













Veel bedrijven kiezen ervoor om over te stappen naar AWS MSK om de operationele hoofdpijn te vermijden die gepaard gaat met het beheren van Apache Kafka-clusters.
In deze tutorial zullen we de functies, voordelen en beste praktijken van AWS MSK verkennen. We zullen ook de basisstappen doorlopen voor het opzetten van AWS MSK en bekijken hoe het zich verhoudt tot andere populaire diensten zoals Kinesis en Confluent.
Wat is AWS MSK?
Laten we eerst Apache Kafka begrijpen en waarom het zo nuttig is voor datastreaming.
Apache Kafka is een open-source gedistribueerd streamingplatform dat realtime datastromen verwerkt en event-gedreven apps kan bouwen. Het kan streamingdata verwerken terwijl het gebeurt.
Volgens de website van Kafka vertrouwt en gebruikt meer dan 80% van de Fortune 100 bedrijven Kafka.
Het belangrijkste is dat Kafka schaalbaar en zeer snel is. Dit betekent dat het veel meer gegevens kan verwerken dan wat op slechts één machine zou passen, en met een super lage latentie.
Als je wilt leren hoe je Kafka voor datastreaming kunt creëren, beheren en oplossen, overweeg dan om de Inleiding tot Kafka cursus te volgen.
Wanneer is de beste tijd om Apache Kafka te gebruiken?
- Wanneer je enorme hoeveelheden gegevens in real-time moet verwerken, zoals het verwerken van gegevensstromen van IoT-apparaten.
- Wanneer je onmiddellijke gegevensverwerking en analyse nodig hebt, zoals bij live gebruikersactiviteittracking of fraudedetectiesystemen.
- In scenario’s voor event-sourcing waar je audit trails nodig hebt met compliance-eisen en regelgeving.
Het beheren van Kafka-instanties kan echter veel hoofdpijn met zich meebrengen. Dit is waar AWS MSK in beeld komt.
![]()
Afbeelding door Auteur
AWS MSK (Managed Streaming for Kafka) is een volledig beheerde service die de provisioning, configuratie, schaling en onderhoud van Kafka-clusters afhandelt. Je kunt het gebruiken om apps te bouwen die direct reageren op datastromen.
Kafka wordt vaak gebruikt als onderdeel van een grotere gegevensverwerkingsopstelling, en AWS MSK maakt het nog eenvoudiger om realtime gegevenspijplijnen te creëren die gegevens tussen verschillende systemen verplaatsen.
Hoe Amazon MSK werkt. Afbeeldingsbron: AWS
Als je nieuw bent bij AWS, overweeg dan om onze Introductie tot AWS cursus te volgen om vertrouwd te raken met de basis. Wanneer je er klaar voor bent, kun je verder gaan met onze AWS Cloud Technologie en Diensten cursus om de volledige suite van diensten te verkennen waarop bedrijven vertrouwen.
Kenmerken van AWS MSK
AWS MSK onderscheidt zich van de concurrentie omdat het een volledig beheerde dienst is. Je hoeft je geen zorgen te maken over het opzetten van servers of het afhandelen van updates.
Echter, er is meer aan de hand dan dat. Deze vijf belangrijke kenmerken van AWS MSK maken het een waardevolle investering:
- MSK is zeer beschikbaar, en AWS garandeert dat strikte SLA’s worden nageleefd. Het vervangt automatisch defecte componenten zonder downtime voor je apps.
- MSK heeft een auto-scaling optie voor opslag, zodat het automatisch meegroeidt met uw behoeften. U kunt ook snel uw opslag vergroten of verkleinen of meer brokers toevoegen indien nodig.
- Op het gebied van beveiliging is MSK een uitgebreide oplossing die encryptie biedt in rust en tijdens verzending. Het integreert ook met AWS IAM voor toegangsbeheer.
- Als u al Kafka gebruikt, kunt u overstappen naar MSK zonder uw code te wijzigen, aangezien MSK alle reguliere Kafka-API’s en tools ondersteunt.
- MSK is een kosteneffectieve optie die geen heel engineeringteam vereist om clusters te monitoren en beheren. AWS beweert zelfs dat het tot 40% goedkoper kan zijn dan zelf beheerde Kafka.
Voordelen van het gebruik van AWS MSK
Zoals we al hebben gezien, biedt AWS MSK onmiddellijke waarde dankzij de beschikbaarheid, schaalbaarheid, beveiliging en het gemak van integratie. Deze kernvoordelen hebben het de favoriete keuze gemaakt voor bedrijven die Kafka-werkbelastingen in de cloud draaien.
AWS MSK lost vier kritieke uitdagingen op waar elk data-streamingproject mee te maken heeft:
- MSK is een volledig beheerde service, waardoor je je kunt concentreren op het bouwen van applicaties in plaats van het beheren van infrastructuur.
- MSK is zeer beschikbaar en betrouwbaar, wat tegenwoordig steeds kritischer wordt, aangezien gebruikers 24/7 toegang tot diensten en applicaties verwachten.
- MSK heeft essentiële uitgebreide beveiligingsmogelijkheden.
- MSK heeft een native AWS-integratie, waardoor het veel eenvoudiger wordt om complete streamingdata-oplossingen binnen het AWS-ecosysteem te bouwen.
AWS MSK Instellen
Om te beginnen met AWS MSK, maak eerst uw AWS-account aan. Als het uw eerste keer is dat u AWS gebruikt, leer dan hoe u uw AWS-account kunt instellen en configureren met onze uitgebreide tutorial.
Log in op de AWS Management Console en open de MSK-console. Klik op “Cluster aanmaken” om het installatieproces te starten.

Beginnen met AWS MSK. Afbeeldingsbron: AWS
Selecteer “Snelle creatie” voor de standaardinstellingen, voer vervolgens een beschrijvende clustern naam in.
Van daaruit heb je veel extra opties om te selecteren, die allemaal afhankelijk zijn van jouw eigen vereisten voor je cluster. Hier is een snel overzicht van de keuzes:
- Cluster type: “Provisioned” of “Serverless”
- Apache Kafka versie
- Broker type: “Standaard” of “Express”
- Broker grootte
- EBS opslagvolume
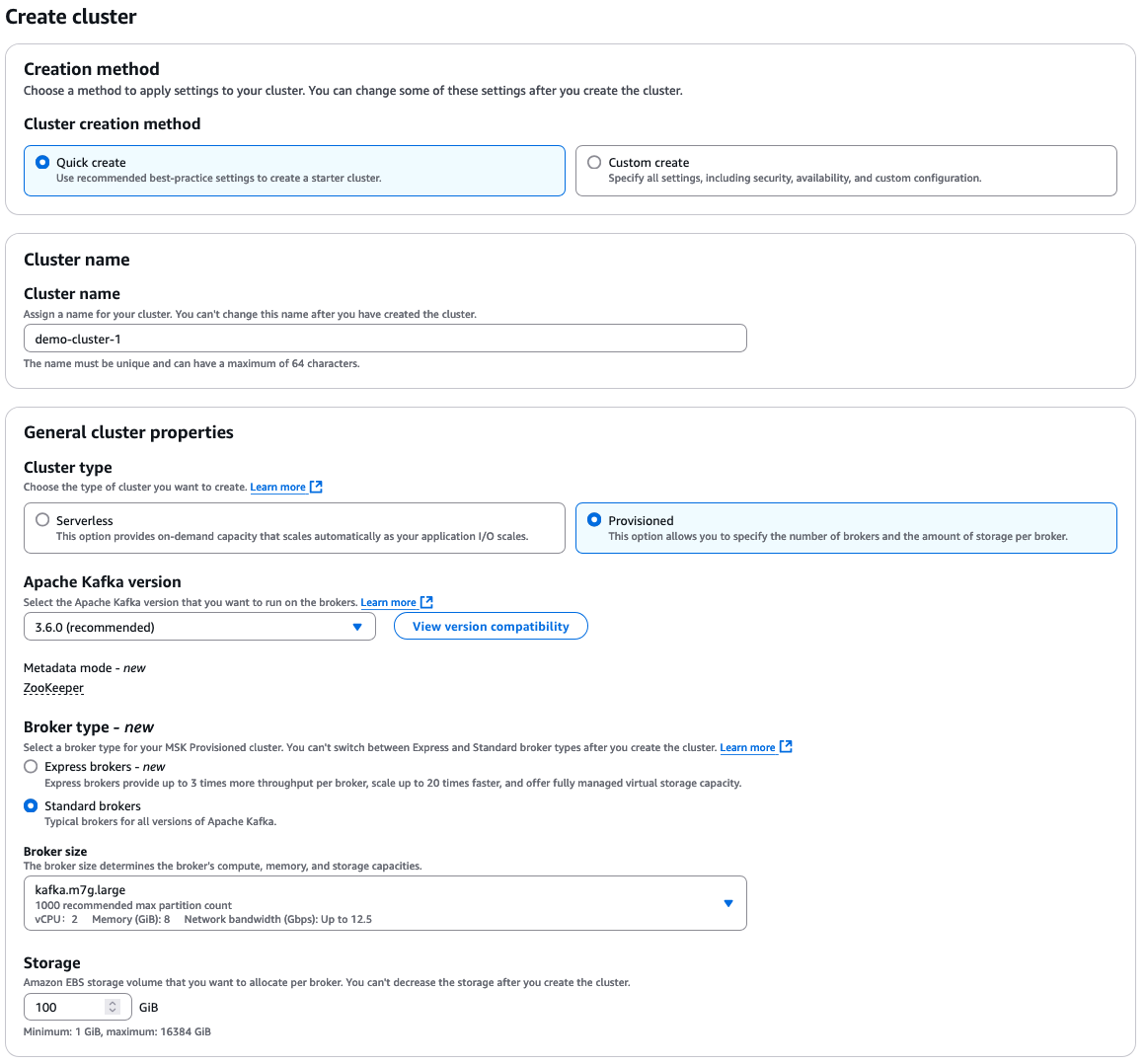
AWS MSK configuratieopties
Het cluster wordt altijd binnen een Amazon VPC aangemaakt. Je kunt ervoor kiezen om de standaard VPC te gebruiken of een aangepaste VPC te configureren en op te geven.
Nu hoef je alleen maar te wachten tot je cluster is geactiveerd, wat 15 tot 30 minuten kan duren. Je kunt de status van je cluster volgen vanaf de samenvattingspagina van het cluster, waar je de status ziet veranderen van “Aan het creëren” naar “Actief”.
Gegevens Ingestie en Verwerking met AWS MSK
Zodra je MSK-cluster is ingesteld, moet je een clientmachine maken om gegevens te produceren en te consumeren over een of meer onderwerpen. Aangezien Apache Kafka zo goed integreert met veel gegevensproducenten (zoals websites, IoT-apparaten, Amazon EC2-instanties, enz.), deelt MSK ook dit voordeel.
Apache Kafka organiseert gegevens in structuren die topics worden genoemd. Elk topic bestaat uit één of meerdere partities. Partities zijn de mate van parallelisme in Apache Kafka. De gegevens worden verdeeld over brokers door middel van gegevenspartionering.
Belangrijke termen om te kennen bij het werken met Apache Kafka-clusters:
- Topics zijn de fundamentele manier van het organiseren van gegevens in Kafka.
- Producers zijn toepassingen die gegevens naar topics publiceren – ze genereren en schrijven gegevens naar Kafka. Ze schrijven gegevens naar specifieke topics en partities.
- Consumenten zijn toepassingen die gegevens uit onderwerpen lezen en verwerken. Ze halen gegevens op van onderwerpen waarop ze zijn geabonneerd.
Bij het bouwen van een op gebeurtenissen gebaseerde architectuur met AWS MSK, moet u verschillende lagen configureren, waarvan MSK het belangrijkste gegevensinvoercomponent is. Hier is een overzicht van de lagen die mogelijk nodig zijn:
- Opzetten van gegevensinvoer
- Verwerkingslaag
- Opslaglaag
- Analyticslaag
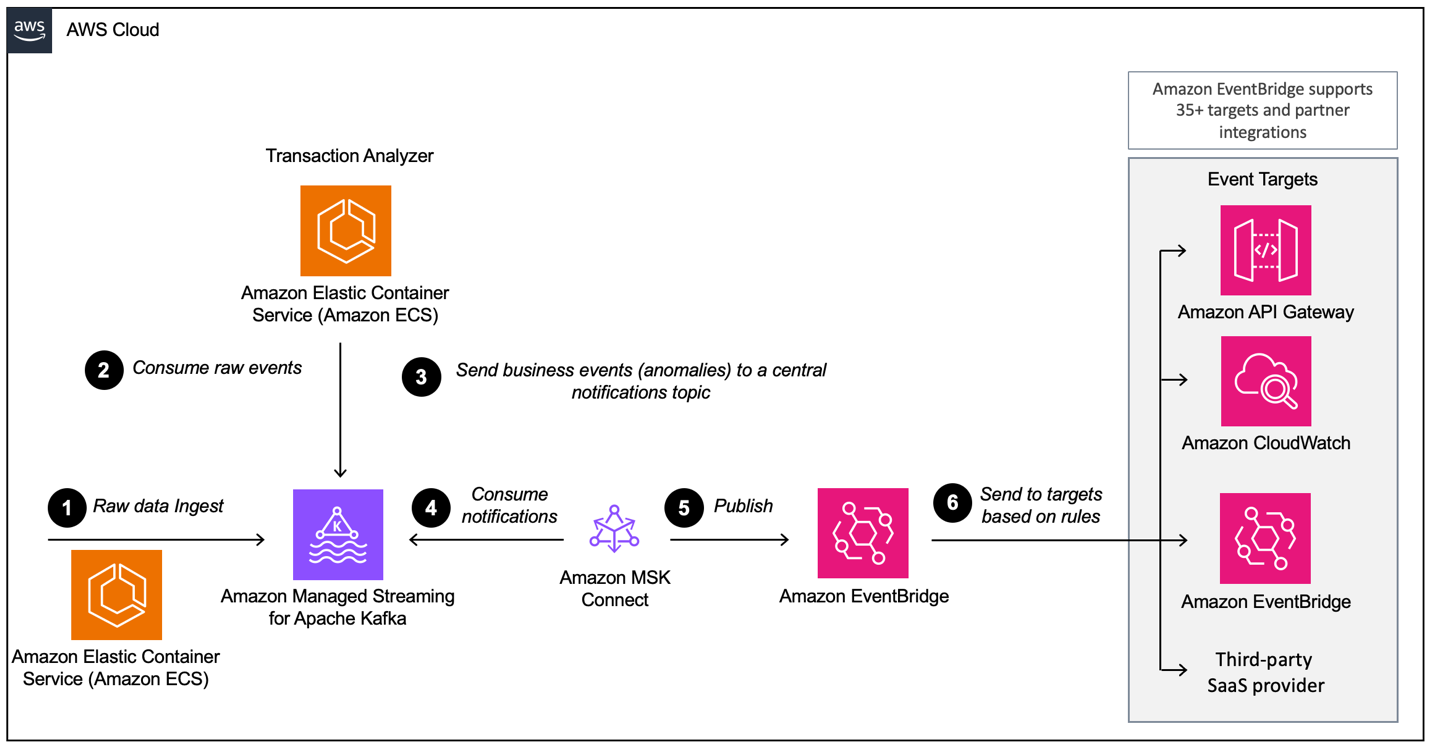
Voorbeeld van een gebeurtenisgestuurde architectuur met Amazon MSK en Amazon EventBridge.Afbeeldingsbron: AWS
Als je geïnteresseerd bent in het gebruik van Python in je datastream workflows, bekijk dan onze Introductie tot AWS Boto in Python cursus.
Beste praktijken voor het gebruik van AWS MSK
AWS MSK is relatief eenvoudig op te zetten en direct te gebruiken. Er zijn echter enkele essentiële beste praktijken die de prestaties van je clusters verbeteren en je later tijd besparen.
Kies de juiste grootte voor je cluster
Je moet het juiste aantal partities per broker en het juiste aantal brokers per cluster kiezen.
Een aantal factoren kunnen hier invloed hebben op uw beslissingen; echter, AWS heeft enkele handige aanbevelingen en bronnen verstrekt om u door dit proces te begeleiden.
Bovendien biedt AWS een eenvoudig te gebruiken dimensionerings- en prijsspreadsheet om u te helpen de juiste omvang van uw cluster en de bijbehorende kosten van het gebruik van AWS MSK versus een vergelijkbare zelfbeheerde EC2 Kafka-cluster te schatten.
Bouw zeer beschikbare clusters
AWS raadt aan om uw clusters zo in te stellen dat ze zeer beschikbaar zijn. Dit is vooral belangrijk bij het uitvoeren van een update (zoals het bijwerken van de Apache Kafka-versie) of wanneer AWS een broker vervangt.
Om ervoor te zorgen dat uw clusters zeer beschikbaar zijn, zijn er drie dingen die u moet doen:
- Stel je clusters in over drie beschikbaarheidszones (ook wel een drie-AZ cluster genoemd).
- Stel de replicatiefactor in op 3 of meer.
- Stel het minimumaantal in-sync replica’s in op RF-1.
Het geweldige aan AWS is dat ze zich houden aan strikte SLA’s voor multi-AZ-implementaties; anders krijg je je credits terug.
Monitor schijf- en CPU-gebruik
Twee belangrijke metingen om te monitoren via AWS CloudWatch zijn schijf- en CPU-gebruik. Dit zorgt er niet alleen voor dat je systeem soepel draait, maar helpt ook om de kosten laag te houden.
De beste manier om schijfgebruik en de bijbehorende opslagkosten te beheren, is door een CloudWatch-alarm in te stellen dat u waarschuwt wanneer het schijfgebruik een bepaalde waarde overschrijdt, zoals 85%, en uw retentiebeleid aan te passen. Het instellen van een retentietijd voor berichten in uw logboek kan aanzienlijk helpen bij het automatisch vrijmaken van schijfruimte.
Bovendien raadt AWS aan om de totale CPU-gebruik van uw brokers onder de 60% te houden om de prestaties van uw cluster te behouden en knelpunten te vermijden. U kunt dit monitoren met AWS CloudWatch en vervolgens corrigerende actie ondernemen door bijvoorbeeld de grootte van uw broker bij te werken.
Beveilig uw gegevens met versleuteling tijdens verzending
Standaard versleutelt AWS gegevens tijdens verzending tussen brokers in uw MSK-cluster. U kunt dit uitschakelen als uw systeem te kampen heeft met een hoge CPU-belasting of latentie. Het wordt echter ten zeerste aanbevolen om de versleuteling tijdens verzending te allen tijde ingeschakeld te houden en andere manieren te vinden om de prestaties te verbeteren als dat een probleem voor u is.
Bekijk onze cursus AWS Security and Cost Management om meer te leren over hoe u uw AWS-cloudomgeving kunt beveiligen en optimaliseren en kosten en resources in AWS kunt beheren.
Vergelijking van AWS MSK met andere streamingtools
Wanneer we beslissen welk gereedschap het beste is voor een project, moeten we vaak verschillende opties evalueren. Hier zijn de meest voorkomende alternatieven voor AWS MSK en hoe ze zich verhouden.
AWS MSK versus Apache Kafka op EC2
Het belangrijkste compromis tussen MSK en een zelfgehoste optie met EC2 is tussen gemak en controle: MSK geeft je minder om te beheren maar minder flexibiliteit, terwijl EC2 je volledige controle geeft maar meer werk vereist.
AWS MSK behandelt alle complexe operationele taken, met automatische provisioning en configuratie. Het voordeel hiervan is dat er geen infrastructuurkosten vooraf zijn. Er is ook naadloze integratie met andere AWS-services en robuuste beveiligingsfuncties.
Het gebruik van Kafka op EC2 vereist daarentegen meer handmatige setup en configuratie, en je moet ook zelf al het onderhoud en updates regelen. Dit biedt veel meer flexibiliteit maar kan gepaard gaan met meer complexiteit en operationele kosten en kan meer hoogopgeleide teams vereisen.
AWS MSK vs. Kinesis
Gebruik Kinesis voor eenvoud en diepe integratie met AWS en MSK voor Kafka-compatibiliteit of meer controle over je streaming setup.
Kinesis is een volledig serverloze architectuur die shards gebruikt voor data streaming. AWS beheert alles voor je. Er zijn echter beperkingen voor gegevensretentie waarvan je op de hoogte moet zijn. Kinesis is een geweldige oplossing voor eenvoudige data-streamingvereisten.
AWS MSK maakt gebruik van Kafka’s topic- en partitiemodel, met praktisch onbeperkte gegevensretentie, afhankelijk van je opslag. Het is een flexibelere en aanpasbare oplossing waar je vanaf AWS kunt migreren indien nodig.
Als je niet bekend bent met Kinesis, hebben we een cursus die je begeleidt bij het werken met streaming data met AWS Kinesis en Lambda.
AWS MSK vs. Confluent
Kies Confluent als je uitgebreide functies en ondersteuning nodig hebt, en kies MSK als je sterk geïnvesteerd bent in AWS en Kafka-expertise in huis hebt.
Confluent heeft een rijke set functies met veel ingebouwde connectors. Het is over het algemeen een duurdere optie, maar biedt wel een gratis niveau met beperkte functies. Confluent werkt goed voor piekbelastingen en heeft een gemakkelijker implementatieproces.
In vergelijking is AWS meer gestroomlijnd en richt het zich op de kernfunctionaliteit van Kafka. Om toegang te krijgen tot een uitgebreidere set functies, moet AWS MSK worden geïntegreerd met andere AWS-diensten. Gelukkig is deze integratie naadloos. AWS MSK heeft lagere basis kosten en kan een goede optie zijn voor consistente werkbelastingen.
De volgende tabel biedt een vergelijking van AWS MSK en zijn alternatieven:
|
Kenmerk |
AWS MSK |
Apache Kafka op EC2 |
Kinesis |
Confluent |
|
Implementatie |
Volledig beheerd |
Self-beheerd op EC2 |
Volledig beheerd |
Volledig beheerd of self-beheerd |
|
Gebruiksgemak |
Makkelijk op te zetten en beheren |
Vereist handmatige installatie en schaling |
Eenvoudige installatie; AWS-native |
Gebruiksvriendelijke UI en geavanceerde tools |
|
Schaalbaarheid |
Automatisch schalen met handmatige aanpassingen |
Handmatig schalen |
Naadloos schalen |
Automatisch schalen met flexibiliteit |
|
Latentie |
Lage latentie |
Lage latentie |
Lagere latentie voor kleine payloads |
Vergelijkbaar met MSK |
|
Protocolondersteuning |
Kafka API-compatibel |
Kafka API-compatibel |
Eigen Kinesis-protocol |
Kafka API en aanvullende protocollen |
|
Gegevensbewaring |
Configureerbaar (tot 7 dagen standaard) |
Configureerbaar |
Configureerbaar (maximaal 365 dagen) |
Zeer configureerbaar |
|
Monitoring en statistieken |
Geïntegreerd met CloudWatch |
Vereist aangepaste installatie |
Geïntegreerd met CloudWatch |
Geavanceerde monitoringtools |
|
Kosten |
Pay-as-you-go |
Gebaseerd op EC2-instantieprijzen |
Pay-as-you-go |
Abonnementgebaseerd |
|
Beveiliging |
Ingebouwde AWS-beveiligingsfuncties |
Moet beveiliging handmatig configureren |
Geïntegreerd met AWS IAM |
Uitgebreide beveiligingsfuncties |
|
Geschiktheid voor gebruikssituatie |
Beste voor Kafka-gebruikers in het AWS-ecosysteem |
Flexibel, maar veel onderhoud |
Beste voor AWS-native apps |
Gevorderde Kafka-gebruikers en bedrijven |
Closing Thoughts
Apache Kafka is de eerste keuze voor situaties waar je een grootschalige, betrouwbare oplossing nodig hebt die geen dataverlies kan veroorloven en waarbij het verbinden van meerdere databronnen of het bouwen van complexe datapipelines vereist is. AWS MSK voorkomt veel van de hoofdpijnen bij het opzetten en configureren van Kafka-clusters, waardoor ontwikkelaars zich meer kunnen richten op het bouwen en verbeteren van applicaties in plaats van op de infrastructuur.
Het behalen van een AWS-certificering is een uitstekende manier om je AWS-carrière te starten. Je kunt je AWS-vaardigheden opbouwen door ons cursusaanbod te bekijken en hands-on ervaring op te doen met projecten!