













ここ数年、トランスフォーマーは機械学習のNLP領域を変革してきました。GPTやBERTなどのモデルは、人間の言語の理解と生成において新たな基準を設定してきました。今、同じ原理がコンピュータビジョン領域にも適用されています。
コンピュータビジョン分野における最近の進展の1つが、ビジョン・トランスフォーマーやViTsです。論文「An Image is Worth 16×16 Words: Transformers for Image Recognition at Scale」で詳細に説明されているように、ViTsやトランスフォーマーをベースとしたモデルは、畳み込みニューラルネットワーク(CNNs)に代わるよう設計されています。
ビジョン・トランスフォーマーは、コンピュータビジョンにおける問題解決に新しいアプローチを提供しています。数十年にわたり画像関連のタスクの中核をなしてきた従来の畳み込みニューラルネットワーク(CNNs)に頼るのではなく、ViTsは画像を処理するためにトランスフォーマーのアーキテクチャを使用しています。画像のパッチを文章中の単語のように扱い、モデルがこれらのパッチ間の関係を学習することを可能にしています。
CNNとは異なり、ViTは入力画像をパッチに分割し、ベクトルに直列化し、行列の乗算を使用して次元を削減します。その後、トランスフォーマーエンコーダーがこれらのベクトルをトークン埋め込みとして処理します。この記事では、ビジョン・トランスフォーマーと畳み込みニューラルネットワークとの主な違いを探求します。彼らを特に興味深いものにしているのは、画像内のグローバルなパターンを理解する能力であり、これはCNNが苦労することがある点です。
前提条件
- ニューラルネットワークの基礎:ニューラルネットワークがデータをどのように処理するかを理解していること。
- 畳み込みニューラルネットワーク(CNN):CNNとそのコンピュータビジョンにおける役割に精通していること。
- トランスフォーマーアーキテクチャ:特に自然言語処理でのトランスフォーマーの使用についての知識。
- 画像処理:画像表現、チャンネル、ピクセル配列などの基本的な概念を理解していること。
- アテンションメカニズム:自己注意とその入力間の関係をモデル化する能力を理解していること。
ビジョン・トランスフォーマーとは何ですか?
ビジョン・トランスフォーマーは、注意とトランスフォーマーの概念を使用して画像を処理します。これは、自然言語処理(NLP)の文脈でのトランスフォーマーと似ています。ただし、トークンを使用せず、画像はパッチに分割され、線形埋め込みのシーケンスとして提供されます。これらのパッチは、NLPにおいてトークンや単語が扱われるのと同じように扱われます。
画像全体を同時に見る代わりに、ViTは画像をジグソーパズルのような小さなピースに分割します。各ピースは、その特徴を記述する数字(ベクトル)のリストに変換され、その後、モデルはすべてのピースを見て、トランスフォーマー機構を使用してそれらがどのように関連しているかを把握します。
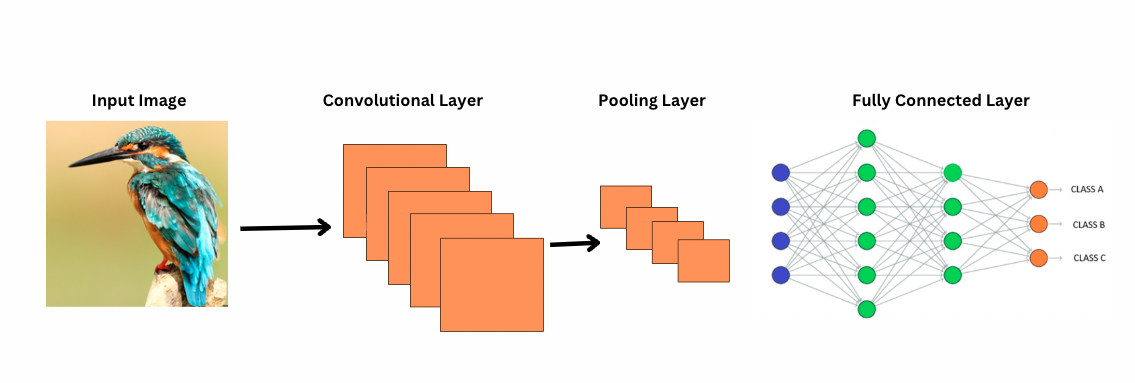
CNNとは異なり、ViTは特定のフィルタやカーネルを画像の上に適用して特定の特徴(例:エッジパターン)を検出することで機能します。これは、プリンタが画像をスキャンするのに非常に似ている畳み込みプロセスです。これらのフィルタは画像全体をスライドし、重要な特徴を強調します。その後、ネットワークはこれらのフィルタの複数の層を重ね、より複雑なパターンを段階的に特定します。
CNNでは、プーリング層が特徴マップのサイズを縮小します。これらの層は、抽出された特徴を分析し、画像認識、物体検出などに役立つ予測を行います。ただし、CNNは固定された受容野を持っており、長距離の依存関係をモデル化する能力が制限されています。
CNNが画像をどのように見るか?
ViTsは、より多くのパラメータを持っているにもかかわらず、より良い特徴表現のために自己注意メカニズムを使用し、より深いレイヤーの必要性を減らします。同様の表現力を得るためには、CNNは著しく深いアーキテクチャが必要であり、これは増加した計算コストにつながります。
さらに、CNNは画像の局所領域に焦点を当てたフィルタを使うため、グローバルレベルの画像パターンを捉えることができません。画像全体や遠い関係を理解するためには、CNNは多くの層を積み重ねてプーリングを行い、視野を広げる必要があります。ただし、このプロセスでは段階的に詳細を集約することでグローバル情報が失われる可能性があります。
一方、ViTsは画像をパッチに分割し、個々の入力トークンとして扱います。自己注意を使用することで、ViTsはすべてのパッチを同時に比較し、それらの関連性を学習します。これにより、層を一つずつ構築することなく、画像全体をまたいだパターンや依存関係を捉えることができます。
帰納バイアスとは何ですか?
さらに進む前に、帰納バイアスの概念を理解することが重要です。帰納バイアスとは、モデルがデータ構造について行う仮定を指し、トレーニング中にこれはモデルが一般化され、バイアスが減少するのに役立ちます。CNNにおける帰納バイアスには以下が含まれます:
- 局所性:画像中の特徴(エッジやテクスチャなど)は小さな領域内に局在しています。
- 2次元近傍構造: 近くのピクセルは関連がある可能性が高いため、フィルターは空間的に隣接した領域に作用します。
- 翻訳の同変性: 画像の一部で検出された特徴(例:エッジ)は、別の部分に現れた場合でも同じ意味を保持します。
これらのバイアスにより、CNNは画像タスクに非常に効率的です。なぜなら、CNNは画像の空間的および構造的な特性を活用するように設計されているからです。
ビジョン・トランスフォーマー(ViTs)は、CNNよりも画像固有の帰紵的なバイアスが著しく少ないです。ViTsでは:
- グローバル処理: セルフアテンション層は画像全体で動作し、モデルは地域に制限されることなく、グローバルな関係と依存関係を捉えます。
- 最小限の2D構造: 画像の2D構造は、パッチに分割されるとき(開始時)とファインチューニング中にのみ使用されます(異なる解像度の位置エンベディングを調整するため)。CNNとは異なり、ViTsは近くのピクセルが必ずしも関連しているとは仮定しません。
- 学習された空間関係: ViTsの位置エンベディングは初期化時に特定の2D空間関係をエンコードしません。代わりに、モデルはトレーニング中にデータからすべての空間関係を学習します。
ビジョン・トランスフォーマーの動作原理
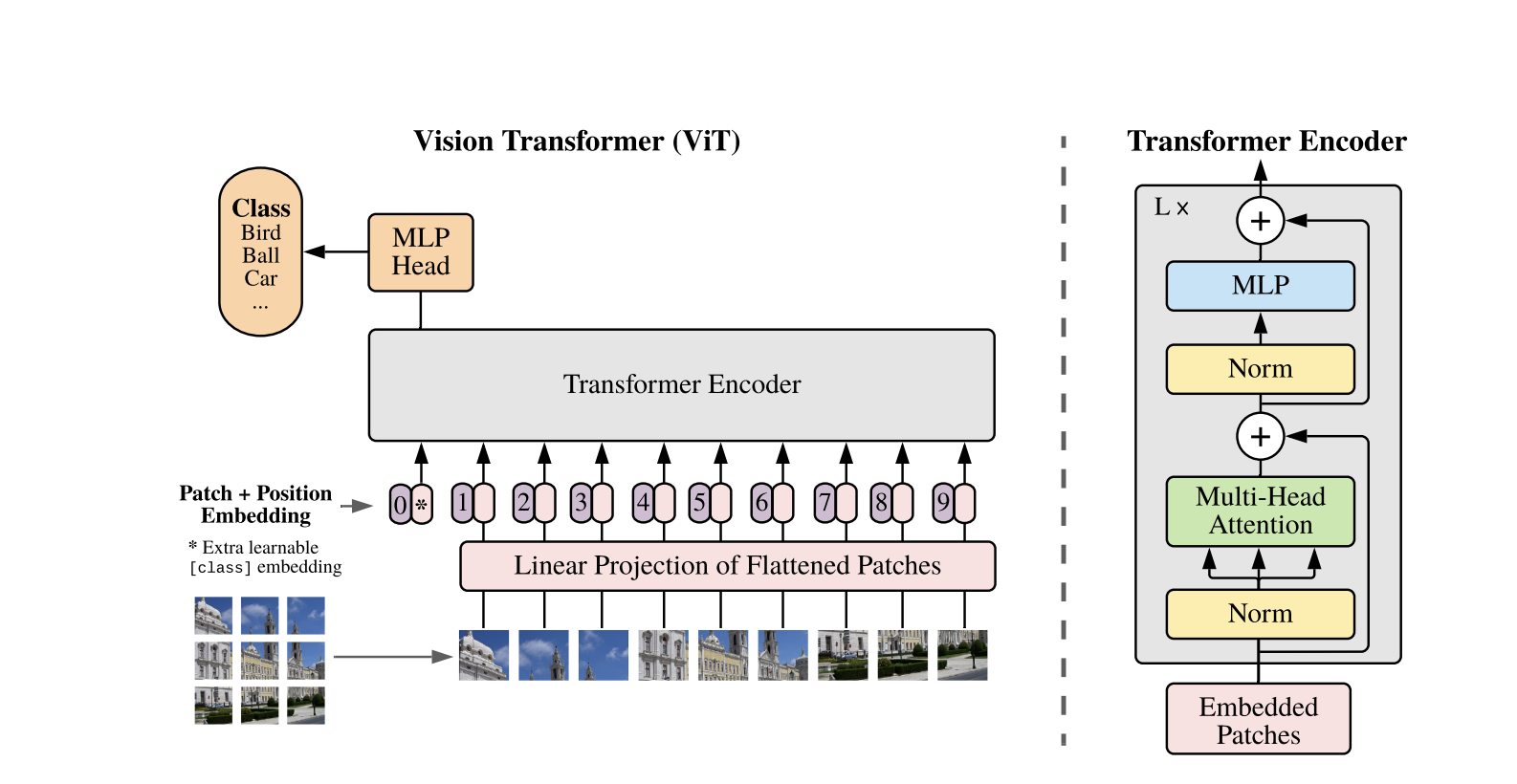
ビジョン・トランスフォーマーは、1次元のテキストシーケンス向けに開発された標準のトランスフォーマーアーキテクチャを使用しています。2次元の画像を処理するために、それらは固定サイズのより小さなパッチに分割され、P×Pピクセルのようにフラット化されたベクトルにします。画像がH×WのサイズでCチャンネルを持つ場合、パッチの総数はN = H×W / P×Pであり、トランスフォーマーのための効果的な入力シーケンス長です。これらのフラット化されたパッチは、固定次元の空間Dに線形に射影され、パッチ埋め込みと呼ばれます。
特別な学習可能なトークンが、BERTの[CLS]トークンに似て、パッチ埋め込みのシーケンスの前に追加されます。このトークンは後で分類に使用されるグローバルな画像表現を学習します。さらに、位置埋め込みがパッチ埋め込みに追加され、位置情報を符号化し、モデルが画像の空間構造を理解するのに役立ちます。
埋め込みのシーケンスは、Transformer エンコーダを通過し、マルチヘッド自己注意(MSA) と呼ばれるフィードフォワードニューラルネットワーク、または MLP ブロックを交互に行います。各層には、レイヤー正規化(LN) がこれらの操作の前に適用され、トレーニングを安定させるためにその後に残差接続が追加されます。Transformer エンコーダの出力、特に [CLS] トークンの状態が、画像の表現として使用されます。
分類タスクのために、最終的な [CLS] トークンにはシンプルなヘッドが追加されます。事前トレーニング中、このヘッドは小さなマルチレイヤーパーセプトロン(MLP)ですが、ファインチューニング中は通常、単一の線形層です。このアーキテクチャにより、ViT はパッチ間のグローバルな関係を効果的にモデル化し、画像理解のための自己注意の全力を活用できます。
ハイブリッド Vision Transformer モデルでは、生の画像を直接パッチに分割する代わりに、入力シーケンスは CNN によって生成された特徴マップから派生します。CNN はまず画像を処理し、意味のある空間的特徴を抽出し、それらを使用してパッチを作成します。これらのパッチはフラット化され、標準的な Vision Transformers と同じ学習可能な線形射影を使用して固定次元空間に投影されます。このアプローチの特別なケースは、1×1 のパッチを使用することであり、各パッチが CNN の特徴マップ内の単一の空間位置に対応する点です。
この場合、特徴マップの空間次元が平坦化され、結果として得られるシーケンスがTransformerの入力次元に投影されます。標準のViTと同様に、位置情報を保持し、グローバルな画像理解を可能にするために、分類トークンと位置エンベッディングが追加されます。このハイブリッドアプローチは、CNNのローカルな特徴抽出の強みを活用しながら、Transformerのグローバルなモデリング能力と組み合わせます。
コードデモ
画像のビジョン・トランスフォーマーの使用方法に関するコードブロックは次のとおりです。
ViTモデルは画像を処理します。これにはBERTのようなエンコーダーと、[CLS]トークンの最終的な隠れ状態の上に配置された線形分類ヘッドが含まれます。
以下は、PyTorchを使用した基本的なビジョン・トランスフォーマー(ViT)の実装です。このコードには、パッチ埋め込み、位置エンコーディング、およびTransformerエンコーダーが含まれます。これは単純な分類タスクに使用できます。
主要コンポーネント:
- パッチ埋め込み: 画像はより小さなパッチに分割され、フラット化され、埋め込みに線形変換されます。
- 位置エンコーディング: 位置情報がパッチの埋め込みに追加され、トランスフォーマーは位置に依存しないためです。
- トランスフォーマーエンコーダー: セルフアテンションとフィードフォワードレイヤーを適用して、パッチ間の関係を学習します。
- 分類ヘッド: CLSトークンを使用してクラスの確率を出力します。
Adamなどのオプティマイザーと交差エントロピーなどの損失関数を使用して、このモデルを任意の画像データセットでトレーニングできます。性能を向上させるためには、ファインチューニングの前に大規模なデータセットで事前トレーニングを検討してください。
人気のある後続作業
-
DeiT(データ効率型画像トランスフォーマー) by Facebook AI: これらは知識蒸留を使用して効率的にトレーニングされたビジョントランスフォーマーです。DeiTには4つのバリアントがあります: deit-tiny, deit-small, および2つの deit-base モデル。画像を準備するには
DeiTImageProcessorを使用してください。 -
Microsoft ResearchによるBEiT(BERT pre-training of Image Transformers):BERTに触発されたBEiTは、自己教師付きマスク画像モデリングを使用し、教師付きViTsを上回る性能を発揮します。トレーニングにはVQ-VAEを使用しています。
-
Facebook AIによるDINO(Self-supervised Vision Transformer Training):DINOで訓練されたViTsは、明示的なトレーニングなしにオブジェクトをセグメント化できます。チェックポイントはオンラインで入手可能です。
-
Facebookは、マスクされたオートエンコーダー(MAE)を使用して、ViTsを再構成したマスクされたパッチ(75%)で事前トレーニングしています。ファインチューニングされると、このシンプルな方法が教師付き事前トレーニングを上回ります。
結論
結論として、ViTsは画像認識にトランスフォーマーを適用し、帰納バイアスを最小限に抑え、画像をシーケンスパッチとして扱うため、CNNの優れた代替手段です。このシンプルで拡張可能なアプローチは、多くの画像分類ベンチマークで最先端のパフォーマンスを実証しており、特に大規模なデータセットでの事前トレーニングと組み合わせた場合に顕著です。ただし、ViTsを物体検出やセグメンテーションなどのタスクに拡張し、自己教師付き事前トレーニング方法をさらに改善し、ViTsのスケーリングの可能性を探るなど、潜在的な課題が残っています。
追加リソース
Source:
https://www.digitalocean.com/community/tutorials/vision-transformer-for-computer-vision