













Introducción
En el evento YOLO Vision 2024, Ultralytics anunció un miembro nuevo de la serie YOLO llamado YOLOv11. Este artículo proporcionará una visión general del nuevo modelo, instrucciones sobre cómo ejecutar inferencia usando YOLOv11, y los avances clave y destacados del modelo en comparación con su predecesor. El modelo YOLOv11 está diseñado para ser rápido, preciso y fácil de usar para tareas como la detección de objetos, la segmentación de imágenes, la clasificación de imágenes, la estimación de la postura y la detección de objetos en tiempo real.
El nuevo modelo de estado del arte (SOTA) ha alcanzado una velocidad de inferencia más rápida y una precisión mejorada en comparación con los modelos YOLO anteriores. Antes de comenzar, vamos a echar un vistazo a los resultados de referencia proporcionados por Ultralytics. En el gráfico de referencia, el modelo YOLOv11 ha sido comparado con YOLOv5, v6, v7, v8, v9, y v10.
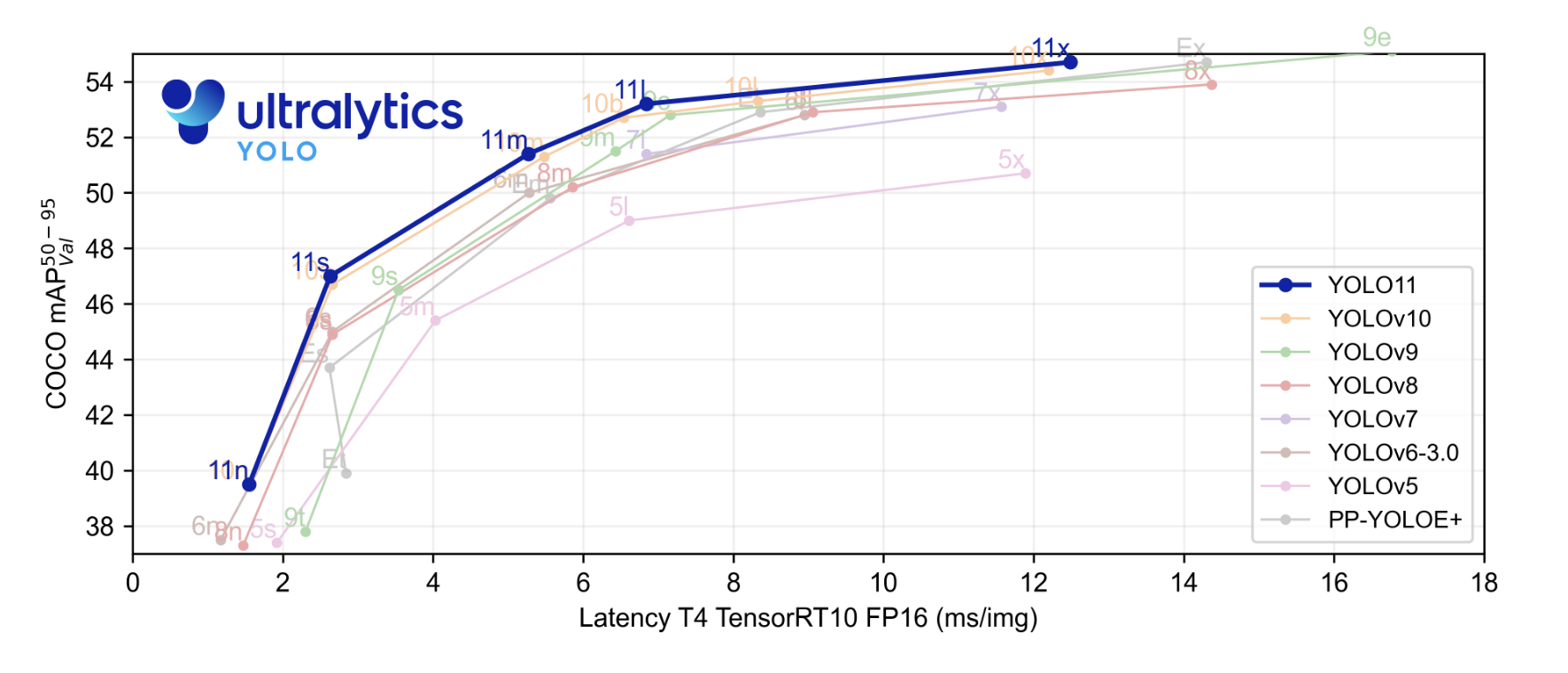
El gráfico resaltado en azul es el rendimiento de YOLOv11 y como podemos ver, ha superado prácticamente a todos los modelos YOLO o series en precisión media promedio en el conjunto de datos COCO y en la velocidad de inferencia representada en el eje x.
Tareas soportadas por YOLOv11
- Detección de objetos:- Localizar objetos en una imagen o videos dibujando cajas de bounding junto con las puntuaciones de confianza. Útil para aplicaciones como conducción autónoma, cámaras de vigilancia o casetas de peaje de tráfico.
- Segmentación de instancias:- Identificar y segmentar objetos o individuos en una imagen. Útil para la imagen médica, la fabricación y más.
- Estimación de posturas:- Identificar puntos clave en una imagen o frame de vídeo para monitorear movimientos corporales o gestos, lo que resulta útil para aplicaciones como realidad virtual, entrenamiento de baile y terapia física.
- Detección de objetos orientados (OBB):- Detección de objetos con un ángulo de orientación, permitiendo una localización más precisa de elementos inclinados o rotados. Esta característica es particularmente útil para aplicaciones como conducción autónoma, inspección industrial y análisis de imágenes de drones o satélites.
| Model | Tasks |
|---|---|
| YOLO11 | Detección (COCO) |
| YOLO11-seg | Segmentación (COCO) |
| YOLO11-pose | Pose/Puntos clave (COCO) |
| YOLO11-obb | Detección Orientada a Objetos (DOTAv1) |
| YOLO11-cls | Clasificación (ImageNet) |
YOLOv11 proporciona modelos preentrenados para Detectar, Segmentar y Poner en Pose sobre el conjunto de datos COCO, así como modelos preentrenados para Clasificar sobre el conjunto de datos ImageNet. También está disponible el modo de seguimiento para todos los modelos de Detección, Segmentación y Pose. Para obtener más información sobre los detalles del modelo y sus diferentes versiones, por favor, refiérase al repositorio oficial de GitHub. Hemos incluido un enlace directo en nuestra sección de recursos para su comodidad.

Prerequisitos
Los prerequisitos para ejecutar los modelos YOLO son:
- Entorno de Python: Instale Python 3.8 o posterior.
- CUDA y cuDNN: Un GPU compatible con CUDA (NVIDIA) con CUDA y cuDNN instalados para un entrenamiento y inferción más rápidos.
- PyTorch: Instale PyTorch compatible con su versión de CUDA.
- Marco de YOLO: Instale el paquete de la versión específica de YOLO de Ultralytics.
- Conjunto de Datos: Conjunto de datos etiquetado en formato YOLO (imágenes y archivos de anotación).
- Requerimientos de Hardware: Al menos 16 GB de RAM y una GPU con 4+ GB de VRAM para un entrenamiento y inferción suaves.
Resaltos de características clave del nuevo modelo
YOLOv11 trae mejoras que lo convierten en una opción fuerte para tareas de computación visual. Cuenta con un mejor diseño de cuerpo y cuello, lo que le ayuda a detectar objetos con mayor precisión y manejar tareas complejas con facilidad. El modelo está optimizado para velocidad, ofreciendo tiempos de procesamiento más rápidos mientras mantiene un buen equilibrio entre precisión y rendimiento. Incluso con un 22% menos de parámetros que YOLOv8m, este modelo ligero alcanza una mayor precisión, lo que lo hace eficiente y efectivo. YOLOv11 también tiene un tiempo de inferción 2% más rápido que el de YOLOv10, lo que lo hace altamente adaptable, funcionando bien en varias plataformas como dispositivos de borde, sistemas en la nube y GPUs de NVIDIA. Además, apoya una amplia gama de tareas, incluyendo detección de objetos, clasificación de imágenes, estimación de posturas y más.
YOLOv11 está diseñado para integrarse fácilmente con varios sistemas y plataformas. Basándonos en la compatibilidad de YOLOv8, funciona bien en diferentes entornos para entrenamiento, pruebas y implementación. Sea que uses GPUs de NVIDIA, dispositivos de borde o plataformas en la nube, YOLOv11 se adapta sin problemas a tu flujo de trabajo.
Estas características hacen de YOLOv11 adaptable para diferentes industrias.
Demo de YOLOv11
Cuando se ejecuta YOLOv11 en una Droplet GPU de DigitalOcean, la velocidad de inferción alcanza los 5 a 6 ms por imagen, lo que lo hace una opción ideal para aplicaciones en tiempo real que requieren un procesamiento rápido y eficiente.
Vamos a empezar instalando el paquete ultralytics o actualizando el paquete.
El entrenamiento del modelo YOLOv11 para detección de objetos puede realizarse tanto en Python como utilizando órdenes de línea de comandos (CLI).
hemos proporcionado el código para utilizar el modelo para detectar objetos en un video.
A continuación, intentaremos utilizar el modelo para detectar objetos en una imagen.
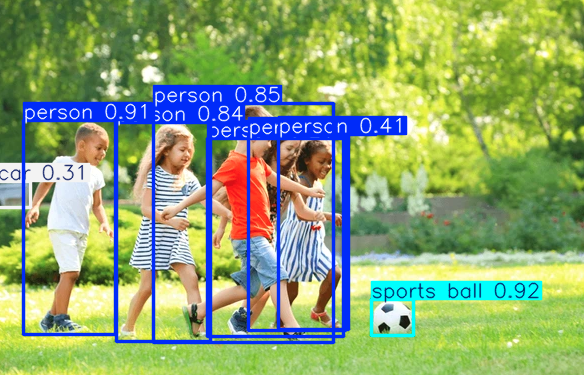
Para utilizar el modelo para la segmentación, necesitamos descargar el modelo YOLO11 ya que intentar utilizar el modelo directamente puede arrojar un error.

De manera similar, para tareas de estimación de posturas y clasificación, necesitamos descargar el modelo YOLO11 y luego intentar el modelo en una imagen.


Ahora es recomendable utilizar una GPU de alto rendimiento para ejecutar o entrenar YOLOv11, de lo contrario, el entrenamiento o la inferencia podrían ser lentos y ineficientes. Cuando se trata de ejecutar o entrenar YOLOv11, elegir GPU en lugar de CPU puede mejorar significativamente el rendimiento y la eficiencia. YOLOv11, con su mejoramiento en la extracción de características y su mayor precisión, exige un alto poder computacional, especialmente para el entrenamiento en bases de datos grandes. Las GPUs están diseñadas específicamente para procesamiento en paralelo, lo que les permite manejar las operaciones de matrices complejas necesarias para el aprendizaje profundo mucho más rápido que las CPUs. Droplets GPU de DigitalOcean están optimizados para cargas de trabajo de AI/ML, ofreciendo acceso a poderosas GPUs como la H100, diseñadas especialmente para un rendimiento avanzado y manejo de computación pesada.
Pensamientos Concluyentes
Vimos algunas cosas interesantes que el modelo puede hacer con imágenes y videos. YOLOv11 es un modelo poderoso y versátil para tareas de computación visual. Sus mejoras en características, alta velocidad y precisión lo hacen una importante actualización con respecto a sus predecesores.
En conclusión, YOLOv11 representa un gran avance en detección de objetos y computación visual. Con su mejor diseño arquitectónico, velocidades más rápidas y precisión mejorada, es ideal para diversos usos, ya sea detección en tiempo real en dispositivos pequeños o análisis más detallado en la nube. Su capacidad para funcionar sin problemas con sistemas existentes significa que las empresas pueden integrar fácilmente sus operaciones diarias, ya sea en agricultura, seguridad o robótica. La combinación de flexibilidad y rendimiento de YOLOv11 lo hace una herramienta potente para cualquier persona que enfrenta desafíos de computación visual.
Sin embargo, este es el capítulo 1 del tutorial, y en el capítulo 2, aprenderemos cómo ajustar y entrenar el modelo para la detección de objetos en un conjunto de datos personalizado.
Referencias
- Imágenes utilizadas fuentes
- Ultralytics YOLO11
- Entrenamiento de modelos de Ultralytics
- Github oficial de YOLOv11
Source:
https://www.digitalocean.com/community/tutorials/what-is-new-with-yolo