













多くの企業がApache Kafkaクラスタを管理する際に発生する運用上の問題を回避するために、AWS MSKに切り替えることを選択しています。
このチュートリアルでは、AWS MSKの機能、利点、およびベストプラクティスについて探求します。また、AWS MSKの基本的な設定手順を説明し、KinesisやConfluentなど他の人気のあるサービスと比較します。
AWS MSKとは何ですか?
まずは、Apache Kafkaとデータストリーミングにおいてなぜ役立つのかを理解しましょう。
Apache Kafkaは、リアルタイムのデータストリームを処理し、イベント駆動型アプリケーションを構築するためのオープンソースの分散ストリーミングプラットフォームです。データストリームを受信し処理することができます。
Kafkaのウェブサイトによると、フォーチュン100社のうち80%以上がKafkaを信頼して利用しています。
最も重要なのは、Kafkaはスケーラブルで非常に高速であるということです。これは、単一のマシンに収まるデータよりもはるかに多くのデータを処理し、超低レイテンシーで処理できることを意味します。
データストリーミングのためにKafkaを作成、管理、トラブルシューティングする方法を学びたい場合は、Kafka入門コースを受講してみてください。
Apache Kafkaを使用するのに最適な時期はいつですか?
- リアルタイムで大量のデータを処理する必要がある場合、例えば、IoTデバイスのデータストリームを処理する場合。
- ライブユーザーアクティビティの追跡や不正検知システムなど、即時のデータ処理と分析が必要な場合。
- 監査トレイルが必要でコンプライアンス要件と規制を満たす必要があるイベントソーシングシナリオで。
ただし、Kafkaインスタンスの管理には多くの頭痛が伴う場合があります。これがAWS MSKの役割です。
![]()
著者による画像
AWS MSK(Managed Streaming for Kafka)は、Kafkaクラスターのプロビジョニング、構成、スケーリング、およびメンテナンスを処理する完全マネージドサービスです。これを使用して、データストリームに即座に反応するアプリを構築できます。
Kafkaはしばしばより大規模なデータ処理セットアップの一部として使用され、AWS MSKを使用すると、さまざまなシステム間でデータを移動するリアルタイムデータパイプラインをさらに簡単に作成できます。
Amazon MSKの動作方法。画像の出典:AWS
AWS に初めての方は、基本を把握するために Introduction to AWS コースを受講することを検討してください。準備が整ったら、ビジネスが依存するさまざまなサービスを探索するために AWS Cloud Technology and Services コースに進んでください。
AWS MSK の特徴
AWS MSK は完全に管理されたサービスであるため、サーバーの設定やアップデートについて心配する必要はありません。
ただし、それだけではありません。AWS MSK のこれらの5つの主要な機能は、それを価値ある投資にします:
- MSK は高い可用性を持ち、AWS は厳格な SLA を満たすことを保証しています。アプリケーションにダウンタイムをもたらさず、自動的に障害が発生したコンポーネントを置き換えます。
- MSKにはストレージの自動スケーリングオプションがあり、必要に応じて自動的に成長します。必要に応じてストレージを迅速にスケーリングしたり、ブローカーを追加したりすることもできます。
- セキュリティ面では、MSKはデータ静止時および転送時の暗号化を提供する包括的なソリューションです。また、アクセス制御のためにAWS IAMと統合されています。
- Kafkaをすでに使用している場合、MSKに移行してもコードを変更する必要はありません。というのも、MSKは通常のKafka APIやツールをサポートしているからです。
- MSKは、エンジニアリングチーム全体を雇う必要がない、費用対効果の高いオプションです。AWSは、それが自己管理型のKafkaよりも最大40%安いことがあると自負しています。
AWS MSKの利点
AWS MSKは、可用性、拡張性、セキュリティ、統合の容易さによる即座の価値を提供していることがすでにわかっています。これらの主要な利点により、クラウドでKafkaワークロードを実行している企業の選択肢となっています。
AWS MSKは、データストリーミングプロジェクトが直面する4つの重要な課題を解決しています。
- MSKは完全に管理されたサービスであり、インフラストラクチャを管理する代わりにアプリケーションの構築に集中できます。
- MSKは高い可用性と信頼性を備えており、ユーザーはサービスやアプリケーションへの24時間365日のアクセスを期待している現在、ますます重要になっています。
- MSKには重要な包括的なセキュリティ機能が備わっています。
- MSKはネイティブのAWS統合を持っており、AWSエコシステム内で完全なストリーミングデータソリューションを構築するのがより簡単になります。
AWS MSKのセットアップ
AWS MSKを始めるには、まずAWSアカウントを作成してください。AWSを初めて使用する場合は、AWSアカウントの設定および構成方法を詳しく説明した当社のチュートリアルをご覧ください。
AWS Management Consoleにサインインし、MSKコンソールを開きます。セットアッププロセスを開始するには、「クラスターの作成」をクリックします。

AWS MSKの始め方。画像の出所: AWS
デフォルトの設定で「クイック作成」を選択し、説明的なクラスター名を入力します。
そこから、クラスターの要件に応じて選択できるさまざまな追加オプションがあります。以下は選択肢の概要です:
- クラスタータイプ:「Provisioned」または「Serverless」
- Apache Kafkaバージョン
- ブローカータイプ:「Standard」または「Express」
- ブローカーサイズ
- EBSストレージボリューム
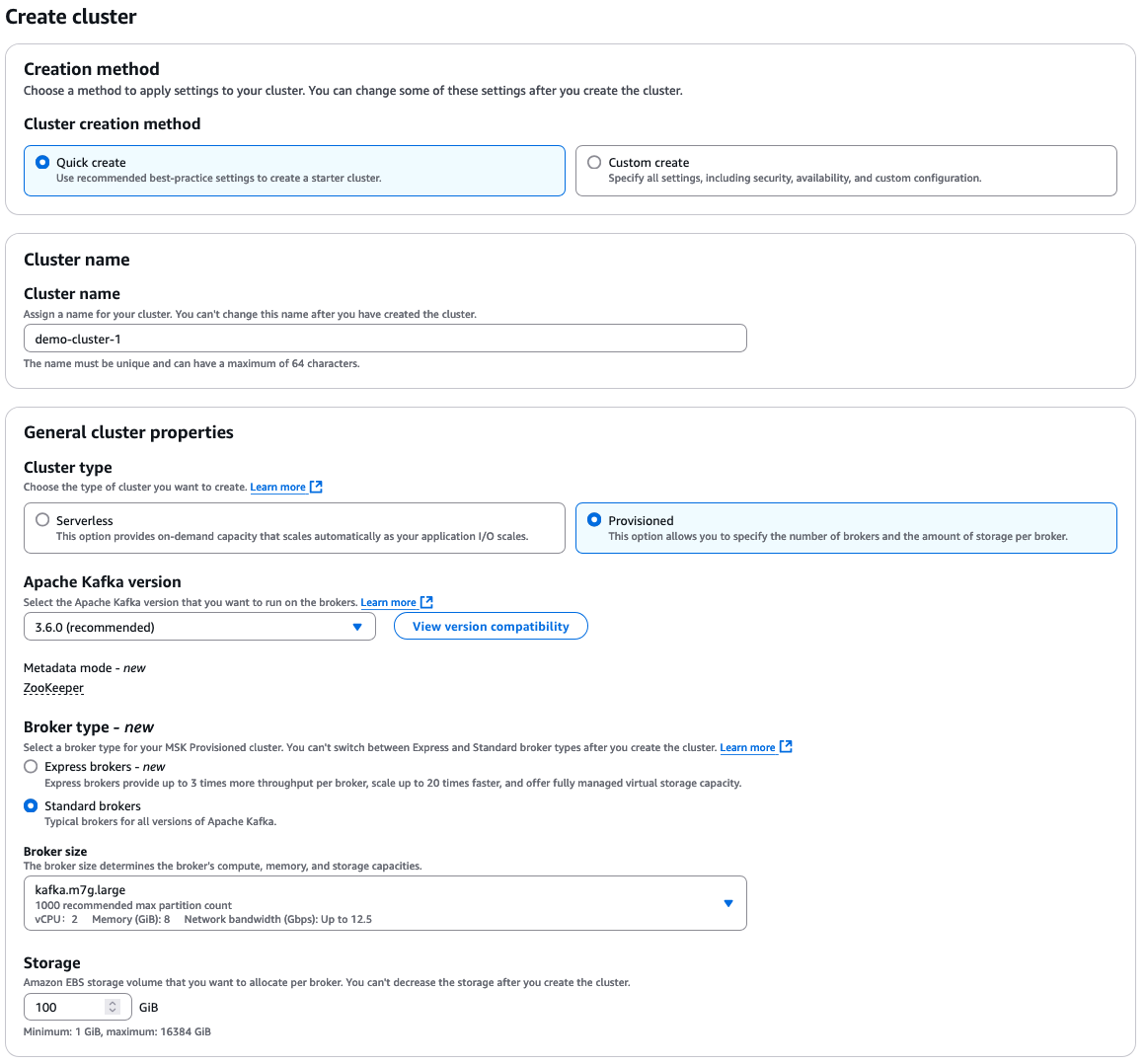
AWS MSK構成オプション
クラスターは常にAmazon VPC内で作成されます。デフォルトのVPCを使用するか、カスタムVPCを構成および指定することができます。
今、クラスターがアクティブ化されるのを待つだけです。このプロセスには15〜30分かかる場合があります。クラスターサマリーページからクラスターのステータスを監視し、「作成中」から「アクティブ」に変更されるのを確認できます。
AWS MSKを使用したデータの取り込みと処理
MSKクラスターが設定されたら、1つ以上のトピックを介してデータを生成および消費するクライアントマシンを作成する必要があります。Apache Kafkaは多くのデータプロデューサー(ウェブサイト、IoTデバイス、Amazon EC2インスタンスなど)と非常にうまく統合されているため、MSKもこの利点を共有しています。
Apache Kafkaはトピックと呼ばれる構造でデータを整理します。各トピックは1つまたは複数のパーティションで構成されています。パーティションはApache Kafkaにおける並列処理の度合いを示します。データはデータパーティショニングを使用してブローカー間に分散されます。
Apache Kafkaクラスタを取り扱う際に知っておくべきキーワード:
- トピックはKafkaでデータを整理する基本的な方法です。
- プロデューサーはトピックにデータを公開するアプリケーションです。彼らはKafkaにデータを生成して書き込みます。指定されたトピックとパーティションにデータを書き込みます。
- コンシューマーは、トピックからデータを読み取り処理するアプリケーションです。購読しているトピックからデータを取得します。
AWS MSKを使用してイベント駆動型アーキテクチャを構築する際には、MSKが主要なデータ取り込みコンポーネントである複数のレイヤーを構成する必要があります。以下に必要なレイヤーの概要を示します。
- データ取り込み設定
- 処理レイヤー
- ストレージレイヤー
- 分析レイヤー
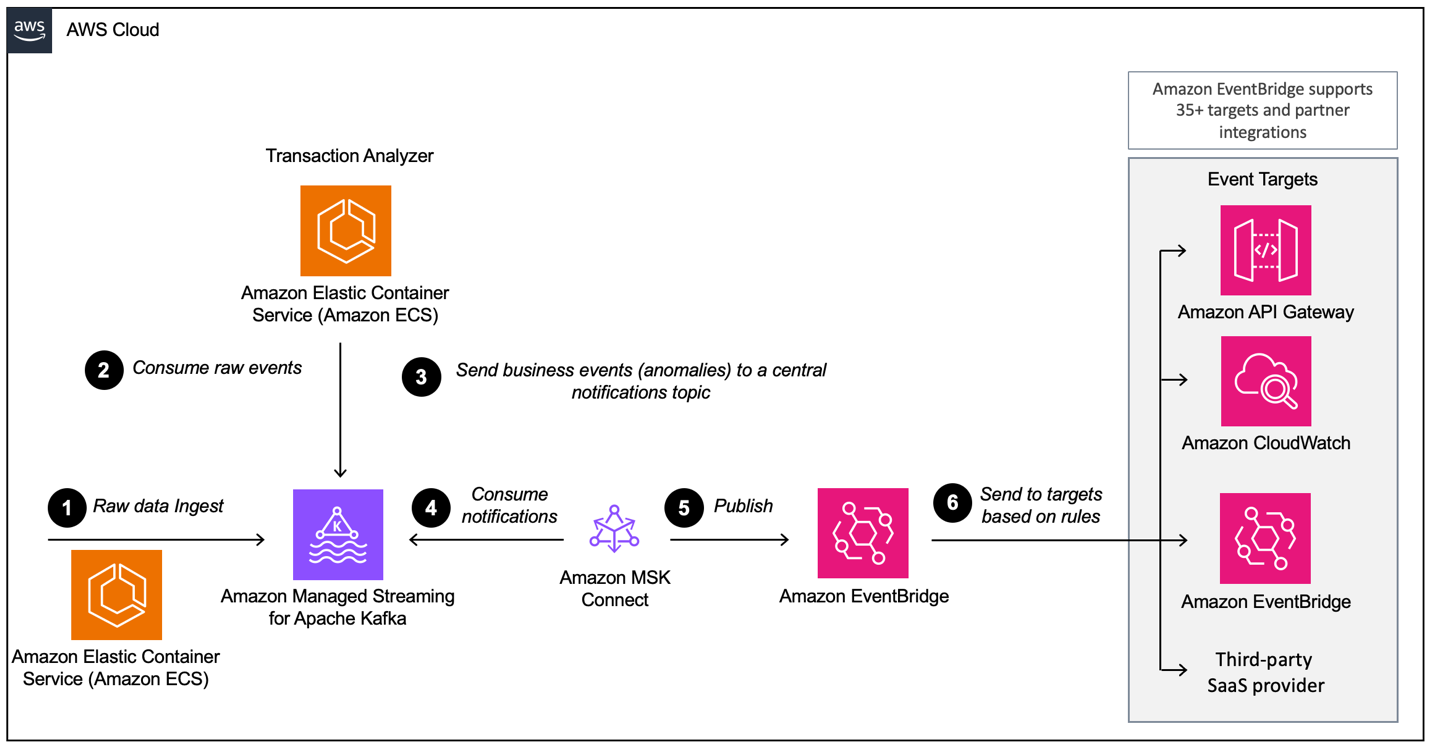
Amazon MSKとAmazon EventBridgeを使用したイベント駆動アーキテクチャの例。画像ソース:AWS
データパイプラインワークフローでPythonを活用したい場合は、PythonでAWS Botoの導入コースをチェックしてみてください。
AWS MSKの使用に関するベストプラクティス
AWS MSKは比較的簡単に設定してすぐに使用できます。ただし、いくつかの重要なベストプラクティスを遵守すると、クラスターのパフォーマンスが向上し、後で時間を節約できます。
クラスターの適切なサイズを決定する
ブローカーごとの適切なパーティション数とクラスターごとの適切なブローカー数を選択する必要があります。
さまざまな要因がここであなたの意思決定に影響を与える可能性があります。ただし、AWSはこのプロセスを案内するための便利な推奨事項とリソースを提供しています。
さらに、AWSは使いやすいサイジングおよび価格設定スプレッドシートを提供し、AWS MSKの使用コストと類似の自己管理型EC2 Kafkaクラスターの正しいサイズを見積もるのに役立ちます。
高可用性クラスターを構築する
AWSは、クラスターを高可用性に設定することをお勧めしています。これは、更新(たとえばApache Kafkaバージョンの更新)を実行する場合やAWSがブローカーを置き換える場合に特に重要です。
クラスターが高可用性であることを確認するには、次の3つのことを行う必要があります。
- 3つの可用性ゾーンにわたるクラスタを設定します(3つのAZクラスタとも呼ばれます)。
- レプリケーションファクタを3以上に設定します。
- 最小の同期レプリカ数をRF-1に設定します。
AWSの素晴らしい点は、マルチAZ展開に厳格なSLAを提供していることです。さもなければ、クレジットを取り戻すことができます。
ディスク使用率とCPU使用率を監視します
AWS CloudWatchを介して監視すべき2つの主要なメトリクスはディスク使用率とCPU使用率です。これにより、システムがスムーズに稼働するだけでなく、コストを抑えるのに役立ちます。
ディスク使用量と関連するストレージコストを管理する最良の方法は、ディスク使用量が85%など特定の値を超えたときにアラームを設定し、保持ポリシーを調整することです。ログのメッセージの保持期間を設定することで、ディスクスペースを自動的に解放するのに役立ちます。
さらに、クラスターのパフォーマンスを維持し、ボトルネックを回避するために、AWSはブローカーの合計CPU使用率を60%未満に保つことを推奨しています。これをAWS CloudWatchを使用して監視し、たとえばブローカーサイズを更新することで、適切な対策を取ることができます。
データの保護には転送中の暗号化を使用します
AWSはデフォルトで、MSKクラスター内のブローカー間のデータを転送中に暗号化します。システムのCPU使用率や遅延が高い場合は、これを無効にすることができます。ただし、常に転送中の暗号化を有効にしておくことを強くお勧めし、パフォーマンスに問題がある場合は他の方法で改善することを検討してください。
AWSセキュリティとコスト管理コースをご覧いただき、AWSクラウド環境をセキュリティで保護し、最適化し、コストやリソースを管理する方法について詳しく学んでください。
AWS MSKと他のストリーミングツールを比較
プロジェクトに最適なツールを選択する際には、いくつかの選択肢を評価する必要があります。以下に、AWS MSKとの最も一般的な代替手段とその比較を示します。
AWS MSK vs Apache Kafka on EC2
MSKとEC2を使用したセルフホストオプションとの主なトレードオフは、利便性とコントロールの間です。MSKは管理するものが少なく、柔軟性が少ない一方、EC2は完全な制御を提供しますが、より多くの作業が必要です。
AWS MSKはすべての複雑な運用タスクを処理し、自動プロビジョニングと構成を提供します。これにより、最初のインフラコストがかからないという利点があります。また、他のAWSサービスとのシームレスな統合や堅牢なセキュリティ機能も備えています。
EC2でKafkaを使用する場合、より多くの手動設定と構成が必要であり、また、すべてのメンテナンスとアップデートを自分で処理する必要があります。これにより、はるかに柔軟性が増しますが、より複雑さと運用コストがかかる可能性があり、より高度なスキルを持つチームが必要になるかもしれません。
AWS MSK vs. Kinesis
KinesisはシンプルさとAWSとの深い統合を活用し、MSKはKafkaとの互換性やストリーミングセットアップのより多くの制御を提供するために使用します。
Kinesisは、データストリーミングにシャードを使用する完全にサーバーレスのアーキテクチャです。AWSがすべてを管理しますが、把握しておく必要があるデータ保持リミットがあります。Kinesisは、シンプルなデータストリーミング要件に適した素晴らしいソリューションです。
AWS MSKは、Kafkaのトピックとパーティションモデルに依存し、ストレージに応じてほぼ無制限のデータ保持を提供します。必要に応じてAWSから移行できるより柔軟でカスタマイズ可能なソリューションです。
Kinesisに慣れていない場合、AWS KinesisとLambdaを使用したストリーミングデータの取り扱いを紹介するコースがあります。
AWS MSK vs. Confluent
包括的な機能とサポートが必要な場合はConfluentを選択し、AWSに大規模な投資があり、社内にKafkaの専門知識がある場合はMSKを選択してください。
Confluentには多くの組み込みコネクタが備わった豊富な機能セットがあります。全体としてより高価なオプションですが、限られた機能を備えた無料ティアを提供しています。 Confluentはスパイキーなワークロードに適しており、より簡単な展開プロセスを持っています。
一方、AWSはより効率的で、コアのKafka機能に焦点を当てています。より拡張された機能セットにアクセスするには、AWS MSKを他のAWSサービスと統合する必要があります。幸いにも、この統合はシームレスです。 AWS MSKは基本コストが低く、一貫したワークロードに適したオプションです。
以下の表は、AWS MSKとその代替製品の比較を示しています:
|
機能 |
AWS MSK |
EC2上のApache Kafka |
Kinesis |
Confluent |
|
デプロイメント |
フルマネージド |
EC2上のセルフマネージド |
フルマネージド |
フルマネージドまたはセルフマネージド |
|
使いやすさ |
簡単にセットアップおよび管理可能 |
手動セットアップおよびスケーリングが必要 |
シンプルな設定; AWSネイティブ |
ユーザーフレンドリーなUIおよび高度なツール |
|
スケーラビリティ |
手動調整可能なオートスケーリング |
手動スケーリング |
シームレスなスケーリング |
柔軟性を持ったオートスケーリング |
|
遅延 |
低遅延 |
低遅延 |
小さなペイロード向けの低遅延 |
MSKに匹敵する |
|
プロトコルのサポート |
Kafka API互換 |
Kafka API互換 |
独自のKinesisプロトコル |
Kafka APIおよび追加プロトコル |
|
データ保持 |
設定可能(最大7日デフォルト) |
設定可能 |
設定可能(最大365日) |
高度に設定可能 |
|
監視とメトリクス |
CloudWatchと統合 |
カスタムセットアップが必要 |
CloudWatchと統合 |
高度な監視ツール |
|
コスト |
従量課金 |
EC2インスタンスの価格に基づく |
従量課金 |
サブスクリプションベースの |
|
セキュリティ |
組み込みのAWSセキュリティ機能 |
セキュリティを手動で設定する必要があります |
AWS IAMと統合 |
包括的なセキュリティ機能 |
|
ユースケースの適合性 |
AWSエコシステム内のKafkaユーザーに最適 |
柔軟性がありますが、メンテナンスが高い |
AWSネイティブアプリに最適 |
上級のKafkaユーザーや企業に最適 |
Closing Thoughts
Apache Kafkaは、データの損失を許容できず、複数のデータソースを接続したり複雑なデータパイプラインを構築する必要がある大規模で信頼性の高いソリューションが必要な場合の選択肢です。AWS MSKは、Kafkaクラスタを設定および構成する際の多くの頭痛を防ぎ、開発者がインフラストラクチャではなくアプリケーションの構築と改善により焦点を当てることを可能にします。
AWS認定を取得することは、AWSキャリアをスタートさせる優れた方法です。当社のコースカタログをチェックし、プロジェクトを通じて実践経験を積むことで、AWSスキルを構築することができます!