













L’extraction de caractéristiques en apprentissage automatique transforme les données brutes en un ensemble de caractéristiques significatives, capturant des informations essentielles tout en réduisant la redondance. Cela peut impliquer des techniques de réduction de dimensionnalité et des méthodes qui créent de nouvelles caractéristiques à partir des données existantes.
Imaginez que vous essayez d’identifier des fruits sur un marché. Alors que vous pourriez considérer d’innombrables attributs (poids, couleur, texture, forme, odeur, etc.), vous pourriez réaliser que quelques caractéristiques clés comme la couleur et la taille suffisent à distinguer entre les pommes et les oranges. C’est exactement ce que fait l’extraction de caractéristiques. Cela vous aide à vous concentrer sur les caractéristiques les plus informatives de vos données.
Lors de l’extraction de caractéristiques, les données originales sont mathématiquement transformées en un nouvel ensemble de caractéristiques. Ces nouvelles caractéristiques sont conçues pour capturer les aspects les plus importants des données tout en réduisant potentiellement leur complexité. Les caractéristiques extraites représentent souvent des motifs ou des structures sous-jacents qui pourraient ne pas être immédiatement apparents dans les données originales.
Extraction de caractéristiques
Dans les prochaines sections, nous explorerons pourquoi l’extraction de caractéristiques est si importante en apprentissage automatique et examinerons diverses méthodes pour extraire des caractéristiques de différents types de données ainsi que leur code. Si vous souhaitez des exemples pratiques, consultez notre cours sur la Réduction de Dimensionnalité en Python, qui comporte un chapitre dédié à l’extraction de caractéristiques.
Pourquoi l’extraction de caractéristiques est-elle importante en apprentissage automatique ?
L’extraction de caractéristiques joue un rôle important en apprentissage automatique. Cela peut faire la différence entre un modèle qui échoue et un qui réussit. Voyons pourquoi c’est si fondamental pour construire des modèles d’apprentissage automatique efficaces.
Amélioration de la précision et de l’efficacité du modèle
Lorsque l’on travaille avec des données brutes, les modèles d’apprentissage automatique ont souvent du mal à distinguer les motifs significatifs du bruit. L’extraction de caractéristiques sert de phase de prétraitement des données qui peut améliorer considérablement l’apprentissage et les performances de vos modèles.
Performance du modèle versus Temps d’entraînement
Par exemple, lorsqu’un modèle atteint une précision de 85% avec des données brutes, le même modèle pourrait atteindre une précision de 95% lorsqu’il est entraîné sur des fonctionnalités soigneusement extraites. Cette amélioration ne vient pas du changement du modèle mais du fait de lui fournir des données d’entrée de meilleure qualité à partir desquelles il peut apprendre.
Gestion des ensembles de données de grande dimension
Les ensembles de données modernes comportent souvent des centaines ou des milliers de fonctionnalités. Cela pose plusieurs défis que l’extraction de fonctionnalités contribue à résoudre.
- La malédiction de la dimensionnalité: À mesure que le nombre de caractéristiques augmente, les données deviennent de plus en plus clairsemées dans l’espace des caractéristiques. Cela rend plus difficile pour les modèles de trouver des motifs significatifs. L’extraction de caractéristiques crée une représentation plus compacte qui préserve les relations importantes tout en réduisant la dimensionnalité.
- Utilisation élevée de la mémoire: Les données de haute dimensionnalité nécessitent plus de stockage et de mémoire lors du traitement. En n’extrayant que les caractéristiques les plus pertinentes, nous pouvons réduire significativement l’empreinte mémoire de nos ensembles de données tout en maintenant leur valeur informative.
- Visualisation des données: Il est impossible de visualiser directement des données avec plus de trois dimensions. L’extraction de caractéristiques peut réduire la dimensionalité à deux ou trois caractéristiques, permettant ainsi de représenter et de comprendre visuellement la structure des données.
L’extraction de caractéristiques aborde ces défis en réduisant la dimensionalité tout en préservant les informations essentielles. Cette réduction transforme des données étendues et de haute dimensionalité en une forme plus compacte et gérable, ce qui conduit à une amélioration des performances du modèle.
Réduire la complexité computationnelle et prévenir le surapprentissage
L’extraction de caractéristiques offre deux avantages critiques pour les modèles d’apprentissage automatique:
- Exigences computationnelles plus faibles
- Moins de fonctionnalités signifient des temps d’entraînement plus rapides
- Utilisation réduite de la mémoire lors du déploiement du modèle
- Génération de prédictions plus efficace
- Meilleure généralisation
- Des espaces de fonctionnalités plus simples aident à prévenir le surajustement
- Les modèles apprennent des motifs plus robustes
- Amélioration des performances sur de nouvelles données non vues
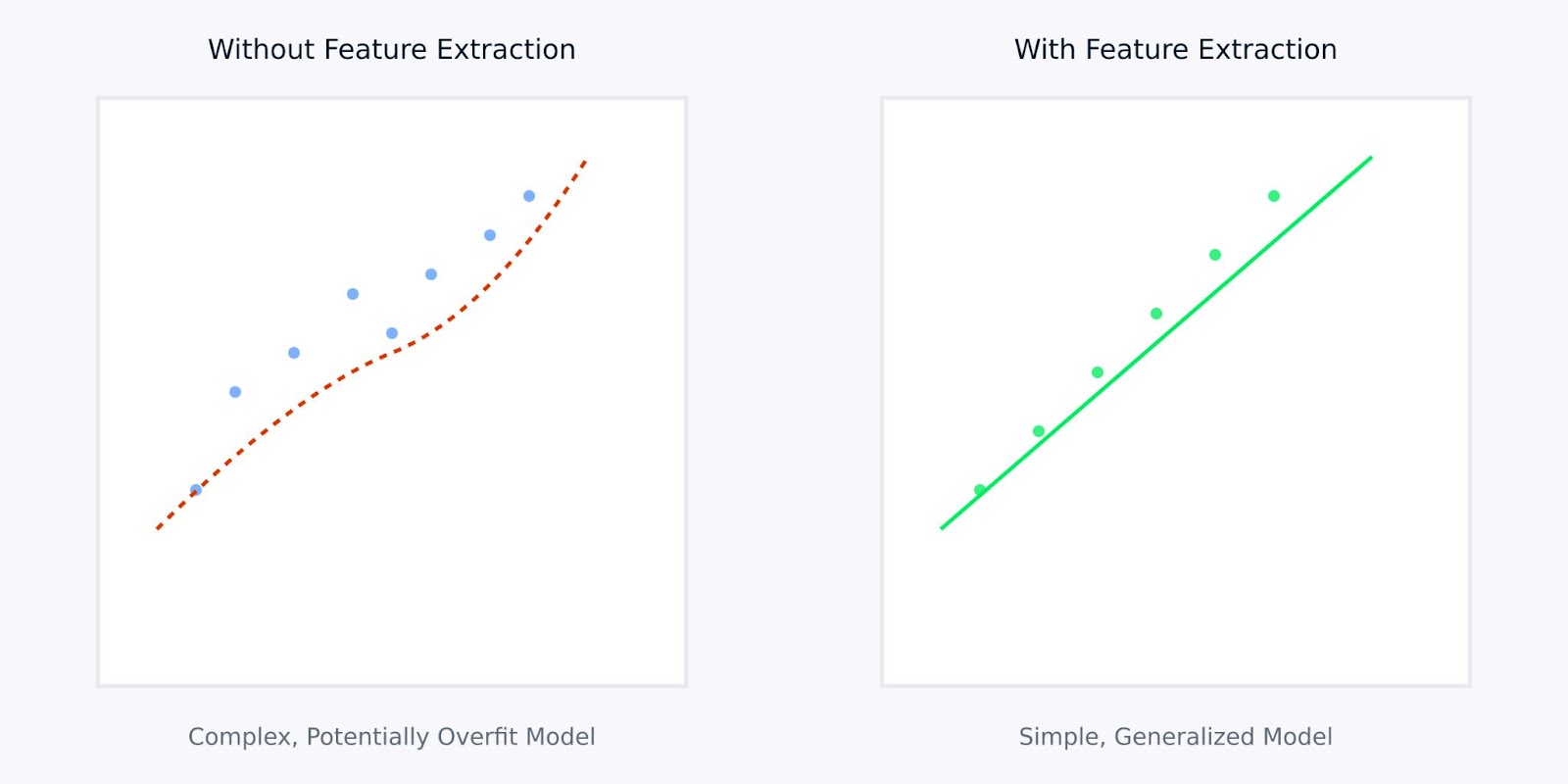
Extraction de caractéristiques par rapport à l’absence d’extraction de caractéristiques
La visualisation ci-dessus illustre comment l’extraction de caractéristiques peut conduire à des modèles plus simples et plus robustes. Le graphique de gauche montre un modèle complexe essayant de s’adapter à des données bruyantes et de haute dimension, tandis que le graphique de droite montre comment l’extraction de caractéristiques peut révéler un motif plus clair et plus généralisable.
Travailler avec des caractéristiques extraites plutôt qu’avec des données brutes revient à donner à votre modèle une version claire et condensée des informations dont il a besoin pour apprendre. Cela rend non seulement le processus d’apprentissage plus efficace, mais conduit également à des modèles plus susceptibles de bien se comporter dans des applications du monde réel.
Ensuite, voyons différentes méthodes d’extraction de caractéristiques.
Méthodes d’extraction de caractéristiques
Les méthodes d’extraction de caractéristiques peuvent être largement classées en deux approches principales : l’ingénierie de caractéristiques manuelle et l’extraction automatique de caractéristiques. Examinons ces deux méthodes pour comprendre comment elles aident à transformer les données brutes en caractéristiques significatives.
Ingénierie de caractéristiques manuelle
L’ingénierie de caractéristiques manuelle implique l’utilisation de l’expertise du domaine pour identifier et créer des caractéristiques pertinentes à partir des données brutes. Cette approche pratique repose sur notre compréhension du problème et des données pour élaborer des caractéristiques significatives.
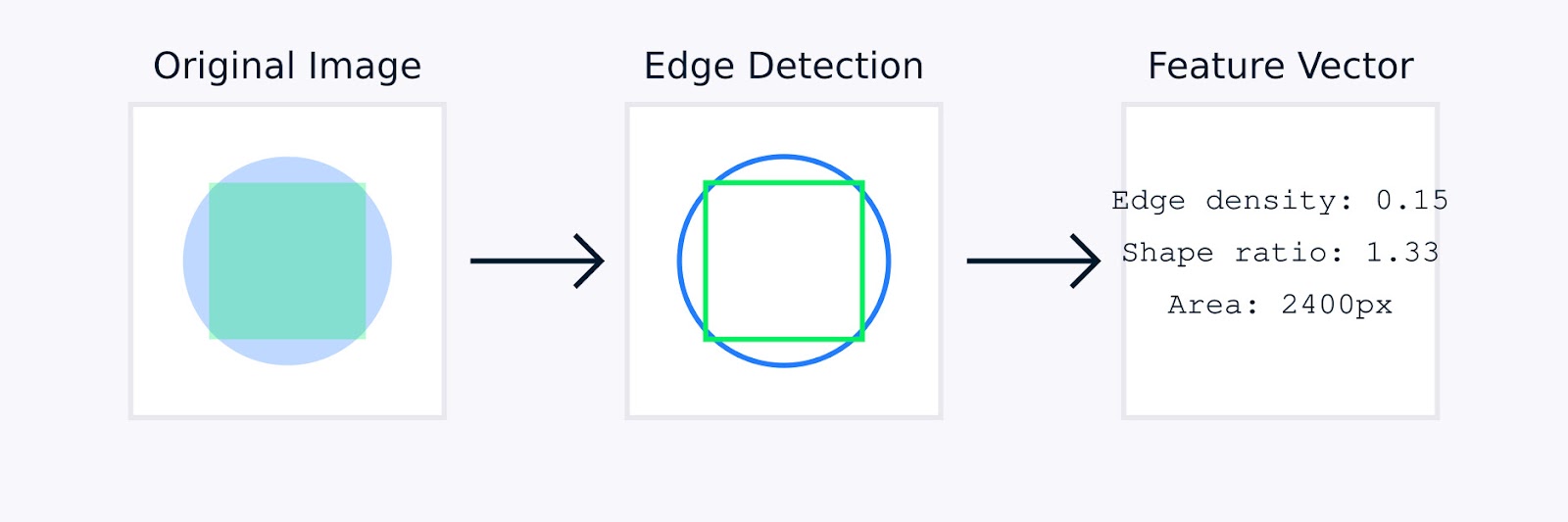
Dans le traitement d’image, l’ingénierie des fonctionnalités manuelle peut impliquer des techniques telles que la détection de contour pour identifier les limites des objets, les histogrammes de couleur pour capturer la distribution des couleurs, l’analyse de texture pour quantifier les motifs, et les descripteurs de forme pour caractériser la géométrie des objets.
Pour les données tabulaires, l’ingénierie des fonctionnalités manuelle implique la création de termes d’interaction entre les fonctionnalités existantes, la transformation des variables en utilisant des fonctions logarithmiques ou polynomiales, l’agrégation des points de données en statistiques significatives, et l’encodage des variables catégorielles.
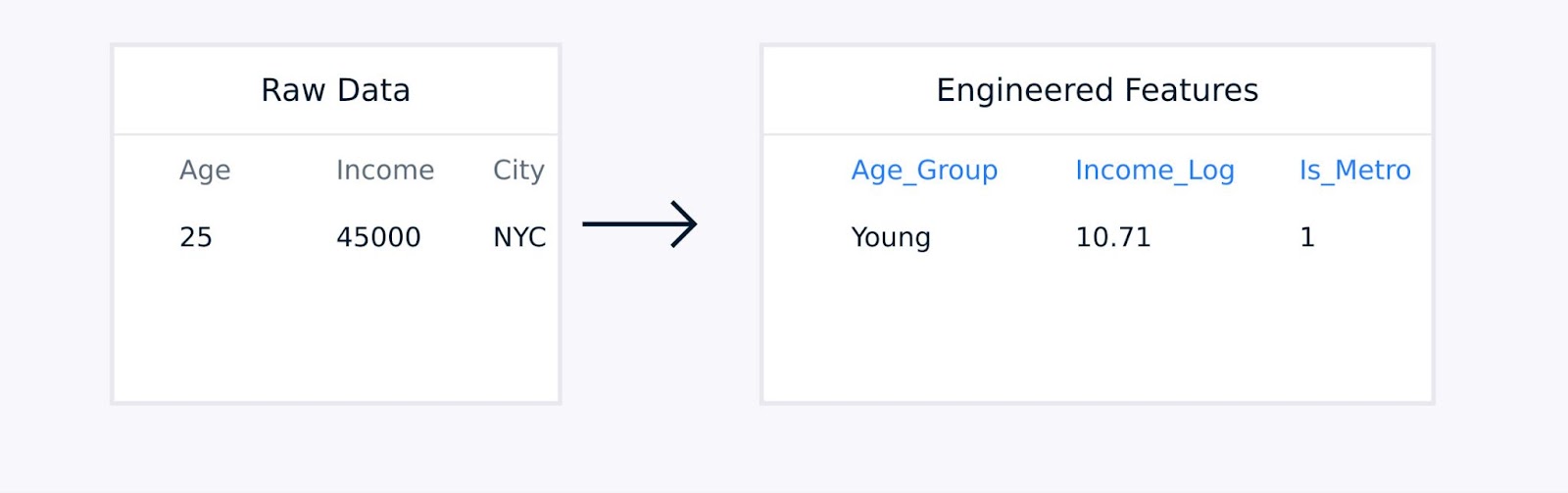
Extraction de fonctionnalités de données tabulaires
Ces techniques, guidées par l’expertise du domaine, améliorent la qualité de la représentation des données et peuvent considérablement améliorer les performances du modèle.
Extraction automatique de fonctionnalités
L’extraction automatique de fonctionnalités utilise des algorithmes pour découvrir et créer des fonctionnalités sans guidage humain explicite. Ces méthodes sont particulièrement utiles lorsqu’il s’agit de traiter des ensembles de données complexes où l’ingénierie des fonctionnalités manuelle pourrait être impraticable ou inefficace.
Les approches automatisées courantes incluent :
Analyse en composantes principales (ACP): Transforme les données en un ensemble de composantes non corrélées, chaque composante capturant la variance restante maximale. Cette approche est particulièrement utile pour la réduction de la dimensionnalité, car elle préserve l’information essentielle des données tout en simplifiant leur structure.
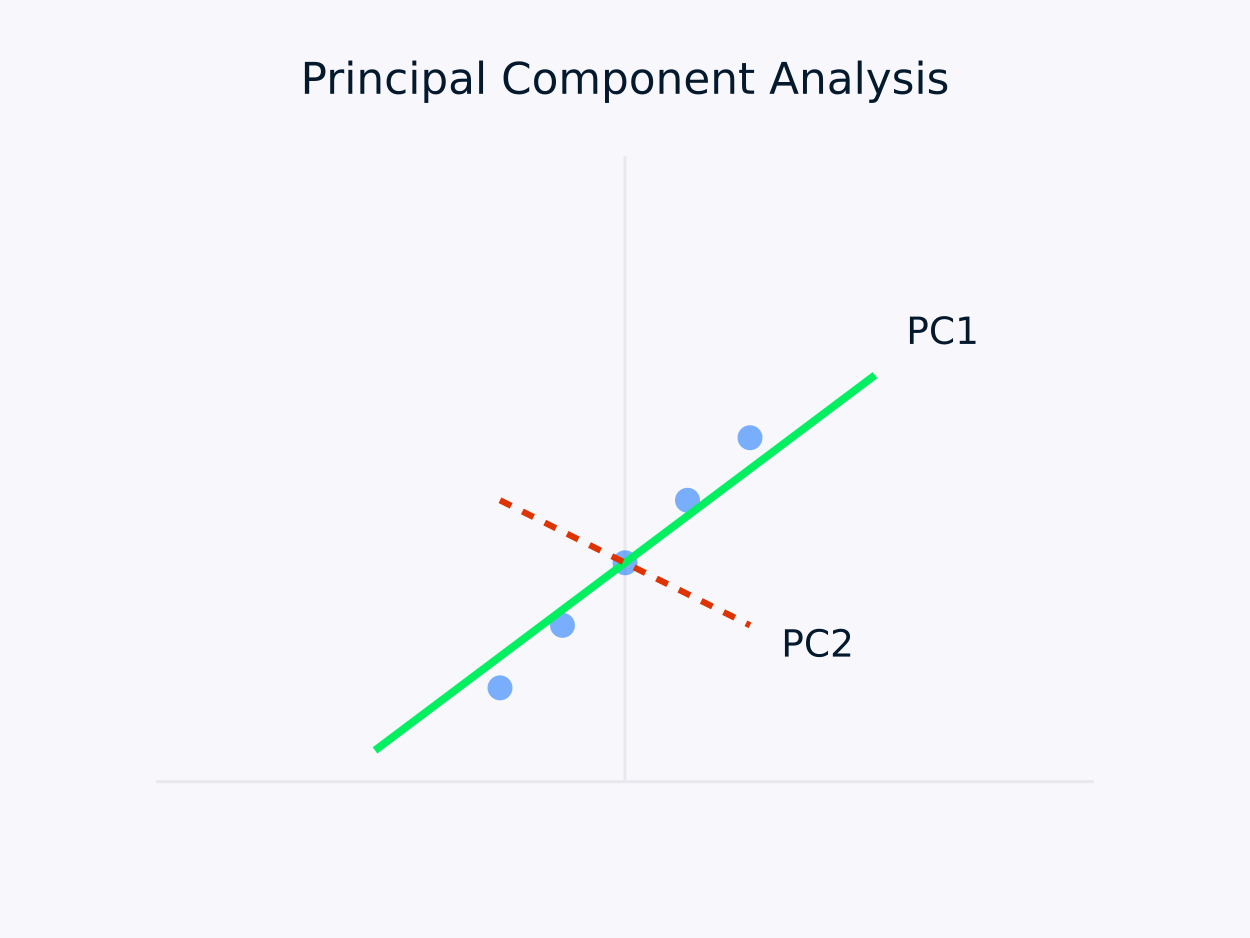
Analyse en composantes principales (ACP)
Autoencodeurs: Il s’agit de réseaux neuronaux qui apprennent des représentations compressées de données, capturant des relations non linéaires. Ils sont particulièrement efficaces pour les ensembles de données de haute dimension, où les méthodes linéaires traditionnelles pourraient être insuffisantes.
Divers outils et bibliothèques ont émergé pour simplifier les tâches d’ingénierie des fonctionnalités. Par exemple, le module de décomposition de Scikit-learn propose une gamme de méthodes de réduction de la dimensionalité, et PyCaret offre des capacités de sélection automatique des fonctionnalités.
Les approches manuelles et automatisées ont chacune leurs forces. Examinons les forces de chaque approche.
|
Ingénierie Manuelle |
Extraction Automatisée |
|
Intégration des connaissances du domaine |
Scalabilité |
|
Fonctionnalités interprétables |
Gère des motifs complexes |
|
Contrôle fin |
Réduit le biais humain |
|
Personnalisé selon des besoins spécifiques |
Découvre des relations cachées |
Le choix entre des méthodes manuelles et automatisées dépend souvent de facteurs tels que la complexité de l’ensemble de données, la disponibilité de l’expertise en domaine, les exigences en termes d’interprétabilité, les ressources de calcul et les contraintes temporelles.
Pour des ensembles de données très complexes ou lorsque le temps et les ressources sont limités, les méthodes automatisées peuvent rapidement générer des fonctionnalités utiles. À l’inverse, les méthodes manuelles peuvent être préférables lorsque l’expertise du domaine est disponible et que l’interprétabilité est une priorité, permettant un génie des fonctionnalités sur mesure qui s’aligne étroitement avec le problème en cours.
En pratique, de nombreux projets réussis d’apprentissage automatique combinent les deux approches, en utilisant l’expertise du domaine pour guider le génie des fonctionnalités tout en tirant parti des méthodes automatisées pour découvrir des motifs supplémentaires qui pourraient ne pas être immédiatement apparents pour les experts humains.
Dans la section suivante, nous examinerons plusieurs techniques d’extraction de fonctionnalités dans divers domaines.
Techniques d’extraction de fonctionnalités
Chaque type de données nécessite des techniques spécifiques d’extraction de fonctionnalités optimisées pour ses caractéristiques uniques. Examinons les techniques les plus courantes pour différents types de données.

Techniques d’extraction de caractéristiques
Extraction de caractéristiques d’image
L’extraction de caractéristiques d’image transforme les données brutes des pixels en représentations significatives qui capturent les informations visuelles essentielles. Il existe trois principales catégories de techniques utilisées dans la vision par ordinateur moderne. Ce sont les méthodes traditionnelles, les méthodes basées sur l’apprentissage profond et les méthodes statistiques.

Méthodes d’extraction de caractéristiques d’image
Examinons chacune des méthodes.
Méthodes traditionnelles de vision par ordinateur
Le Transform Invariant à l’Échelle des Caractéristiques (SIFT) est une méthode robuste qui détecte des caractéristiques locales distinctives dans les images. Il fonctionne en identifiant des points clés et en générant des descripteurs qui sont :
- Invariants par rapport à l’échelle et à la rotation de l’image
- Partiellement invariants aux changements d’éclairage
- Résistants à la distorsion géométrique locale
L’algorithme SIFT traite les images à travers plusieurs étapes. Il commence par la détection des extrema de l’espace d’échelle pour identifier les points clés potentiels qui sont invariants à l’échelle. Ensuite, la localisation des points clés affine ces candidats en pinpointant leurs emplacements précis et en éliminant les points instables.
Suite à cela, l’attribution d’orientation détermine une orientation constante pour chaque point clé, assurant l’invariance par rotation. Enfin, la génération de descripteurs de points clés crée des descripteurs distinctifs basés sur les gradients d’image locaux, facilitant la correspondance robuste entre les images.
Une autre méthode est le Histogramme de gradients orientés (HOG). Il capture les informations de forme locale en analysant les motifs de gradient à travers une image. Le processus commence par le calcul des gradients sur toute l’image pour mettre en évidence les détails des bords.
L’image est ensuite divisée en petites cellules, et pour chaque cellule, un histogramme des orientations de gradient est créé pour résumer la structure locale. Enfin, ces histogrammes sont normalisés à travers des blocs plus grands pour garantir la robustesse contre les variations d’éclairage et de contraste, ce qui donne un descripteur de fonction robuste pour des tâches comme la détection et la reconnaissance d’objets.
Méthodes d’apprentissage profond
Réseaux Neuronaux Convolutifs (CNN) ont changé notre façon d’effectuer l’extraction de caractéristiques en apprenant automatiquement des représentations hiérarchiques.

Extraction de Caractéristiques avec CNN
Les CNN apprennent des caractéristiques à travers leur structure hiérarchique. Dans les premières couches, ils détectent des éléments visuels de base tels que les contours et les couleurs. Les couches intermédiaires combinent ensuite ces éléments pour reconnaître des motifs et des formes, tandis que les couches plus profondes capturent des objets complexes et permettent la compréhension de scènes.
L’apprentissage par transfert nous permet d’utiliser ces caractéristiques pré-apprises provenant de modèles entraînés sur de grands ensembles de données, les rendant particulièrement précieuses lorsqu’on travaille avec des données limitées.
Méthodes statistiques
Les méthodes statistiques extraient à la fois des motifs globaux et locaux des images, facilitant une analyse et une interprétation robustes des images.
Par exemple, les histogrammes de couleur représentent la distribution des couleurs dans une image et fournissent des caractéristiques invariantes par rotation et échelle, les rendant particulièrement utiles pour des tâches telles que la classification et la recherche d’images.
L’analyse de texture capture les motifs répétés et les caractéristiques de surface en utilisant des techniques comme les matrices de co-occurrence de niveaux de gris (GLCM), qui sont efficaces pour des applications telles que la reconnaissance de matériaux et la classification de scènes.
De plus, la détection de contours identifie les limites et les changements d’intensité significatifs à travers des méthodes telles que les opérateurs Sobel, Canny et Laplacien, jouant un rôle crucial dans la détection d’objets et l’analyse de forme.
Le choix de la méthode d’extraction de caractéristiques dépend de plusieurs facteurs. Elle doit être en accord avec les exigences spécifiques de votre tâche, tenir compte des ressources informatiques disponibles et prendre en compte le besoin d’interprétabilité.
De plus, les caractéristiques de votre jeu de données, telles que sa taille, ses niveaux de bruit et sa complexité, jouent un rôle crucial, tout comme les propriétés d’invariance requises telles que l’échelle, la rotation et l’illumination.
Extraction de caractéristiques audio
Imaginez essayer d’apprendre à un ordinateur à comprendre la parole comme le font les humains. C’est là que les coefficients cepstraux en fréquence Mel (MFCC) entrent en jeu.
Les MFCC sont des caractéristiques audio spéciales qui décomposent le son d’une manière similaire à la façon dont nos oreilles le traitent. Ils sont particulièrement efficaces car ils se concentrent sur les fréquences auxquelles les humains sont les plus sensibles. Pensez à eux comme à une traduction du son dans un format que les ordinateurs et l’audition humaine trouveraient significatif.
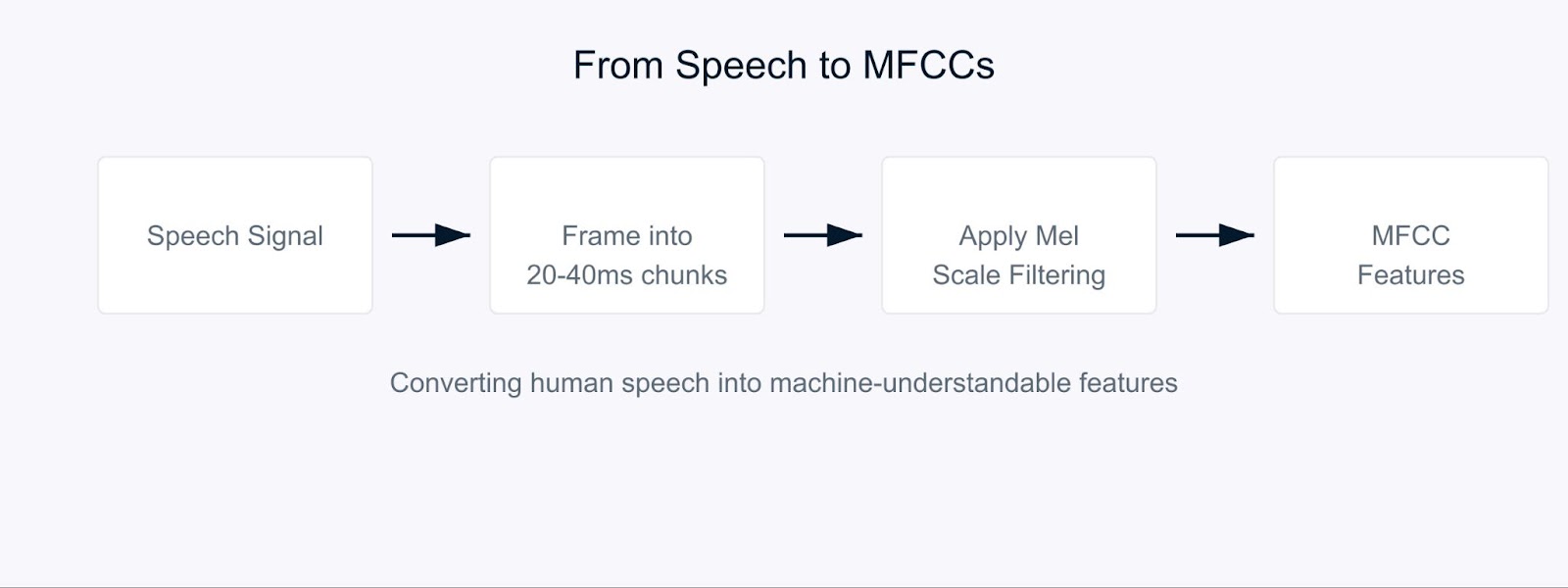
Coefficients Cepstraux en Fréquence Mel
Le processus commence par la décomposition du signal audio en courts segments, généralement de 20 à 40 millisecondes. Pour chaque segment, nous appliquons une série de transformations mathématiques qui convertissent les ondes sonores brutes en composants de fréquence. C’est là que cela devient intéressant. Au lieu de traiter toutes les fréquences de manière égale, nous utilisons quelque chose appelé l’échelle Mel.
![]()
Cette formule peut sembler complexe, mais elle se contente de mapper les fréquences pour correspondre à la façon dont les humains perçoivent le son. Nos oreilles sont meilleures pour détecter les différences dans les basses fréquences que dans les plus élevées, et l’échelle de Mel tient compte de ce biais naturel.
Dans la reconnaissance vocale, les MFCC servent de base pour comprendre qui parle et ce qu’il dit. Lorsque vous parlez à l’assistant virtuel de votre téléphone, il utilise probablement des MFCC pour traiter votre voix. Ces coefficients aident à capturer les caractéristiques uniques de la voix de chaque personne, ce qui les rend inestimables pour les systèmes d’identification des locuteurs.
Pour l’analyse des sentiments dans la parole, les MFCC aident à détecter les variations subtiles de la voix qui indiquent les émotions. Ils peuvent capturer les changements de hauteur, de tonalité et de débit de parole qui pourraient indiquer si quelqu’un est heureux, triste, en colère ou neutre. Par exemple, lors de l’analyse des appels de service client, les MFCC peuvent aider à identifier les niveaux de satisfaction des clients en fonction de leur manière de parler, pas seulement de ce qu’ils disent.
Extraction de caractéristiques de séries temporelles
Lorsque vous travaillez avec séries temporelles données, extraire des caractéristiques significatives nous aide à capturer des motifs et des tendances qui évoluent avec le temps. Examinons quelques techniques clés utilisées pour transformer les données brutes de séries temporelles en caractéristiques utiles.

Méthodes d’extraction de caractéristiques de séries temporelles
La transformée de Fourier décompose les données de séries temporelles en ses composantes de fréquence, révélant des motifs périodiques cachés. La formule est :
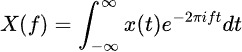
Les méthodes statistiques complètent l’analyse de fréquence en capturant les caractéristiques temporelles. Les fonctionnalités communes incluent les moyennes mobiles, les écarts-types et les composantes de tendance. Ces techniques sont particulièrement puissantes dans la prévision financière, où elles aident à identifier les tendances du marché et les anomalies.
Par exemple, dans l’analyse du marché boursier, combiner les caractéristiques de Fourier avec des mesures statistiques peut révéler à la fois les tendances à long terme et les motifs cycliques. De même, dans les environnements industriels, ces méthodes aident à détecter les anomalies d’équipement en analysant les motifs de données des capteurs au fil du temps.
Outils et bibliothèques pour l’extraction de fonctionnalités
Jetons un coup d’œil à quelques outils essentiels qui rendent la mise en œuvre de ces méthodes d’extraction de fonctionnalités simple et efficace.
Outils et bibliothèques pour l’extraction de fonctionnalités
Pour le traitement d’images, OpenCV et scikit-image offrent des outils complets pour la mise en œuvre de diverses techniques d’extraction de fonctionnalités. Ces bibliothèques proposent des implémentations efficaces de SIFT, HOG et d’autres algorithmes que nous avons discutés précédemment. Lorsque vous travaillez avec des approches d’apprentissage profond, des frameworks comme TensorFlow et PyTorch deviennent inestimables. Vous pouvez commencer avec notre tutoriel OpenCV pour en savoir plus.
Les tâches de traitement audio sont simplifiées avec des bibliothèques comme LibROSA, qui excelle dans l’extraction des MFCC et d’autres caractéristiques acoustiques. PyAudioAnalysis étend ces capacités avec des interfaces de haut niveau pour les tâches d’analyse audio.
Pour les données de séries temporelles, tsfresh et Featuretools automatisent le processus d’extraction des caractéristiques. Ces bibliothèques peuvent générer et sélectionner automatiquement des caractéristiques pertinentes à partir de vos données temporelles, ce qui facilite la concentration sur le développement du modèle plutôt que sur l’ingénierie des caractéristiques.
Exemple d’extraction de caractéristiques
Mettons nos connaissances en pratique avec quelques exemples pratiques. Nous commencerons par l’extraction de caractéristiques d’images, l’une des applications les plus courantes en vision par ordinateur.
Extraction de caractéristiques d’images à l’aide d’OpenCV
Tout d’abord, importons les bibliothèques nécessaires
# Importer les bibliothèques requises import cv2 import numpy as np import matplotlib.pyplot as plt
Maintenant, chargeons une image pour extraire des fonctionnalités pertinentes. Pour cet exemple, nous utiliserons une image de Godzilla téléchargée depuis internet.
# Charger l'image image = cv2.imread('godzilla.jpg') # Convertir de BGR à RGB (OpenCV charge en format BGR) image_rgb = cv2.cvtColor(image, cv2.COLOR_BGR2RGB) # Afficher l'image d'origine plt.imshow(image_rgb) plt.title('Original Image') plt.axis('off') plt.show()
Sortie:

Avant d’appliquer la détection de bord, nous devons prétraiter notre image. Nous le faisons comme suit:
# Convertir l'image en niveaux de gris gray_image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY) # Appliquer un flou gaussien pour réduire le bruit blurred = cv2.GaussianBlur(gray_image, (5, 5), 0)
Enfin, appliquons l’algorithme de détection de bord Canny et visualisons les résultats:
# Appliquer la détection de contours de Canny edges = cv2.Canny(blurred, threshold1=100, threshold2=200) # Afficher les résultats plt.figure(figsize=(10, 5)) plt.subplot(1, 2, 1) plt.imshow(image_rgb) plt.title('Original Image') plt.axis('off') plt.subplot(1, 2, 2) plt.imshow(edges, cmap='gray') plt.title('Edge Detection') plt.axis('off') plt.tight_layout() plt.show()
Sortie :

Le détecteur de contours de Canny nous aide à identifier des frontières et des caractéristiques importantes dans notre image, qui peuvent être utilisées pour une analyse plus approfondie ou comme entrée pour des modèles d’apprentissage automatique.
Extraction des MFCC à partir de l’audio en utilisant LibROSA
Avant de pouvoir commencer à traiter des fichiers audio, nous devons installer les bibliothèques requises. Comme LibROSA n’est pas inclus dans la bibliothèque standard de Python, nous allons l’installer avec pip :
# Installer les bibliothèques requises # Exécutez ces commandes dans votre terminal ou invite de commande pip install librosa pip install numpy pip install matplotlib
LibROSA est une bibliothèque puissante conçue pour l’analyse musicale et audio, alors commençons par l’importer avec d’autres bibliothèques nécessaires :
# Importez les bibliothèques requises import librosa import librosa.display import numpy as np import matplotlib.pyplot as plt
Les fichiers audio contiennent beaucoup d’informations au format d’onde. Pour travailler avec ces données, nous devons d’abord les charger dans notre programme. LibROSA nous aide à le faire en convertissant le fichier audio dans un format que nous pouvons analyser:
# Charger le fichier audio # La durée est limitée à 10 secondes pour cet exemple audio_path = 'audio_sample.wav' y, sr = librosa.load(audio_path, duration=10) # Afficher la forme d'onde plt.figure(figsize=(10, 4)) plt.plot(y) plt.title('Audio Waveform') plt.show()
Sortie:
Maintenant que notre audio est chargé, nous devons extraire des caractéristiques significatives. Nos oreilles décomposent naturellement le son en différentes composantes de fréquence, et les MFCC imitent ce processus. Nous utilisons la fonction d’extraction de caractéristiques de librosa pour calculer ces coefficients:
# Extraire les caractéristiques MFCC mfccs = librosa.feature.mfcc(y=y, sr=sr, n_mfcc=13) # Afficher les MFCC plt.figure(figsize=(10, 4)) librosa.display.specshow(mfccs, x_axis='time') plt.colorbar(format='%+2.0f dB') plt.title('MFCC') plt.show()
Sortie :
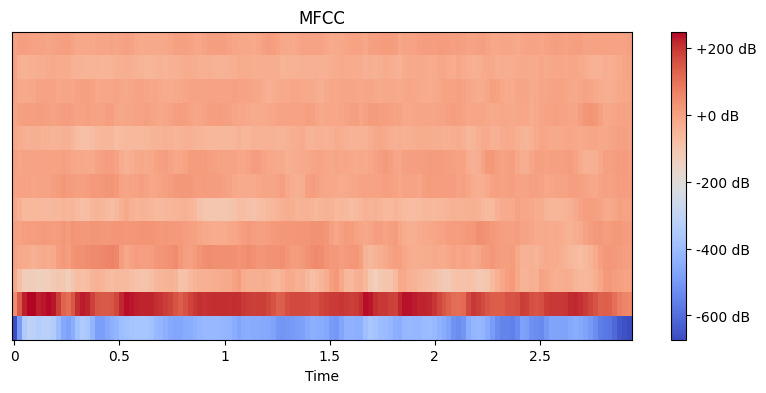
Ici, nous définissons n_mfcc=13 car les 13 premiers coefficients capturent généralement les aspects les plus importants du son qui aident dans des tâches comme la reconnaissance vocale. La visualisation résultante montre comment ces caractéristiques changent au fil du temps, où les couleurs plus claires représentent des valeurs plus élevées.
Extraction de caractéristiques à partir de données de séries temporelles avec tsfresh
Tout d’abord, installons les bibliothèques requises. Nous utiliserons yfinance pour obtenir des données financières, ainsi que tsfresh pour l’extraction de caractéristiques :
# Installer les bibliothèques requises # Exécutez ces commandes dans votre terminal ou votre invite de commandes pip install tsfresh pip install pandas pip install numpy pip install matplotlib pip install yfinance
Maintenant importons nos bibliothèques et récupérons quelques données financières réelles :
# Importez les bibliothèques requises import pandas as pd import numpy as np from tsfresh import extract_features from tsfresh.feature_extraction import MinimalFCParameters import matplotlib.pyplot as plt import yfinance as yf
Obtenons des données réelles du marché boursier. Nous utiliserons les données boursières d’Apple comme exemple :
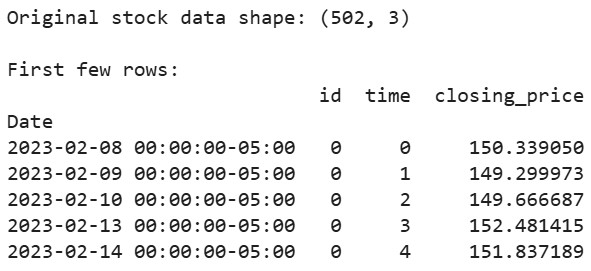
# Téléchargez les données boursières d'Apple des 2 dernières années aapl = yf.Ticker("AAPL") df = aapl.history(period="2y") # Préparez les données dans le format attendu par tsfresh df_tsfresh = pd.DataFrame({ 'id': [0] * len(df), # Chaque série temporelle a besoin d'un ID 'time': range(len(df)), 'closing_price': df['Close'] # Nous utiliserons les prix de clôture }) # Affichez les premières lignes de nos données print("Original stock data shape:", df_tsfresh.shape) print("\nFirst few rows:") print(df_tsfresh.head())
Sortie :
Maintenant, extrayons des caractéristiques de nos données financières de séries temporelles :
# Configurez les paramètres d'extraction des caractéristiques extraction_settings = MinimalFCParameters() # Extrayez automatiquement les caractéristiques extracted_features = extract_features(df_tsfresh, column_id='id', column_sort='time', column_value='values', default_fc_parameters=extraction_settings) # Affichez les caractéristiques extraites print("\nExtracted features shape:", extracted_features.shape) print("\nExtracted features:") print(extracted_features.head())
Sortie:

Ici, nous utilisons MinimalFCParameters() pour spécifier les caractéristiques à extraire. Cela nous donne un ensemble de base de caractéristiques de séries temporelles significatives telles que la moyenne, la variance et les caractéristiques de tendance, qui sont essentielles pour comprendre les motifs dans nos données.
Défis de l’extraction de caractéristiques
Lorsque nous travaillons sur l’extraction de caractéristiques, nous rencontrons souvent des défis.
La haute dimensionnalité et les contraintes computationnelles surviennent souvent lors du traitement de grands ensembles de données. Par exemple, extraire des caractéristiques à partir d’images haute résolution ou de longs fichiers audio peut consommer une mémoire et une puissance de traitement significatives.
Le surapprentissage dû à des caractéristiques non pertinentes ou redondantes est un autre défi courant. Lorsque trop de caractéristiques sont extraites, les modèles peuvent apprendre du bruit au lieu de motifs significatifs. C’est particulièrement fréquent dans le traitement d’images et de l’audio où des milliers de caractéristiques peuvent être générées.
Pour surmonter ces défis, envisagez ces stratégies :
- Utilisez les connaissances du domaine pour sélectionner les caractéristiques pertinentes
- Appliquez des méthodes de sélection de caractéristiques pour réduire la dimensionnalité
- Mettez en œuvre des techniques d’ingénierie des caractéristiques appropriées en fonction de votre type de données
Ces défis nécessitent une considération minutieuse et un équilibre entre la richesse des fonctionnalités et l’efficacité computationnelle.
Conclusion
L’extraction de caractéristiques est une compétence fondamentale en apprentissage automatique qui transforme les données brutes en représentations significatives. À travers nos exemples pratiques avec OpenCV, LibROSA et tsfresh, nous avons vu comment extraire des fonctionnalités de différents types de données. En comprenant ces techniques et leurs défis, nous pouvons construire des modèles d’apprentissage automatique efficaces.
Prêt à aller plus loin? Consultez ces ressources:
Source:
https://www.datacamp.com/tutorial/feature-extraction-machine-learning