













紹介
YOLO Vision 2024イベントで、UltralyticsはYOLOシリーズの新しいメンバーとしてYOLOv11を発表しました。この記事では、YOLOv11モデルの概要、YOLOv11を使用して推論を実行する方法、そしてこのモデルと前のモデルの祖先进と比較しての主要な進歩と特徴点を提供します。YOLOv11モデルは、物体検出、画像分割、画像分類、姿勢推定、及び实时物体追跡などの任务に対して、速く、正確で、使用しやすいデザインになっています。
新しい最も最先端の(SOTA)モデルは、前のYOLOモデルよりも推論速度が速く、精度が改善されています。始める前に、Ultralyticsによって提供されるベンチマーク結果を見てみましょう。ベンチマークプロットでは、YOLOv11モデルがYOLOv5、v6、v7、v8、v9、およびv10と比較されています。
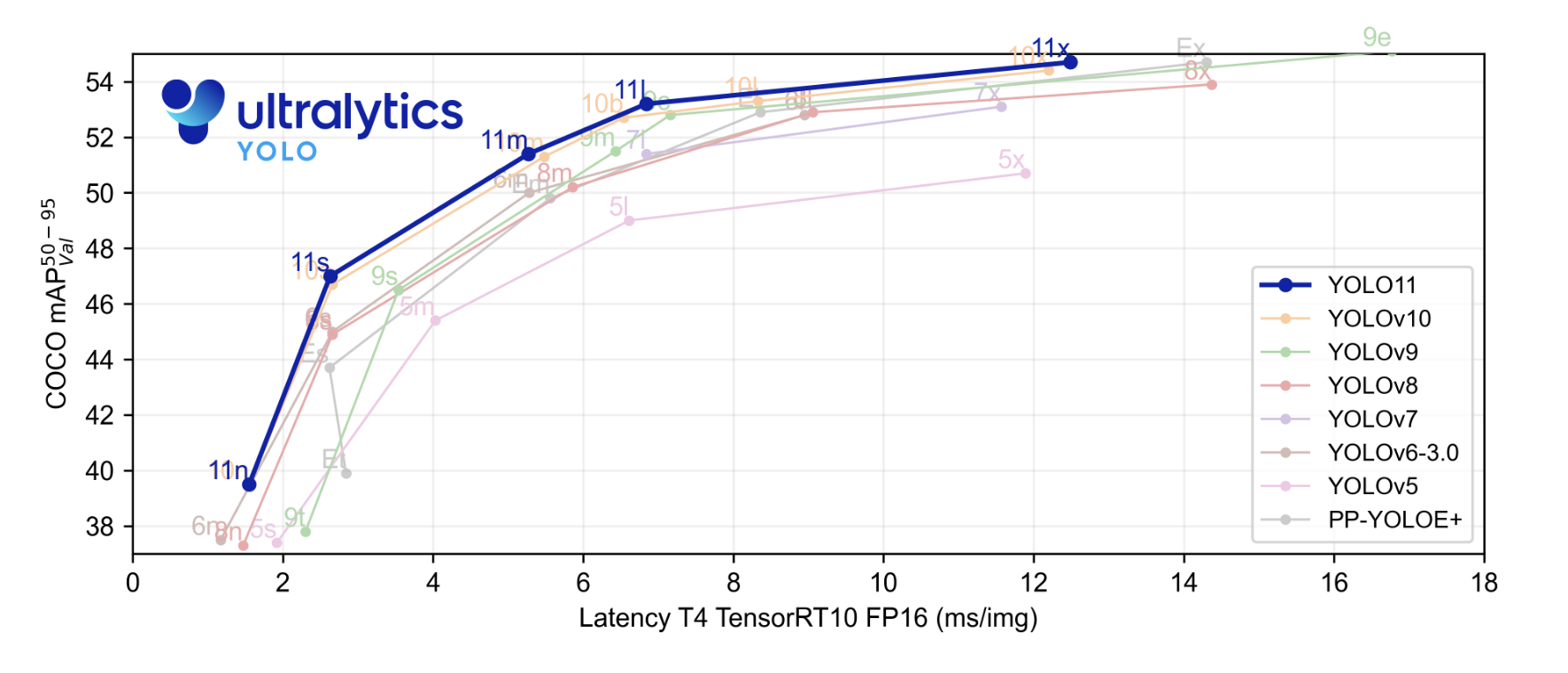
青い線で示されるYOLOv11のパフォーマンスは、COCOデータセット上でYOLOモデルやそのシリーズの平均平均精度を大幅に上回っていることがわかります。また、x軸に示される推論速度においても同様の結果です。
YOLOv11がサポートしているタスク
- 物体检测:- 画像やビデオに対して境界ボックスを引くことで物体を特定し、信頼度スコアを算出する。自律走行車、監視カメラ、または交通課のようなアプリケーションに有用です。
- インスタンス分割:- 画像内の物体や個体を特定し、分割する。医学画像、製造においても便利です。
- 姿勢推定:- 画像やビデオフレーム内の关键点を特定し、体の動きや手勢を監視する。虚拟現実、ダンス指導、または身体理学療法のようなアプリケーションに有用です。
- 向き付けた物体检测(OBB):- 傾きや回転されたアイテムをより正確に定位するために、傾斜ある物体を检测する機能。自律走行車、工業機械の検査、またはドローンや衛星からの画像の分析に特に有用です。
| Model | Tasks |
|---|---|
| YOLO11 | 検出(COCO) |
| YOLO11-seg | 分割(COCO) |
| YOLO11-pose | 姿勢/キーポイント(COCO) |
| YOLO11-obb | 向け検出 (DOTAv1) |
| YOLO11-cls | 分類 (ImageNet) |
YOLOv11は、COCOデータセットで事前学習されたDetect、Segment、およびPoseモデルを提供しており、ImageNetデータセットで事前学習されたClassifyモデルも提供しています。すべてのDetect、Segment、およびPoseモデルに Track モードも利用可能です。モデルの詳細とその異なるバージョンについての更多信息は、公式のGitHubリポジトリをご参照ください。リソースセクションに直接リンクを含めていますので、便利に利用できます。

前提条件
YOLOモデルを実行するための前提条件は以下の通りです。
- Python環境: Python 3.8またはそれ以降のバージョンをインストールしてください。
- CUDA & cuDNN: CUDAに対応したGPU (NVIDIA)をお持ちで、CUDAとcuDNNをインストールしてください。これらはより速いトレーニングと推論に使用できます。
- PyTorch: お使いのCUDAバージョンに合わせたPyTorchをインストールしてください。
- YOLOフレームワーク: Ultralyticsから特定のYOLOバージョンのパッケージをインストールしてください。
- データセット: YOLO形式のラベル付きデータセット (画像とアノテーションファイル)。
- ハードウェア要件: トレーニングと推論をスムーズにするために、少なくとも16 GBのRAMとGPUをお持ちでください。GPUのVRAMが4+ GBを超えるものをお勧めします。
新型のキー機能の特徴
YOLOv11は、コンピュータビジョンのタスクに最適な強力な選択肢となるように、いくつかの改善点を持っています。より良いバックボーンとネックの設計により、物体をより正確に認識し、複雑なタスクを簡単に処理することができます。このモデルはスピードに最適化されており、より速い処理時間を提供しながら、精度と性能のバランスを保ちます。YOLOv8mより22%のパラメータを少なくなっているにも関わらず、この軽量なモデルはより高い精度を Achieve,効率的で有効なです。YOLOv11はまた、YOLOv10より2%しか早い推論時間を提供し、幅広い環境に适応できるようになっています。EDGEデバイス、クラウドシステム、NVIDIA GPUなどの様々なプラットフォームで良く機能します。また、物体認識、画像分類、姿勢推定など幅広いタスクにサポートしています。
YOLOv11は、さまざまなシステムやプラットフォームに簡単に統合できるよう設計されています。YOLOv8のサポートを基に、トレーニング、テスト、およびデプロイメントに适したさまざまな環境でよく機能します。NVIDIA GPU、EDGEデバイス、クラウドプラットフォームを使用しても、YOLOv11はあなたのワークフローに柔軟に取り込まれることができます。
これらの特徴がさまざまな産業に適応性を持っています。
YOLOv11デモ
YOLOv11がDigitalOceanのGPU Dropletで実行されると、推論速度は画像に1つの物体を認識するために5から6ミリ秒に達することができ、これは速くて効率の高い処理が必要なリアルタイムアプリケーションの理想的な選択肢となる。
まず、ultralyticsパッケージをインストールしたり、パッケージをアップグレードすることから始めます。
YOLOv11モデルを物体認識するためには、Pythonを使用したり、CLIコマンドを使用したりしてモデルのトレーニングが可能である。
私たちは、モデルを動画内の物体認識に使用するためのコードを提供しました。
次に、モデルを画像内の物体認識に試すことにします。
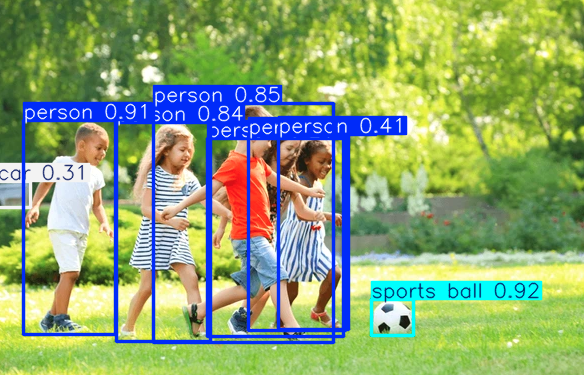
モデルをセグメンテーションに使用するためには、YOLO11 modelをダウンロードする必要があり、直接試すことはエラーを投げる可能性がある。

同様に、姿勢推定と分類任务にはYOLO11 modelをダウンロードし、その後画像に試す必要があります。


現在、YOLOv11の実行またはトレーニングには高性能GPUを使用することが推奨されます。CPUを選択しない場合、トレーニングまたは推論は遅く且つ效率が低い可能性があります。YOLOv11の実行またはトレーニングにおいて、GPUをCPUより選択することで、パフォーマンスと効率を大幅に向上させることができます。より良い特徴抽出機能と精度向上に対する要求に耐えるために、GPUは大きなデータセットでのトレーニングに特に高性能を必要とします。GPUは並列処理に Optimized されており、深層学習に必要な複雑な行列演算をCPUよりも大幅に速く処理することができます。デジタルオーシャンGPUドロップレットはAI/MLのワークロードに最適化されており、H100のような強力なGPUへのアクセスを提供します。これらのGPUは高度なパフォーマンスと重い計算を処理するために特に設計されています。
結論
私たちは、モデルが画像とビデオで行うすばらしいことを見ました。YOLOv11は、コンピュータビジョンのタスクにおいて強力で多用途なモデルであり、改善された機能、高いスピードと精度が前のモデルを大幅に上回るという点で、大きな進歩を示しています。
結論的には、YOLOv11は、物体認識とコンピュータビジョンにおける大きな一歩 forward であり、より良いアーキテクチャ設計、より速い速度、改善された精度により、さまざまな用途に最適なようになっています。小さな装置上の实时認識やクラウド上のより詳細な分析など。それが既存のシステムとうまく互換性があることから、企業は日常的な业务に容易に取り込むことができます。農業、セキュリティ、ロボット学どの分野でも。YOLOv11は、柔軟性とパフォーマンスの融合により、コンピュータビジョンの課題に取り組む人すべてに強力なツールとなっています。
しかし、これはチュートリアルの第1部分であり、第2部分では、カスタムデータセットにおける物体認識のためにモデルを細工し、トレーニングする方法を学びます。
関連文献
Source:
https://www.digitalocean.com/community/tutorials/what-is-new-with-yolo