













在過去幾年中,變壓器已經改變了機器學習中的 NLP 領域。像 GPT 和 BERT 這樣的模型在理解和生成自然語言方面設立了新的基準。現在同樣的原則也被應用於計算機視覺領域。
最近在計算機視覺領域的發展是視覺變壓器或 ViTs。正如論文“一張圖片價值 16×16 個詞:用於大規模圖像識別的變壓器”中詳細說明的那樣,ViTs 和基於變壓器的模型旨在取代卷積神經網絡(CNNs)。
視覺變壓器是解決計算機視覺問題的一種新方法。ViTs 不再依賴傳統的卷積神經網絡(CNNs),這些網絡幾十年來一直是圖像相關任務的支柱,而是使用變壓器架構來處理圖像。它們將圖像塊視為句子中的單詞,使模型能夠學習這些塊之間的關係,就像它學習文本段落中的上下文一樣。
與CNN不同,ViTs將輸入圖像分成多個塊,將它們序列化為向量,並使用矩陣乘法降低它們的維度。然後,一個Transformer編碼器處理這些向量作為令牌嵌入。在本文中,我們將探討視覺Transformer及其與卷積神經網絡的主要區別。使它們特別有趣的是它們能夠理解圖像中的全局模式,這是CNN可能會遇到困難的地方。
先決條件
- 神經網絡基礎知識:了解神經網絡如何處理數據。
- 卷積神經網絡(CNNs):熟悉CNN及其在計算機視覺中的作用。
- Transformer架構:了解Transformer,特別是它們在NLP中的應用。
- 圖像處理:理解基本概念,如圖像表示、通道和像素陣列。
- 注意機制:理解自注意力及其在跨輸入模型關係中的建模能力。
什麼是視覺Transformer?
視覺轉換器使用注意力和變壓器的概念來處理圖像,這與自然語言處理(NLP)中的變壓器類似。然而,它不是使用標記,而是將圖像分割成補丁,並提供作為線性嵌入序列。這些補丁被視為在NLP中處理標記或單詞的方式。
視覺轉換器不是同時觀看整個圖像,而是像拼圖一樣將圖像切成小塊。每個塊被轉換為描述其特徵的數字列表(向量),然後模型查看所有塊並使用變壓器機制來找出它們之間的關係。
與CNN不同,視覺轉換器是通過對圖像應用特定的過濾器或內核來檢測特定特徵,例如邊緣模式。這就是卷積過程,非常類似於打印機掃描圖像。這些過濾器在整個圖像上滑動並突出顯著特徵。然後,網絡堆疊多層這些過濾器,逐漸識別更複雜的模式。
在CNN中,池化層減小了特徵圖的大小。這些層分析提取的特徵,以進行對圖像識別、物體檢測等有用的預測。然而,CNN具有固定的感知域,從而限制了建模長距離依賴性的能力。
CNN如何看待圖像?
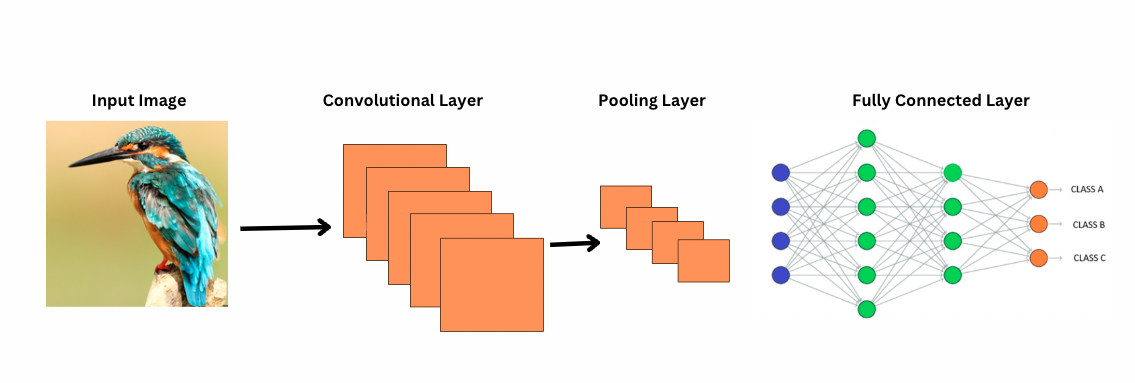
ViTs 儘管擁有更多的參數,但使用自我注意力機制以實現更好的特徵表示,並減少對更深層次的需求。CNNs 需要顯著更深的架構來實現類似的表示能力,這導致計算成本的增加。
此外,CNNs 無法捕捉全局級別的圖像模式,因為它們的濾波器專注於圖像的局部區域。為了理解整個圖像或遠距離的關係,CNNs 依賴於堆疊多層和池化,以擴大視野。然而,這個過程可能會在逐步聚合細節時失去全局信息。
另一方面,ViTs 將圖像劃分為補丁,這些補丁被視為獨立的輸入標記。使用自我注意力,ViTs 同時比較所有補丁並學習它們之間的關係。這使它們能夠捕捉整幅圖像中的模式和依賴性,而無需逐層構建。
什麼是歸納偏差?
在深入探討之前,了解 歸納偏差 的概念非常重要。歸納偏差指的是模型對數據結構所做的假設;在訓練過程中,這有助於模型更具通用性並減少偏見。在 CNNs 中,歸納偏差包括:
- 局部性:圖像中的特徵(如邊緣或紋理)是在小區域內定位的。
- 二維鄰域結構:附近的像素更有可能相關,因此過濾器在空間上相鄰的區域上操作。
- 翻譯等變性:在圖像一部分檢測到的特徵,例如邊緣,如果在另一部分出現,則保持相同的意義。
這些偏差使得 CNN 在圖像任務中高度有效,因為它們天生設計用來利用圖像的空間和結構特性。
視覺變壓器(ViT)相比 CNN 擁有顯著較少的圖像特定歧義。在 ViT 中:
- 全局處理:自注意力層在整個圖像上運作,使模型捕捉全局關係和依賴,而不受局部區域的限制。
- 最小 2D 結構:圖像的 2D 結構僅在開始時(當圖像被劃分成補丁時)和在微調期間使用(調整不同解析度的位置信息)。與 CNN 不同,ViT 不假設附近的像素必然相關。
- 學習的空間關係:ViT 中的位置信息在初始化時不編碼特定的 2D 空間關係。相反,模型在訓練期間從數據中學習所有空間關係。
視覺變壓器的工作原理
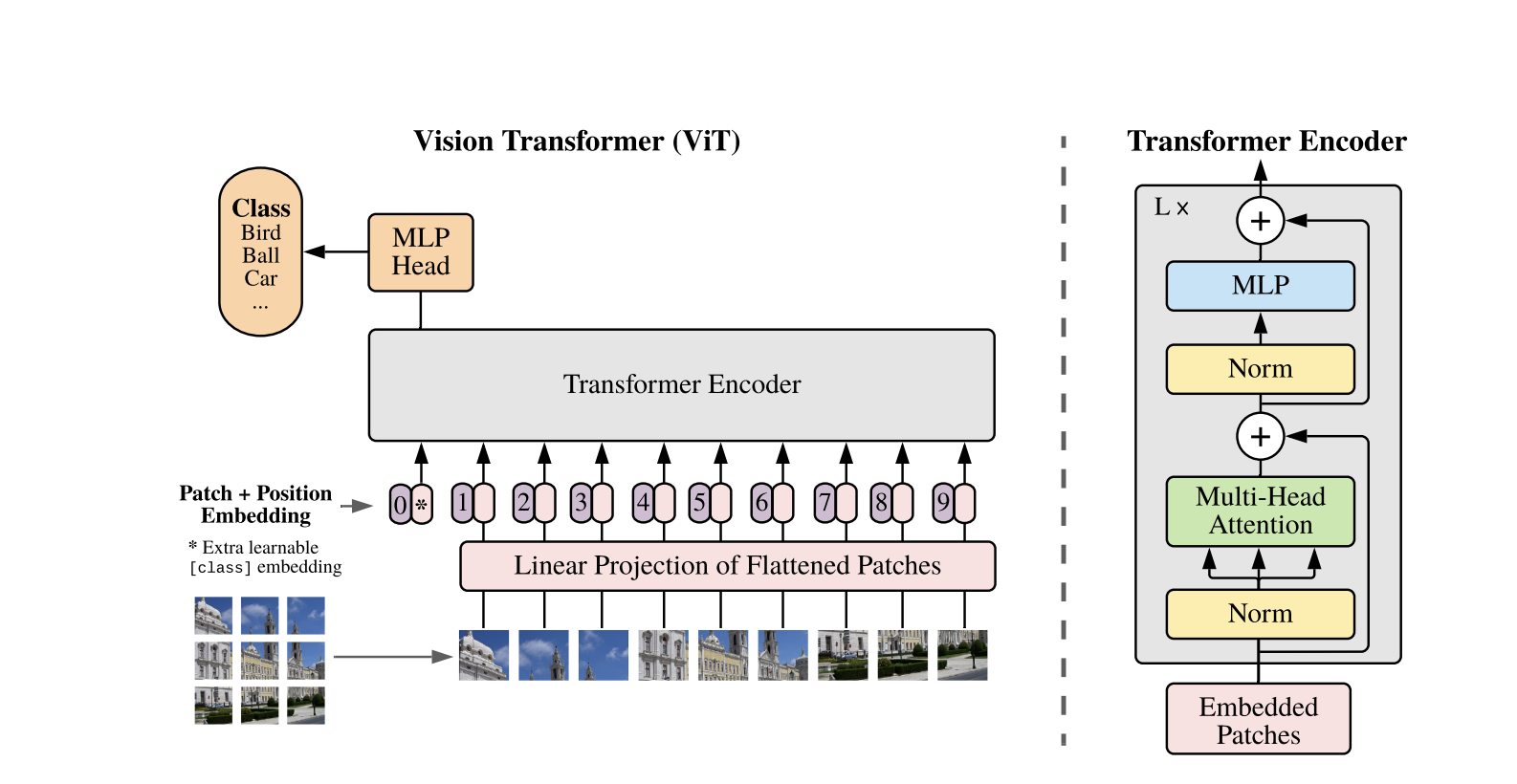
Vision Transformers 使用為 1D 文本序列開發的標準 Transformer 架構。為了處理 2D 圖像,將它們劃分為固定大小的較小补丁,例如 P×P 像素,然後將其展平為向量。如果圖像的尺寸為 H×W 且有 C 個通道,則补丁的總數為 N = H×W / P×P,這是 Transformer 的有效輸入序列長度。這些展平的补丁然後被線性投影到一個固定維度空間 D,稱為补丁嵌入。
一個特殊的可學習標記被添加到补丁嵌入序列的開頭,類似於 BERT 中的 [CLS] 標記。這個標記學習一個全局圖像表示,後來用於分類。此外,還添加了位置嵌入到补丁嵌入中,以編碼位置信息,幫助模型理解圖像的空間結構。
嵌入序列通過Transformer編碼器,該編碼器在兩個主要操作之間交替進行:多頭自注意力(MSA)和前向神經網絡,也被稱為MLP塊。每一層都包括層正則化(LN)在這些操作之前應用,之後添加殘差連接以穩定訓練。Transformer編碼器的輸出,特別是[CLS]標記的狀態,被用作圖像的表示。
對於分類任務,在最終[CLS]標記中添加了一個簡單的頭。在預訓練期間,這個頭是一個小型多層感知器(MLP),而在微調期間,它通常是一個單線性層。這種架構使得ViT能夠有效地建模补丁之间的全局關係,並利用自注意的全部威力來理解圖像。
在混合Vision Transformer模型中,不是直接將原始圖像分成補丁,而是從CNN生成的特征映射中衍生輸入序列。CNN首先處理圖像,提取有意義的空間特征,然後用於創建補丁。這些補丁被展平並使用與標准Vision Transformer中相同的可訓練線性投影投影到固定維度空間。這種方法的一個特例是使用大小為1×1的補丁,其中每個補丁對應於CNN特征映射中的單個空間位置。
在這種情況下,特徵圖的空間維度被展平,並將結果序列投影到Transformer的輸入維度。與標準的ViT一樣,添加了一個分類標記和位置嵌入,以保留位置信息並實現全局圖像理解。這種混合方法利用了CNN的局部特徵提取能力,同時將其與Transformer的全局建模能力結合起來。
代碼示範
以下是如何在圖像上使用視覺轉換器的代碼塊。
ViT模型處理圖像。它包括一個類似BERT的編碼器和一個位於[CLS]標記最終隱藏狀態頂部的線性分類頭。
這是使用PyTorch的基本Vision Transformer(ViT)實現。此代碼包括核心組件:补丁嵌入、位置編碼和Transformer編碼器。這可以用於簡單的分類任務。
關鍵組件:
- 補丁嵌入: 圖像被劃分為更小的補丁,扁平化並線性轉換為嵌入。
- 位置編碼: 將位置信息添加到補丁嵌入中,因為變壓器對位置不敏感。
- 變壓器編碼器: 應用自注意力和前饋層來學習補丁之間的關係。
- 分類頭部: 使用CLS token輸出類別概率。
您可以使用像Adam這樣的優化器和像交叉熵這樣的損失函數在任何圖像數據集上訓練這個模型。為了獲得更好的性能,請考慮在微調之前對大型數據集進行預訓練。
熱門後續工作
-
DeiT(高效數據圖像轉換) by Facebook AI: 這些是使用知識蒸餾高效訓練的視覺轉換器。DeiT提供四個變體: deit-tiny, deit-small, 和兩個 deit-base 模型。使用
DeiTImageProcessor來準備圖像。 -
微軟研究院的BEiT(BERT圖像Transformer的預訓練):受BERT啟發,BEiT使用自監督遮罩圖像建模,表現優於監督式ViTs。它依賴VQ-VAE進行訓練。
-
Facebook AI的DINO(自我監督視覺Transformer訓練):經DINO訓練的ViTs能夠在沒有明確訓練的情況下分割物件。在線提供檢查點。
-
Facebook通過重建遮罩補丁(75%)來預先訓練ViTs的MAE(Masked Autoencoders)。當進行微調時,這種簡單的方法超越了監督式預訓練。
結論
總之,ViTs作為CNN的優秀替代品,將變壓器應用於圖像識別,最小化歸納偏差,並將圖像視為序列補丁。這種簡單而可擴展的方法在許多圖像分類基準測試中展現了最先進的性能,特別是在與大型數據集的預訓練配對時。然而,仍然存在潛在挑戰,包括將ViTs擴展到對象檢測和分割等任務,進一步改進自監督式預訓練方法,以及探索將ViTs擴展至更好性能的潛力。
其他資源
Source:
https://www.digitalocean.com/community/tutorials/vision-transformer-for-computer-vision