













En los últimos años, los transformadores han revolucionado el dominio de NLP en el aprendizaje automático. Modelos como GPT y BERT han establecido nuevos estándares en la comprensión y generación del lenguaje humano. Ahora, el mismo principio se está aplicando al dominio de la visión por computadora.
Un desarrollo reciente en el campo de la visión por computadora son los transformadores de visión o ViTs. Como se detalla en el artículo “Una imagen vale 16×16 palabras: Transformadores para el reconocimiento de imágenes a escala“, los ViTs y los modelos basados en transformadores están diseñados para reemplazar las redes neuronales convolucionales (CNNs).
Los Transformadores de Visión son un enfoque innovador para resolver problemas en la visión por computadora. En lugar de depender de las redes neuronales convolucionales tradicionales (CNNs), que han sido la base de las tareas relacionadas con imágenes durante décadas, los ViTs utilizan la arquitectura del transformador para procesar imágenes. Tratan los parches de imágenes como palabras en una oración, lo que permite al modelo aprender las relaciones entre estos parches, al igual que aprende el contexto en un párrafo de texto.
A diferencia de las CNN, los ViTs dividen las imágenes de entrada en parches, las convierten en vectores y reducen su dimensionalidad mediante multiplicación de matrices. Luego, un codificador transformador procesa estos vectores como incrustaciones de tokens. En este artículo, exploraremos los transformadores de visión y sus principales diferencias con las redes neuronales convolucionales. Lo que los hace particularmente interesantes es su capacidad para entender patrones globales en una imagen, algo con lo que las CNN pueden tener dificultades.
Prerrequisitos
- Conceptos básicos de redes neuronales: Comprensión de cómo las redes neuronales procesan datos.
- Redes Neuronales Convolucionales (CNNs): Familiaridad con las CNN y su papel en visión por computadora.
- Arquitectura de Transformadores: Conocimiento de los transformadores, en particular su uso en PNL.
- Procesamiento de Imágenes: Comprensión de conceptos básicos como representación de imágenes, canales y matrices de píxeles.
- Mecanismo de Atención: Comprensión de la autoatención y su capacidad para modelar relaciones entre entradas.
¿Qué son los transformadores de visión?
Los transformadores de visión utilizan el concepto de atención y transformadores para procesar imágenes; esto es similar a los transformadores en un contexto de procesamiento de lenguaje natural (NLP). Sin embargo, en lugar de utilizar tokens, la imagen se divide en parches y se proporciona como una secuencia de incrustaciones lineales. Estos parches se tratan de la misma manera que se tratan los tokens o palabras en NLP.
En lugar de mirar toda la imagen simultáneamente, un ViT corta la imagen en pequeñas piezas como un rompecabezas. Cada pieza se convierte en una lista de números (un vector) que describe sus características, y luego el modelo observa todas las piezas y determina cómo se relacionan entre sí utilizando un Mecanismo de transformador.
A diferencia de las CNN, los ViTs trabajan aplicando filtros o núcleos específicos sobre una imagen para detectar características específicas, como patrones de bordes. Este es el proceso de convolución, que es muy similar a un escáner de impresora que escanea una imagen. Estos filtros se deslizan a través de toda la imagen y destacan características significativas. La red luego apila múltiples capas de estos filtros, identificando gradualmente patrones más complejos.
Con las CNN, las capas de agrupamiento reducen el tamaño de los mapas de características. Estas capas analizan las características extraídas para hacer predicciones útiles para el reconocimiento de imágenes, detección de objetos, etc. Sin embargo, las CNN tienen un campo receptivo fijo, limitando así la capacidad de modelar dependencias de largo alcance.
¿Cómo ven las CNN las imágenes?
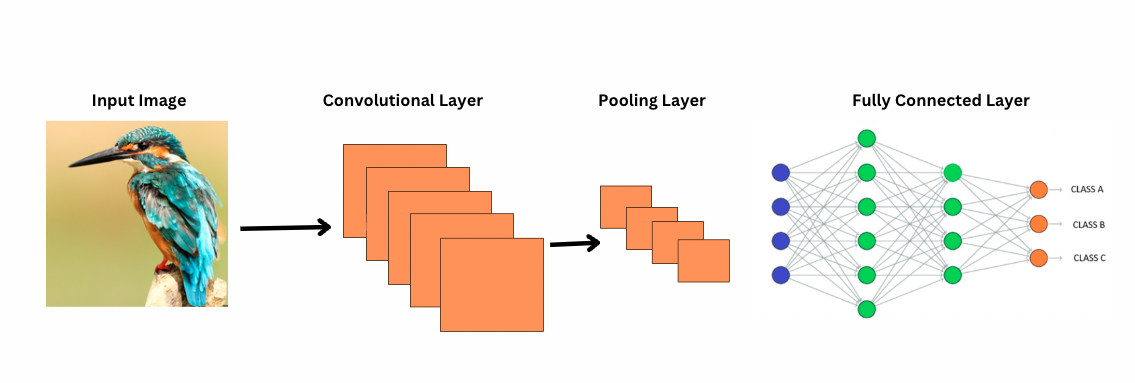
ViTs, a pesar de tener más parámetros, utilizan mecanismos de autoatención para una mejor representación de características y reducir la necesidad de capas más profundas. Las CNNs requieren una arquitectura significativamente más profunda para lograr una potencia representacional similar, lo que conlleva a un mayor costo computacional.
Además, las CNNs no pueden capturar patrones de imagen a nivel global porque sus filtros se enfocan en regiones locales de una imagen. Para entender la imagen completa o las relaciones distantes, las CNNs dependen de apilar muchas capas y pooling, expandiendo el campo de visión. Sin embargo, este proceso puede perder información global a medida que se agregan detalles paso a paso.
Por otro lado, los ViTs dividen la imagen en parches que se tratan como tokens de entrada individuales. Utilizando autoatención, los ViTs comparan todos los parches simultáneamente y aprenden cómo se relacionan. Esto les permite capturar patrones y dependencias en toda la imagen sin construirlos capa por capa.
¿Qué es el sesgo inductivo?
Antes de continuar, es importante entender el concepto de sesgo inductivo. El sesgo inductivo se refiere a la suposición que un modelo hace sobre la estructura de los datos; durante el entrenamiento, esto ayuda al modelo a ser más generalizado y reducir el sesgo. En las CNNs, los sesgos inductivos incluyen:
- Localidad: Las características en las imágenes (como bordes o texturas) están localizadas dentro de regiones pequeñas.
- La estructura de vecindad bidimensional: Los píxeles cercanos tienen más probabilidades de estar relacionados, por lo que los filtros operan en regiones espacialmente adyacentes.
- Equivarancia de traducción: Las características detectadas en una parte de la imagen, como un borde, mantienen el mismo significado si aparecen en otra parte.
Estos sesgos hacen que las CNN sean altamente eficientes para tareas de imágenes, ya que están inherentemente diseñadas para explotar las propiedades espaciales y estructurales de las imágenes.
Los Transformadores de Visión (ViTs) tienen significativamente menos sesgos inductivos específicos de imágenes que las CNN. En los ViTs:
- Procesamiento global: Las capas de autoatención operan en toda la imagen, lo que hace que el modelo capture relaciones y dependencias globales sin estar restringido por regiones locales.
- Estructura 2D mínima: La estructura 2D de la imagen se utiliza solo al principio (cuando la imagen se divide en parches) y durante el ajuste fino (para ajustar los incrustamientos posicionales para diferentes resoluciones). A diferencia de las CNN, los ViTs no asumen que los píxeles cercanos están necesariamente relacionados.
- Relaciones espaciales aprendidas: Los incrustamientos posicionales en ViTs no codifican relaciones espaciales 2D específicas en la inicialización. En cambio, el modelo aprende todas las relaciones espaciales de los datos durante el entrenamiento.
Cómo funcionan los Transformadores de Visión
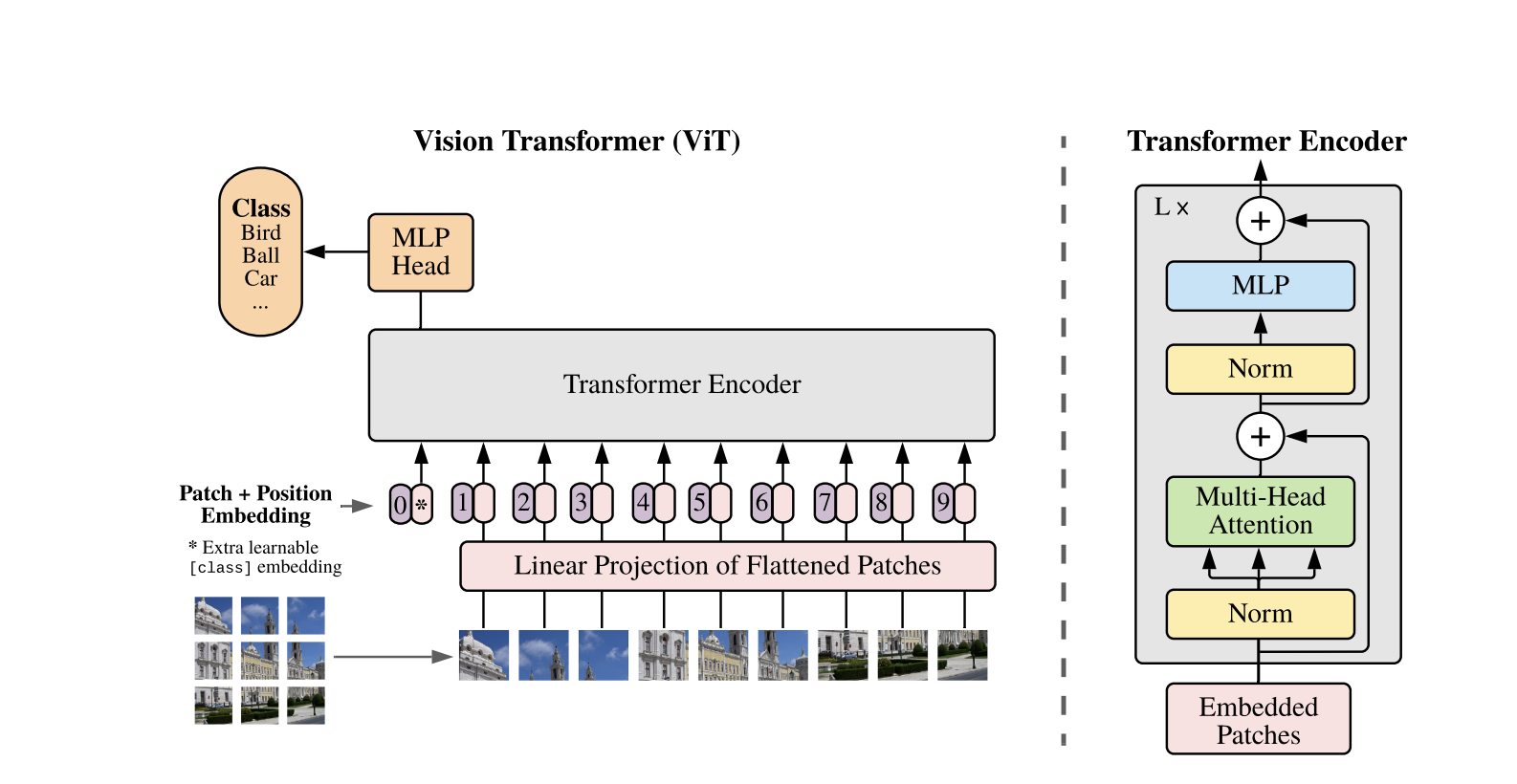
Los Vision Transformers utilizan la arquitectura estándar de Transformer desarrollada para secuencias de texto 1D. Para procesar las imágenes 2D, se dividen en parches más pequeños de tamaño fijo, como P x P píxeles, que se aplanan en vectores. Si la imagen tiene dimensiones H x W con C canales, el número total de parches es N = H x W / P x P, que es la longitud efectiva de la secuencia de entrada para el Transformer. Estos parches aplanados se proyectan linealmente en un espacio de dimensión fija D, llamado incrustaciones de parches.
Se añade un token especial aprendible, similar al token [CLS] en BERT, al principio de la secuencia de incrustaciones de parches. Este token aprende una representación global de la imagen que se utiliza posteriormente para la clasificación. Además, se añaden incrustaciones posicionales a las incrustaciones de parches para codificar información posicional, ayudando al modelo a comprender la estructura espacial de la imagen.
La secuencia de incrustaciones se pasa a través del codificador Transformer, que alterna entre dos operaciones principales: Autoatención Multicabezal (MSA) y una red neuronal feedforward, también llamada bloque MLP. Cada capa incluye Normalización de Capa (LN) aplicada antes de estas operaciones y conexiones residuales añadidas posteriormente para estabilizar el entrenamiento. La salida del codificador Transformer, específicamente el estado del token [CLS], se utiliza como representación de la imagen.
Se añade una cabeza simple al token [CLS] final para tareas de clasificación. Durante el preentrenamiento, esta cabeza es un pequeño perceptrón multicapa (MLP), mientras que en el ajuste fino, suele ser una sola capa lineal. Esta arquitectura permite que los ViTs modelen eficazmente las relaciones globales entre parches y utilicen todo el poder de la autoatención para la comprensión de imágenes.
En un modelo híbrido de Vision Transformer, en lugar de dividir directamente las imágenes crudas en parches, la secuencia de entrada se deriva de mapas de características generados por una CNN. La CNN procesa primero la imagen, extrayendo características espaciales significativas, que luego se utilizan para crear parches. Estos parches se aplanan y proyectan en un espacio dimensional fijo mediante la misma proyección lineal entrenable que en los Vision Transformers estándar. Un caso especial de este enfoque es el uso de parches de tamaño 1×1, donde cada parche corresponde a una ubicación espacial única en el mapa de características de la CNN.
En este caso, las dimensiones espaciales del mapa de características se aplanan, y la secuencia resultante se proyecta en la dimensión de entrada del Transformador. Al igual que con el ViT estándar, se agregan un token de clasificación y codificaciones posicionales para retener la información posicional y permitir la comprensión global de la imagen. Este enfoque híbrido aprovecha las fortalezas de extracción de características locales de las CNNs mientras las combina con las capacidades de modelado global de los Transformadores.
Demo de Código
Aquí está el bloque de código sobre cómo usar los transformadores de visión en imágenes.
El modelo ViT procesa la imagen. Consta de un codificador similar a BERT y una cabeza de clasificación lineal ubicada encima del estado oculto final del token [CLS].
Aquí hay una implementación básica del Transformador de Visión (ViT) usando PyTorch. Este código incluye los componentes principales: incrustación de parches, codificación posicional y el codificador del Transformador. Esto se puede utilizar para tareas de clasificación simple.
Componentes clave:
- Incrustación de parches: Las imágenes se dividen en parches más pequeños, se aplanan y se transforman linealmente en incrustaciones.
- Codificación posicional: Se agrega información posicional a las incrustaciones de parches, ya que los Transformers son ajenos a la posición.
- Codificador Transformer: Aplica autoatención y capas de alimentación directa para aprender relaciones entre los parches.
- Encabezado de Clasificación: Produce las probabilidades de clase utilizando el token CLS.
Puedes entrenar este modelo en cualquier conjunto de datos de imágenes utilizando un optimizador como Adam y una función de pérdida como la entropía cruzada. Para obtener un mejor rendimiento, considera preentrenar en un conjunto de datos grande antes de ajustar finamente.
Trabajos de Seguimiento Populares
-
DeiT (Transformadores de Imagen Eficientes en Datos) por Facebook AI: Estos son transformadores de visión entrenados eficientemente con destilación de conocimiento. DeiT ofrece cuatro variantes: deit-tiny, deit-small, y dos modelos deit-base. Usa
DeiTImageProcessorpara preparar imágenes. -
BEiT (BERT pre-entrenamiento de Image Transformers) por Microsoft Research: Inspirado por BERT, BEiT utiliza modelado de imágenes enmascaradas auto-supervisado y supera a los ViTs supervisados. Se basa en VQ-VAE para el entrenamiento.
-
DINO (Entrenamiento de Vision Transformer Auto-supervisado) por Facebook AI: Los ViTs entrenados con DINO pueden segmentar objetos sin entrenamiento explícito. Los puntos de control están disponibles en línea.
-
MAE (Masked Autoencoders) de Facebook preentrena ViTs reconstruyendo parches enmascarados (75%). Cuando se ajusta finamente, este método simple supera el preentrenamiento supervisado.
Conclusión
En conclusión, los ViTs son una excelente alternativa para las CNN, ya que aplican transformadores al reconocimiento de imágenes, minimizan el sesgo inductivo y tratan las imágenes como parches de secuencia. Este enfoque simple pero escalable ha demostrado un rendimiento de vanguardia en muchos benchmarks de clasificación de imágenes, especialmente cuando se combina con el preentrenamiento en conjuntos de datos grandes. Sin embargo, aún existen desafíos potenciales, que incluyen extender los ViTs a tareas como la detección y segmentación de objetos, mejorar aún más los métodos de preentrenamiento auto-supervisados y explorar el potencial de escalar los ViTs para lograr un rendimiento aún mejor.
Recursos Adicionales
Source:
https://www.digitalocean.com/community/tutorials/vision-transformer-for-computer-vision