













Introdução
No evento YOLO Vision 2024, a Ultralytics anunciou um novo membro da série YOLO chamado YOLOv11. Este artigo fornecerá uma visão geral do novo modelo, instruções sobre como executar inferencia usando o YOLOv11, e as melhorias e destaques do modelo em comparação com o seu predecessor. O modelo YOLOv11 é projetado para ser rápido, preciso e fácil de usar para tarefas como detecção de objetos, segmentação de imagem, classificação de imagem, estimação de postura e rastreamento de objetos em tempo real.
O novo modelo de estado da arte (SOTA) alcançou uma velocidade de inferência mais rápida e uma precisão melhorada em comparação com os modelos YOLO anteriores. Antes de começarmos, vamos olhar para os resultados de referência fornecidos pela Ultralytics. No gráfico de referência, o modelo YOLOv11 foi comparado com o YOLOv5, v6, v7, v8, v9 e v10.
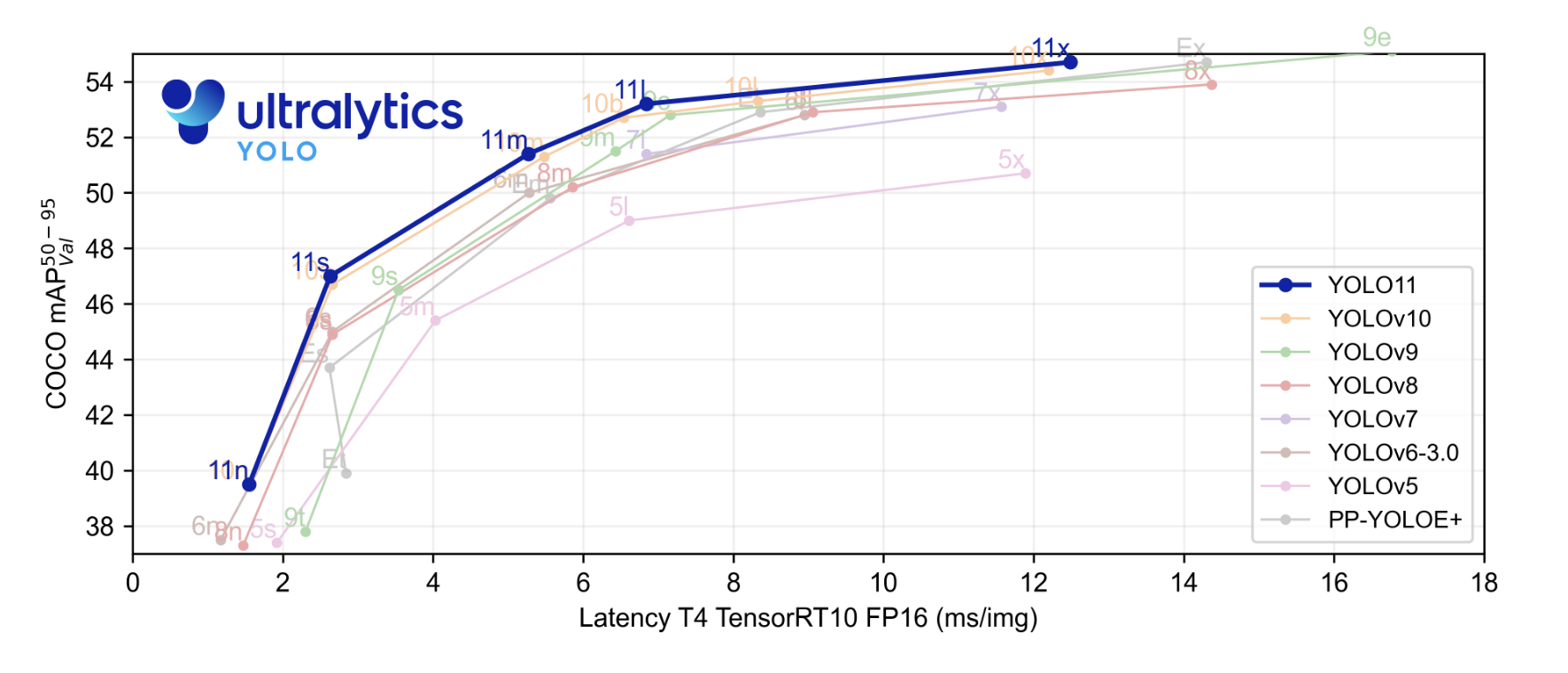
O gráfico destacado em azul é a performance do YOLOv11 e, conforme podem ver, ele superou praticamente todos os modelos YOLO ou as séries em média máxima de precisão no conjunto de dados COCO e na velocidade de inferência, conforme representado no eixo x.
Tarefas Suportadas pelo YOLOv11
- Detecção de Objetos:- Localizar objetos em imagens ou vídeos, desenhando caixas de delimitação juntamente com as notas de confiança. Util para aplicações como condução autônoma, câmeras de vigilância ou postos de cobrança de tráfego.
- Segmentação de Instâncias:- Identificar e segmentar objetos ou indivíduos em uma imagem. Util para imagens médicas, manufatura e muito mais.
- Estimação de Pose:- Identificar pontos chave em uma imagem ou quadro de vídeo para monitorar movimentos corporais ou gestos, tornando-se útil para aplicações como realidade virtual, treinamento de dança e terapia física.
- Detecção de Objetos Orientados (OBB):- Detecção de objetos com um ângulo de orientação, permitindo a localização mais precisa de itens inclinados ou rotacionados. Esta funcionalidade é particularmente útil para aplicações como condução autônoma, inspeção industrial e análise de imagens de drones ou satélites.
| Model | Tasks |
|---|---|
| YOLO11 | Detecção (COCO) |
| YOLO11-seg | Segmentação (COCO) |
| YOLO11-pose | Pose/Pontos-chave (COCO) |
| YOLO11-obb | Detecção Orientada a Oval (DOTAv1) |
| YOLO11-cls | Classificação (ImageNet) |
O YOLOv11 fornece modelos pré-treinados em detecção, segmentação e pose baseados no conjunto de dados COCO, além de modelos de classificação pré-treinados no conjunto de dados ImageNet. O modo de rastreamento também está disponível para todos os modelos de detecção, segmentação e pose. Para obter informações detalhadas sobre os modelos e suas versões diferentes, consulte o repositório oficial no GitHub. Nós incluímos um link direto na nossa seção de recursos para a conveniência.

Pré-requisitos
Estes são os pré-requisitos para executar os modelos YOLO:
- Ambiente Python: Instale Python 3.8 ou posterior.
- CUDA & cuDNN: Uma GPU compatível com CUDA da NVIDIA com CUDA e cuDNN instalados para treinamento e inferência mais rápidos.
- PyTorch: Instale o PyTorch compatível com sua versão de CUDA.
- Framework YOLO: Instale o pacote da versão específica do YOLO de Ultralytics.
- Dados de Treinamento: Conjunto de dados rotulados no formato YOLO (imagens e arquivos de anotação).
- Requisitos de Hardware: Pelo menos 16 GB de RAM e uma GPU com 4+ GB de VRAM para treinamento e inferência suaves.
Destacados Recursos Chave do novo modelo
O YOLOv11 traz várias melhorias que o tornam uma boa escolha para tarefas de visão computacional. Tem um melhor desenho de backbone e neck, o que o ajuda a detectar objetos com maior precisão e a lidar com tarefas complexas com facilidade. O modelo é otimizado para velocidade, oferecendo processamento mais rápido enquanto mantém um bom equilíbrio entre precisão e desempenho. Mesmo com 22% menos parâmetros do que o YOLOv8m, este modelo leve alcança maior precisão, tornando-se tanto eficiente quanto efetivo. O YOLOv11 também tem tempo de inferência 2% mais rápido do que o YOLOv10, tornando-o altamente adaptável, funcionando bem em várias plataformas como dispositivos de borda, sistemas em nuvem e GPUs NVIDIA. Além disso, ele suporta uma ampla gama de tarefas, incluindo detecção de objetos, classificação de imagens, estimulação de postura e muito mais.
O YOLOv11 está projetado para integrar facilmente com vários sistemas e plataformas. Ao construir na funcionalidade do YOLOv8, funciona bem em diferentes ambientes para treinamento, teste e implantação. Quer você use GPUs NVIDIA, dispositivos de borda ou plataformas em nuvem, o YOLOv11 se encaixa facilmente em seu fluxo de trabalho.
Estes recursos fazem do YOLOv11 adaptável para diferentes indústrias.
Demonstração YOLOv11
Quando o YOLOv11 é executado no Droplet GPU DigitalOcean, a velocidade de inferência atinge até 5 a 6 ms por imagem, tornando-o uma escolha ideal para aplicações em tempo real que exijam processamento rápido e eficiente.
Vamos começar instalando o pacote ultralytics ou atualizando o pacote.
Treinar o modelo YOLOv11 para detecção de objetos pode ser feito tanto em Python quanto usando comandos CLI.
Nós forneceram o código para usar o modelo para detecção de objetos em um vídeo.
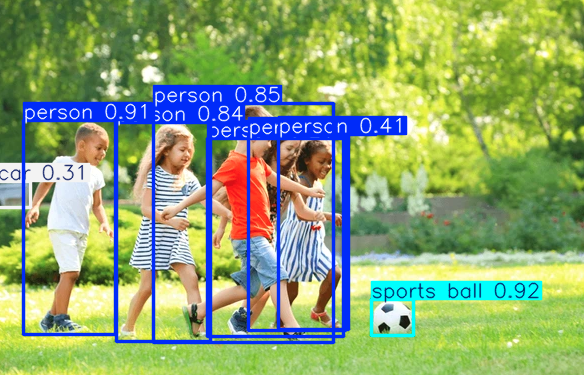
Em seguida, vamos tentar usar o modelo para detecção de objetos em uma imagem.
Para usar o modelo para segmentação, precisamos baixar o YOLO11 pois tentar o modelo diretamente pode lançar um erro.

Do mesmo modo, para tarefas de estimação de postura e classificação, precisamos baixar o modelo YOLO11 e depois tentar o modelo em uma imagem.


Agora é recomendável usar um GPU de alto final para executar ou treinar o YOLOv11, caso contrário, o treinamento ou a inferência podem ser lentos e ineficientes. Quando se trata de executar ou treinar o YOLOv11, escolher GPU em vez de CPU pode melhorar significativamente desempenho e eficiência. O YOLOv11, com suas melhorias na extração de recursos e precisão melhorada, exige alta potência computacional, particularmente para treinamento em grandes conjuntos de dados. GPUs são projetadas especificamente para processamento paralelo, permitindo que elas gerem as operações de matriz complexas necessárias para aprendizagem profunda muito mais rápido do que os CPUs. Droplets GPU DigitalOcean são otimizados para cargas de trabalho de AI/ML, oferecendo acesso a poderosos GPUs como o H100, que são projetados especialmente para o desempenho avançado e para lidar com computações pesadas.
Conclusões
Vimos algumas coisas interessantes que o modelo pode fazer com imagens e vídeos. O YOLOv11 é um modelo poderoso e versátil para tarefas de visão computacional. Suas melhorias funcionais e sua alta velocidade e precisão o tornam uma atualização significativa em relação a seus predecessores.
Em conclusão, o YOLOv11 representa um grande avanço em detecção de objetos e visão computacional. Com seu melhor desenho arquitetônico, velocidades mais rápidas e precisão melhorada, é excelente para vários usos – detecção em tempo real em dispositivos pequenos ou análise mais detalhada no cloud. Sua capacidade de funcionar sem problemas com sistemas existentes significa que as empresas podem integrá-lo facilmente em suas operações diárias, quer em agricultura, segurança ou robótica. A mistura de flexibilidade e desempenho do YOLOv11 o torna uma ferramenta poderosa para qualquer pessoa que enfrenta desafios de visão computacional.
Entretanto, este é o primeiro parte do tutorial, e na segunda parte, vamos aprender a finetune e treinar o modelo para detecção de objetos the um conjunto de dados customizado.
Referências
- Imagens usadas fontes
- Ultralytics YOLO11
- Treino de Modelos de Ultralytics
- Github Oficial do YOLOv11
Source:
https://www.digitalocean.com/community/tutorials/what-is-new-with-yolo