













在过去几年中,变压器已经在机器学习的NLP领域发生了变革。像GPT和BERT这样的模型为理解和生成人类语言树立了新的基准。现在同样的原理正在应用于计算机视觉领域。
计算机视觉领域的一个最新发展是视觉变压器或ViTs。正如在论文《An Image is Worth 16×16 Words: Transformers for Image Recognition at Scale》中详细介绍的那样,ViTs和基于变压器的模型旨在取代卷积神经网络(CNNs)。
视觉变压器是解决计算机视觉问题的一种新方法。ViTs不再依赖传统的卷积神经网络(CNNs),后者几十年来一直是与图像相关任务的支柱,而是使用变压器架构来处理图像。它们将图像补丁视为句子中的单词,使模型能够学习这些补丁之间的关系,就像学习文本段落中的上下文一样。
与CNN不同,ViTs将输入图像分成补丁,将它们串行化为向量,并使用矩阵乘法降低它们的维度。然后,一个Transformer编码器处理这些向量作为标记嵌入。在本文中,我们将探讨视觉Transformer及其与卷积神经网络的主要区别。它们特别有趣的地方在于它们能够理解图像中的全局模式,这是CNN可能会遇到困难的地方。
先决条件
- 神经网络基础:了解神经网络如何处理数据。
- 卷积神经网络(CNNs):熟悉CNN以及它们在计算机视觉中的作用。
- Transformer架构:了解Transformer,特别是它们在NLP中的应用。
- 图像处理:理解图像表示、通道和像素数组等基本概念。
- 注意力机制:理解自注意力及其在模型关系跨输入方面的能力。
什么是视觉Transformer?
Vision transformers 使用注意力和 transformer 的概念来处理图像,这类似于自然语言处理(NLP)中的 transformer。然而,与其使用标记不同,图像被分割成补丁,并作为线性嵌入的序列提供。这些补丁被以与 NLP 中标记或单词处理方式相同的方式处理。
视觉 transformer 不会同时查看整个图片,而是像拼图一样将图像切分成小块。每个块被转换为描述其特征的一组数字(向量),然后模型查看所有块,并使用 transformer 机制弄清它们之间的关系。
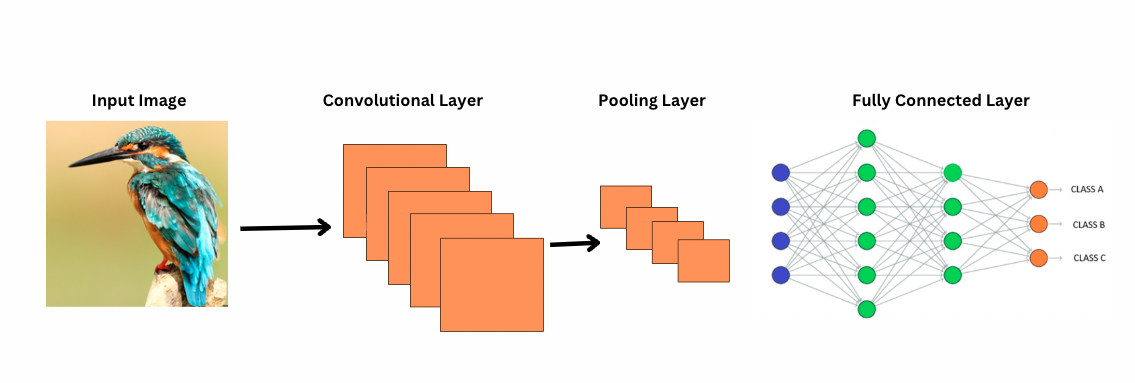
与 CNN 不同,Vision transformers 通过在图像上应用特定的过滤器或卷积核来检测特定特征,例如边缘模式。这是卷积过程,类似于打印机扫描图像。这些过滤器在整个图像上滑动并突出显著特征。网络然后堆叠多个这些过滤器的层,逐渐识别出更复杂的模式。
使用 CNN,池化层会减小特征图的大小。这些层分析提取的特征,以进行有用的图像识别、物体检测等预测。然而,CNN 具有固定的感受野,从而限制了对长距离依赖性的建模能力。
CNN 如何看待图像?
尽管 ViTs 具有更多的参数,但使用自注意力机制以获得更好的特征表示,并减少对更深层的需求。CNNs 需要更深的架构才能达到类似的表征能力,这会导致增加计算成本。
此外,CNNs 无法捕捉全局级别的图像模式,因为它们的滤波器专注于图像的局部区域。为了理解整个图像或远距离关系,CNNs 依赖于堆叠许多层和池化,扩展视野。然而,这个过程会逐步聚合细节,可能会丢失全局信息。
另一方面,ViTs 将图像分成补丁,将其视为单独的输入标记。使用自注意力,ViTs 可同时比较所有补丁并学习它们之间的关系。这使它们能够捕捉整个图像中的模式和依赖关系,而无需逐层构建。
归纳偏置是什么?
在深入讨论之前,重要的是理解归纳偏置的概念。归纳偏置是模型对数据结构的假设;在训练过程中,这有助于使模型更加泛化并减少偏差。在 CNNs 中,归纳偏置包括:
- 局部性:图像中的特征(如边缘或纹理)在小区域内局部化。
- 二维邻域结构:附近的像素更可能相关,因此滤波器在空间上相邻的区域上操作。
- 平移等变性:在图像的一个部分检测到的特征(如边缘)如果出现在另一个部分,仍保持相同含义。
这些偏见使得卷积神经网络对图像任务非常高效,因为它们天生就被设计用来利用图像的空间和结构特性。
视觉Transformer(ViTs)比卷积神经网络具有更少的图像特定归纳偏见。在ViTs中:
- 全局处理:自注意力层作用于整个图像,使模型捕获全局关系和依赖性,而不受局部区域的限制。
- 最小的二维结构:图像的二维结构仅在开始阶段(将图像分成补丁时)和微调期间(调整不同分辨率的位置嵌入)使用。与卷积神经网络不同,ViTs不假设附近的像素必定相关。
- 学习的空间关系:ViTs中的位置嵌入在初始化时不编码特定的二维空间关系。相反,模型在训练过程中从数据中学习所有空间关系。
视觉Transformer的工作原理
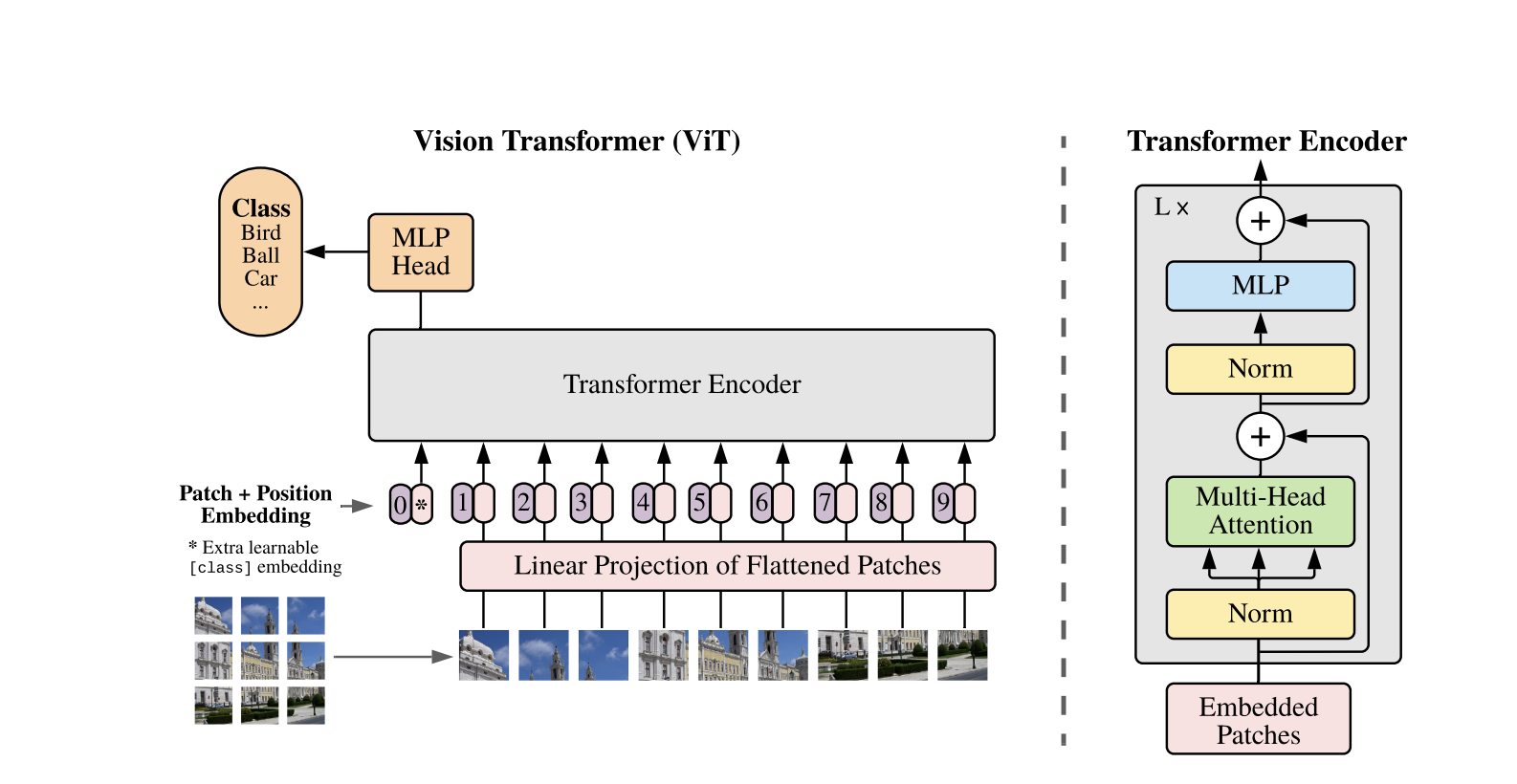
Vision Transformers 使用了为处理1D文本序列开发的标准Transformer架构。为了处理2D图像,它们被分成固定大小的较小块,如P*P像素,然后被展平为向量。如果图像的尺寸为H*W,具有C个通道,那么块的总数为N=H*W/P*P,这是Transformer的有效输入序列长度。这些展平的块然后被线性投影到一个固定维度空间D中,称为块嵌入。
一个特殊的可学习标记,类似于BERT中的[CLS]标记,被添加到块嵌入序列的开头。这个标记学习了一个全局图像表示,然后用于分类。此外,位置嵌入被添加到块嵌入中,以编码位置信息,帮助模型理解图像的空间结构。
嵌入序列通过Transformer编码器传递,该编码器在两个主要操作之间交替进行:多头自注意力(MSA)和前馈神经网络,也称为MLP块。每个层包括层归一化(LN)在这些操作之前应用,并在之后添加残差连接以稳定训练。Transformer编码器的输出,特别是[CLS]标记的状态,用作图像的表示。
在最终[CLS]标记上添加一个简单的头以进行分类任务。在预训练期间,此头部是一个小型多层感知器(MLP),而在微调中,它通常是一个单个线性层。这种架构允许ViTs有效地建模补丁之间的全局关系,并利用自注意力的全部能力进行图像理解。
在混合视觉Transformer模型中,输入序列不是直接将原始图像分成补丁,而是从CNN生成的特征图中导出。CNN首先处理图像,提取有意义的空间特征,然后用于创建补丁。这些补丁被展平,并使用与标准Vision Transformers中相同的可训练线性投影投影到固定维度空间中。这种方法的一个特殊情况是使用大小为1×1的补丁,其中每个补丁对应CNN特征图中的单个空间位置。
在这种情况下,特征图的空间维度被展平,生成的序列被投影到Transformer的输入维度。与标准的ViT一样,添加了分类令牌和位置编码,以保留位置信息并实现全局图像理解。这种混合方法利用了CNN的局部特征提取优势,同时结合了Transformer的全局建模能力。
代码示例
以下是如何在图像上使用视觉Transformer的代码块。
ViT模型处理图像。它包括类似BERT的编码器和位于[CLS]令牌最终隐藏状态顶部的线性分类头。
这是使用PyTorch的基本Vision Transformer(ViT)实现。这段代码包括核心组件:块嵌入、位置编码和Transformer编码器。这可用于简单的分类任务。
关键组件:
- 补丁嵌入:图像被分成较小的补丁,展平,并线性转换为嵌入。
- 位置编码:将位置信息添加到补丁嵌入中,因为 Transformer 是位置不可知的。
- Transformer 编码器:应用自注意力和前馈层来学习补丁之间的关系。
- 分类头: 使用CLS标记输出类概率。
您可以使用像Adam这样的优化器和交叉熵这样的损失函数在任何图像数据集上训练此模型。为了获得更好的性能,在微调之前考虑在大型数据集上进行预训练。
热门后续工作
-
DeiT(Data-efficient Image Transformers)由Facebook AI开发:这些是通过知识蒸馏高效训练的视觉Transformer。DeiT提供四个变体:deit-tiny、deit-small和两个deit-base模型。使用
DeiTImageProcessor来准备图像。 -
微软研究的BEiT(BERT图像Transformer的预训练):受BERT启发,BEiT使用自监督的遮罩图像建模,表现优于受监督的ViTs。它依赖于VQ-VAE进行训练。
-
Facebook AI的DINO(自监督视觉Transformer训练):经DINO训练的ViTs可以分割对象而无需显式训练。在线提供了检查点。
-
Facebook的MAE(Masked Autoencoders)通过重构遮罩补丁(75%)来预训练ViTs。在微调时,这种简单方法超越了监督式预训练。
结论
总之,ViTs作为CNN的出色替代品,将transformers应用于图像识别,最小化归纳偏差,并将图像视为序列补丁。这种简单而可扩展的方法在许多图像分类基准测试中展示了最先进的性能,特别是与在大型数据集上进行预训练相配合时。然而,仍然存在潜在挑战,包括将ViTs扩展到目标检测和分割等任务,进一步改进自监督预训练方法,以及探索将ViTs扩展至更好性能的潜力。
额外资源
Source:
https://www.digitalocean.com/community/tutorials/vision-transformer-for-computer-vision