













简介
在YOLO Vision 2024活动上,Ultralytics宣布了名为YOLOv11的新一代YOLO系列模型。本文将概述新模型的特点,提供使用YOLOv11进行推理的指导,并比较该模型与其前身的关键进步和亮点。YOLOv11模型旨在为对象检测、图像分割、图像分类、姿态估计和实时对象追踪等任务提供快速、准确且易于使用的能力。
这个最新的先进模型(SOTA)在推理速度和准确性上超过了之前的YOLO模型。在开始之前,让我们看一下Ultralytics提供的基准测试结果。在基准测试图表中,YOLOv11模型与YOLOv5、v6、v7、v8、v9和v10进行了比较。
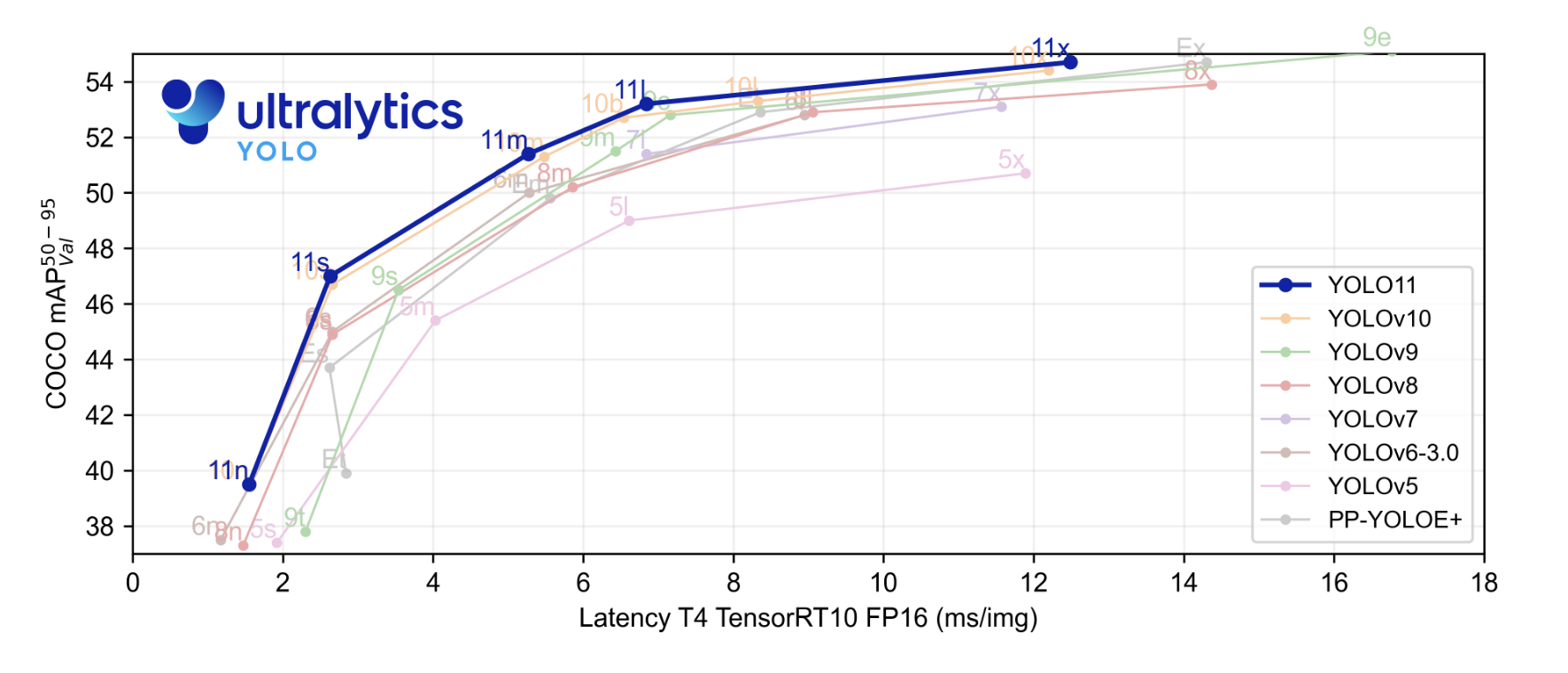
高亮显示的蓝色部分是YOLOv11的性能表现,从图中我们可以看出,它在COCO数据集上的平均精度已经超过了几乎所有YOLO系列模型,并且在x轴上的推理速度上也表现出色。
YOLOv11支持的任务
- 目标检测:通过在图像或视频中绘制边界框并附上置信度得分来定位对象。这对于自动驾驶、监控摄像头或收费亭等应用非常有益。
- 实例分割:识别并分割图像中的对象或个体。这对于医学成像、制造业等应用非常有用。
- 姿态估计:识别图像或视频帧中的关键点以监控身体动作或手势,这对于虚拟现实、舞蹈训练和物理治疗等应用非常有用。
- 定向对象检测(OBB):检测具有倾斜或旋转角度的对象,使倾斜或旋转物品的定位更加精确。这一功能对于自动驾驶、工业检测以及无人机或卫星图像分析等应用尤为重要。
| Model | Tasks |
|---|---|
| YOLO11 | 检测(COCO) |
| YOLO11-seg | 分割(COCO) |
| YOLO11-pose | 姿态/关键点(COCO) |
| YOLO11-obb | 目标检测(DOTAv1) |
| YOLO11-cls | 分类(ImageNet) |
YOLOv11提供了在COCO数据集上预训练的Detect、Segment和Pose模型,以及在ImageNet数据集上预训练的Classify模型。还为所有Detect、Segment和Pose模型提供了跟踪模式。有关模型详细信息及其不同版本的信息,请参考官方GitHub仓库。为了方便起见,我们在资源部分提供了直达链接。

先决条件
运行YOLO模型的先决条件如下:
- Python环境:安装Python 3.8或更高版本。
- CUDA & cuDNN:配备CUDA和cuDNN的NVIDIA CUDA兼容GPU,以实现更快的训练和推理。
- PyTorch:安装与您的CUDA版本兼容的PyTorch。
- YOLO框架:从Ultralytics安装特定版本的YOLO包。
- 数据集:YOLO格式的标注数据集(图像和注释文件)。
- 硬件要求:至少16GB RAM和4+ GB VRAM的GPU,以确保平滑的训练和推理。
新模型关键特性亮点
YOLOv11带来了多项改进,使其成为计算机视觉任务的强大选择。它具有更优的主干网络和颈部设计,有助于更准确地检测对象并轻松处理复杂任务。该模型针对速度进行了优化,提供更快的处理时间,同时保持了准确性和性能之间的良好平衡。即使参数比YOLOv8m少22%,这个轻量级模型也实现了更高的准确度,使其既高效又有效。YOLOv11的推理时间比YOLOv10快2%,使其高度适应各种平台,如边缘设备、云计算系统和NVIDIA GPU。此外,它支持广泛的任务,包括目标检测、图像分类、姿态估计等。
YOLOv11旨在轻松集成到各种系统和平台中。在YOLOv8的支持基础上,它可以在不同的环境中进行训练、测试和部署。无论您使用NVIDIA GPU、边缘设备还是云计算平台,YOLOv11都能顺利适应您的工作流程。
这些特性使YOLOv11适应不同行业的需求。
YOLOv11演示
当YOLOv11在DigitalOcean的GPU Droplet上运行时,推理速度可以达到每张图像5到6毫秒,使其成为实时应用中快速高效处理的理想选择。
我们将首先安装ultralytics包或升级包。
无论是使用Python还是CLI命令,都可以对YOLOv11模型进行对象检测训练。
我们提供了使用模型在视频中检测物体的代码。
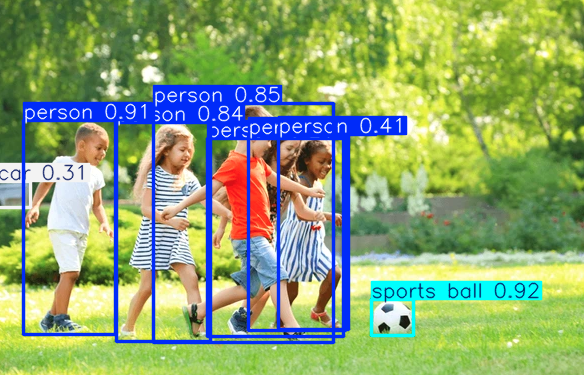
接下来,我们将尝试使用模型在图像中检测物体。
要使用模型进行分割,我们需要下载YOLO11,因为直接尝试模型可能会抛出错误。

同样,进行姿态估计和分类任务时,我们需要下载YOLO11模型,然后在图像上尝试模型。


现在建议使用高性能GPU来运行或训练YOLOv11,否则训练或推理可能会很慢且效率低下。在运行或训练YOLOv11时,选择GPU而不是CPU可以显著提高性能和效率。YOLOv11通过增强特征提取和改进准确性,需要强大的计算能力,尤其是在大型数据集上进行训练时。GPU专门用于并行处理,使它们能够以比CPU快得多的速度处理深学习所需的复杂矩阵运算。DigitalOcean GPU Droplets针对AI/ML工作负载进行了优化,提供了对功能强大的GPU(如H100)的访问权限,这些GPU专门设计用于高级性能和处理重计算。
总结
我们看到了模型在图像和视频方面能做到的一些酷的事情。YOLOv11是一个强大且多功能的计算机视觉任务模型。其改进的特征以及高速度和准确性使它比其前身有了显著的升级。
总之,YOLOv11在目标检测和计算机视觉方面迈出了重要的一步。凭借其更好的架构设计、更快的速度和提高的准确性,它非常适合各种应用——无论是在小型设备上进行实时检测,还是在云端进行更详细的分析。其与现有系统顺利工作的能力意味着企业可以轻松将其整合到日常运营中,无论是在农业、安全还是机器人技术方面。YOLOv11在灵活性和性能之间的平衡使其成为解决计算机视觉挑战的强大工具。
然而,这是教程的第一部分,在第二部分中,我们将学习如何针对自定义数据集对模型进行微调和训练以进行目标检测。
参考文献
Source:
https://www.digitalocean.com/community/tutorials/what-is-new-with-yolo