













Nell’ultimo decennio, Apache Flink è diventato lo standard de facto per la processing stream reale-time. Il processing stream è un paradigma per la costruzione di sistemi che tratta gli stream di eventi (sequenze di eventi in tempo) come suo blocco fondamentale. Un processore di stream, come Flink, consuma input stream prodotte da fonti di eventi e produce output stream che sono consumate da sink (i sink memorizzano i risultati e li rendono disponibili per ulteriore processing).
Nomi noti come Amazon, Netflix e Uber fanno affidamento su Flink per alimentare i data pipeline in scala elevata al cuore delle loro attività, ma Flink riveste anche un ruolo chiave in molte piccole aziende con requisiti simili per la capacità di reagire rapidamente agli eventi commerciali critici.
Cosa viene utilizzato Flink? Gli use case comuni rientrano in queste tre categorie:
|
Pipeline di dati in streaming |
Analisi reale-time |
Applicazioni a eventi |
|---|---|---|
|
Ingeliunga in modo continuo, arricchisci e trasforma stream di dati, caricandoli in sistemi di destinazione per azioni timely (rispetto al processing a batch). |
Produci e aggiorna continuamente risultati che sono mostrati e consegnati agli utenti mentre gli stream di dati in streaming sono consumati. |
Riconosciamo i pattern e reagiamo agli eventi in entrata attivando calcoli, aggiornamenti di stato o azioni esterne. |
|
Alcuni esempi includono:
|
Alcuni esempi comprendono:
|
Alcuni esempi comprendono:
|
Flink include:
- Supporto robusto per carichi di lavoro di streaming dati a scala sufficiente per le aziende globali
- Garanzie di correttezza esattamente una volta e recupero dall’errore
- Supporto per Java, Python e SQL, con un supporto unificato sia per processi batch che stream
- Flink è un progetto open-source maturo della Apache Software Foundation e ha una comunità molto attiva e supportiva.
Flink viene a volte descritto come complesso e difficile da imparare. Sì, l’implementazione del runtime di Flink è complessa, ma ciò non dovrebbe sorprendere, poiché risolve alcuni problemi difficili. Le API di Flink possono essere un po ‘difficili da imparare, ma questo ha più a che fare con i concetti e i principi organizzativi sconosciuti piuttosto che con alcuna complessità intrinseca.
Flink potrebbe differire da qualcosa che avete utilizzato prima, ma in molti aspetti è davvero piuttosto semplice. Ad un certo punto, mentre diventate più familiari con il modo in cui Flink è strutturato e con i problemi che il runtime deve affrontare, i dettagli delle API di Flink dovrebbero iniziare a sembrarvi come la conseguenza ovvia di alcuni principi chiave, invece di una raccolta di dettagli arcani da imparare a memoria.
Questo articolo si propone di render la guida all’apprendimento di Flink molto più semplice, illustrando i principi fondamentali sottostanti il suo design.
Flink Incarna Alcune Grandi Idee
Streaming
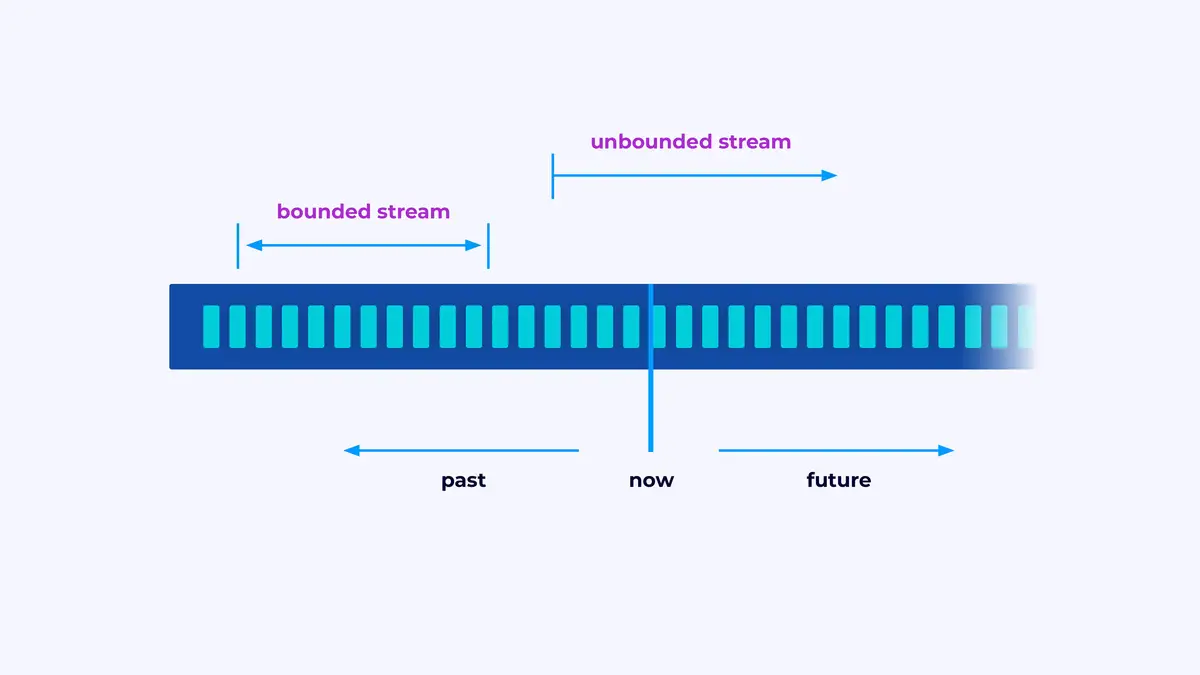
Flink è un framework per la costruzione di applicazioni in grado di processare flussi di eventi, in cui un flusso è una sequenza di eventi limitata o illimitata.
Una applicazione Flink è un pipeline di processamento dati. I vostri eventi scorrono attraverso questo pipeline e vengono elaborati in ogni fase dal codice che scrivete. Chiamiamo questo pipeline grafo del job, e i nodi di questo grafo (o, in parole diverse, le fasi del pipeline di processamento) sono chiamati operatori.
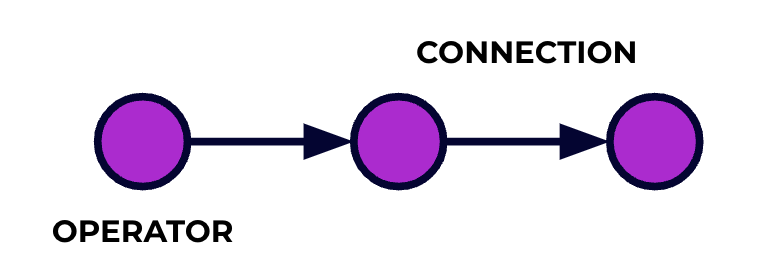
Il codice che scrivete utilizzando una delle API di Flink descrive il grafo del job, incluso il comportamento degli operatori e le loro connessioni.
Processamento Parallelo
Ogni operatore può avere molte istanze parallele, ciascuna operando indipendentemente su una sottosequenza degli eventi.
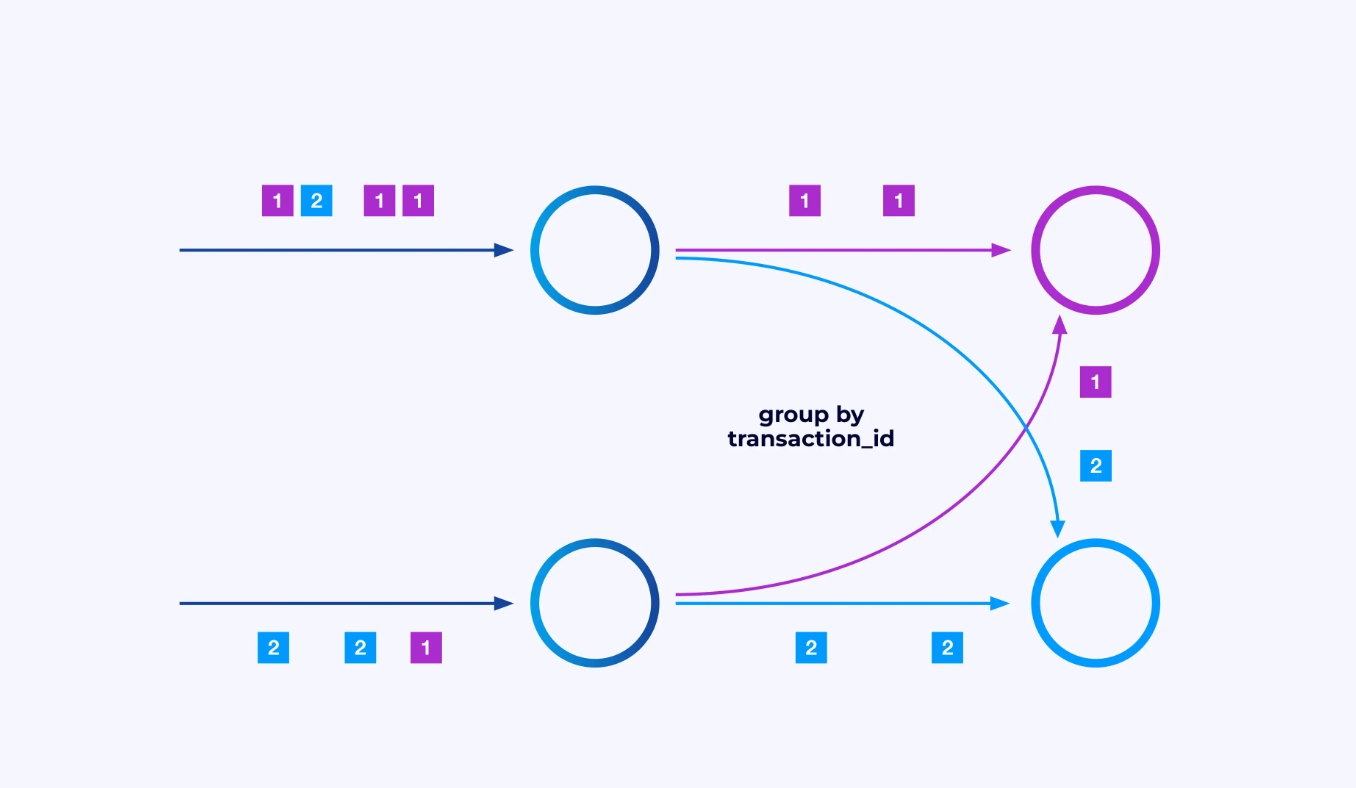
A volte sarai in grado di applicare un particolare schema di particionamento the questi sotto-flussi in modo da raggruppare gli eventi secondo logiche specifiche dell’applicazione. Per esempio, se stai processando transazioni finanziarie, potresti aver bisogno di organizzare in modo da processare lo stesso thread per ogni evento di una data transazione. Questo consentirà di connettere gli eventi diversi che si verificano nel tempo per ogni transazione
In Flink SQL, fareste questo usando GROUP BY transaction_id, mentre nell’API DataStream usareste keyBy(event -> event.transaction_id) per specificare questo raggruppamento o partizionamento. In entrambi i casi, questo apparirà nel grafo del job come una rete di scambio completamente connessa tra due fasi consecutive del grafo.
Stato
Gli operatori che lavorano su stream di partizionamento chiave possono usare il store distribuito di stato chiave/valore di Flink per persistere in modo duraturo ciò che vogliono. Lo stato per ciascuna chiave è locale a una specifica istanza di un operatore e non può essere accessibile da altrove. Le sotto-topologie parallele non condivide niente — questo è cruciale per una scalabilità illimitata.
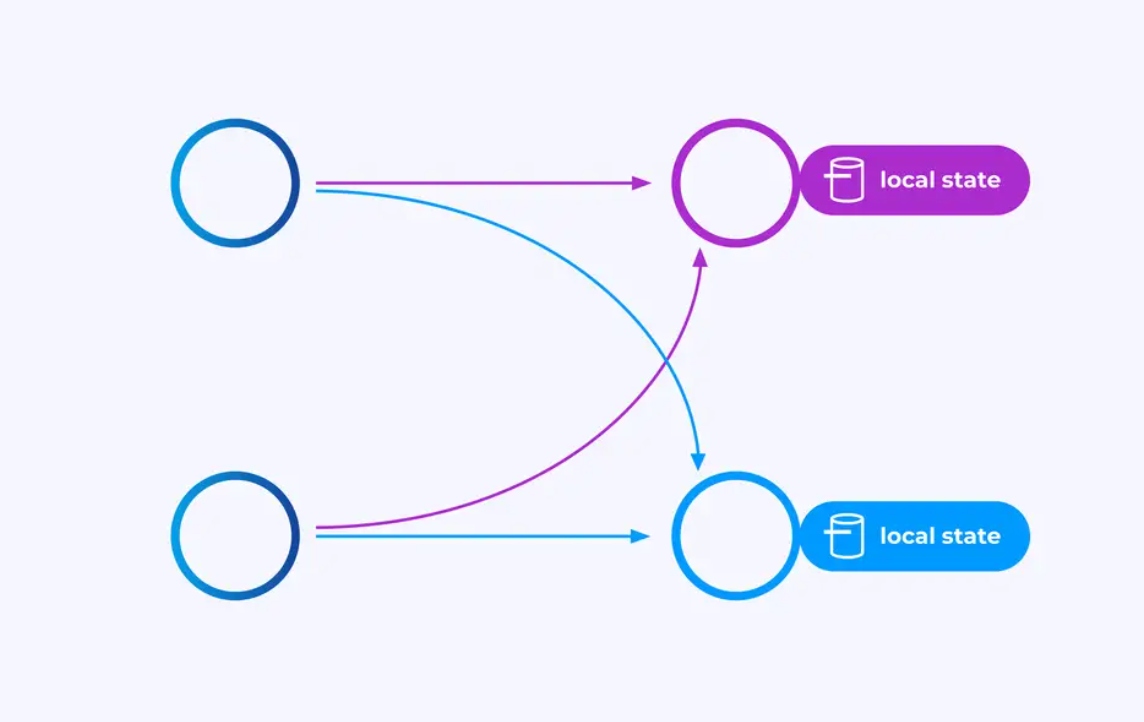
Un job Flink potrebbe essere lasciato in esecuzione indeterminatamente. Se un job Flink sta continuamente creando nuove chiavi (ad esempio, ID di transazione) e immagazzinando qualcosa per ogni nuova chiave, allora quel job rischia di esplodere perché utilizza una quantità dello stato non limitata. Ognuno degli API di Flink è organizzato intorno a metodi per aiutarti a evitare esplosioni incontrollate dello stato.
Tempo
Un modo per evitare di mantenere uno stato troppo a lungo è di conservarlo solo fino a un punto specifico del tempo. Per esempio, se si desidera contare le transazioni in finestre di durata minutiera, una volta che ogni minuto è scaduto, i risultati di quella minuto possono essere prodotti, e quel contatore può essere liberato.
Flink fa una distinzione importante tra due differenti nozioni di tempo:
- Tempo di processamento (o orologio da parete), che deriva dalla ora reale del giorno in cui un evento è in fase di processamento
- Tempo degli eventi, che si basa sui timestamp registrati con ciascun evento
Per illustrare la differenza tra loro, considerate cosa significa che una finestra di durata minutiera sia completa:
- Una finestra di tempo di processamento è completa quando il minuto è scaduto. Questo è perfettamente chiaro.
- Una finestra di tempo degli eventi è completa quando tutti gli eventi che si sono verificati in quel minuto sono stati processati. Questo può essere complesso perché Flink non può sapere nulla sugli eventi che non ha ancora processato. Il massimo che possiamo fare è fare un’ipotesi riguardo alla possibile malfunzionamento di una stream e applicare quell’ipotesiuristicamente.
Checkpointing per la Ripristinazione in caso di Fallimento
I fallimenti sono inevitabili. Nonostante i fallimenti, Flink riesce a fornire garanzie di esattamente una volta, ovvero che ogni evento influirà lo stato che Flink gestisce esattamente una volta, come se il fallimento non fosse mai accaduto. Lo fa prendendo ripetutamente snapshot globali e self-consistenti di tutti gli stati. Questi snapshot, creati e gestiti automaticamente da Flink, si chiamano checkpoint.
Il recupero richiama il ripristino allo stato catturato nell’ultimo punto di controllo e esegue un riavvio globale di tutti gli operatori a partire da quel punto di controllo. Durante il recupero, alcuni eventi vengono riprocessati, ma Flink è in grado di garantire la correttezza garantendo che ogni punto di controllo sia una panoramica globale e self-consistente dello stato completo del sistema.
Architettura del sistema
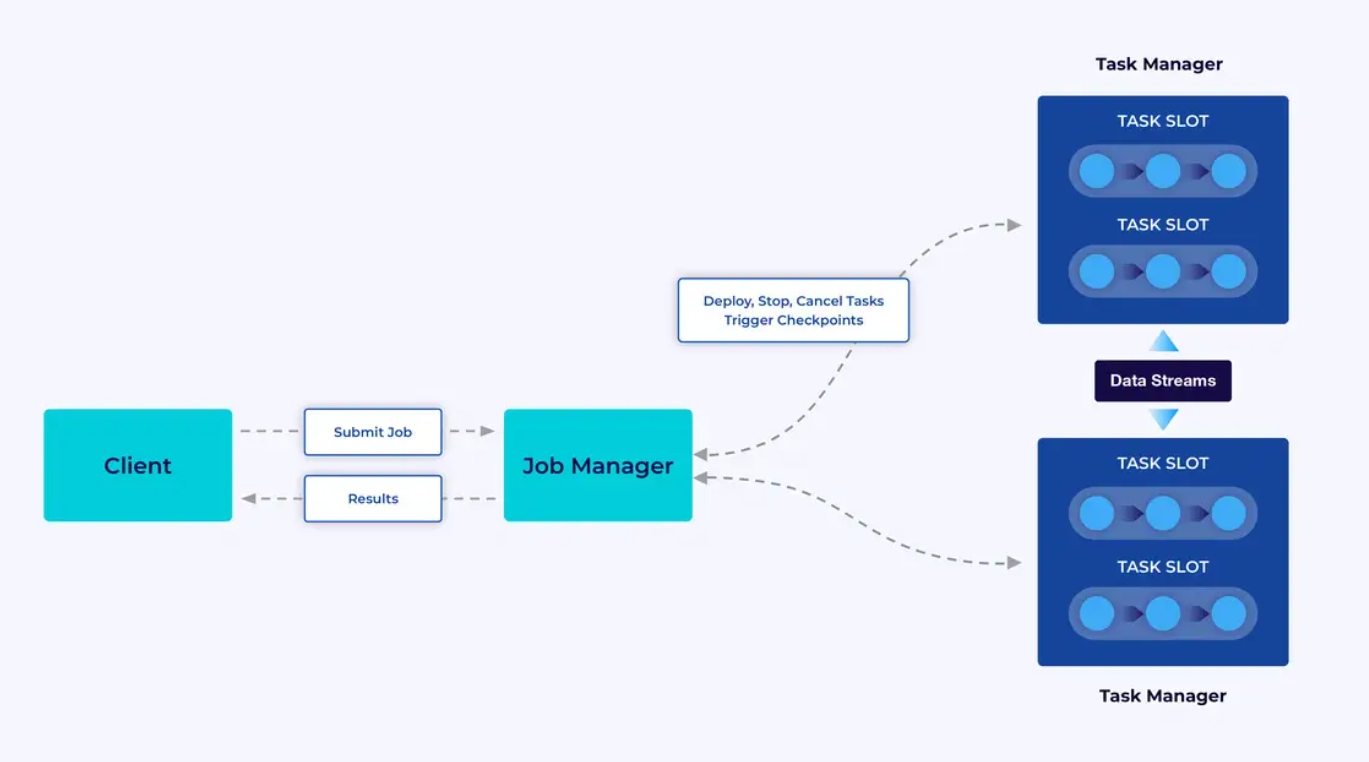
Le applicazioni Flink vengono eseguite in cluster Flink, quindi prima di poter mettere una applicazione Flink in produzione, è necessario avere un cluster per deployarla. Per fortuna, durante lo sviluppo e i test è facile iniziare lavorando localmente in un ambiente di sviluppo integrato (IDE) come IntelliJ o Docker.
Un cluster Flink è composto da due tipi di componenti: un Job Manager e un insieme di Task Managers. I task managers eseguono le vostre applicazioni in parallelo, mentre il job manager agisce come gateway tra i task managers e il mondo esterno. Le applicazioni vengono sottmesse al job manager, che gestisce le risorse fornite dai task managers, coordina il salvataggio dei punti di controllo e fornisce una visione dello cluster attraverso le metriche.
L’esperienza dello sviluppatore
L’esperienza di un sviluppatore Flink dipenderà, in un certo senso, dalla scelta dell’API: sia l’antica, più basso livello DataStream API o le moderne, relative API relazionali Tabella e SQL.
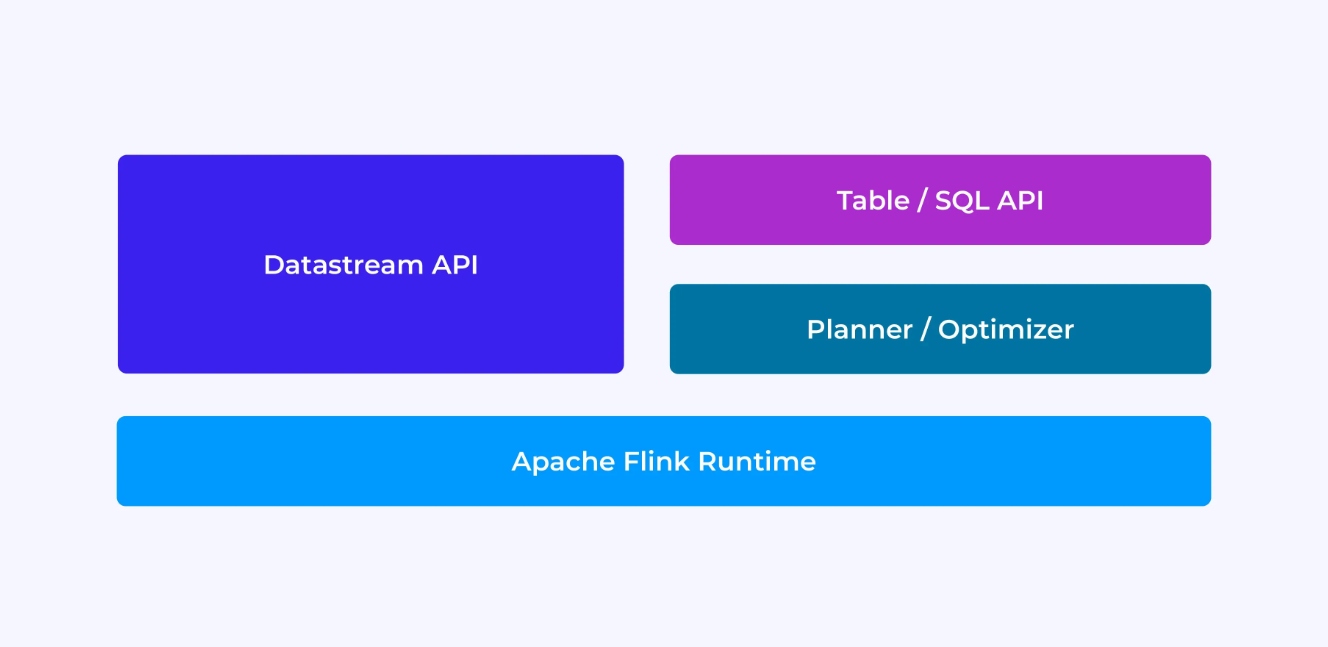
Quando state programmando con l’API DataStream di Flink, state pensando consapevolmente a ciò che il runtime di Flink farà mentre la vostra applicazione si avvia. Ciò significa che state costruendo il grafo del job in base ad ogni operatore, descrivendo lo stato in uso insieme ai tipi coinvolti e la loro serializzazione, creando timer e implementando funzioni di callback da eseguire quando questi timer vengono attivati, ecc. L’astrazione fondamentale nell’API DataStream è l’evento, e le funzioni che scrivete handleranno un evento alla volta, appena ricevuto.
Dall’altro lato, quando utilizzate l’API Table/SQL di Flink, questi problemi a basso livello sono risolti per voi, e potete concentrarvi maggiormente sulla vostra logica aziendale. L’astrazione fondamentale è la tabella, e state pensando più in termini di unione di tabelle per l’enriccimento, di raggruppamento di righe per il calcolo di analisi aggregate, ecc. Un planner/ottimizzatore di query SQL integrato si occupa delle dettagli. Il planner/ottimizzatore fa un ottimo lavoro nel gestire i risorse efficientemente, spesso ottenendo risultati migliori di codice scritto a mano.
Alcune considerazioni prima di approfondire i dettagli: primo, non dovete scegliere tra l’API DataStream o l’API Table/SQL – entrambi le API sono interoperabili e puoi combinarle. Può essere un modo buono se avete bisogno di personalizzazioni che non siano possibili nell’API Table/SQL. Ma un’altra buona via per andare oltre ciò che l’API Table/SQL offre di default è aggiungere alcune capacità in forma di funzioni definite dall’utente (UDFs). Qui, Flink SQL offre molte opzioni per l’estensione.
Costruzione del grafo del job
Indipendentemente dalla quale API utilizzi, l’obiettivo ultimo del codice che scrivi è costruire il grafo di lavoro che il runtime di Flink eseguirà a nome tuo. Ciò significa che queste API sono organizzate intorno alla creazione di operatori e alla specifica del loro comportamento e delle loro connessioni tra loro. Con l’API DataStream, stai costruendo direttamente il grafo di lavoro, mentre con l’API Table/SQL, il pianificatore SQL di Flink si occupa di questo.
Serializzazione Funzioni e Dati
In definitiva, il codice fornito a Flink verrà eseguito in parallelo dai worker (i task manager) in un cluster Flink. Per renderlo possibile, gli oggetti funzione che crei sono serializzati e inviati ai task manager dove vengono eseguiti. Allo stesso modo, gli eventi stessi a volte devono essere serializzati e inviati attraverso la rete da un task manager all’altro. Di nuovo, con l’API Table/SQL non devi preoccuparti di questo.
Gestione Stato
Il runtime di Flink deve essere informato riguardo qualsiasi stato che ti aspetti che riprenda in caso di fallimento. Per far funzionare questo processo, Flink ha bisogno di informazioni di tipo che possa utilizzare per serializzare e deserializzare questi oggetti (così possono essere scritti nei checkpoint elettivamente, e letti da essi). Puoi configurare questo stato gestito in opzione con descrittori di tempo di validità che Flink userà poi per scadute automaticamente lo stato una volta che è scaduto il suo uso.
Con l’API DataStream, di solito finisci per gestire direttamente lo stato necessario per il tuo applicativo (le operazioni integrate della finestra sono l’unico caso di eccezione a questo). D’altro canto, con l’API Table/SQL, questo concetto viene astratto. Per esempio, date una query come quella seguente, sai che da qualche parte nella runtime di Flink deve essere mantenuto un counter per ogni URL, ma tutti i dettagli sono affrontati per te.
SELECT url, COUNT(*)
FROM pageviews
GROUP BY URL;Impostazione e Triggered Timers
I timer hanno molte utilizzazioni nella processing stream. Per esempio, è comune per le applicazioni Flink aver bisogno di raccogliere informazioni da molti diversi sorgenti di eventi prima di produrre eventuali risultati. I timer funzionano bene per i casi in cui è sensibile attendere (ma non indefinitamente) per dati che potrebbero (o non potrebbero) eventualmente arrivare.
I timer sono anche essenziali per l’implementazione di operazioni di windowing basate su tempo. Entrambe le API DataStream e Table/SQL hanno supporto integrato per le finestre e creano e gestiscono i timer per te.
Casi d’uso
Ritornando alle tre categorie ampi di casi d’uso di streaming introdotte all’inizio di questo articolo, vediamo come corrispondono a ciò che hai appena imparato su Flink.
Pipeline di Streaming dati
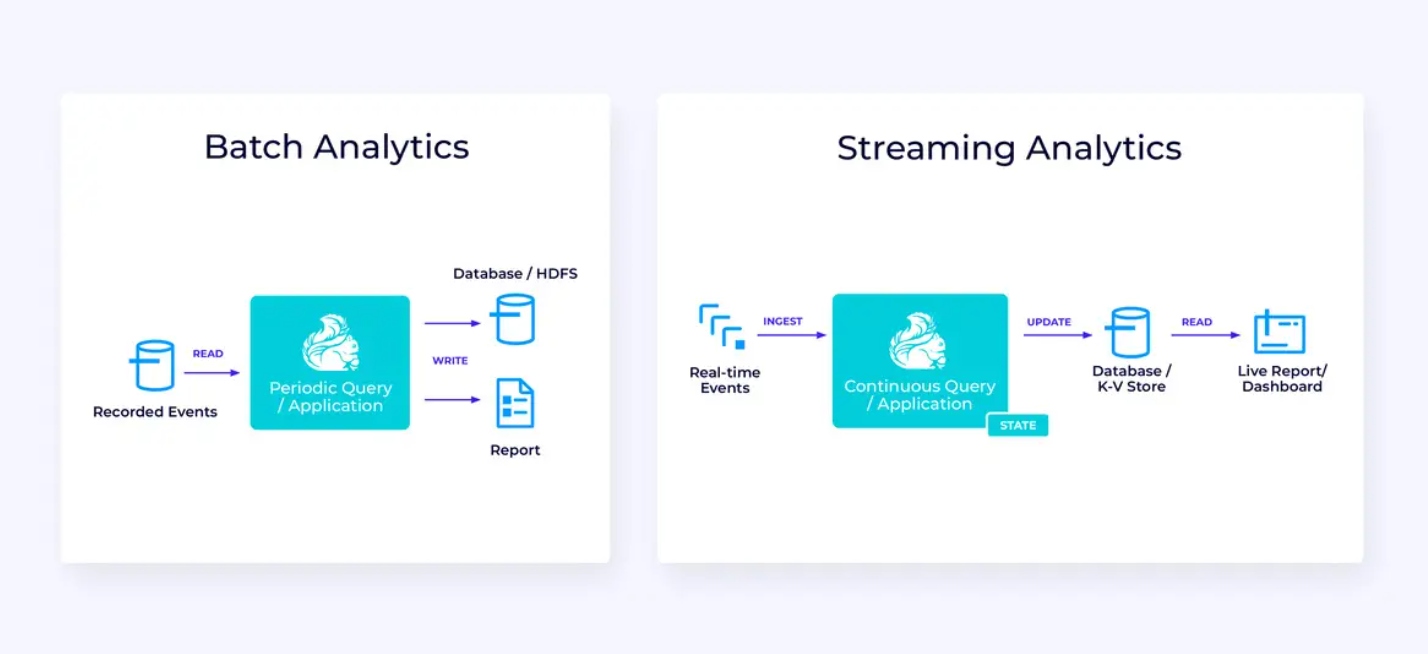
Ecco sotto, a sinistra, un esempio di un tradizionale job di estrazione, trasformazione e caricamento batch (ETL) che legge periodicamente da un database transazionale, trasforma i dati e scrive i risultati in un’altra store dati, come un database, file system o data lake.
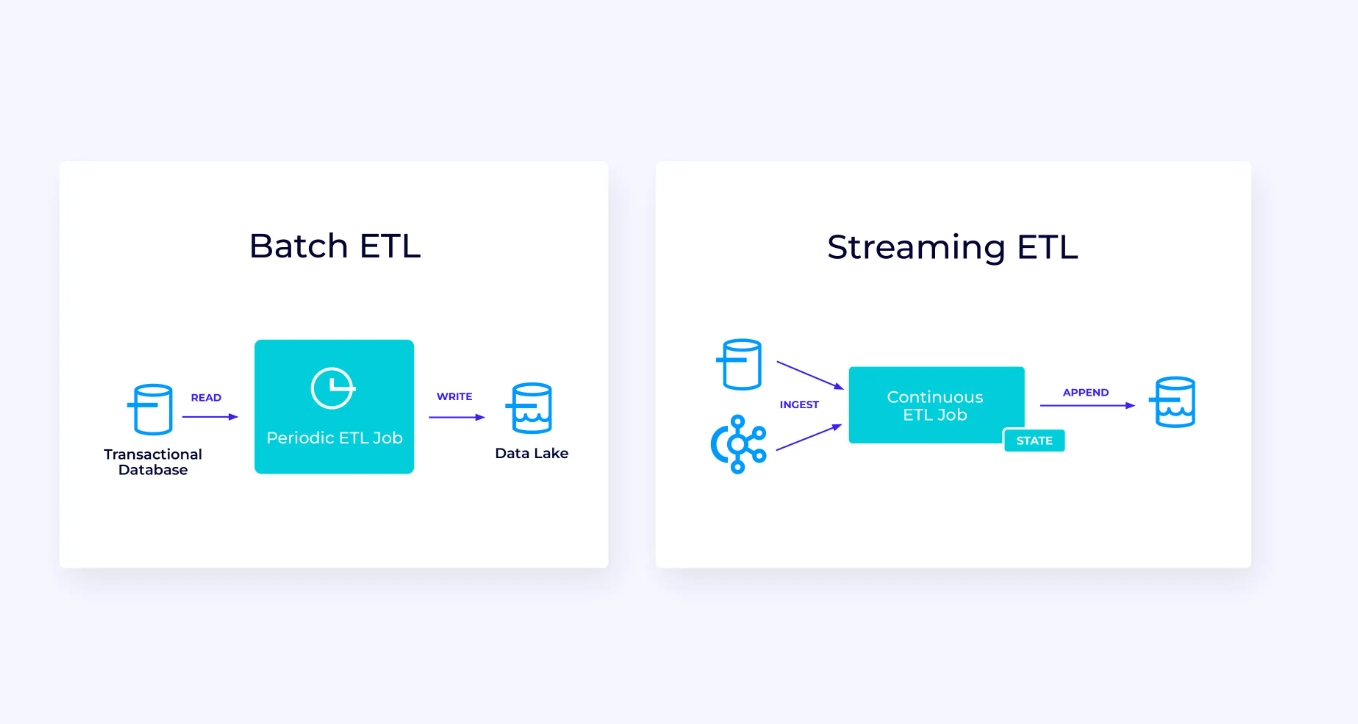
Il pipeline streaming corrispondente è superficialmente simile, ma presenta differenze significative:
- Il pipeline streaming è sempre in esecuzione.
- I dati transazionali vengono consegnati al pipeline streaming in due parti: un carico iniziale di massa dalla base dati, in combinazione con una stream di cambiamento dati (CDC) che trasporta le aggiornamenti della base dati da quella carica iniziale.
- La versione streaming produce continuamente nuovi risultati appena diventano disponibili.
- Il stato è gestito esplicitamente in modo da poter essere recuperato robustamente in caso di fallimento. I pipeline streaming ETL di solito utilizzano un minimo di stato. I dati sorgente tengono traccia esattamente di quanto dell’input sia stato iniettato, di solito nella forma di offset che contano i record dalla fine delle stream. I sink usano le transazioni per gestire i loro scritti nei sistemi esterni, come le basi dati o Kafka. Durante il checkpoint, le fonti registrano i loro offset, e i sink committano le transazioni che trasportano i risultati di aver letto esattamente fino a, ma non oltre, quegli offset sorgente.
Per questo caso d’uso, l’API Table/SQL sarebbe una scelta migliore.
Analisi in tempo reale
Confrontando quest’applicazione di analisi streaming con l’applicazione di streaming ETL, ci sono alcune interessanti differenze:
- Di nuovo, Flink è utilizzato per eseguire un’applicazione continua, ma per questa applicazione, Flink probabilmente dovrà gestire molto più stato.
- Per questo caso d’uso, ha senso che la stream in ingresso sia salvata in un sistema di storage nativo stream, come Apache Kafka.
- Invece di produrre periodicamente un rapporto statico, la versione streaming può essere utilizzata per guidare un dashboard live.
Di nuovo, l’API Tabella/SQL è di solito una scelta ottima per questo caso d’uso.
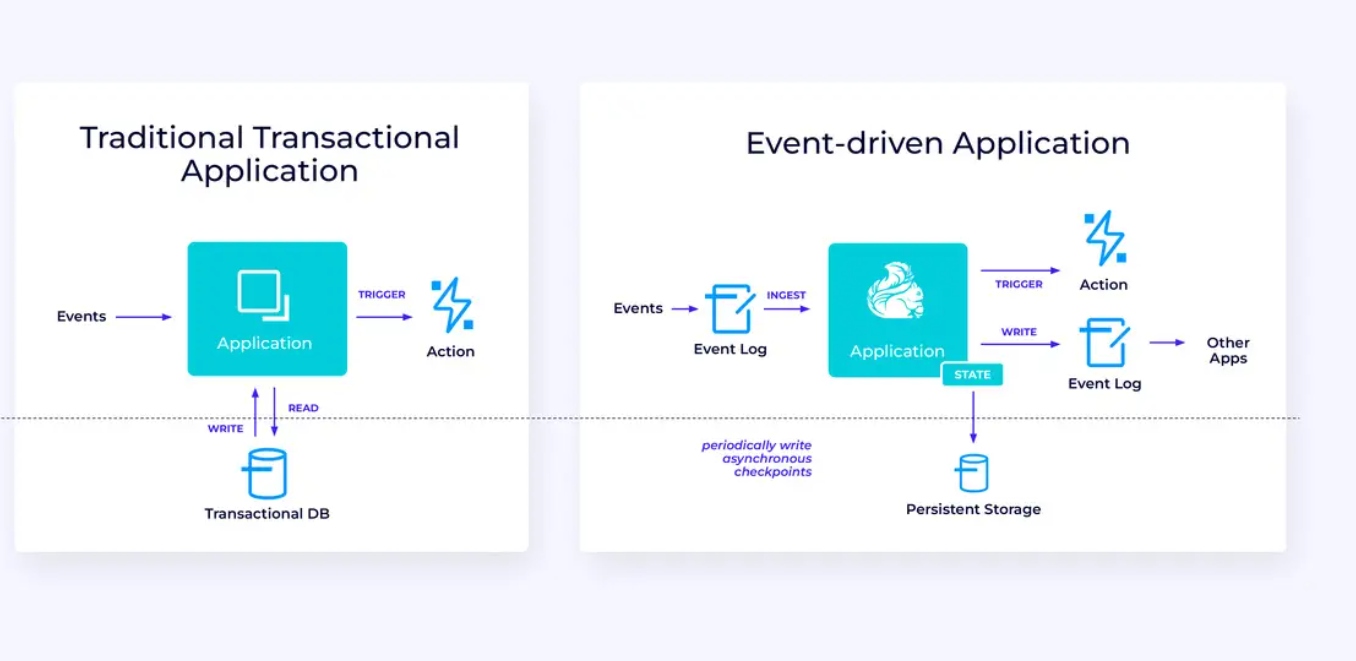
Applicazioni ad eventi
La nostra terza e ultima famiglia di casi d’uso coinvolge l’implementazione di applicazioni ad eventi o microservizi. Molto è stato scritto in altro luogo su questo argomento; questo è un pattern di progettazione architetturale che offre molti benefici.
Flink può essere un ottimo candidato per queste applicazioni, specialmente se hai bisogno del tipo di performance che Flink può fornire. In alcuni casi, l’API Tabella/SQL ha tutto ciò che serve, ma in molti casi, avrai bisogno della flessibilità aggiuntiva dell’API DataStream per almeno una parte del lavoro.
Iniziare con Flink
Flink fornisce un potente framework per la creazione di applicazioni che processano stream di eventi. Come abbiamo visto, alcuni concetti potrebbero sembrare innovativi all’inizio, ma una volta familiarizzati con il modo in cui Flink è progettato e opera, il software è intuitivo da usare, e i benefici di conoscere Flink sono significativi.
Come passo successivo, seguile istruzioni nella documentazione di Flink, che ti guiderà attraverso il processo di download, installazione e avvio della versione stabile più recente di Flink. Pensa ai casi d’uso ampi che abbiamo discusso – pipeline dati moderni, analisi in tempo reale e microservizi ad eventi – e come questi possono aiutare a risolvere un problema o a generare valore per la tua organizzazione.
Il data streaming è una delle aree più emozionanti dell’attuale tecnologia aziendale, e il processamento in streaming con Flink lo rende ancora più potente. Imparare Flink sarà benefico non solo per la tua organizzazione ma anche per la tua carriera perché il processamento dei dati in tempo reale diventa sempre più prezioso per le aziende a livello mondiale. Quindi controlla Flink oggi e vedi cosa può aiutarti a raggiungere questa potente tecnologia.
Source:
https://dzone.com/articles/apache-flink-101-a-guide-for-developers