













Au cours des dernières années, les transformateurs ont révolutionné le domaine du traitement automatique du langage naturel (NLP) en apprentissage automatique. Des modèles tels que GPT et BERT ont établi de nouveaux référentiels en matière de compréhension et de génération du langage humain. Maintenant, le même principe est appliqué au domaine de la vision par ordinateur.
Un récent développement dans le domaine de la vision par ordinateur concerne les transformateurs de vision ou ViTs. Comme détaillé dans l’article « Une image vaut 16×16 mots : Transformateurs pour la reconnaissance d’images à grande échelle » (An Image is Worth 16×16 Words: Transformers for Image Recognition at Scale), les ViTs et les modèles basés sur les transformateurs sont conçus pour remplacer les réseaux neuronaux convolutifs (CNN).
Les transformateurs de vision offrent une nouvelle approche pour résoudre les problèmes en vision par ordinateur. Au lieu de s’appuyer sur les réseaux neuronaux convolutifs traditionnels (CNN), qui ont été l’épine dorsale des tâches liées à l’image depuis des décennies, les ViTs utilisent l’architecture de transformateur pour traiter les images. Ils traitent les fragments d’image comme des mots dans une phrase, permettant au modèle d’apprendre les relations entre ces fragments, tout comme il apprend le contexte dans un paragraphe de texte.
Contrairement aux CNN, les ViTs divisent les images d’entrée en patches, les sérialisent en vecteurs et réduisent leur dimensionnalité en utilisant la multiplication matricielle. Un encodeur transformateur traite ensuite ces vecteurs en tant qu’embeddings de tokens. Dans cet article, nous explorerons les transformateurs de vision et leurs principales différences avec les réseaux de neurones convolutifs. Ce qui les rend particulièrement intéressants, c’est leur capacité à comprendre des motifs globaux dans une image, ce qui est quelque chose avec lequel les CNN peuvent avoir des difficultés.
Prérequis
- Notions de base sur les réseaux de neurones: Compréhension de la manière dont les réseaux de neurones traitent les données.
- Réseaux de neurones convolutifs (CNN): Familiarité avec les CNN et leur rôle dans la vision par ordinateur.
- Architecture de transformateur: Connaissance des transformateurs, en particulier de leur utilisation en traitement du langage naturel (NLP).
- Traitement d’image: Compréhension des concepts de base tels que la représentation d’image, les canaux et les tableaux de pixels.
- Mécanisme d’attention: Compréhension de l’auto-attention et de sa capacité à modéliser les relations entre les entrées.
Qu’est-ce que les transformateurs de vision ?
Les transformateurs de vision utilisent le concept d’attention et de transformateurs pour traiter les images, ce qui est similaire aux transformateurs dans un contexte de traitement du langage naturel (NLP). Cependant, au lieu d’utiliser des tokens, l’image est divisée en patches et fournie sous forme de séquence d’embeddings linéaires. Ces patches sont traités de la même manière que les tokens ou les mots dans le NLP.
Au lieu de regarder l’image entière simultanément, un ViT découpe l’image en petits morceaux comme un puzzle. Chaque morceau est transformé en une liste de nombres (un vecteur) qui décrit ses caractéristiques, puis le modèle examine tous les morceaux et détermine comment ils se relient les uns aux autres en utilisant un mécanisme de transformateur.
Contrairement aux CNN, les ViT fonctionnent en appliquant des filtres ou des noyaux spécifiques sur une image pour détecter des caractéristiques particulières, telles que des motifs de bord. C’est le processus de convolution qui est très similaire à une imprimante scannant une image. Ces filtres glissent sur toute l’image et mettent en évidence des caractéristiques significatives. Le réseau empile ensuite plusieurs couches de ces filtres, identifiant progressivement des motifs plus complexes.
Avec les CNN, les couches de pooling réduisent la taille des cartes de caractéristiques. Ces couches analysent les caractéristiques extraites pour faire des prédictions utiles pour la reconnaissance d’images, la détection d’objets, etc. Cependant, les CNN ont un champ réceptif fixe, limitant ainsi la capacité à modéliser les dépendances à longue portée.
Comment les CNN voient-ils les images ?
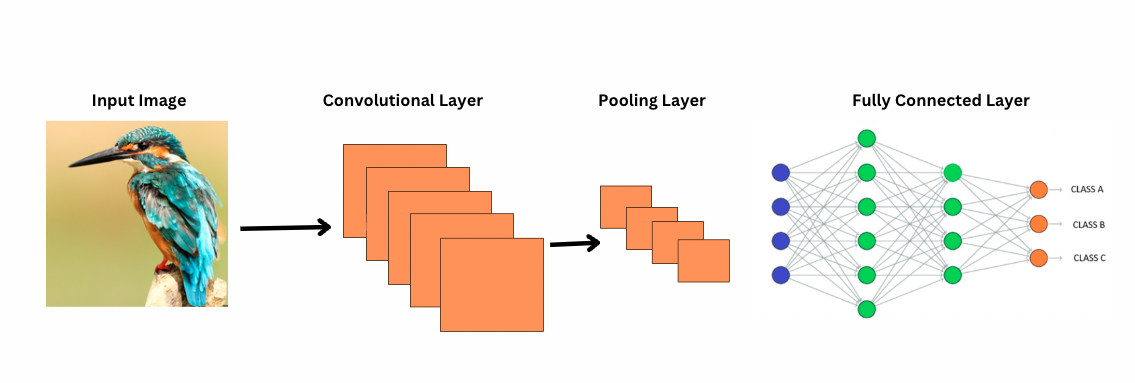
Les ViTs, malgré un plus grand nombre de paramètres, utilisent des mécanismes d’attention pour une meilleure représentation des caractéristiques et réduisent le besoin de couches plus profondes. Les CNN nécessitent une architecture significativement plus profonde pour atteindre une puissance de représentation similaire, ce qui entraîne des coûts computationnels accrus.
De plus, les CNN ne peuvent pas capturer les motifs d’image à un niveau global car leurs filtres se concentrent sur des régions locales d’une image. Pour comprendre l’ensemble de l’image ou les relations à distance, les CNN s’appuient sur l’empilement de nombreuses couches et sur le pooling, élargissant le champ de vision. Cependant, ce processus peut faire perdre des informations globales car il agrège les détails étape par étape.
Les ViTs, en revanche, divisent l’image en patches qui sont traités comme des tokens d’entrée individuels. En utilisant l’attention, les ViTs comparent tous les patches simultanément et apprennent comment ils se rapportent les uns aux autres. Cela leur permet de capturer des motifs et des dépendances à travers l’ensemble de l’image sans les construire couche par couche.
Qu’est-ce que le biais inductif ?
Avant d’aller plus loin, il est important de comprendre le concept de biais inductif. Le biais inductif fait référence à l’hypothèse qu’un modèle fait sur la structure des données ; pendant l’entraînement, cela aide le modèle à être plus généralisé et à réduire le biais. Dans les CNN, les biais inductifs incluent :
- Localité : Les caractéristiques dans les images (comme les bords ou les textures) sont localisées dans de petites régions.
- Structure de voisinage bidimensionnelle: Les pixels proches ont plus de chances d’être liés, donc les filtres agissent sur des régions spatialement adjacentes.
- Translation equivariance: Les caractéristiques détectées dans une partie de l’image, comme un bord, conservent la même signification si elles apparaissent dans une autre partie.
Ces biais rendent les CNN très efficaces pour les tâches d’image, car ils sont conçus pour exploiter intrinsèquement les propriétés spatiales et structurales des images.
Les transformers de vision (ViTs) ont significativement moins de biais inductifs spécifiques à l’image que les CNN. Dans les ViTs :
- Traitement global: Les couches d’auto-attention opèrent sur l’ensemble de l’image, permettant au modèle de capturer les relations globales et les dépendances sans être limité par les régions locales.
- Structure 2D minimale: La structure 2D de l’image est utilisée uniquement au début (lorsque l’image est divisée en patchs) et lors du peaufinage (pour ajuster les plongements positionnels pour différentes résolutions). Contrairement aux CNN, les ViTs ne supposent pas que les pixels proches sont nécessairement liés.
- Relations spatiales apprises: Les plongements positionnels dans les ViTs n’encodent pas de relations spatiales 2D spécifiques à l’initialisation. Au lieu de cela, le modèle apprend toutes les relations spatiales à partir des données lors de l’entraînement.
Comment fonctionnent les transformers de vision
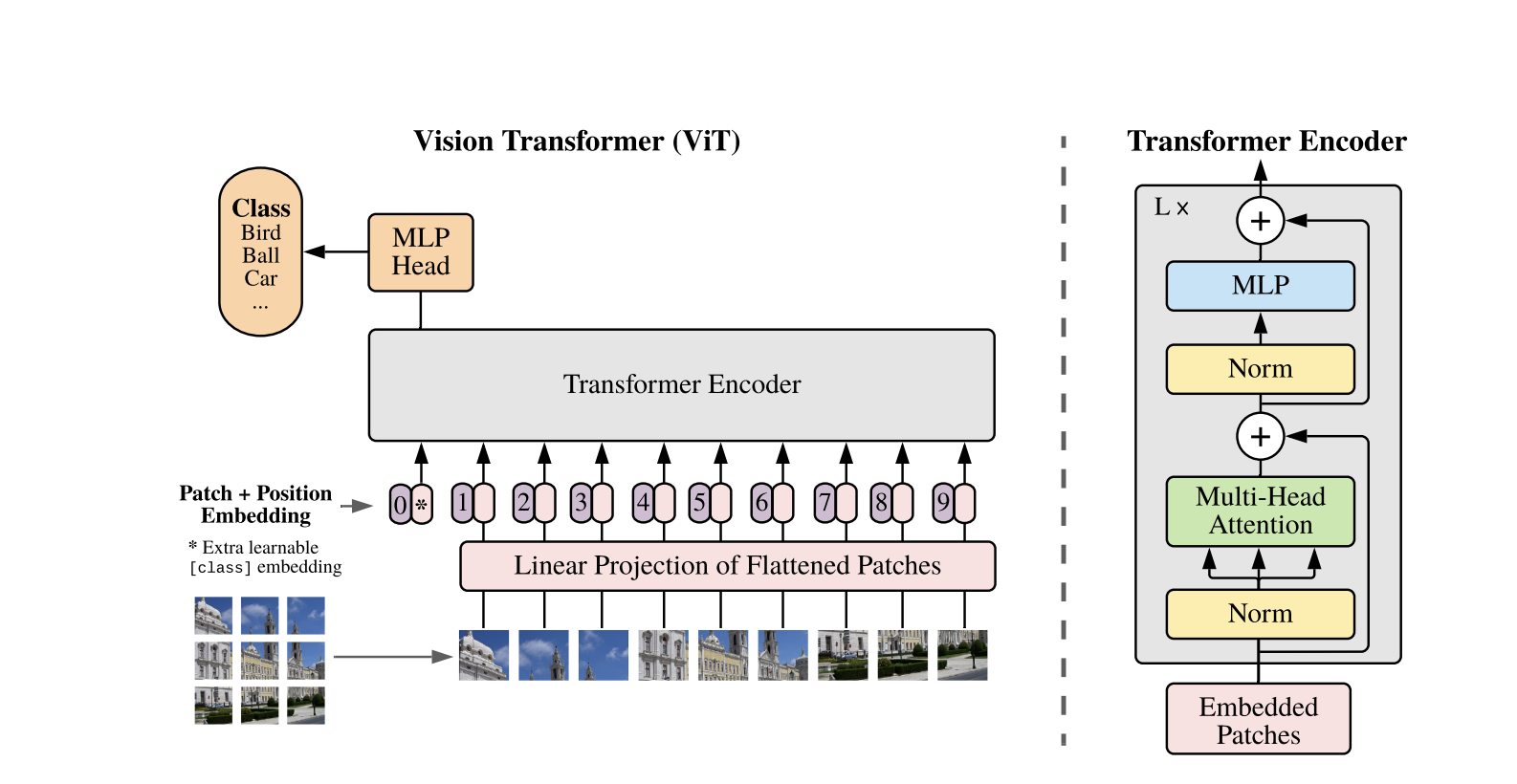
Les Vision Transformers utilisent l’architecture standard du Transformer développée pour les séquences de texte 1D. Pour traiter les images 2D, elles sont divisées en de plus petits patchs de taille fixe, tels que P P pixels, qui sont aplatis en vecteurs. Si l’image a des dimensions H W avec C canaux, le nombre total de patchs est N = H W / P P, la longueur d’entrée effective de la séquence pour le Transformer. Ces patchs aplatis sont ensuite projetés linéairement dans un espace dimensionnel fixe D, appelé les incrustations de patch.
Un jeton appris spécial, similaire au jeton [CLS] dans BERT, est ajouté en tête de la séquence d’incrustations de patch. Ce jeton apprend une représentation globale de l’image qui est ensuite utilisée pour la classification. De plus, des incrustations positionnelles sont ajoutées aux incrustations de patch pour encoder des informations de position, aidant le modèle à comprendre la structure spatiale de l’image.
La séquence d’embeddings est passée à travers l’encodeur Transformer, qui alterne entre deux opérations principales : Attention Autoregressive Multi-Tête (MSA) et un réseau de neurones feedforward, également appelé bloc MLP. Chaque couche inclut Normalisation de Couche (LN) appliquée avant ces opérations et des connexions résiduelles ajoutées par la suite pour stabiliser l’entraînement. La sortie de l’encodeur Transformer, spécifiquement l’état du token [CLS], est utilisée comme représentation de l’image.
Une tête simple est ajoutée au token final [CLS] pour les tâches de classification. Pendant le préentraînement, cette tête est un petit perceptron multicouche (MLP), tandis que lors de l’ajustement fin, il s’agit généralement d’une seule couche linéaire. Cette architecture permet aux ViTs de modéliser efficacement les relations globales entre les patches et d’utiliser toute la puissance de l’attention autonome pour la compréhension d’image.
Dans un modèle hybride de Vision Transformer, au lieu de diviser directement les images brutes en patches, la séquence d’entrée est dérivée des cartes de caractéristiques générées par un CNN. Le CNN traite d’abord l’image, extrayant des caractéristiques spatiales significatives, qui sont ensuite utilisées pour créer des patches. Ces patches sont aplatis et projetés dans un espace de dimension fixe en utilisant la même projection linéaire entraînable que dans les Vision Transformers standard. Un cas particulier de cette approche consiste à utiliser des patches de taille 1×1, où chaque patch correspond à un emplacement spatial unique dans la carte de caractéristiques du CNN.
Dans ce cas, les dimensions spatiales de la carte des caractéristiques sont aplaties, et la séquence résultante est projetée dans la dimension d’entrée du Transformateur. Comme avec le ViT standard, un jeton de classification et des plongements positionnels sont ajoutés pour conserver les informations de position et permettre une compréhension globale de l’image. Cette approche hybride tire parti des forces d’extraction de caractéristiques locales des CNN tout en les combinant avec les capacités de modélisation globale des Transformateurs.
Démonstration de code
Voici le bloc de code sur comment utiliser les transformateurs d’image.
Le modèle ViT traite l’image. Il comprend un encodeur de type BERT et une tête de classification linéaire située au sommet de l’état caché final du jeton [CLS].
Voici une implémentation basique du Transformateur d’Images (ViT) en utilisant PyTorch. Ce code inclut les composants principaux : l’encodage de patch, le codage positionnel et l’encodeur Transformer. Cela peut être utilisé pour des tâches de classification simples.
Composants clés:
- Intégration de patch: Les images sont divisées en patchs plus petits, aplatis et transformés linéairement en intégrations.
- Encodage de position: Les informations de position sont ajoutées aux intégrations de patch, car les Transformers sont agnostiques à la position.
- Encodeur Transformer: Applique des couches d’auto-attention et de feed-forward pour apprendre les relations entre les patchs.
- Tête de Classification : Produit les probabilités de classe en utilisant le token CLS.
Vous pouvez entraîner ce modèle sur n’importe quel ensemble de données d’images en utilisant un optimiseur comme Adam et une fonction de perte comme l’entropie croisée. Pour de meilleures performances, envisagez un pré-entraînement sur un grand ensemble de données avant l’ajustement fin.
Travaux Suivants Populaires
-
DeiT (Transformateurs d’Images Efficaces en Données) par Facebook AI : Ce sont des transformateurs de vision entraînés efficacement avec la distillation des connaissances. DeiT propose quatre variantes : deit-tiny, deit-small, et deux modèles deit-base. Utilisez
DeiTImageProcessorpour préparer les images. -
BEiT (Pré-entraînement BERT des Transformateurs d’Image) par Microsoft Research : Inspiré par BERT, BEiT utilise la modélisation d’image masquée auto-supervisée et surpasse les ViTs supervisés. Il repose sur VQ-VAE pour l’entraînement.
-
DINO (Entraînement de Transformateurs d’Image Auto-supervisé) par Facebook AI : Les ViTs entraînés avec DINO peuvent segmenter des objets sans entraînement explicite. Des points de contrôle sont disponibles en ligne.
-
MAE (Masked Autoencoders) par Facebook pré-entraîne les ViTs en reconstruisant des patchs masqués (75%). Lorsqu’ils sont affinés, cette méthode simple dépasse l’entraînement supervisé.
Conclusion
En conclusion, les ViTs sont une excellente alternative aux CNN car ils appliquent des transformers à la reconnaissance d’images, minimisent les biais inductifs et traitent les images comme des patchs de séquence. Cette approche simple mais évolutive a démontré des performances de pointe sur de nombreux bancs d’essai de classification d’images, en particulier lorsqu’elle est associée à un pré-entraînement sur de grands ensembles de données. Cependant, des défis potentiels subsistent, notamment l’extension des ViTs à des tâches telles que la détection d’objets et la segmentation, l’amélioration des méthodes d’auto-entraînement et l’exploration du potentiel de mise à l’échelle des ViTs pour des performances encore meilleures.
Ressources Additionnelles
Source:
https://www.digitalocean.com/community/tutorials/vision-transformer-for-computer-vision