













In de afgelopen jaren hebben transformers het NLP domein in machine learning getransformeerd. Modellen zoals GPT en BERT hebben nieuwe benchmarks ingesteld in het begrijpen en genereren van menselijke taal. Nu wordt hetzelfde principe toegepast op het domein van computer vision.
Een recente ontwikkeling op het gebied van computer vision zijn vision transformers of ViTs. Zoals gedetailleerd beschreven in het artikel “An Image is Worth 16×16 Words: Transformers for Image Recognition at Scale”, zijn ViTs en transformer-gebaseerde modellen ontworpen om convolutionele neurale netwerken (CNN’s) te vervangen.
Vision Transformers zijn een frisse benadering om problemen in computer vision op te lossen. In plaats van te vertrouwen op traditionele convolutionele neurale netwerken (CNN’s), die decennialang de ruggengraat zijn geweest van beeldgerelateerde taken, gebruiken ViTs de transformerarchitectuur om afbeeldingen te verwerken. Ze behandelen afbeeldingspatches als woorden in een zin, waardoor het model de relaties tussen deze patches kan leren, net zoals het de context in een alinea tekst leert.
In tegenstelling tot CNN’s verdelen ViT’s invoerafbeeldingen in patches, serialiseren ze deze in vectoren en verminderen ze hun dimensionaliteit met behulp van matrixvermenigvuldiging. Een transformer-encoder verwerkt vervolgens deze vectoren als token-embeddings. In dit artikel zullen we visietransformers verkennen en hun belangrijkste verschillen met convolutionele neurale netwerken. Wat ze bijzonder interessant maakt, is hun vermogen om globale patronen in een afbeelding te begrijpen, iets waar CNN’s moeite mee kunnen hebben.
Vereisten
- Basis van Neurale Netwerken: Begrip van hoe neurale netwerken gegevens verwerken.
- Convolutionele Neurale Netwerken (CNN’s): Bekendheid met CNN’s en hun rol in computer vision.
- Transformer Architectuur: Kennis van transformers, met name hun gebruik in NLP.
- Afbeeldingsverwerking: Begrip van basisconcepten zoals afbeeldingsrepresentatie, kanalen en pixelarrays.
- Aandacht Mechanisme: Begrip van zelf-aandacht en het vermogen om relaties tussen invoer te modelleren.
Wat zijn visietransformers?
Visie-transformers gebruiken het concept van aandacht en transformers om afbeeldingen te verwerken – dit is vergelijkbaar met transformers in een context van natuurlijke taalverwerking (NLP). In plaats van tokens te gebruiken, wordt de afbeelding opgesplitst in patches en als een reeks lineair ingesloten gegeven. Deze patches worden op dezelfde manier behandeld als tokens of woorden in NLP.
In plaats van tegelijkertijd naar het hele beeld te kijken, snijdt een ViT de afbeelding in kleine stukjes, zoals een puzzel. Elk stuk wordt omgevormd tot een lijst van getallen (een vector) die zijn kenmerken beschrijft, en vervolgens kijkt het model naar alle stukjes en bepaalt het hoe ze zich tot elkaar verhouden met behulp van een transformermechanisme.
In tegenstelling tot CNN’s werkt ViTs door specifieke filters of kernen op een afbeelding toe te passen om specifieke kenmerken te detecteren, zoals randpatronen. Dit is het convolutieproces dat zeer vergelijkbaar is met een printer die een afbeelding scant. Deze filters schuiven door de hele afbeelding en benadrukken belangrijke kenmerken. Het netwerk stapelt vervolgens meerdere lagen van deze filters op, waardoor het geleidelijk meer complexe patronen identificeert.
Bij CNN’s verminderen pooling-lagen de grootte van de kenmerkkaarten. Deze lagen analyseren de geëxtraheerde kenmerken om voorspellingen te doen die nuttig zijn voor afbeeldingsherkenning, objectdetectie, enz. Echter, CNN’s hebben een vast receptief veld, waardoor de mogelijkheid om langetermijnafhankelijkheden te modelleren beperkt is.
Hoe bekijken CNN’s afbeeldingen?
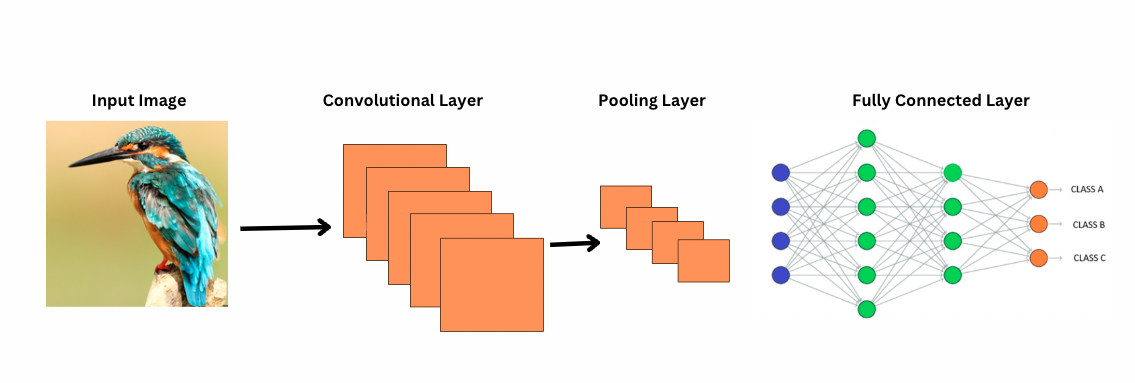
ViTs, ondanks dat ze meer parameters hebben, maken gebruik van zelf-attentiemechanismen voor betere feature-representatie en verminderen de behoefte aan diepere lagen. CNN’s vereisen aanzienlijk diepere architecturen om een vergelijkbare representatieve kracht te bereiken, wat leidt tot hogere computatiekosten.
Daarnaast kunnen CNN’s globale afbeeldingspatronen niet vastleggen omdat hun filters zich richten op lokale gebieden van een afbeelding. Om de gehele afbeelding of verre relaties te begrijpen, zijn CNN’s afhankelijk van het stapelen van veel lagen en pooling, waardoor het gezichtsveld wordt vergroot. Dit proces kan echter globale informatie verliezen terwijl het details stap voor stap aggregeert.
ViTs daarentegen verdelen de afbeelding in patches die worden behandeld als individuele invoertokens. Door gebruik te maken van zelf-attentie vergelijken ViTs alle patches gelijktijdig en leren ze hoe ze zich tot elkaar verhouden. Dit stelt hen in staat om patronen en afhankelijkheden over de hele afbeelding vast te leggen zonder ze laag voor laag op te bouwen.
Wat is Inductieve Bias?
Voordat we verder gaan, is het belangrijk om het concept van inductieve bias te begrijpen. Inductieve bias verwijst naar de aanname die een model maakt over de datastructuur; tijdens de training helpt dit het model om meer gegeneraliseerd te zijn en bias te verminderen. In CNN’s omvatten inductieve biases:
- Localiteit: Kenmerken in afbeeldingen (zoals randen of texturen) zijn gelokaliseerd binnen kleine gebieden.
- Twee-dimensionale buurtstructuur: Nabijgelegen pixels zijn waarschijnlijk gerelateerd, dus filters werken op ruimtelijk aangrenzende regio’s.
- Vertalingsequivariantie: Kenmerken die worden gedetecteerd in een deel van de afbeelding, zoals een rand, behouden dezelfde betekenis als ze in een ander deel voorkomen.
Deze vooroordelen maken CNN’s zeer efficiënt voor taken met afbeeldingen, omdat ze inherent zijn ontworpen om ruimtelijke en structurele eigenschappen van afbeeldingen te benutten.
Vision Transformers (ViTs) hebben aanzienlijk minder beeldspecifieke inductieve vooroordelen dan CNN’s. In ViTs:
- Globale verwerking: Zelfaandachtlagen werken op de hele afbeelding, waardoor het model wereldwijde relaties en afhankelijkheden vastlegt zonder beperkt te worden door lokale regio’s.
- Minimale 2D-structuur: De 2D-structuur van de afbeelding wordt alleen aan het begin gebruikt (wanneer de afbeelding in patches wordt verdeeld) en tijdens fijnafstemming (om positionele embeddings aan te passen voor verschillende resoluties). In tegenstelling tot CNN’s nemen ViTs niet aan dat nabijgelegen pixels noodzakelijkerwijs gerelateerd zijn.
- Geleerde ruimtelijke relaties: Positionele embeddings in ViTs coderen geen specifieke 2D-ruimtelijke relaties bij de initialisatie. In plaats daarvan leert het model alle ruimtelijke relaties van de data tijdens de training.
Hoe Vision Transformers Werken
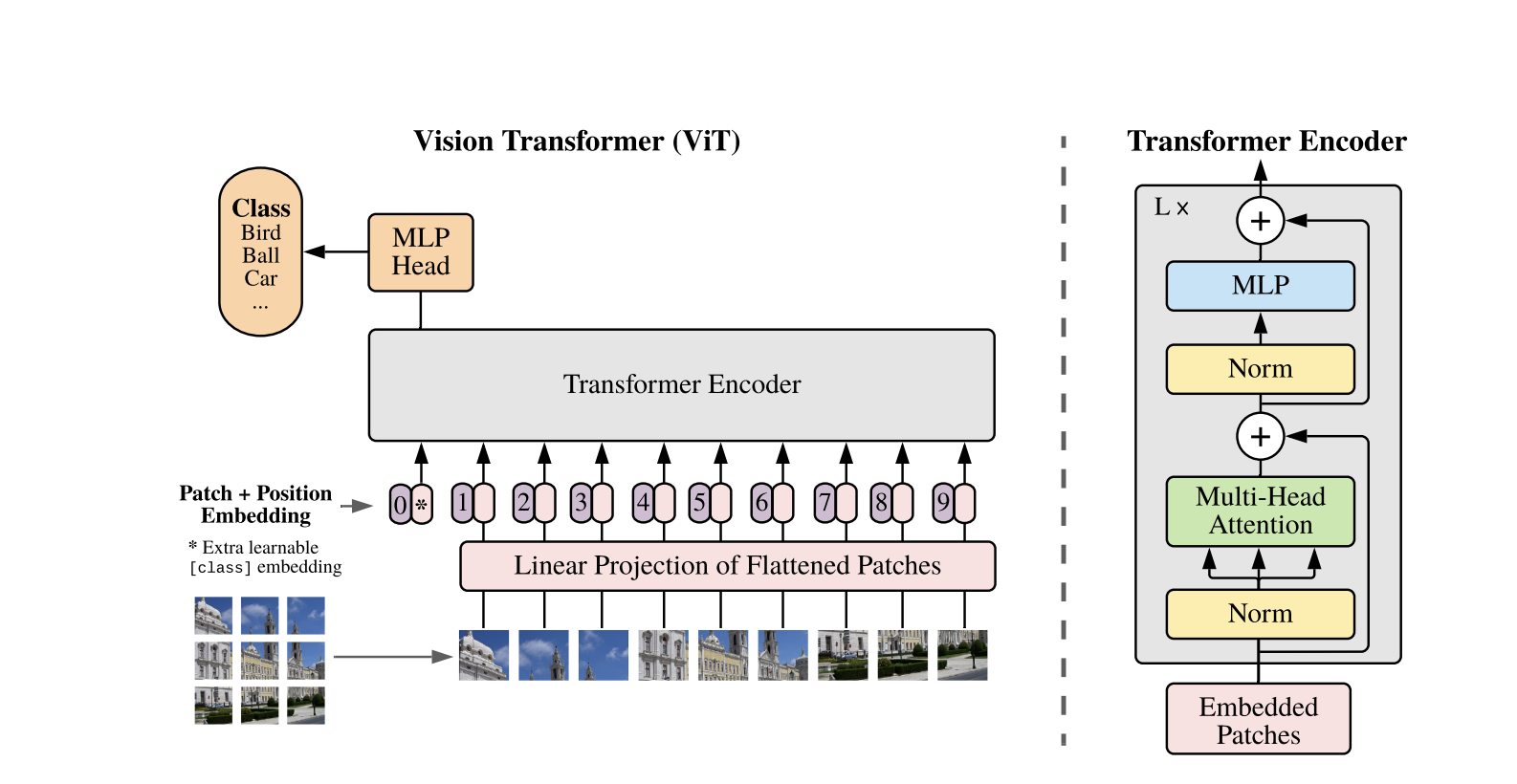
Vision Transformers gebruiken de standaard Transformer-architectuur die is ontwikkeld voor 1D-tekstsequenties. Om de 2D-afbeeldingen te verwerken, worden ze verdeeld in kleinere patches van vaste grootte, zoals P P pixels, die worden afgevlakt tot vectoren. Als de afbeelding dimensies H W heeft met C kanalen, is het totale aantal patches N = H W / P P de effectieve invoersequentielengte voor de Transformer. Deze afgevlakte patches worden vervolgens lineair geprojecteerd in een vaste dimensionale ruimte D, genaamd de patch embeddings.
Een speciale leerbare token, vergelijkbaar met de [CLS] token in BERT, wordt aan het begin van de sequentie van patch embeddings toegevoegd. Deze token leert een globale afbeeldingsrepresentatie die later wordt gebruikt voor classificatie. Daarnaast worden positionele embeddings aan de patch embeddings toegevoegd om positionele informatie te coderen, waardoor het model de ruimtelijke structuur van de afbeelding beter kan begrijpen.
De reeks van embeddings wordt door de Transformer-encoder geleid, die afwisselt tussen twee hoofdbewerkingen: Multi-Headed Self-Attention (MSA) en een feedforward-neuraal netwerk, ook wel een MLP-blok genoemd. Elke laag bevat Layer Normalization (LN) die wordt toegepast vóór deze bewerkingen en restverbindingen die nadien worden toegevoegd om training te stabiliseren. De uitvoer van de Transformer-encoder, specifiek de status van het [CLS]-token, wordt gebruikt als de representatie van de afbeelding.
Er wordt een eenvoudige kop toegevoegd aan het laatste [CLS]-token voor classificatietaken. Tijdens pretraining is deze kop een kleine multi-layer perceptron (MLP), terwijl het bij fine-tuning meestal een enkele lineaire laag is. Deze architectuur stelt ViTs in staat om effectief wereldwijde relaties tussen patches te modelleren en de volledige kracht van zelfaandacht te benutten voor beeldbegrip.
In een hybride Vision Transformer-model wordt de invoerreeks niet rechtstreeks verdeeld in ruwe beelden, maar afgeleid van functiekaarten die zijn gegenereerd door een CNN. De CNN verwerkt eerst het beeld, waarbij betekenisvolle ruimtelijke kenmerken worden geëxtraheerd, die vervolgens worden gebruikt om patches te creëren. Deze patches worden afgevlakt en geprojecteerd in een vast-dimensionale ruimte met behulp van dezelfde trainbare lineaire projectie als in standaard Vision Transformers. Een speciaal geval van deze benadering is het gebruik van patches van grootte 1×1, waarbij elke patch overeenkomt met een enkele ruimtelijke locatie in de functiekaart van de CNN.
In dit geval worden de ruimtelijke dimensies van de feature map afgevlakt, en de resulterende reeks wordt geprojecteerd in de invoerdimensie van de Transformer. Net als bij de standaard ViT worden er een classificatietoken en positionele embeddings toegevoegd om positionele informatie te behouden en om een globaal begrip van de afbeelding mogelijk te maken. Deze hybride benadering benut de sterke punten van lokale feature-extractie van CNN’s, terwijl ze worden gecombineerd met de globale modelleringscapaciteiten van Transformers.
Code Demo
Hier is de codeblok over hoe je de visie-transformers op afbeeldingen kunt gebruiken.
Het ViT-model verwerkt de afbeelding. Het bestaat uit een BERT-achtige encoder en een lineaire classificatiekop die bovenop de laatste verborgen toestand van de [CLS] token is geplaatst.
Hier is een basisimplementatie van de Vision Transformer (ViT) met PyTorch. Deze code omvat de kerncomponenten: patch embedding, positionele codering en de Transformer-encoder. Dit kan worden gebruikt voor eenvoudige classificatietaken.
Belangrijke Componenten:
- Patch Embedding: Afbeeldingen worden verdeeld in kleinere patches, afgeplat en lineair getransformeerd naar embeddings.
- Positional Encoding: Positionele informatie wordt toegevoegd aan de patch embeddings, aangezien Transformers positie-onafhankelijk zijn.
- Transformer Encoder: Past zelf-attentie en feed-forward lagen toe om relaties tussen patches te leren.
- Classificatiekop: Geeft de klassekansen weer met behulp van de CLS-token.
Je kunt dit model trainen op elke afbeeldingsdataset met een optimizer zoals Adam en een verliesfunctie zoals kruisentropie. Voor betere prestaties, overweeg voortraining op een grote dataset voordat je fijnafstemt.
Populaire vervolgwerken
-
DeiT (Data-efficiënte Beeldtransformatoren) van Facebook AI: Dit zijn visietransformatoren die efficiënt zijn getraind met kennisdistillatie. DeiT biedt vier varianten: deit-tiny, deit-small, en twee deit-base modellen. Gebruik
DeiTImageProcessorom afbeeldingen voor te bereiden. -
BEiT (BERT vooraf trainen van beeldtransformatoren) door Microsoft Research: Geïnspireerd door BERT maakt BEiT gebruik van zelfgestuurde gemaskerde beeldmodellering en presteert beter dan begeleide ViTs. Het vertrouwt op VQ-VAE voor training.
-
DINO (Zelfgestuurde Vision Transformer Training) door Facebook AI: DINO-getrainde ViTs kunnen objecten segmenteren zonder expliciete training. Checkpoints zijn online beschikbaar.
-
MAE (Masked Autoencoders) door Facebook pre-traint ViTs door het reconstrueren van gemaskeerde patches (75%). Wanneer fijn afgestemd, overtreft deze eenvoudige methode gesuperviseerd vooraf trainen.
Conclusie
Samenvattend zijn ViTs een uitstekend alternatief voor CNN’s omdat ze transformers toepassen op beeldherkenning, inductieve bias minimaliseren en afbeeldingen behandelen als sequentiepatches. Deze eenvoudige maar schaalbare aanpak heeft state-of-the-art prestaties aangetoond op vele beeldclassificatie-benchmarks, vooral wanneer gecombineerd met vooraf trainen op grote datasets. Er blijven echter potentiële uitdagingen bestaan, zoals het uitbreiden van ViTs naar taken zoals objectdetectie en segmentatie, het verder verbeteren van zelf-supervised vooraf trainingsmethoden, en het verkennen van het potentieel van het schalen van ViTs voor nog betere prestaties.
Aanvullende bronnen
Source:
https://www.digitalocean.com/community/tutorials/vision-transformer-for-computer-vision