













خلال السنوات القليلة الماضية، قامت التحويلات بتحويل مجال NLP في تعلم الآلة. نماذج مثل GPT و BERT قد حددت مقاييس جديدة في فهم وتوليد اللغة البشرية. الآن نفس المبدأ يُطبق على مجال رؤية الحاسوب.
آخر تطور في مجال رؤية الحاسوب هي المحولات البصرية أو ViTs. كما هو مفصل في الورقة “صورة تستحق 16×16 كلمة: المحولات لتمييز الصور بمقياس واسع”، تم تصميم ViTs والنماذج القائمة على المحولات لاستبدال الشبكات العصبية التكرارية التجريبية (CNNs).
المحولات البصرية هي نهج جديد لحل المشاكل في رؤية الحاسوب. بدلاً من الاعتماد على الشبكات العصبية التكرارية التقليدية (CNNs)، التي كانت العمود الفقري للمهام المتعلقة بالصور لعقود، يستخدم ViTs هندسة المحول لمعالجة الصور. إنها تعامل بالتقسيمات الصورية مثل الكلمات في جملة، مما يسمح للنموذج بتعلم العلاقات بين هذه التقسيمات، تمامًا كما يتعلم السياق في فقرة نص.
على عكس الشبكات العصبية التلافيفية (CNNs)، تقوم محولات الرؤية (ViTs) بتقسيم الصور المدخلة إلى قطع، وتحويلها إلى متجهات، وتقليل أبعادها باستخدام ضرب المصفوفات. ثم يقوم مشفر المحول بمعالجة هذه المتجهات كتمثيلات رمزية. في هذه المقالة، سنستكشف محولات الرؤية واختلافاتها الرئيسية عن الشبكات العصبية التلافيفية. ما يجعلها مثيرة للاهتمام بشكل خاص هو قدرتها على فهم الأنماط العالمية في الصورة، وهو شيء قد تعاني منه الشبكات العصبية التلافيفية.
المتطلبات الأساسية
- أساسيات الشبكات العصبية: فهم كيفية معالجة الشبكات العصبية للبيانات.
- الشبكات العصبية التلافيفية (CNNs): الإلمام بالشبكات العصبية التلافيفية ودورها في رؤية الكمبيوتر.
- هندسة المحولات: معرفة بالمحولات، وخاصة استخدامها في معالجة اللغة الطبيعية.
- معالجة الصور: فهم المفاهيم الأساسية مثل تمثيل الصورة، والقنوات، ومصفوفات البكسل.
- آلية الانتباه: فهم الانتباه الذاتي وقدرته على نمذجة العلاقات عبر المدخلات.
ما هي محولات الرؤية؟
تستخدم المحولات البصرية مفهوم الانتباه والمحولات لمعالجة الصور – وهذا مشابه للمحولات في سياق معالجة اللغة الطبيعية (NLP). ومع ذلك، بدلاً من استخدام الرموز، يتم تقسيم الصورة إلى قطع وتقديمها كسلسلة من التضمينات الخطية. تُعامل هذه القطع بنفس الطريقة التي تُعامل بها الرموز أو الكلمات في معالجة اللغة الطبيعية.
بدلاً من النظر إلى الصورة بأكملها في وقت واحد، يقوم نموذج في آي تي (ViT) بتقسيم الصورة إلى قطع صغيرة مثل لغز الصور. يتم تحويل كل قطعة إلى قائمة من الأرقام (متجه) تصف ميزاتها، ثم ينظر النموذج إلى جميع القطع ويكتشف كيفية ارتباطها ببعضها البعض باستخدام آلية المحول.
على عكس الشبكات العصبية الالتفافية (CNNs)، يعمل نموذج في آي تي (ViTs) عن طريق تطبيق مرشحات أو نوى محددة على الصورة لاكتشاف ميزات معينة، مثل أنماط الحواف. هذه هي عملية الالتفاف التي تشبه إلى حد كبير مسح الطابعة لصورة. تنزلق هذه المرشحات عبر الصورة بأكملها وتسلط الضوء على الميزات المهمة. ثم يقوم الشبكة بتكديس عدة طبقات من هذه المرشحات، مما يتيح التعرف تدريجياً على أنماط أكثر تعقيدًا.
مع الشبكات العصبية الالتفافية، تقلل طبقات التجميع من حجم خرائط الميزات. تقوم هذه الطبقات بتحليل الميزات المستخرجة لإجراء توقعات مفيدة لتمييز الصور، واكتشاف الكائنات، وما إلى ذلك. ومع ذلك، تتمتع الشبكات العصبية الالتفافية بحقل استقبال ثابت، مما يحد من القدرة على نمذجة الاعتماديات طويلة المدى.
كيف ترى الشبكات العصبية الالتفافية الصور؟
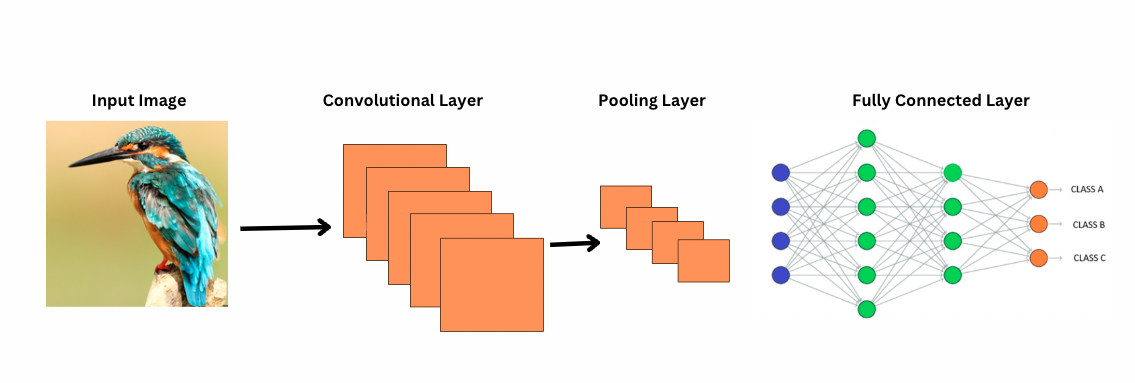
تستخدم شبكات النقاط الظاهرية الانتباه الذاتي لتمثيل الميزات بشكل أفضل وتقليل الحاجة إلى طبقات أعمق، على الرغم من وجود معلمات أكثر. تتطلب الشبكات العصبية التصنيفية بنية أعمق بشكل كبير لتحقيق نفس القوة التمثيلية، مما يؤدي إلى زيادة تكلفة الحساب.
بالإضافة إلى ذلك، لا تستطيع الشبكات العصبية التصنيفية التقاط أنماط الصور على مستوى عالمي لأن عوامل التصفية الخاصة بها تركز على مناطق محلية من الصورة. لفهم الصورة بأكملها أو العلاقات البعيدة، تعتمد الشبكات العصبية التصنيفية على تكديس العديد من الطبقات والتجميع، مما يوسع مجال الرؤية. ومع ذلك، يمكن أن يؤدي هذا العملية إلى فقدان المعلومات العامة مع تجميع التفاصيل خطوة بخطوة.
من ناحية أخرى، تقسم شبكات النقاط الظاهرية الصورة إلى قطع صغيرة يتم التعامل معها كرموز إدخال فردية. باستخدام الانتباه الذاتي، تقارن شبكات النقاط الظاهرية جميع القطع معًا وتتعلم كيف تتصل ببعضها. يتيح لهم ذلك التقاط الأنماط والتبعيات عبر الصورة بأكملها دون بناء طبقة بعد طبقة.
ما هو الانحياز الاستقرائي؟
قبل المضي قدمًا، من المهم فهم مفهوم الانحياز الاستقرائي. الانحياز الاستقرائي يشير إلى الافتراض الذي يقوم به النموذج حول هيكل البيانات؛ وأثناء التدريب، يساعد هذا النموذج على أن يكون أكثر عمومية ويقلل الانحياز. في شبكات النقاط الظاهرية، تشمل الانحيازات الاستقرائية:
- المحلية: الميزات في الصور (مثل الحواف أو الأنسجة) متمركزة داخل مناطق صغيرة.
- هيكل الحيز ثنائي الأبعاد: البكسلات القريبة من بعضها البعض أكثر ارتباطًا، لذلك تعمل المرشحات على مناطق ملاصقة مكانيًا.
- التعادلية في الترجمة: الميزات المكتشفة في جزء من الصورة، مثل حافة، تحتفظ بنفس المعنى إذا ظهرت في جزء آخر.
هذه التحيزات تجعل الشبكات العصبية التصنيفية CNNs فعالة للغاية في مهام المعالجة الصورية، حيث تم تصميمها بشكل طبيعي لاستغلال الخصائص المكانية والهيكلية للصور.
تتمتع المحولات البصرية (ViTs) بتحيز تفسيري أقل بكثير مما هو موجود في CNNs. في ViTs:
- المعالجة العالمية: تعمل طبقات الانتباه الذاتي على الصورة بأكملها، مما يجعل النموذج يلتقط العلاقات والتبعيات العالمية دون أن يقتصر على المناطق المحلية.
- هيكل 2D الأدنى: يتم استخدام هيكل الصورة ثنائي الأبعاد فقط في بداية عملية التقسيم (عند تقسيم الصورة إلى أجزاء) وأثناء ضبط الدقة العالية (لضبط تضمينات المواقع لدقات مختلفة). على عكس CNNs، لا تفترض ViTs أن البكسلات القريبة من بعضها بالضرورة ذات صلة.
- علاقات المواقع المعلمة: تضمينات المواقع في ViTs لا تُشفر علاقات المواقع الثنائية الخاصة بالبكسلات عند البدء. بدلاً من ذلك، يتعلم النموذج كافة العلاقات المكانية من البيانات أثناء التدريب.
كيف تعمل المحولات البصرية
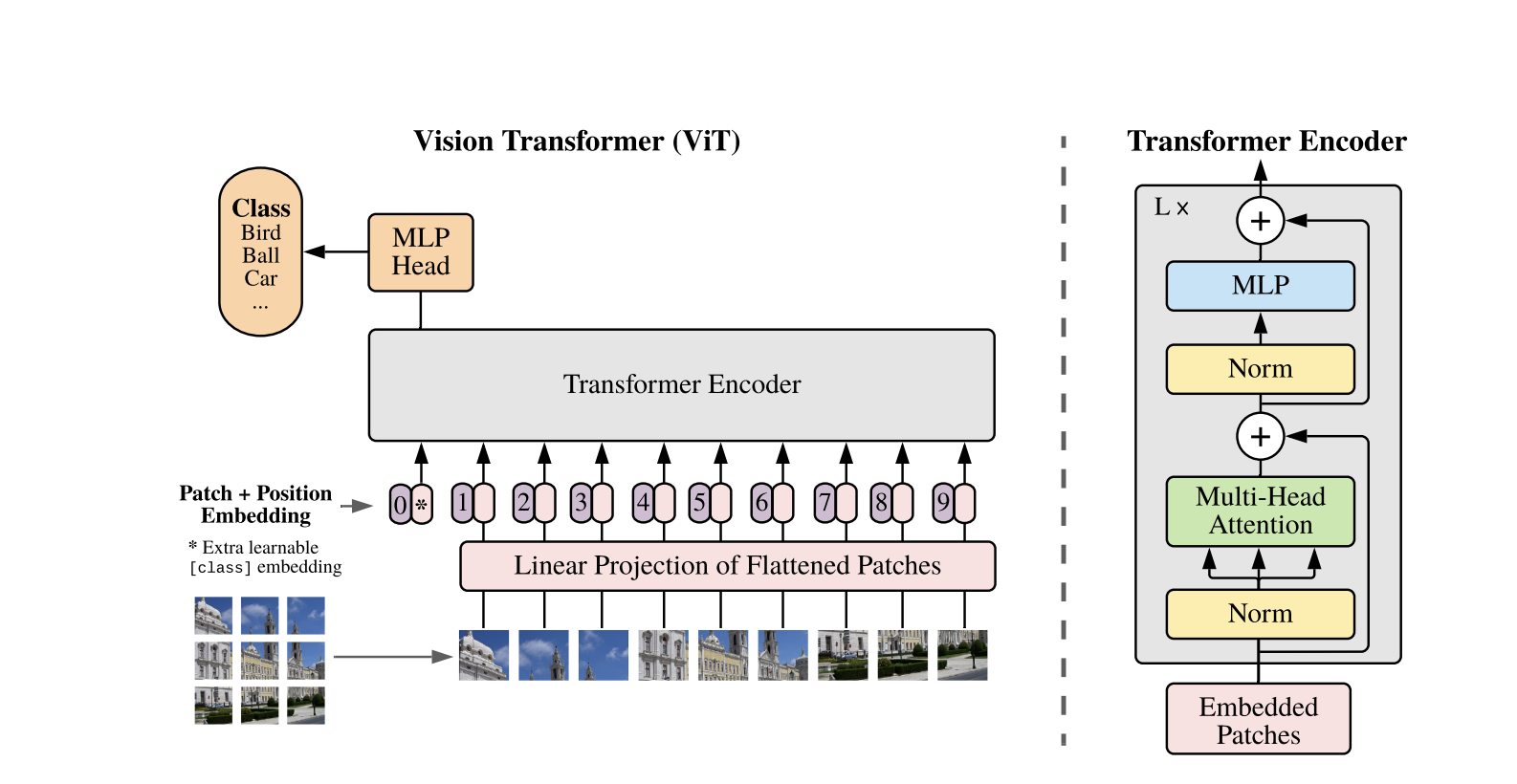
تستخدم المحولات البصرية تصميم المحولات القياسي المطور لتسلسلات النصوص ذات الأبعاد 1D. لمعالجة الصور ثنائية الأبعاد، يتم تقسيمها إلى أجزاء صغيرة من حجم ثابت، مثل P × P بكسل، التي يتم تسطيعها إلى متجهات. إذا كانت الصورة لها أبعاد H × W مع قنوات C، فإن العدد الإجمالي للأجزاء هو N = (H × W) / (P × P)، وهو طول تسلسل الإدخال الفعال للمحول. ثم يتم مشروعة خطياً إلى فضاء ذو بُعد ثابت D، يُسمى تضمين الأجزاء.
يتم إضافة رمز تعلمي خاص، مشابه لرمز [CLS] في BERT، إلى بداية تسلسل تضمين الأجزاء. يتعلم هذا الرمز تمثيل صورة عالمي يُستخدم لاحقًا للتصنيف. بالإضافة إلى ذلك، يتم إضافة تضمينات موضعية إلى تضمينات الأجزاء لترميز المعلومات الموضعية، مما يساعد النموذج على فهم الهيكل المكاني للصورة.
تُمرر سلسلة التضمينات عبر مشفر التحويل، الذي يت alternates بين عمليتين رئيسيتين: الانتباه الذاتي متعدد الرؤوس (MSA) وشبكة عصبية تغذوية متقدمة، تُسمى أيضًا كتلة MLP. تتضمن كل طبقة تطبيع الطبقة (LN) المطبق قبل هذه العمليات والاتصالات المتبقية المضافة afterward لتثبيت التدريب. يتم استخدام ناتج مشفر التحويل، وبالتحديد حالة رمز [CLS]، كتمثيل للصورة.
يتم إضافة رأس بسيط إلى رمز [CLS] النهائي لمهام التصنيف. خلال التدريب المسبق، يكون هذا الرأس عبارة عن شبكة عصبية متعددة الطبقات صغيرة (MLP)، بينما في الضبط الدقيق، يكون عادةً طبقة خطية واحدة. يسمح هذا التصميم لـ ViTs بنمذجة العلاقات العالمية بين الأجزاء بفعالية واستخدام القوة الكاملة للاهتمام الذاتي لفهم الصورة.
في نموذج تحويل الرؤية الهجين، بدلاً من تقسيم الصور الخام مباشرة إلى أجزاء، يتم اشتقاق سلسلة الإدخال من خرائط الميزات التي تولدها CNN. تقوم CNN بمعالجة الصورة أولاً، واستخراج ميزات مكانية ذات مغزى، والتي تُستخدم بعد ذلك لإنشاء أجزاء. يتم تسطيح هذه الأجزاء وإسقاطها في فضاء ثابت الأبعاد باستخدام نفس الإسقاط الخطي القابل للتدريب كما في تحويلات الرؤية القياسية. حالة خاصة من هذا النهج هي استخدام أجزاء بحجم 1×1، حيث يتوافق كل جزء مع موقع مكاني واحد في خريطة ميزات CNN.
في هذه الحالة، يتم تسطيح الأبعاد المكانية لخريطة الميزات، ويتم إسقاط التسلسل الناتج في بُعد إدخال المحول. كما هو الحال مع ViT القياسي، يتم إضافة رمز تصنيف وتضمينات موضعية للاحتفاظ بمعلومات الموضع وتمكين فهم الصورة العالمية. يستفيد هذا النهج الهجين من نقاط القوة في استخراج الميزات المحلية من الشبكات العصبية التلافيفية (CNNs) بينما يجمعها مع قدرات النمذجة العالمية للمحول.
عرض الكود
إليك كتلة الكود حول كيفية استخدام محولات الرؤية على الصور.
معالجة نموذج ViT للصورة. يتألف من مشفر شبيه بـ BERT ورأس تصنيف خطي يقع فوق الحالة المخفية النهائية لرمز [CLS].
إليك تنفيذ أساسي لمحول الرؤية (ViT) باستخدام PyTorch. يتضمن هذا الكود المكونات الأساسية: تضمين الباتش، ترميز الموضع، ومشفر المحول. يمكن استخدامه لمهام التصنيف البسيطة.
المكونات الرئيسية:
- تضمين الرقعة: تتم قسمة الصور إلى رقع أصغر، وتسطيحها، وتحويلها بشكل خطي إلى تضمينات.
- ترميز الموضع: يتم إضافة معلومات الموضع إلى تضمينات الرقعة، حيث أن المحولات لا تأخذ في الاعتبار الموضع.
- مُشفر المحول: يطبق الانتباه الذاتي والطبقات التغذية الأمامية لتعلم العلاقات بين الرقع.
- رأس التصنيف: يخرج احتماليات الفئات باستخدام رمز CLS.
يمكنك تدريب هذا النموذج على أي مجموعة بيانات للصور باستخدام محسن مثل آدم ووظيفة خسارة مثل التبادل المتقاطع. للحصول على أداء أفضل، يُنصح بالتدريب المسبق على مجموعة بيانات كبيرة قبل ضبط الدقة.
أعمال متابعة شهيرة
-
DeiT (تحويلات الصور الفعالة من حيث البيانات) من Facebook AI: هذه تحويلات رؤية تم تدريبها بكفاءة باستخدام تبخير المعرفة. يقدم DeiT أربعة إصدارات: deit-tiny، deit-small، ونموذجين deit-base. استخدم
معالج صور DeiTلتحضير الصور. -
BEiT (تدريب BERT للمحولات الصورية) بواسطة بحث Microsoft: مستوحى من BERT، يستخدم BEiT نمذجة الصور المقننة ذاتيًا بتقنية القناع ويفوق ViTs المدربة بشكل مراقب. يعتمد على VQ-VAE للتدريب.
-
DINO (تدريب النماذج البصرية الذاتي للمحولات) بواسطة Facebook AI: يمكن لـ ViTs المدربة بواسطة DINO تقسيم الكائنات دون تدريب صريح. تتوفر نقاط التحقق عبر الإنترنت.
-
MAE (المشفرة الذاتية المقنعة) من فيسبوك تقوم بتدريب ViTs مسبقاً عن طريق إعادة بناء الأجزاء المقنعة (75%). عند إجراء التعديل الدقيق، تتجاوز هذه الطريقة البسيطة التدريب المسبق تحت الإشراف.
الخاتمة
ختاماً، تعتبر ViTs بديلاً ممتازاً لشبكات CNN حيث تطبق المحولات في التعرف على الصور، وتقلل من التحيز الاستقرائي، وتعامل الصور كأجزاء متسلسلة. وقد أظهرت هذه الطريقة البسيطة والقابلة للتوسع أداءً رائداً في العديد من معايير تصنيف الصور، خاصة عند اقترانها بالتدريب المسبق على مجموعات بيانات كبيرة. ومع ذلك، لا تزال هناك تحديات محتملة، بما في ذلك توسيع ViTs لتشمل مهام مثل كشف الأجسام والتجزئة، وتحسين طرق التدريب الذاتي المسبق، واستكشاف إمكانية توسيع ViTs لأداء أفضل.
موارد إضافية
Source:
https://www.digitalocean.com/community/tutorials/vision-transformer-for-computer-vision