













파이썬 프로그래밍에서 NumPy와 Pandas는 수치 계산과 데이터 조작을 위한 가장 강력한 라이브러리 중 두 가지로 두드러지게 나타난다.
NumPy: 수치 계산의 기초
NumPy (Numerical Python)은 다차원 배열과 다양한 수학 함수를 지원하여 과학적 계산에 필수적이다.
- NumPy는 파이썬에서 수치 계산을 위한 가장 기본적인 패키지이다.
- NumPy가 수치 계산에 중요한 이유 중 하나는 대량의 데이터 배열에 대해 효율적으로 설계되어 있다는 것이다. 이에 대한 이유로는:
- 내부에서 데이터를 다른 내장 파이썬 객체와 독립적인 연속된 메모리 블록에 저장한다.
- “for” 루프가 필요하지 않고 전체 배열에 대한 복잡한 계산을 수행한다.
ndarray는 빠른 배열 지향 산술 연산과 유연한 브로드캐스팅 기능을 제공하는 효율적인 다차원 배열이다.- NumPy의
ndarray객체는 파이썬에서 대규모 데이터 집합을 위한 빠르고 유연한 컨테이너이다. - 배열을 사용하면 동일한 데이터 유형의 여러 항목을 저장할 수 있다. NumPy를 통해 수학 및 데이터 조작을 수행하는 데 편리한 기능을 제공하는 것이 배열 객체 주변의 기능이다.
NumPy에서의 작업
배열 생성:

배열 재구성:

슬라이싱 및 인덱싱:

산술 연산:
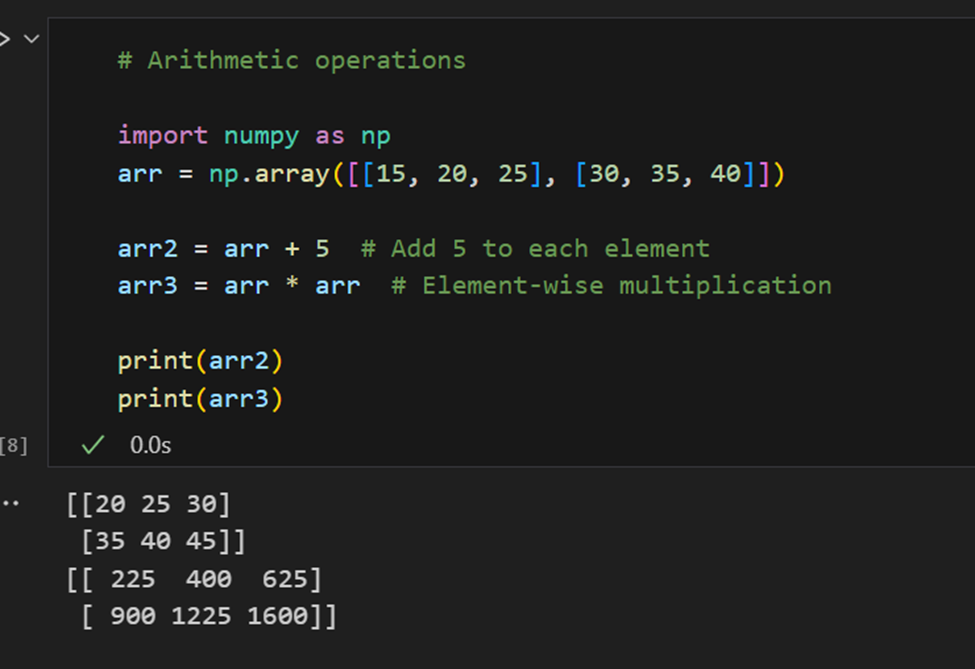
선형 대수:

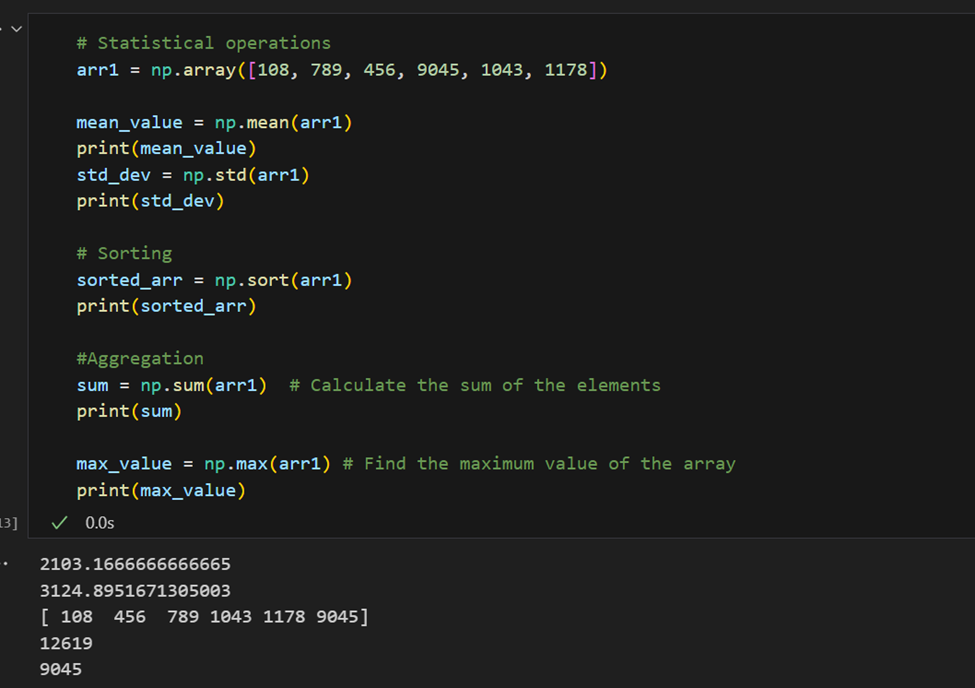
통계 작업:
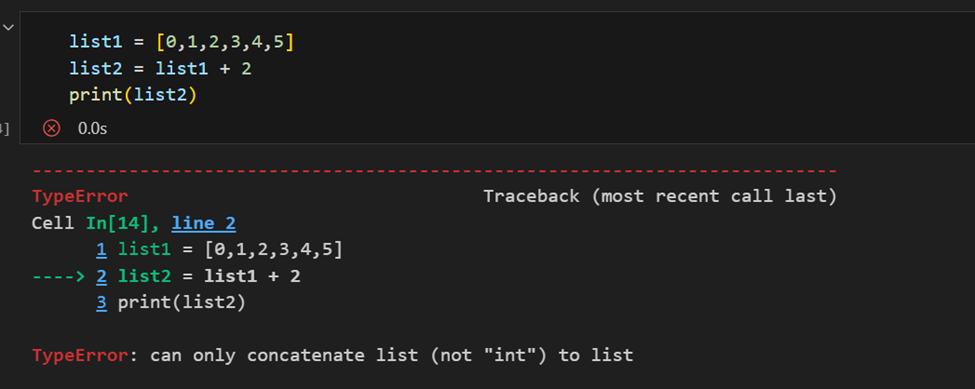
NumPy 배열과 Python 리스트의 차이
배열과 리스트의 주요 차이점은 배열이 벡터화된 작업을 처리하도록 설계되었는데, Python 리스트는 아닌 것입니다. 즉, 함수를 적용하면 배열의 각 항목에 대해 수행되며, 전체 배열 객체에 대해 수행되지 않습니다.
Pandas
Pandas는 수치 계산 및 데이터 조작을 위한 가장 강력한 라이브러리 중 하나로 두드러집니다. 이는 인공 지능 및 기계 학습 분야에 중요합니다.
Pandas는 NumPy와 마찬가지로 가장 인기 있는 Python 라이브러리 중 하나입니다. 이것은 순수 C로 작성된 낮은 수준의 NumPy에 대한 고수준 추상화입니다. Pandas는 고성능이며 사용하기 쉬운 데이터 구조 및 데이터 분석 도구를 제공합니다. Pandas는 두 가지 주요 구조를 사용합니다: 데이터 프레임 및 시리즈.
Pandas Series에서의 인덱스
Pandas 시리즈는 리스트와 유사하지만, 각 요소에 레이블을 연결하는 점에서 다릅니다. 이는 사전과 유사한 모습을 만듭니다. 사용자가 명시적으로 인덱스를 제공하지 않으면 Pandas는 0부터 N-1까지의 범위를 가지는 RangeIndex를 생성합니다. 각 시리즈 객체에는 데이터 유형도 있습니다.
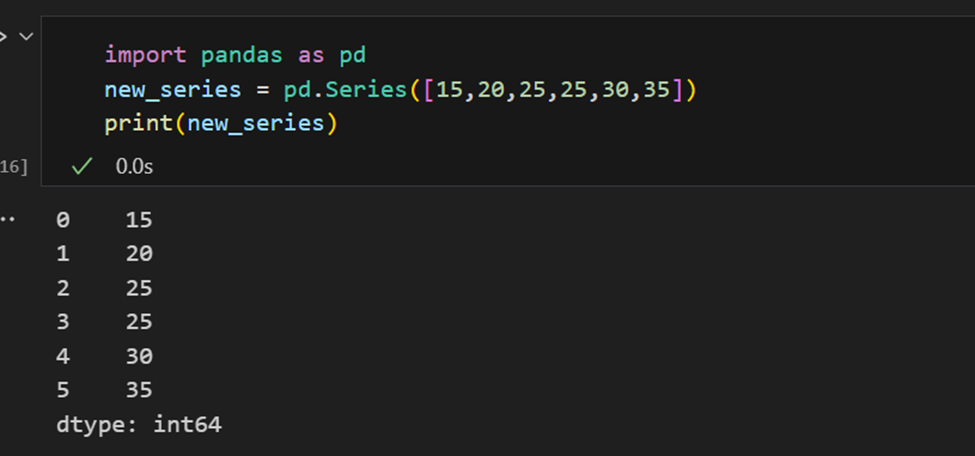
판다 Series에는 Series의 모든 값을 추출하는 방법과 색인별 개별 요소를 추출하는 방법이 있습니다.
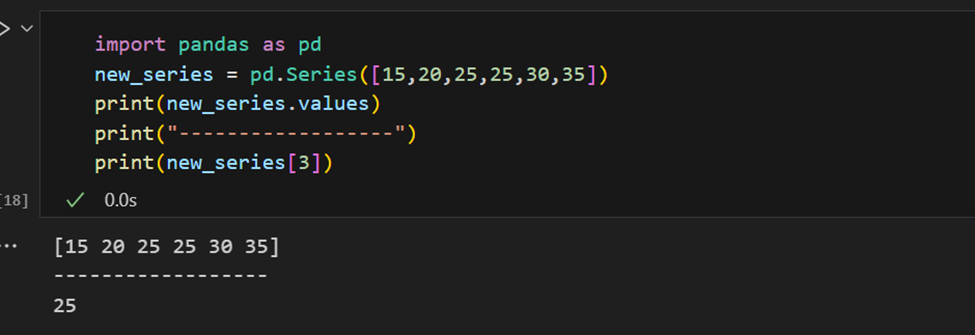
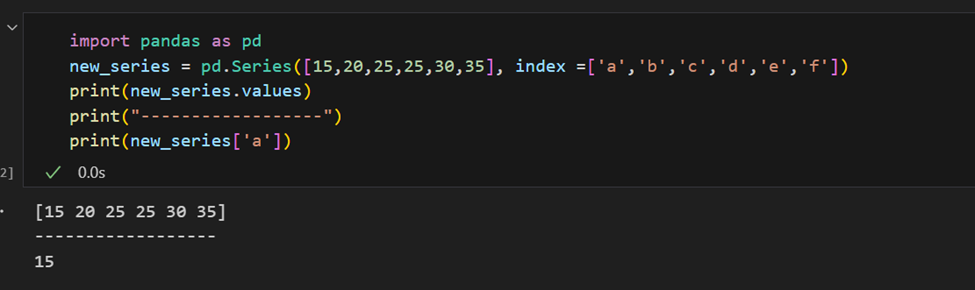
색인은 수동으로 제공할 수도 있습니다.
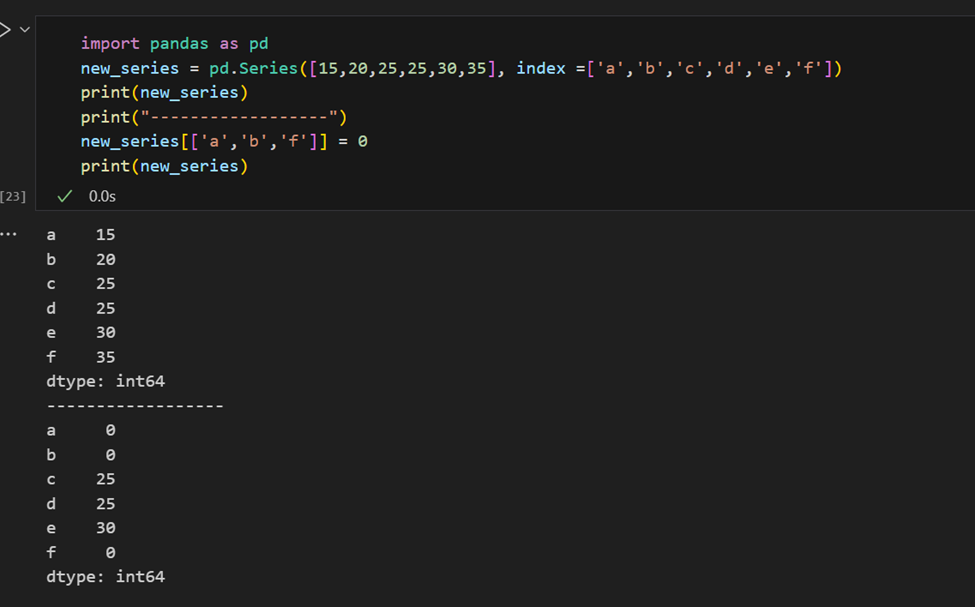
시리즈의 색인으로 여러 요소를 검색하거나 그룹 할당을 만들기 쉽습니다.
판다스 데이터프레임
데이터프레임은 행과 열이 있는 테이블입니다. 데이터프레임의 각 열은 시리즈 객체입니다. 행은 시리즈 내의 요소로 이루어져 있습니다. 판다스 데이터프레임은 데이터 조작 및 분석을 위한 다양한 연산을 제공합니다. 일반적인 연산의 요약은 다음과 같습니다:
기본 연산
데이터프레임 생성
- 사전에서:
pd.DataFrame({'col1': [1, 2], 'col2': [3, 4]}) - CSV 파일에서:
pd.read_csv('data.csv') - Excel 파일에서:
pd.read_excel('data.xlsx')
데이터 액세스
- 열 선택:
df['col1'] - 행 선택:
df.loc[0] (인덱스 레이블로), df.iloc[0](인덱스 위치로) - 슬라이싱:
df [0:2] (첫 두 개의 행), df[['coll', 'col2']](여러 열)
열/행 추가 및 제거
- 열 추가:
df['new_col'] = - 열 제거:
df.drop('coll', axis=1) - 행 추가:
df.append({'col1': 7, 'col2': 8}, ignore_index=True) - 행 제거:
df.drop(0)
데이터 필터링
- 부울 조건 사용:
df [df['col1'] > 2]
수학 연산
- 산술 연산:
df['col1'] + df['col2'],df * 2, 등 - 집계 함수:
df.sum(),df.mean(),df.max(),df.min(), 등 - 사용자 정의 함수 적용:
df.apply(lambda x: x**2)
누락된 데이터 처리
- 누락된 값 확인:
df.isnull() - 누락된 값 제거:
df.dropna() - 누락된 값 채우기:
df.fillna(0)
데이터프레임 병합 및 결합
- 병합:
pd.merge(df1, df2, on='key_column') - 결합:
df1.join(df2, on='key_column')
그룹화 및 집계
- 그룹화:
df.groupby('col1') - 집계:
df.groupby('col1').mean()
시계열 작업
- 재샘플링:
df.resample('D').sum()(일별 주기로 다운샘플링) - 시간 이동:
df.shift(1)(데이터를 한 기간씩 이동)
데이터 시각화
그래픽 표시: df.plot() (선 그래프), df.hist() (히스토그램), 등
복잡한 판다스 예제
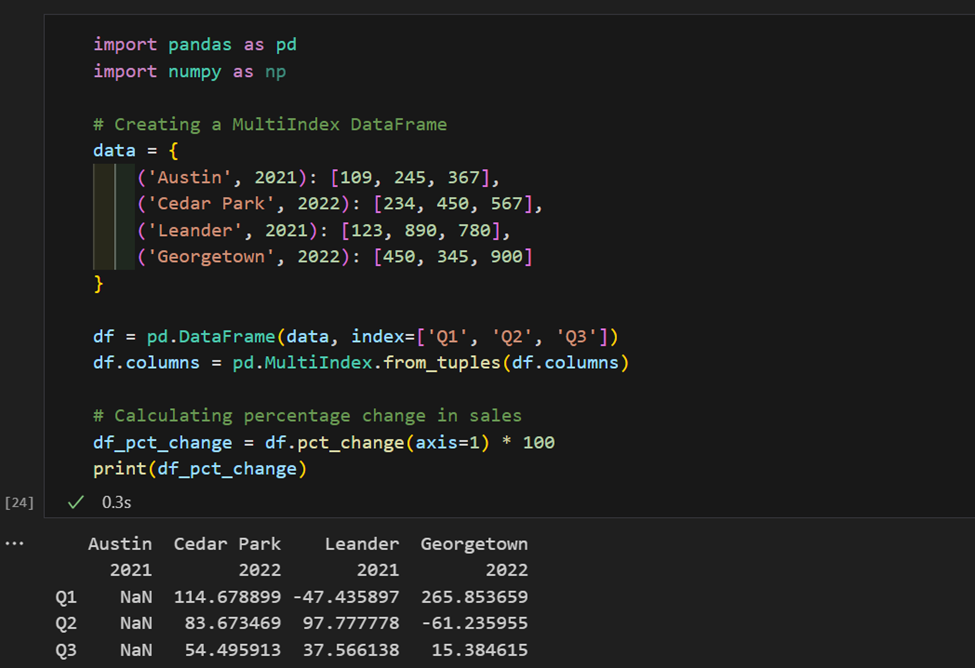
1. 여기에는 지역 및 연도별로 색인화된 판매 데이터가 있습니다. 이제 여기에서 각 지역별 판매액의 변동률을 계산합니다.
2. 제품 및 가격이 포함된 데이터셋이 있습니다. 각 카테고리별 평균 가격을 계산하고 각각에서 가장 비싼 제품을 찾습니다.
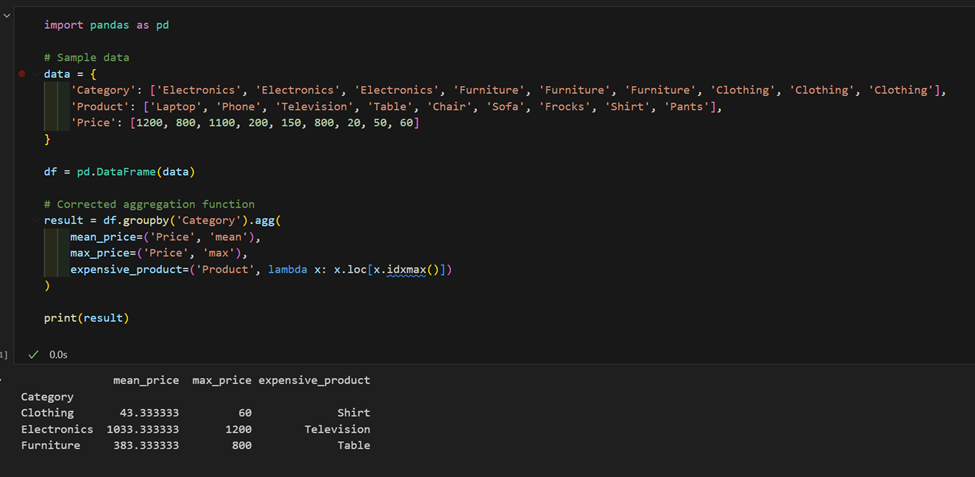
3. 복잡한 “apply” 사용:
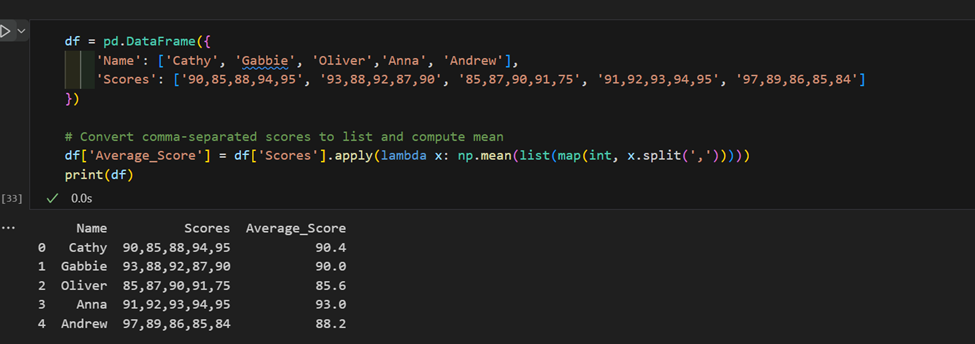
결론
NumPy와 Pandas 두 라이브러리는 BFSI(금융 분석), 과학 계산, AI 및 ML, 그리고 대규모 데이터 처리와 같은 실생활 응용 프로그램에서 널리 사용됩니다. 이 두 라이브러리는 주식 시장의 중요한 트렌드를 분석부터 대규모 ERP 비즈니스 데이터를 관리하는 데이터 주도적 의사 결정에 중요한 역할을 합니다.
초보자들을 위한 다음 단계는 작은 프로젝트를 수행하고 데이터셋을 탐색하며 실제 시나리오에서 기능을 적용하여 NumPy와 Pandas를 사용하는 것입니다. 사람들은 GitHub에서 금융, 부동산 또는 일반 제조업 데이터를 오픈 소스로 다운로드할 수 있습니다. 이러한 소스 데이터와 이러한 라이브러리를 사용하여 사람들은 확실한 이야기나 경험적 분석을 만들 수 있습니다. 실무 경험은 개념을 확고히 하고 학습자들을 더 고급 데이터 과학 작업을 위해 준비하게 도와줄 것입니다.
결론적으로, NumPy와 Pandas는 데이터 조작 및 분석에 필수적인 두 개의 Python 라이브러리입니다. 여기서 NumPy는 효율적인 배열 작업으로 숫자 계산에 강력한 지원을 제공하며, Pandas는 NumPy를 기반으로 Series 및 DataFrame과 같은 구조화된 데이터를 처리하기 위한 본질적이고 직관적인 데이터 구조를 제공합니다.
Source:
https://dzone.com/articles/python-libraries-introduction-numpy-pandas