













Many companies are choosing to switch to AWS MSK to avoid the operational headaches associated with managing Apache Kafka clusters.
In this tutorial, we will explore AWS MSK’s features, benefits, and best practices. We will also go over the basic steps for setting up AWS MSK and see how it compares to other popular services such as Kinesis and Confluent.
What is AWS MSK?
First, let’s understand Apache Kafka and why it’s so useful for data streaming.
Apache Kafka is an open-sourced distributed streaming platform that handles real-time data streams and can build event-driven apps. It can ingest and process streaming data as it happens.
According to Kafka’s website, over 80% of Fortune 100 companies trust and use Kafka.
Most importantly, Kafka is scalable and very fast. This means it can handle way more data than what would fit on just one machine and with super low latency.
If you’d like to learn how to create, manage, and troubleshoot Kafka for data streaming, consider taking the Introduction to Kafka course.
When is the best time to use Apache Kafka?
- When you need to handle massive amounts of data in real time, such as handling IoT device data streams.
- When you need immediate data processing and analysis, such as with live user activity tracking or fraud detection systems.
- In event-sourcing scenarios where you need audit trails with compliance requirements and regulations.
However, managing Kafka instances can come with a lot of headaches. This is where AWS MSK comes in.

Image by Author
AWS MSK (Managed Streaming for Kafka) is a fully managed service that handles the provisioning, configuration, scaling, and maintenance of Kafka clusters. You can use it to build apps that react to data streams instantly.
Kafka is often used as part of a bigger data processing setup, and AWS MSK makes it even easier to create real-time data pipelines that move data between different systems.
How Amazon MSK works. Image source: AWS
If you’re new to AWS, consider taking our Introduction to AWS course to get familiar with the basics. When you’re ready, you can move on to our AWS Cloud Technology and Services course to explore the full suite of services that businesses rely on.
Features of AWS MSK
AWS MSK stands out from the competition because it is a fully managed service. You don’t have to worry about setting up servers or dealing with updates.
However, there’s more to it than that. These five key features of AWS MSK make it a worthwhile investment:
- MSK is highly available, and AWS guarantees that strict SLAs are met. It automatically replaces failed components without downtime for your apps.
- MSK has an auto-scaling option for storage, so it grows with your needs automatically. You can also quickly scale up or down your storage or add more brokers as needed.
- In terms of security, MSK is a comprehensive solution that provides encryption at rest and in transit. It also integrates with AWS IAM for access control.
- If you’re already using Kafka, you can move to MSK without changing your code since MSK supports all the regular Kafka APIs and tools.
- MSK is a cost-effective option that doesn’t require hiring an entire engineering team to monitor and manage clusters. AWS even boasts that it can be up to 40% cheaper than self-managed Kafka.
Benefits of using AWS MSK
As we have seen already, AWS MSK delivers immediate value due to its availability, scalability, security, and ease of integration. These core advantages have made it the go-to choice for companies running Kafka workloads in the cloud.
AWS MSK solves four critical challenges that every data streaming project faces:
- MSK is a fully managed service, allowing you to focus on building applications instead of managing infrastructure.
- MSK is highly available and reliable, which is becoming increasingly critical nowadays, as users expect 24/7 access to services and applications.
- MSK has critical comprehensive security capabilities.
- MSK has native AWS integration, making it much easier to build complete streaming data solutions within the AWS ecosystem.
Setting Up AWS MSK
To get started with AWS MSK, first, create your AWS account. If it’s your first time using AWS, learn how to set up and configure your AWS account with our comprehensive tutorial.
Sign in to the AWS Management Console and open the MSK console. Click “Create cluster” to start the setup process.

Getting started with AWS MSK. Image source: AWS
Select “Quick create” for default settings, then enter a descriptive cluster name.
From there, you have many additional options to select, which all depend on your own requirements for your cluster. Here’s a quick overview of the choices:
- Cluster type: “Provisioned” or “Serverless”
- Apache Kafka version
- Broker type: “Standard” or “Express”
- Broker size
- EBS storage volume
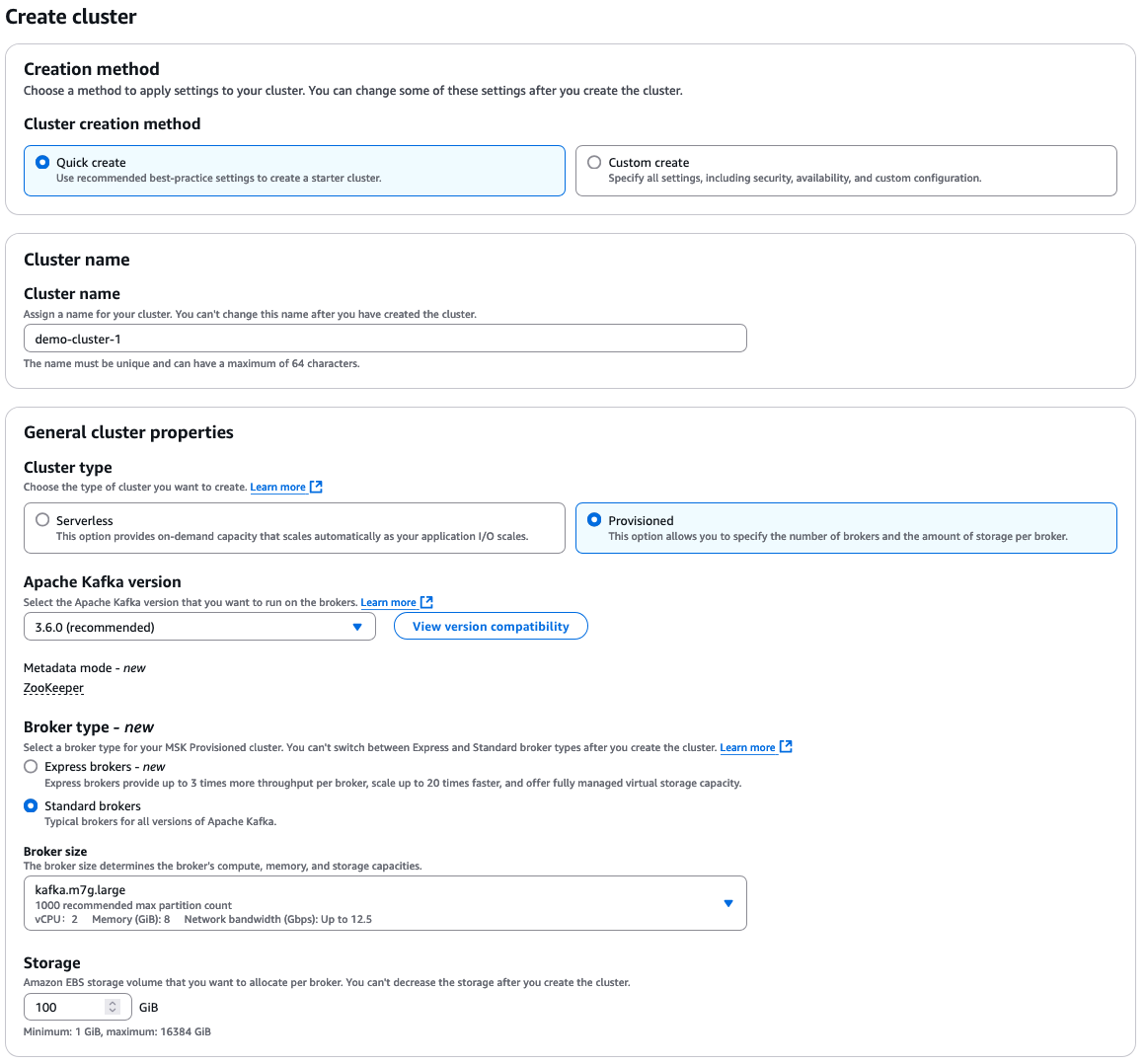
AWS MSK configuration options
The cluster is always created within an Amazon VPC. You can choose to use the default VPC or configure and specify a custom VPC.
Now, you just need to wait for your cluster to get activated, which can take 15 to 30 minutes. You can monitor the status of your cluster from the cluster summary page, where you will see the status change from “Creating” to “Active”.
Ingesting and Processing Data with AWS MSK
Once your MSK cluster is set up, you’ll need to create a client machine to produce and consume data across one or more topics. Since Apache Kafka integrates so well with many data producers (such as websites, IoT devices, Amazon EC2 instances, etc.), MSK also shares this benefit.
Apache Kafka organizes data in structures called topics. Each topic consists of single or many partitions. Partitions are the degree of parallelism in Apache Kafka. The data is distributed across brokers using data partitioning.
Key terms to know when dealing with Apache Kafka clusters:
- Topics are the fundamental way of organizing data in Kafka.
- Producers are applications that publish data to topics—they generate and write data to Kafka. They write data on specific topics and partitions.
- Consumers are applications that read and process data from topics. They pull data from topics to which they are subscribed.
When building an event-driven architecture with AWS MSK, you need to configure several layers, of which MSK is the main data ingestion component. Here’s an overview of the layers that may be required:
- Data ingestion setup
- Processing layer
- Storage layer
- Analytics layer
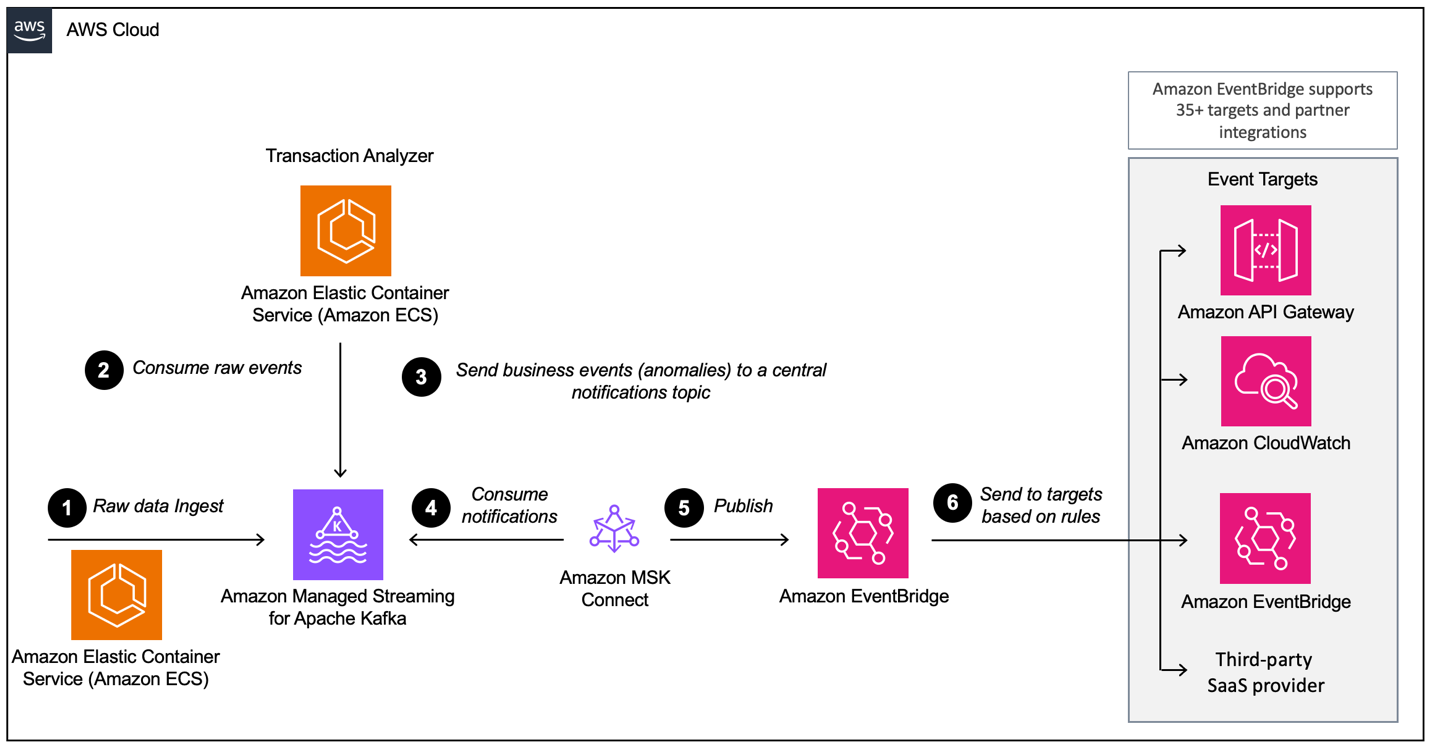
Example of an event-driven architecture with Amazon MSK and Amazon EventBridge. Image source: AWS
If you’re interested in leveraging Python in your data pipeline workflows, check out our Introduction to AWS Boto in Python course.
Best Practices for Using AWS MSK
AWS MSK is relatively simple to set up and start using right away. However, some essential best practices will improve the performance of your clusters and save you time later down the road.
Right-size your cluster
You will need to choose the right number of partitions per broker and the right number of brokers per cluster.
A number of factors can influence your decisions here; however, AWS has provided some handy recommendations and resources to guide you through this process.
In addition, AWS provides an easy-to-use sizing and pricing spreadsheet to help you estimate the right size of your cluster and the associated costs of using AWS MSK versus a similar self-managed EC2 Kafka cluster.
Build highly available clusters
AWS recommends that you set up your clusters to be highly available. This is especially important when performing an update (such as updating the Apache Kafka version) or when AWS is replacing a broker.
To ensure that your clusters are highly available, there are three things you must do:
- Set up your clusters across three availability zones (also called a three-AZ cluster).
- Set the replication factor to 3 or more.
- Set the minimum number of in-sync replicas to RF-1.
The great thing about AWS is that they commit to strict SLAs for multi-AZ deployments; otherwise, you get your credits back.
Monitor disk and CPU usage
Two key metrics to monitor through AWS CloudWatch are disk and CPU usage. Doing this will not only ensure that your system runs smoothly but will also help to keep costs down.
The best way to manage disk usage and the associated storage costs is to set up a CloudWatch alarm that alerts you when disk usage exceeds a certain value, such as 85%, and to adjust your retention policies. Setting a retention time for messages in your log can go a long way toward helping free up disk space automatically.
Additionally, to maintain the performance of your cluster and avoid bottlenecks, AWS recommends that you maintain the total CPU usage for your brokers under 60%. You can monitor this using AWS CloudWatch and then take corrective action by updating your broker size, for example.
Protect your data using encryption in transit
By default, AWS encrypts data in transit between brokers in your MSK cluster. You can disable this if your system is experiencing high CPU usage or latency. However, it is strongly recommended that you keep in-transit encryption enabled at all times and find other ways of improving performance if that is a problem for you.
Check out our AWS Security and Cost Management course to learn more about how to secure and optimize your AWS cloud environment and manage costs and resources in AWS.
Comparing AWS MSK to Other Streaming Tools
When deciding which tool is best for a project, we often need to evaluate several options. Here are the most common alternatives to AWS MSK and how they compare.
AWS MSK vs Apache Kafka on EC2
The main trade-off between MSK and a self-hosted option using EC2 is between convenience and control: MSK gives you less to manage but less flexibility, while EC2 gives you complete control but requires more work.
AWS MSK handles all the complex operational tasks, with automatic provisioning and configuration. The upside to this is that there are no upfront infrastructure costs. There is also seamless integration with other AWS services and robust security features.
Using Kafka on EC2, on the other hand, involves more manual setup and configuration, and you also need to handle all maintenance and updates yourself. This offers much more flexibility but could come with more complexity and operational costs and may require more highly skilled teams.
AWS MSK vs. Kinesis
Use Kinesis for simplicity and deep AWS integration and MSK for Kafka compatibility or more control over your streaming setup.
Kinesis is a completely serverless architecture that uses shards for data streaming. AWS manages everything for you. However, there are data retention limits to be aware of. Kinesis is a great solution for simple data streaming requirements.
AWS MSK relies on Kafka’s topic and partition model, with virtually unlimited data retention, depending on your storage. It is a more flexible and customizable solution that you can migrate away from AWS if needed.
If you’re not familiar with Kinesis, we have a course that walks you through working with streaming data using AWS Kinesis and Lambda.
AWS MSK vs. Confluent
Choose Confluent if you need comprehensive features and support, and choose MSK if you’re heavily invested in AWS and have Kafka expertise in-house.
Confluent has a rich feature set with a lot of built-in connectors. It is a more expensive option overall but does offer a free tier with limited features. Confluent works well for spiky workloads and has an easier deployment process.
In comparison, AWS is more streamlined and focuses on core Kafka functionality. To get access to a more extended feature set, AWS MSK must be integrated with other AWS services. Luckily, this integration is seamless. AWS MSK has a lower base cost and can be a good option for consistent workloads.
The following table offers a comparison of AWS MSK and its alternatives:
|
Feature |
AWS MSK |
Apache Kafka on EC2 |
Kinesis |
Confluent |
|
Deployment |
Fully managed |
Self-managed on EC2 |
Fully managed |
Fully managed or self-managed |
|
Ease of use |
Easy to set up and manage |
Requires manual setup and scaling |
Simple setup; AWS-native |
User-friendly UI and advanced tools |
|
Scalability |
Auto-scaling with manual adjustments |
Manual scaling |
Seamless scaling |
Auto-scaling with flexibility |
|
Latency |
Low latency |
Low latency |
Lower latency for small payloads |
Comparable to MSK |
|
Protocol support |
Kafka API compatible |
Kafka API compatible |
Proprietary Kinesis protocol |
Kafka API and additional protocols |
|
Data retention |
Configurable (up to 7 days default) |
Configurable |
Configurable (max 365 days) |
Highly configurable |
|
Monitoring and metrics |
Integrated with CloudWatch |
Requires custom setup |
Integrated with CloudWatch |
Advanced monitoring tools |
|
Cost |
Pay-as-you-go |
Based on EC2 instance pricing |
Pay-as-you-go |
Subscription-based |
|
Security |
Built-in AWS security features |
Must configure security manually |
Integrated with AWS IAM |
Comprehensive security features |
|
Use case suitability |
Best for Kafka users in AWS ecosystem |
Flexible, but high maintenance |
Best for AWS-native apps |
Advanced Kafka users and enterprises |
Closing Thoughts
Apache Kafka is the go-to choice for situations where you need a large-scale, reliable solution that cannot afford data loss and requires connecting multiple data sources or building complex data pipelines. AWS MSK prevents many of the headaches of setting up and configuring Kafka clusters, allowing developers to focus more on building and improving applications instead of infrastructure.
Getting an AWS certification is an excellent way to start your AWS career. You can build your AWS skills by checking out our course catalog and getting hands-on experience through projects!