













За последние несколько лет трансформеры преобразили область NLP в машинном обучении. Модели, такие как GPT и BERT, установили новые стандарты в понимании и генерации человеческого языка. Теперь тот же принцип применяется в области компьютерного зрения.
Недавнее развитие в области компьютерного зрения – это видеотрансформеры или ViTs. Как подробно описано в статье “Картинка стоит 16×16 слов: трансформеры для распознавания изображений в масштабе”, ViTs и модели на основе трансформеров разработаны для замены сверточных нейронных сетей (CNNs).
Видеотрансформеры – это новый подход к решению проблем в области компьютерного зрения. Вместо использования традиционных сверточных нейронных сетей (CNNs), которые были основой задач, связанных с изображениями, на протяжении десятилетий, ViTs используют архитектуру трансформера для обработки изображений. Они обрабатывают патчи изображения как слова в предложении, позволяя модели изучать отношения между этими патчами, как она изучает контекст в абзаце текста.
В отличие от сверточных нейронных сетей, ViT разделяют входные изображения на фрагменты, сериализуют их в вектора и уменьшают их размерность с помощью матричного умножения. Затем кодировщик трансформера обрабатывает эти векторы как токенные вложения. В этой статье мы исследуем видовые трансформеры и их основные отличия от сверточных нейронных сетей. Их особенной интересностью является способность понимать глобальные паттерны на изображении, с чем сверточные нейронные сети могут иметь проблемы.
Предпосылки
- Основы нейронных сетей: Понимание того, как нейронные сети обрабатывают данные.
- Сверточные нейронные сети (CNN): Знакомство с CNN и их ролью в компьютерном зрении.
- Архитектура трансформера: Знание трансформеров, особенно их использование в NLP.
- Обработка изображений: Понимание основных концепций, таких как представление изображения, каналы и пиксельные массивы.
- Механизм внимания: Понимание самовнимания и его способности моделировать отношения между входами.
Что такое видовые трансформеры?
Трансформеры видения используют концепцию внимания и трансформеры для обработки изображений — это аналогично трансформерам в контексте обработки естественного языка (NLP). Однако вместо использования токенов изображение разбивается на фрагменты и предоставляется в виде последовательности линейных вложений. Эти фрагменты обрабатываются так же, как токены или слова в NLP.
Вместо того чтобы смотреть на всю картину одновременно, ViT разбивает изображение на маленькие кусочки, подобно пазлу. Каждый кусок превращается в список чисел (вектор), описывающих его особенности, после чего модель рассматривает все куски и определяет, как они взаимосвязаны друг с другом, используя механизм трансформера.
В отличие от свёрточных нейронных сетей, ViT работает, применяя определённые фильтры или ядра к изображению для обнаружения конкретных особенностей, таких как узоры краев. Это процесс свёртки, который очень похож на сканирование изображения принтером. Эти фильтры скользят по всему изображению и выделяют значимые особенности. Затем сеть накладывает несколько слоев этих фильтров, постепенно идентифицируя более сложные узоры.
С помощью свёрточных нейронных сетей слои пулинга уменьшают размер карт признаков. Эти слои анализируют извлечённые признаки, чтобы делать прогнозы, полезные для распознавания изображений, детектирования объектов и т. д. Однако у свёрточных нейронных сетей фиксированное рецептивное поле, что ограничивает возможность моделирования долгосрочных зависимостей.
Как свёрточные нейронные сети видят изображения?
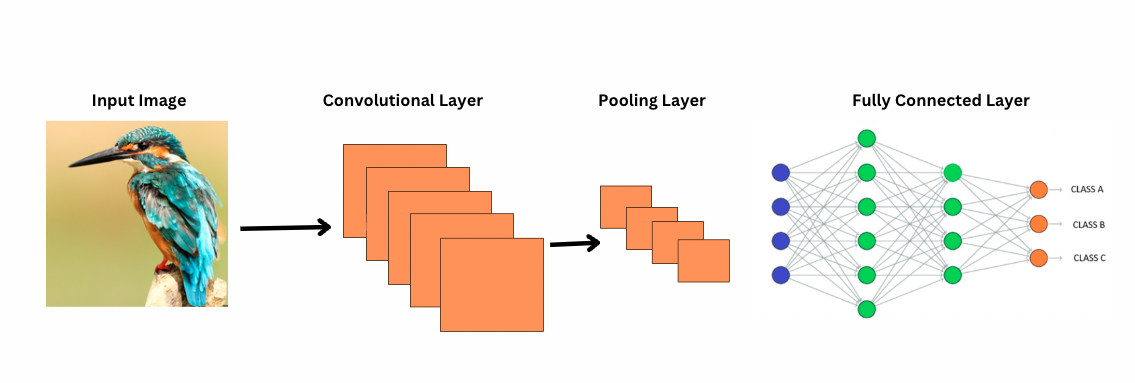
ViTs, несмотря на большее количество параметров, используют механизмы самовнимания для лучшего представления признаков и уменьшения необходимости в более глубоких слоях. Для достижения аналогичной репрезентативной мощности CNN требуется значительно более глубокая архитектура, что приводит к увеличению вычислительных затрат.
Кроме того, CNN не могут захватывать глобальные образовательные образы изображений, потому что их фильтры сосредотачиваются на локальных областях изображения. Для понимания всего изображения или отдаленных отношений CNN полагаются на наложение множества слоев и пулинг, расширяя область обзора. Однако этот процесс может потерять глобальную информацию, так как детали агрегируются пошагово.
С другой стороны, ViT разделяют изображение на фрагменты, которые рассматриваются как отдельные входные токены. Используя самовнимание, ViT сравнивают все фрагменты одновременно и учатся, как они связаны. Это позволяет им захватывать образцы и зависимости по всему изображению, без построения их слой за слоем.
Что такое индуктивный байес?
Прежде чем двигаться дальше, важно понять концепцию индуктивного байеса. Индуктивный байес относится к предположению, которое модель делает о структуре данных; во время обучения это помогает модели стать более обобщенной и снизить смещение. В CNN индуктивные предположения включают:
- Локальность: Признаки в изображениях (например, края или текстуры) локализованы в небольших областях.
- Двумерная структура окрестности: Близкие пиксели скорее всего взаимосвязаны, поэтому фильтры действуют на пространственно смежные области.
- Эквивариантность перевода: Особенности, обнаруженные в одной части изображения, например, край, сохраняют тот же смысл, если они появляются в другой части.
Эти предвзятости делают сверточные нейронные сети чрезвычайно эффективными для задач обработки изображений, поскольку они по своей природе разработаны для использования пространственных и структурных свойств изображений.
У Vision Transformers (ViTs) значительно меньше специфичных для изображений индуктивных предвзятостей, чем у CNN. В ViTs:
- Глобальная обработка: Слои самовнимания работают на всем изображении, позволяя модели улавливать общие отношения и зависимости, не ограничиваясь локальными областями.
- Минимальная 2D структура: Двумерная структура изображения используется только в начале (когда изображение разделяется на участки) и во время тонкой настройки (для корректировки позиционных вложений для разных разрешений). В отличие от CNN, ViTs не предполагают, что близкие пиксели обязательно взаимосвязаны.
- Выученные пространственные отношения: Позиционные вложения в ViTs не кодируют конкретные двумерные пространственные отношения при инициализации. Вместо этого модель изучает все пространственные отношения из данных в процессе обучения.
Как работают Vision Transformers
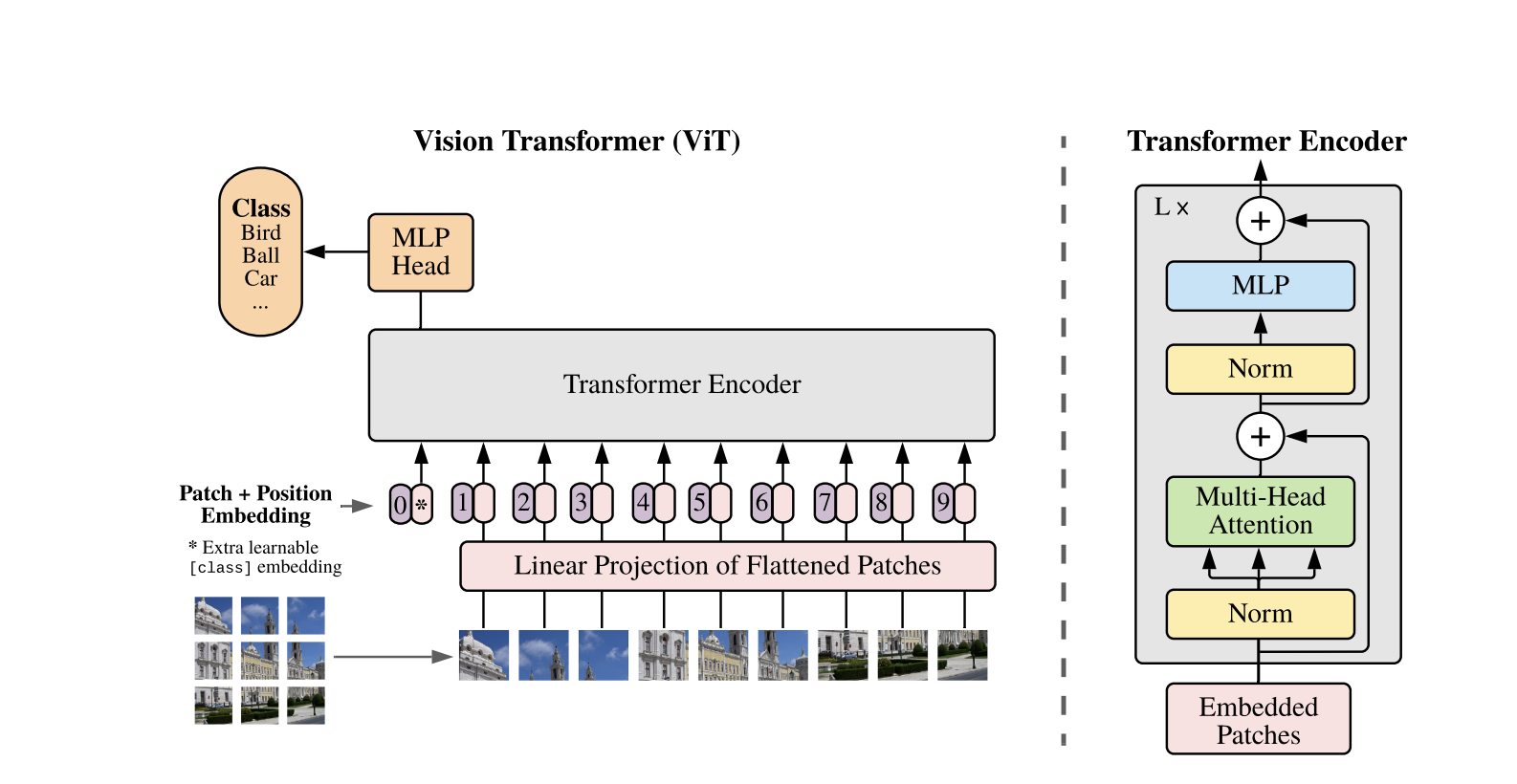
Vision Transformers используют стандартную архитектуру Transformer, разработанную для одномерных текстовых последовательностей. Для обработки двумерных изображений они делят их на меньшие патчи фиксированного размера, например, P P пикселей, которые выравниваются в векторы. Если изображение имеет размеры H W с C каналами, общее количество патчей равно N = H W / P P, что является эффективной длиной входной последовательности для Transformer. Эти выровненные патчи затем линейно проецируются в фиксированное пространство размерности D, называемое встраиваниями патчей.
К последовательности встраиваний патчей добавляется специальный обучаемый токен, аналогичный токену [CLS] в BERT. Этот токен обучает глобальное представление изображения, которое затем используется для классификации. Кроме того, к встраиваниям патчей добавляются позиционные встраивания, чтобы закодировать позиционную информацию, помогая модели понять пространственную структуру изображения.
Последовательность вложений проходит через кодер Трансформера, который чередует две основные операции: Многоголовое самовнимание (MSA) и нейронная сеть прямого распространения, также называемый блок MLP. Каждый слой включает в себя Нормализацию слоя (LN), применяемую перед этими операциями, и добавленные после них остаточные соединения для стабилизации обучения. Выход кодера Трансформера, точнее состояние токена [CLS], используется как представление изображения.
Простая голова добавляется к конечному токену [CLS] для классификационных задач. Во время предварительного обучения эта голова является небольшим многослойным персептроном (MLP), в то время как при настройке feine-tuning обычно используется один линейный слой. Эта архитектура позволяет ViT эффективно моделировать глобальные отношения между патчами и использовать полную мощь самовнимания для понимания изображения.
В гибридной модели Vision Transformer вместо непосредственного разделения исходных изображений на патчи входная последовательность происходит из карт признаков, сгенерированных CNN. Сначала CNN обрабатывает изображение, извлекая смысловые пространственные признаки, которые затем используются для создания патчей. Эти патчи выравниваются и проецируются в фиксированное размерное пространство с использованием той же обучаемой линейной проекции, что и в стандартных Vision Transformers. Особый случай этого подхода – использование патчей размером 1×1, где каждый патч соответствует одному пространственному положению на карте признаков CNN.
В этом случае пространственные размеры карты объектов уплощаются, и полученная последовательность проецируется на входное измерение трансформера. Как и в стандартной модели ViT, для сохранения информации о позиции и обеспечения глобального понимания изображения добавляются токен классификации и позиционные вложения. Этот гибридный подход использует преимущества локального извлечения признаков CNN в сочетании с глобальными возможностями моделирования трансформеров.
Пример кода
Вот блок кода о том, как использовать визионные трансформеры на изображениях.
Модель ViT обрабатывает изображение. Она состоит из кодера, похожего на BERT, и линейного классификатора, расположенного поверх окончательного скрытого состояния токена [CLS].
Вот базовая реализация Визионного Трансформера (ViT) с использованием PyTorch. Этот код включает основные компоненты: встраивание патчей, позиционное кодирование и кодер трансформера. Это можно использовать для простых задач классификации.
Основные компоненты:
- Встраивание патчей: Изображения разделяются на более мелкие патчи, выпрямляются и линейно преобразуются во вложения.
- Позиционное кодирование: Позиционная информация добавляется к вложениям патчей, так как трансформеры не зависят от позиции.
- Кодировщик трансформера: Применяет самовнимание и слои прямого распространения для изучения взаимосвязей между патчами.
- Классификационная голова: Выводит вероятности классов, используя токен CLS.
Вы можете обучать эту модель на любом наборе изображений, используя оптимизатор, такой как Adam, и функцию потерь, например, перекрестную энтропию. Для лучшей производительности рассмотрите предварительное обучение на большом наборе данных перед настройкой.
Популярные последующие работы
-
DeiT (Data-efficient Image Transformers) от Facebook AI: Это видовые трансформеры, обученные эффективно с помощью дистилляции знаний. DeiT предлагает четыре варианта: deit-tiny, deit-small и две модели deit-base. Используйте
DeiTImageProcessorдля подготовки изображений. -
BEiT (BERT предварительное обучение трансформеров изображений) от Microsoft Research: Вдохновленный BERT, BEiT использует моделирование изображений с маскировкой на основе самообучения и превосходит надзорные ViT. Он полагается на VQ-VAE для обучения.
-
DINO (Самообучение Вижн-трансформеров) от Facebook AI: DINO-обученные ViT могут сегментировать объекты без явного обучения. Чекпоинты доступны онлайн.
-
MAE (Маскированные автокодировщики) от Facebook предварительно обучают ViTs путем восстановления маскированных участков (75%). При настройке Fein-tuned этот простой метод превосходит надзорное предварительное обучение.
Вывод
В заключение, ViTs являются отличной альтернативой для CNN, поскольку они применяют трансформеры к распознаванию изображений, минимизируют индуктивный уклон и обрабатывают изображения как последовательности участков. Этот простой, но масштабируемый подход продемонстрировал передовые результаты на многих бенчмарках классификации изображений, особенно в паре с предварительным обучением на больших наборах данных. Однако остаются потенциальные проблемы, включая расширение ViTs на задачи, такие как обнаружение объектов и сегментация, дальнейшее улучшение методов самообучения и исследование потенциала масштабирования ViTs для еще более высокой производительности.
Дополнительные ресурсы
Source:
https://www.digitalocean.com/community/tutorials/vision-transformer-for-computer-vision