles se comprometem a manter SLAs rigorosos para implantações multi-AZ; caso contrário, você recebe seus créditos de volta.
Monitore o uso de disco e CPU
Dupla métricas chave a serem monitoradas através do AWS CloudWatch são o uso de disco e CPU. Fazer isso não apenas garantirá que seu sistema funcione sem problemas, mas também ajudará a manter os custos baixos.
A melhor maneira de gerenciar o uso de disco e os custos de armazenamento associados é configurar um alarme do CloudWatch que o alerte quando o uso de disco exceder um certo valor, como 85%, e ajustar suas políticas de retenção. Definir um tempo de retenção para mensagens em seu log pode ajudar significativamente a liberar espaço em disco automaticamente.
Além disso, para manter o desempenho de seu cluster e evitar gargalos, a AWS recomenda que você mantenha o uso total de CPU de seus brokers abaixo de 60%. Você pode monitorar isso usando o AWS CloudWatch e, em seguida, tomar medidas corretivas, como atualizar o tamanho do seu broker, por exemplo.
Proteja seus dados usando criptografia em trânsito
Por padrão, a AWS criptografa dados em trânsito entre brokers em seu cluster MSK. Você pode desativar isso se seu sistema estiver enfrentando alto uso de CPU ou latência. No entanto, é altamente recomendável que você mantenha a criptografia em trânsito ativada o tempo todo e encontre outras maneiras de melhorar o desempenho se isso for um problema para você.
Confira nosso curso de Segurança e Gestão de Custos da AWS para saber mais sobre como proteger e otimizar seu ambiente de nuvem AWS e gerenciar custos e recursos na AWS.
Comparando o AWS MSK a Outras Ferramentas de Streaming
Ao decidir qual ferramenta é a melhor para um projeto, muitas vezes precisamos avaliar várias opções. Aqui estão as alternativas mais comuns ao AWS MSK e como elas se comparam.
AWS MSK vs Apache Kafka no EC2
A principal troca entre o MSK e uma opção auto-hospedada usando EC2 é entre conveniência e controle: o MSK oferece menos para gerenciar, mas menos flexibilidade, enquanto o EC2 oferece controle total, mas requer mais trabalho.
O AWS MSK lida com todas as tarefas operacionais complexas, com provisionamento e configuração automáticos. A vantagem disso é que não há custos de infraestrutura iniciais. Também há integração perfeita com outros serviços da AWS e recursos de segurança robustos.
Usar Kafka no EC2, por outro lado, envolve mais configuração e instalação manual, e você também precisa gerenciar toda a manutenção e atualizações por conta própria. Isso oferece muito mais flexibilidade, mas pode trazer mais complexidade e custos operacionais e pode exigir equipes mais altamente qualificadas.
AWS MSK vs. Kinesis
Use Kinesis pela simplicidade e profunda integração com a AWS e MSK pela compatibilidade com Kafka ou mais controle sobre sua configuração de streaming.
Kinesis é uma arquitetura completamente sem servidor que usa fragmentos para streaming de dados. A AWS gerencia tudo para você. No entanto, há limites de retenção de dados a serem observados. Kinesis é uma ótima solução para requisitos simples de streaming de dados.
AWS MSK se baseia no modelo de tópicos e partições do Kafka, com retenção de dados virtualmente ilimitada, dependendo do seu armazenamento. É uma solução mais flexível e personalizável que você pode migrar para fora da AWS, se necessário.
Se você não está familiarizado com o Kinesis, temos um curso que guia você no trabalho com dados em tempo real usando AWS Kinesis e Lambda.
AWS MSK vs. Confluent
Escolha Confluent se você precisa de recursos abrangentes e suporte, e escolha MSK se você está fortemente envolvido com a AWS e tem experiência em Kafka internamente.
O Confluent tem um conjunto de recursos ricos com muitos conectores integrados. É uma opção mais cara no geral, mas oferece um nível gratuito com recursos limitados. O Confluent funciona bem para cargas de trabalho com picos e tem um processo de implantação mais fácil.
Em comparação, a AWS é mais simplificada e foca na funcionalidade principal do Kafka. Para ter acesso a um conjunto de recursos mais estendido, o AWS MSK deve ser integrado com outros serviços da AWS. Felizmente, essa integração é tranquila. O AWS MSK tem um custo base mais baixo e pode ser uma boa opção para cargas de trabalho consistentes.
A tabela a seguir oferece uma comparação entre o AWS MSK e suas alternativas:
|
Recurso |
AWS MSK |
Apache Kafka na EC2 |
Kinesis |
Confluent |
|
Implantação |
Completamente gerenciado |
Autogerenciado na EC2 |
Completamente gerenciado |
Completamente gerenciado ou autogerenciado |
|
Facilidade de uso |
Fácil de configurar e gerenciar |
Requer configuração e escalonamento manuais |
Configuração simples; nativo da AWS |
Interface amigável e ferramentas avançadas |
|
Escalabilidade |
Autoescalonamento com ajustes manuais |
Escalonamento manual |
Escalonamento sem interrupções |
Autoescalonamento com flexibilidade |
|
Latência |
Baixa latência |
Baixa latência |
Latência menor para pequenas cargas |
Comparável ao MSK |
|
Suporte a protocolo |
Compatível com a API Kafka |
Compatível com a API Kafka |
Protocolo Kinesis proprietário |
API Kafka e protocolos adicionais |
|
Retenção de dados |
Configurável (até 7 dias por padrão) |
Configurável |
Configurável (máx. 365 dias) |
Altamente configurável |
|
Monitoramento e métricas |
Integrado com CloudWatch |
Requer configuração personalizada |
Integrado com CloudWatch |
Ferramentas avançadas de monitoramento |
|
Custo |
Pague conforme o uso |
Baseado na precificação de instâncias EC2 |
Pague conforme o uso |
Baseado em assinatura |
|
Segurança |
Recursos de segurança integrados da AWS |
Necessita configurar a segurança manualmente |
Integrado com AWS IAM |
Recursos de segurança abrangentes |
|
Adequação ao caso de uso |
Melhor para usuários de Kafka no ecossistema da AWS |
Flexível, mas requer manutenção intensiva |
Melhor para aplicativos nativos da AWS |
Usuários avançados de Kafka e empresas |
Considerações Finais
O Apache Kafka é a escolha ideal para situações em que você precisa de uma solução confiável em larga escala, que não pode se dar ao luxo de perder dados e requer a conexão de várias fontes de dados ou a construção de pipelines de dados complexos. O AWS MSK evita muitas das dores de cabeça na configuração de clusters Kafka, permitindo que os desenvolvedores se concentrem mais na construção e melhoria de aplicativos em vez da infraestrutura.
Obter uma certificação AWS é uma excelente maneira de iniciar sua carreira na AWS. Você pode desenvolver suas habilidades na AWS conferindo nosso catálogo de cursos e obtendo experiência prática por meio de projetos!