













지난 몇 년 동안, 트랜스포머는 기계 학습에서 NLP 도메인을 변화시켰습니다. GPT와 BERT와 같은 모델들은 인간 언어를 이해하고 생성하는 데 새로운 기준을 세웠습니다. 이제 동일한 원칙이 컴퓨터 비전 도메인에 적용되고 있습니다.
컴퓨터 비전 분야의 최근 발전 중 하나는 비전 트랜스포머 또는 ViTs입니다. “An Image is Worth 16×16 Words: Transformers for Image Recognition at Scale” 논문에서 자세히 설명된 대로, ViTs와 트랜스포머 기반 모델은 합성곱 신경망(CNNs)을 대체하기 위해 설계되었습니다.
비전 트랜스포머는 컴퓨터 비전 분야의 문제를 해결하는 새로운 방법론입니다. 수십 년 동안 이미지 관련 작업의 중추였던 전통적인 합성곱 신경망(CNNs)에 의존하는 대신, ViTs는 이미지를 처리하기 위해 트랜스포머 아키텍처를 사용합니다. 이 모델은 문장에서 단어를 다루는 것처럼 이미지 패치를 다루어, 이러한 패치 간의 관계를 학습하며, 마치 텍스트 단락에서 문맥을 학습하는 것과 같습니다.
CNN과는 달리, ViTs는 입력 이미지를 패치로 분할하고 벡터로 직렬화한 후 행렬 곱셈을 사용하여 차원을 줄입니다. 그런 다음 트랜스포머 인코더가 이러한 벡터를 토큰 임베딩으로 처리합니다. 이 글에서는 비전 트랜스포머와 합성곱 신경망과의 주요 차이를 탐구할 것입니다. 흥미로운 점은 비전 트랜스포머가 이미지의 전역 패턴을 이해하는 능력을 갖추고 있다는 것인데, 이는 CNN이 고민할 수 있는 부분입니다.
전제 조건
- 신경망 기초: 신경망이 데이터를 처리하는 방법에 대한 이해.
- 합성곱 신경망(CNNs): CNN 및 컴퓨터 비전에서의 역할에 대한 친숙함.
- 트랜스포머 아키텍처: NLP에서의 트랜스포머의 사용에 대한 지식.
- 이미지 처리: 이미지 표현, 채널 및 픽셀 배열과 같은 기본 개념의 이해.
- 주의 메커니즘: 자기 주의 및 입력 간 관계 모델링 능력에 대한 이해.
비전 트랜스포머란?
비전 트랜스포머는 주의(attention)와 트랜스포머(transformers) 개념을 사용하여 이미지를 처리합니다. 이는 자연어 처리(NLP) 맥락의 트랜스포머와 유사합니다. 그러나 토큰을 사용하는 대신, 이미지는 패치(patches)로 나뉘어 선형 임베딩의 시퀀스로 제공됩니다. 이러한 패치는 NLP에서 토큰이나 단어가 처리되는 방식과 동일하게 취급됩니다.
전체 이미지를 동시에 보는 대신, ViT는 이미지를 퍼즐 조각처럼 작은 조각으로 잘라냅니다. 각 조각은 그 특징을 설명하는 숫자 목록(벡터)으로 변환되고, 모델은 모든 조각을 살펴보며 트랜스포머 메커니즘을 사용하여 서로의 관계를 파악합니다.
CNN과 달리 ViT는 특정 특징(예: 엣지 패턴)을 감지하기 위해 이미지 위에 특정 필터나 커널을 적용하여 작동합니다. 이는 이미지를 스캔하는 프린터와 매우 유사한 컨볼루션 과정입니다. 이러한 필터는 전체 이미지를 통해 슬라이드하며 중요한 특징을 강조합니다. 네트워크는 이러한 필터의 여러 레이어를 쌓아 올려 점차 더 복잡한 패턴을 식별합니다.
CNN에서는 풀링 레이어가 특징 맵의 크기를 줄입니다. 이러한 레이어는 추출된 특징을 분석하여 이미지 인식, 객체 탐지 등을 위한 유용한 예측을 만듭니다. 그러나 CNN은 고정된 수용 영역을 가지므로 장기적인 의존성을 모델링하는 능력이 제한됩니다.
CNN은 이미지를 어떻게 보는가?
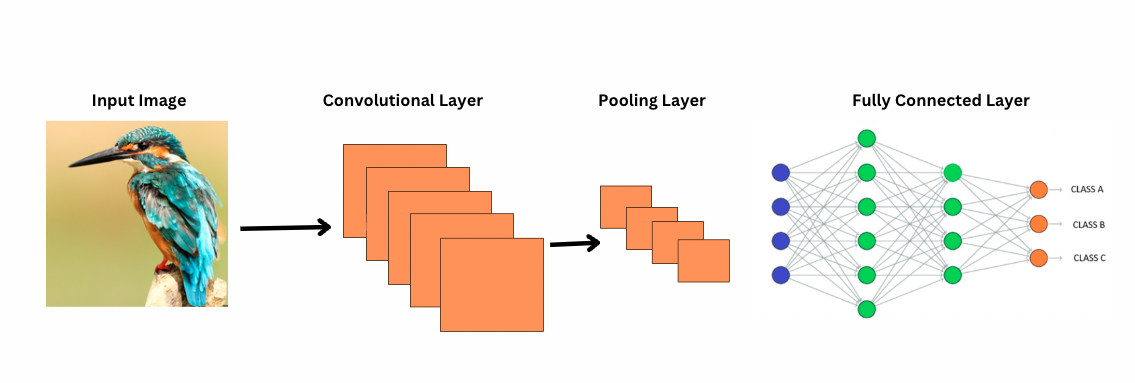
ViTs는 더 많은 매개변수를 가지고 있지만, 더 나은 특성 표현을 위해 자기 주의 메커니즘을 사용하고 더 깊은 레이어의 필요성을 줄입니다. CNN은 유사한 표현 능력을 달성하기 위해 상당히 깊은 아키텍처가 필요하며, 이는 증가된 계산 비용을 야기합니다.
게다가, CNN은 이미지의 지역 영역에 집중하는 필터들 때문에 전역 수준의 이미지 패턴을 포착할 수 없습니다. 전체 이미지나 먼 관계를 이해하기 위해 CNN은 많은 레이어를 쌓고 풀링에 의존하여 시야를 확장합니다. 그러나 이러한 과정은 전역 정보를 단계별로 집계하면서 전역 정보를 잃을 수 있습니다.
반면에 ViTs는 이미지를 개별 입력 토큰으로 처리하는 패치로 나눕니다. 자기 주의를 사용하여 ViTs는 모든 패치를 동시에 비교하고 관련성을 학습합니다. 이를 통해 레이어별로 쌓지 않고 전체 이미지를 효과적으로 포괄하는 패턴과 종속성을 포착할 수 있습니다.
귀납 편향(Inductive Bias)이란?
더 나아가기 전에, 귀납 편향 개념을 이해하는 것이 중요합니다. 귀납 편향은 모델이 데이터 구조에 대해 하는 가정을 나타내며, 이는 훈련 중에 모델이 보다 일반화되고 편향을 줄이도록 도와줍니다. CNN에서 귀납 편향에는 다음이 포함됩니다:
- 지역성: 이미지의 특성(가장자리 또는 질감과 같은)은 작은 영역 내에 국부화됩니다.
- 2차원 이웃 구조: 근처 픽셀은 관련성이 높기 때문에 필터가 공간적으로 인접한 영역에서 작동합니다.
- 번역 동질성: 이미지의 한 부분에서 감지된 기능(예: 가장자리)은 다른 부분에 나타날 때도 동일한 의미를 유지합니다.
이러한 편향은 CNN을 이미지 작업에 매우 효율적으로 만들어주며, 이미지의 공간적 및 구조적 특성을 자연적으로 활용하도록 설계되었습니다.
Vision Transformers (ViTs)는 CNN에 비해 이미지 특정 귀납적 편향이 훨씬 적습니다. ViTs에서는:
- 전역 처리: 셀프 어텐션 레이어가 전체 이미지에서 작동하여 모델이 지역 영역에 제한받지 않고 전역 관계와 의존성을 포착하도록 합니다.
- 최소한의 2D 구조: 이미지의 2D 구조는 처음에만 사용(이미지를 패치로 나눌 때)되고 세밀하게 조정될 때(다른 해상도에 대한 위치 임베딩을 조정할 때)에만 사용됩니다. CNN과는 달리 ViTs는 근접한 픽셀이 반드시 관련되어 있다고 가정하지 않습니다.
- 학습된 공간적 관계: ViTs의 위치 임베딩은 초기화 단계에서 특정 2D 공간적 관계를 인코딩하지 않습니다. 대신 모델은 훈련 중에 데이터로부터 모든 공간 관계를 학습합니다.
비전 트랜스포머 작동 방식
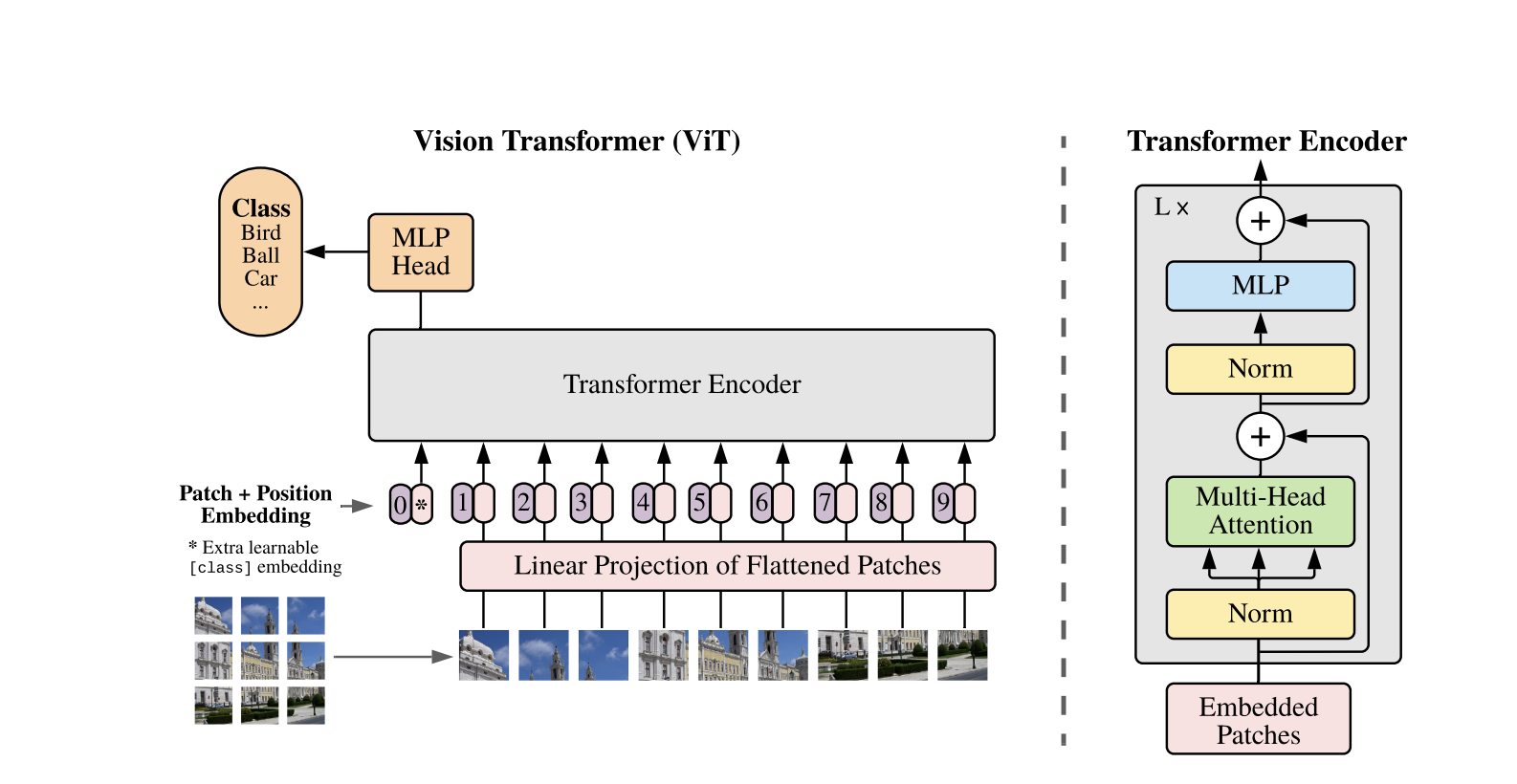
비전 트랜스포머는 1차원 텍스트 시퀀스용으로 개발된 표준 트랜스포머 아키텍처를 사용합니다. 2차원 이미지를 처리하기 위해 이미지는 P * P 픽셀과 같은 고정 크기의 작은 패치로 나누어지며 이들은 벡터로 평평하게 만듭니다. 이미지가 H * W 크기와 C 채널을 가지고 있다면, 패치의 총 개수는 N = H * W / P * P이고 이는 트랜스포머의 유효한 입력 시퀀스 길이입니다. 이러한 평평한 패치들은 고정 차원 D의 공간으로 선형으로 투영되는데, 이를 패치 임베딩이라고 합니다.
BERT의 [CLS] 토큰과 유사한 특수한 학습 가능한 토큰이 패치 임베딩 시퀀스 앞에 추가됩니다. 이 토큰은 이후 분류에 사용되는 전역 이미지 표현을 학습합니다. 또한 위치 임베딩이 패치 임베딩에 추가되어 위치 정보를 부여하며, 모델이 이미지의 공간 구조를 이해하는 데 도움이 됩니다.
임베딩 시퀀스는 Transformer 인코더를 통과하며, 두 가지 주요 작업인 다중 헤드 자기 주의(MSA)와 피드포워드 신경망, 즉 MLP 블록을 번갈아 수행합니다. 각 레이어는 이러한 작업 전에 적용되는 레이어 정규화 (LN)를 포함하고, 훈련을 안정시키기 위해 이후에 잔여 연결이 추가됩니다. Transformer 인코더의 출력, 특히 [CLS] 토큰의 상태는 이미지의 표현으로 사용됩니다.
분류 작업을 위해 최종 [CLS] 토큰에 간단한 헤드가 추가됩니다. 사전 훈련 중에는 이 헤드가 작은 다층 퍼셉트론(MLP)이고, 파인튜닝 동안에는 일반적으로 단일 선형 레이어입니다. 이 아키텍처는 ViTs가 패치 간의 전역 관계를 효과적으로 모델링하고 이미지 이해를 위해 자기 주의의 전체 힘을 활용할 수 있게 해줍니다.
하이브리드 비전 트랜스포머 모델에서는 원시 이미지를 패치로 직접 나누는 대신, 입력 시퀀스가 CNN에 의해 생성된 피처 맵에서 파생됩니다. CNN은 이미지를 먼저 처리하여 의미 있는 공간적 특징을 추출하고, 이를 사용하여 패치를 생성합니다. 이러한 패치는 평탄화되어 표준 비전 트랜스포머와 동일한 학습 가능 선형 투영을 사용하여 고정 차원 공간으로 투영됩니다. 이 접근 방식의 특별한 경우는 1×1 크기의 패치를 사용하는 것으로, 각 패치는 CNN의 피처 맵의 단일 공간적 위치에 해당합니다.
이 경우에는 특성 맵의 공간 차원이 평평하게 되고 결과 시퀀스가 Transformer의 입력 차원으로 투영됩니다. 일반적인 ViT와 마찬가지로 분류 토큰과 위치 임베딩이 추가되어 위치 정보를 유지하고 전역 이미지 이해를 가능하게 합니다. 이 하이브리드 접근법은 CNN의 지역 특성 추출 능력을 활용하면서 Transformer의 전역 모델링 능력과 결합합니다.
코드 데모
이미지에서 비전 트랜스포머를 사용하는 방법에 대한 코드 블록은 다음과 같습니다.
ViT 모델은 이미지를 처리합니다. 이는 BERT와 유사한 인코더와 [CLS] 토큰의 최종 숨겨진 상태 위에 있는 선형 분류 헤드로 구성됩니다.
PyTorch를 사용한 기본 Vision Transformer (ViT) 구현은 다음과 같습니다. 이 코드에는 핵심 구성 요소인 패치 임베딩, 위치 인코딩 및 Transformer 인코더가 포함되어 있습니다. 이것은 간단한 분류 작업에 사용할 수 있습니다.
주요 구성 요소:
- 패치 임베딩: 이미지를 작은 패치로 나누어 펼치고, 선형 변환하여 임베딩으로 만듦.
- 위치 인코딩: Transformer는 위치에 무관하기 때문에 패치 임베딩에 위치 정보를 추가함.
- Transformer 인코더: 패치 간의 관계를 학습하기 위해 self-attention 및 피드포워드 레이어를 적용함.
- 분류 헤드: CLS 토큰을 사용하여 클래스 확률을 출력합니다.
이 모델을 Adam과 같은 옵티마이저와 교차 엔트로피와 같은 손실 함수를 사용하여 어떤 이미지 데이터셋에서도 훈련할 수 있습니다. 더 나은 성능을 위해 미세 조정하기 전에 대규모 데이터셋에서 사전 훈련을 고려하십시오.
인기 있는 후속 작업
-
DeiT(Data-efficient Image Transformers) by Facebook AI: 지식 증류를 사용하여 효율적으로 훈련된 비전 트랜스포머입니다. DeiT에는 deit-tiny, deit-small, 두 개의 deit-base 모델이 포함되어 있습니다. 이미지를 준비하기 위해
DeiTImageProcessor을(를) 사용하십시오. -
마이크로소프트 연구소에서 개발한 BEiT(BERT pre-training of Image Transformers): BERT를 모티브로 한 BEiT는 자가 감독된 가리고 가리지 않은 이미지 모델링을 사용하며 감독된 ViTs를 능가합니다. 훈련에 VQ-VAE를 의존합니다.
-
페이스북 AI에서 개발한 DINO(Self-supervised Vision Transformer Training): DINO로 훈련된 ViTs는 명시적 훈련 없이 객체를 세분화할 수 있습니다. 체크포인트는 온라인에서 사용 가능합니다.
-
MAE (마스킹 오토인코더)는 페이스북에서 ViTs를 마스킹된 패치를 재구성하여 사전 훈련합니다 (75%). 미세 조정 시, 이 간단한 방법은 감독 학습 사전 훈련을 초월합니다.
결론
결론적으로, ViTs는 이미지 인식에 변환기를 적용하고 유도 편향을 최소화하며 이미지를 시퀀스 패치로 처리하기 때문에 CNN의 훌륭한 대안입니다. 이 간단하면서도 확장 가능한 접근 방식은 특히 대규모 데이터셋에서 사전 훈련과 함께 사용할 때 많은 이미지 분류 벤치마크에서 최첨단 성능을 입증했습니다. 그러나 물체 탐지 및 분할과 같은 작업으로 ViTs를 확장하고, 자기 지도 사전 훈련 방법을 더욱 개선하며, 더 나은 성능을 위한 ViTs의 확장 가능성을 탐색하는 등 잠재적인 도전 과제가 남아 있습니다.
추가 자료
Source:
https://www.digitalocean.com/community/tutorials/vision-transformer-for-computer-vision