













介紹
在YOLO Vision 2024活動中,Ultralytics宣布YOLO系列的新成員YOLOv11。本文將提供新模型的概览,以及如何使用YOLOv11進行推理的指示,並比較模型與其前一代的主要進步和亮點。YOLOv11模型的設計旨在為诸如目標檢測、圖像分割、圖像分類、姿态估計和實時目標跟蹤等任務提供快速、準確且易於使用。
新的最前沿(SOTA)模型相比以前的YOLO模型實現了更快的推理速度和 improved accuracy。在我們開始之前,讓我們來看一下Ultralytics提供的基准結果。在基准圖中,YOLOv11模型的性能已經與YOLOv5、v6、v7、v8、v9和v10進行了比較。
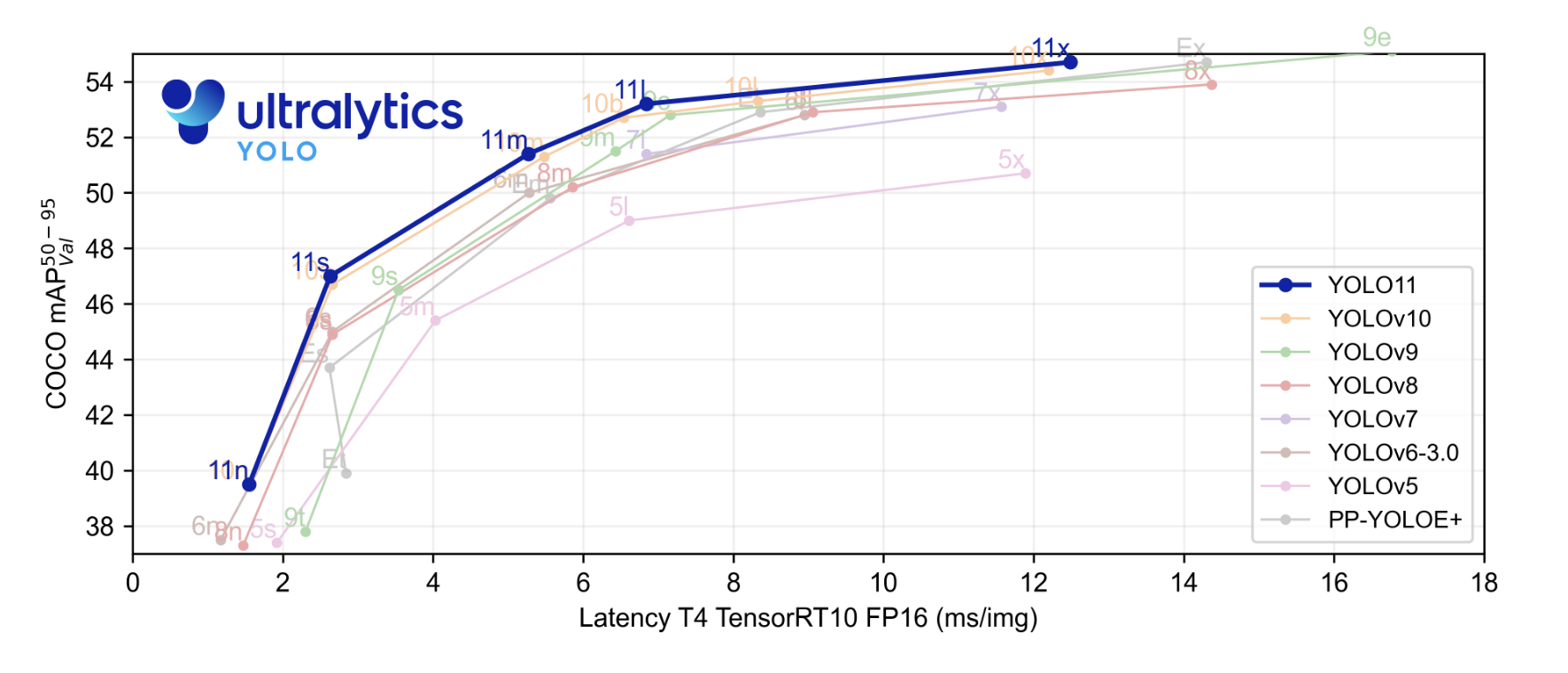
highlighted blue plot 是 YOLOv11 的性能表现,從图中可见,它在 COCO 數據集上的 平均平均精度 已經超越了大部分的 YOLO 系列模型,而且在 X 軸上的推理速度上也表現出色。
YOLOv11 支援的任務
- 目標检测:- 通過在圖像或视频中畫出邊界框並提供自信心分數來定位圖像中的目標。這對於无人驾驶汽車、監控攝像頭或收費站的應用來說非常有用。
- 实例分割:- 在圖像中識別和分割目標或個體。這對於醫學成像、製造等應用非常有益。
- 姿态估計:- 在圖像或視頻幀中識別關鍵點以監控身體动作或手勢,這對於虛擬現實、舞蹈訓練和物理治療等應用非常有用。
- 定向目標檢測 (OBB):- 檢測具有定向角度的目標,使傾斜或旋轉项目的精確定位更加準確。這個特性對於无人驾驶汽車、工業 Inspection 和分析無人機或衛星影像等應用非常有益。
| Model | Tasks |
|---|---|
| YOLO11 | 檢測 (COCO) |
| YOLO11-seg | 分割 (COCO) |
| YOLO11-pose | 姿态/關鍵點 (COCO) |
| YOLO11-obb | 目標侦測 (DOTAv1) |
| YOLO11-cls | 分類 (ImageNet) |
YOLOv11 提供了在 COCO 數據集上預訓練的 Detect、Segment 和 Pose 模型,以及在地 ImageNet 數據集上預訓練的 Classify 模型。對於所有 Detect、Segment 和 Pose 模型,都可用 Track 模式。有關模型的詳細信息及其不同版本,請參考官方 GitHub 倉庫。我們在我們的資源區間包括了直接的鏈接,以方便使用。

的先決條件
以下是運行 YOLO 模型的先決條件:
- Python 環境:安装 Python 3.8 或更高版本。
- CUDA & cuDNN:CUDA 兼容的 NVIDIA GPU,並已安裝 CUDA 和 cuDNN,以加快訓練和推理速度。
- PyTorch:根據您的 CUDA 版本安裝 PyTorch。
- YOLO 框架:從 Ultralytics 安裝特定版本的 YOLO 包。
- 數據集:YOLO 格式的標記數據集(圖像和注釋文件)。
- 硬件要求:至少 16 GB RAM 和具有 4+ GB VRAM 的 GPU,以確保平滑的訓練和推理。
新模型的重要特點
YOLOv11帶來了幾個改善,使其成為電腦視覺任務的強佳選擇。它具有更出色的骨干和頸部設計,有助於更準確地侦測對象並輕鬆處理複雜任務。該模型经过優化,以提供更快的處理時間,同時仍然保持精度與性能之間的良好平衡。即使比YOLOv8m少22%的參數,這個輕量型模型仍達到更高的精度,使其既高效又有效。YOLOv11的推理時間也比YOLOv10快2%,使其具有高度適應性,能夠在邊緣設備、雲系統和NVIDIA GPU等各種平台上良好工作。此外,它還支持廣泛的任務,包括对象侦測、圖像分類、姿态估計等。
YOLOv11設計用以輕鬆集成到各種系統和平台中。建立在YOLOv8的支援之上,它在不同的環境中對於訓練、測試和部署都能良好運作。無論您使用NVIDIA GPU、邊緣設備還是雲平台,YOLOv11都能順暢地融入您的 workflow。
這些特點使YOLOv11能夠適應不同行業。
YOLOv11展示
當 YOLOv11 在 DigitalOcean 的 GPU Droplet 上運行時,推理速度可達每張圖 5 至 6 毫秒,使其成為要求快速有效處理的實時應用程序的理想選擇。
我們將從安裝 ultralytics 包或更新包開始。
用 Python 或使用 CLI 命令來訓練 YOLOv11 模型的目標检测都可以完成。
我們提供了用於在影片中检测物體的模型代碼。
接下來,我們將嘗試用模型在圖像中檢測物體。
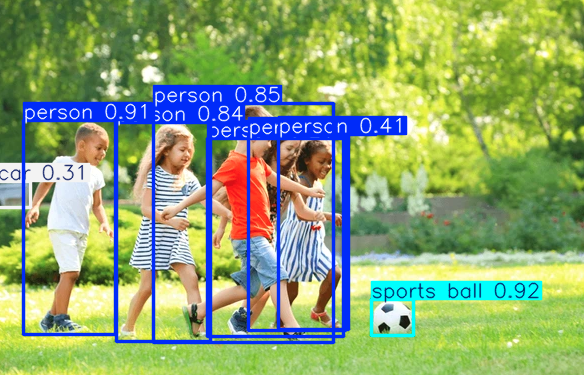
要使用模型進行分割,我們需要下載 YOLO11,因為直接嘗試模型可能會導致錯誤。

同樣,對於姿态估計和分類任務,我們需要下載 YOLO11 模型,然後在圖像上嘗試模型。


現在建議使用高性能 GPU 來運行或訓練 YOLOv11,否則訓練或推理可能會變得很慢且效率低下。當涉及到運行或訓練 YOLOv11 時,選擇 GPU 而不是 CPU 可以顯著提高性能和效率。YOLOv11 凭借其優化的特徵提取和提高的準確性,需要极高的計算能力,特別是對於在大型數據集上進行訓練。GPU 特地設計用於並行處理,使它們能夠比 CPU 快得多地處理深層學習所需的複雜矩陣運算。DigitalOcean GPU Droplets 經過優化以支援 AI/ML 工作負載,提供访问像 H100 這樣 powerful GPUs 的权限,這款 GPU 是特別設計用於進階性能和处理重 computational 工作的。
結論
我們看到模型在圖像和視頻方面可以做些酷的事情。YOLOv11是一個強大且多功能的電腦視覺任務模型。它改進的特性、高速度和準確性使其比起前身有顯著的升級。
總結來說,YOLOv11在目標檢測和電腦視覺上是巨大的進步。其更好的架構設計、更快的速度和改進的準確性,使其適合各種用途—無論是在小型設備上的實時檢測或在雲端的更詳細分析。它與现有系統顺畅工作的能力意味著企業可以輕鬆將其整合到日常操作中,無論是在農業、安保還是機器人技術。YOLOv11的靈活性和性能的結合使其成為解決電腦視覺挑戰的強大工具。
然而,這只是教程的第一部分,在第二部分中,我們將學習如何针对自定义数据集对模型进行微调和训练以进行目标检测。
參考资料
Source:
https://www.digitalocean.com/community/tutorials/what-is-new-with-yolo