













개 introduce
YOLO Vision 2024 이벤트에서, Ultralytics는 YOLO 시리즈의 새로운 멤버로 YOLOv11을 발표했습니다. 이 記事에서는 YOLOv11 모델의 개요, 이를 사용하여 推論 실행하는 방법, 그리고 이전 모델 predecessor와 比较해 보는 주요 발전 및 모델의 selling points를 제시합니다. YOLOv11 모델은 객체 감지, 이미지 분할, 이미지 분류, 姿勢 推定, 실시간 객체 추적과 같은 任务에 대해 快速, 정확하고 사용하기 쉽게 디자인되었습니다.
최신 주요 기술(SOTA) 모델은 이전 YOLO 모델과 比较해 推论 速度이 더 빨라지고 정확도가 향상되었습니다. 시작하기 전에, Ultralytics에서 제시한 기준 결과를 살펴봅시다. 기준 그래프에서, YOLOv11 모델은 YOLOv5, v6, v7, v8, v9, v10과 比较되었습니다.
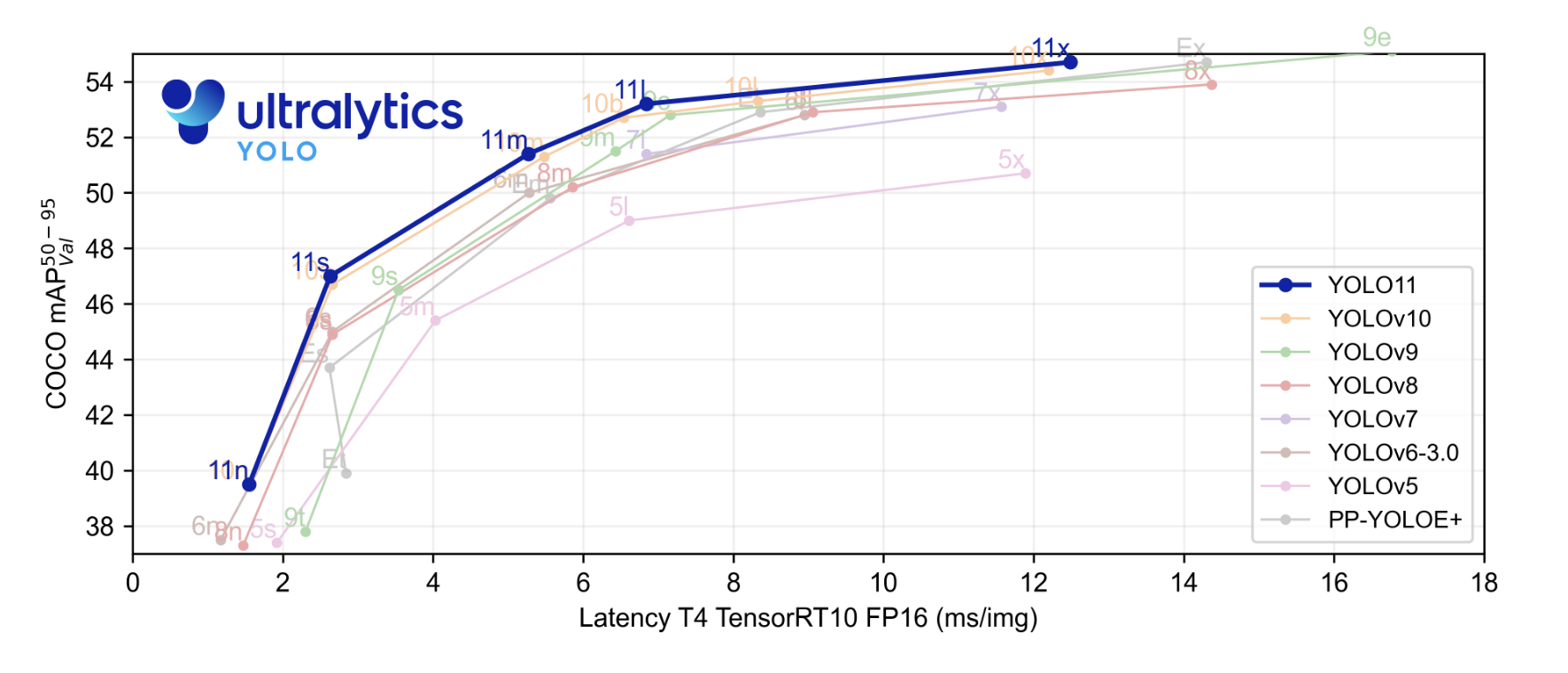
하얀 底色의 파란 사각형은 YOLOv11의 성능입니다. 우리는 YOLOv11이 COCO 데이터셋에 대해 ほぼ모든 YOLO 모델이나 시리즈를 제补血한 평균 정확도를 기록했음을 확인할 수 있습니다. 또한 x-축에 나타낸 推定 속도에서도 그 성능을 보여줍니다.
YOLOv11로 지원하는 태스크
- 객체 감지:- 이미지나 동영상에서 객체를 矩形 region of interest(ROI)로 localize하고 신뢰도 점수를 표시하는 것。자율 주행, 監視 摄像头, 또는 교통 collects booths과 같은 응용 장치에 유용합니다.
- 인스턴스 분할:- 이미지에서 객체나 개인을 식별하고 분할하는 것。의료 이미지 처리, 제조 과정 등에 유용합니다.
- 姿勢 추정:- 이미지나 동영상 프레임에서 신체 運動 또는 gesture를 모니터하기 위해 주요 지점을 식별하는 것。가상 현실, 舞蹈 교육, 신체 치료와 같은 응용에 유용합니다.
- direction object detection (OBB):- 傾斜되거나 회전된 아이템을 더 精準하게 위치를 localize하기 위해 각도 angel에 의한 객체 감지。자율 주행, 산업 inspecction, 또는 无人機나 衛星 이미지 분석과 같은 응용에 특히 유용합니다.
| Model | Tasks |
|---|---|
| YOLO11 | Detection (COCO) |
| YOLO11-seg | Segmentation (COCO) |
| YOLO11-pose | Pose/Keypoints (COCO) |
| YOLO11-obb | Oriented Detection (DOTAv1) |
| YOLO11-cls | Classification (ImageNet) |
YOLOv11는 COCO 데이터셋을 이용해 예지 ripple, 구별 ripple, 姿勢 ripple 모델을 미리 트레이닝 하고, ImageNet 데이터셋을 이용해 분류 ripple을 미리 트레이닝 한 모델로 구성되어 있습니다. 모든 예지 ripple, 구별 ripple, 姿勢 ripple 모델에 대해 트랙 모드도 사용 가능합니다. 모델 세부 사항과 여러 버전에 대한 更多信息은 공식 GitHub 저장소를 참조하십시오. 자료 부분에 직접 연결을 included하였습니다.

Prerequisites
YOLO 모델을 실행하기 위한 前提条件은 다음과 같습니다:
- Python Environment: Python 3.8 이상을 설치하십시오.
- CUDA & cuDNN: 빠른 트레이닝과 推论을 위해 CUDA-compatible GPU (NVIDIA)를 가지고 CUDA와 cuDNN을 설치하십시오.
- PyTorch: 您的 CUDA 버전에 compatible하는 PyTorch을 설치하십시오.
- YOLO Framework: Ultralytics에서 specific YOLO version package를 설치하십시오.
- Dataset: YOLO 형식의 레이블링 데이터셋 (이미지와 주석 파일).
- Hardware Requirements: Truman training과 inference를 위해 至少 16 GB RAM과 GPU가 4+ GB VRAM을 가지는지 확인하십시오.
新区提案의 주요 특징 고lighting
YOLOv11는 컴퓨터 비전 任务에 대한 강력한 선택이지만, 이를 위해 다양한 改善들을 적용했습니다. 이 모델은 더 좋은 主干(backbone)과 목(neck) 設計을 갖추고 있어 객체를 더 精確하게 감지하고 複雑한 任务을 어려움 없이 처리할 수 있습니다. 이 모델은 속도를 optimization 하였으며, 처리 시간을 더 빨라捷하게 하며 정확性和 성능의 좋은 balanc을 유지합니다. YOLOv8m보다 22%의 パラ미터를 적게 가지고 있지만, 이 가벼운 모델은 더 높은 정확性을 달성하며 效率的하고 적절하게 작동합니다. YOLOv11는 또한 YOLOv10보다 推論 시간을 2% 더 빨라捷하게 하며 높은 적응성을 보유하며, 端末 device, 云 시스템, NVIDIA GPU 등의 다양한 Platform에서 잘 작동합니다. 또한, 객체 감지, 이미지 분류, 姿勢 추정 등의 다양한 task를 지원합니다.
YOLOv11는 다양한 시스템과 latform에 容易하게 통합할 수 있는 모델입니다. YOLOv8의 지원을 기반으로 다양한 환경에서 훈련, 테스트, 배치를 위한 良好한 작동을 할 수 있습니다. NVIDIA GPU, 端末 device, 云 atform 등을 사용하든지 마음대로 workflow에 넣을 수 있습니다.
이러한 특징은 YOLOv11가 다양한 産業에 적용되는 것을 도울 수 있습니다.
YOLOv11 示 Demo
YOLOv11이 DigitalOcean의 GPU Droplet上에 실행되면, 각 이미지당 推論 속도가 5 到 6 毫秒로 달성되며, 快速하고 효율적인 처리를 요구하는 실시간 应用程序에 理想的한 선택이 되ます。
우리는 ULTRAlytics 패키지를 설치하거나 패키지를 업그레이드 시키기를 시작할 것입니다.
YOLOv11 모델을 객체 감지하기 위해 Python을 사용하거나 CLI 명령어를 사용하여 트레이닝할 수 있습니다.
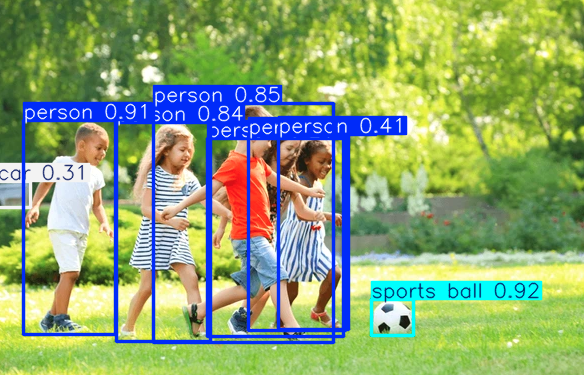
이미지 내 객체 감지를 위해 모델을 사용하는 코드를 제공했습니다.
次に, 이미지 내 객체 감지를 시도할 것입니다.
segmentation를 위해 모델을 사용하기 위해 YOLO11을 다운로드해야만 直接的 시도하여 에러를 던질 수 있습니다.

조사 예측과 분류 任务에 대해서는 YOLO11 모델을 다운로드하고 이미지에 대한 시도를 해야 합니다.


지금 하드웨어 GPU를 사용하여 YOLOv11을 실행하거나 트레이닝하는 것이 좋은 의도입니다. 그렇지 않으면 트레이닝 또는 인ference가 느리고 inefficient하게 동작할 수 있습니다. YOLOv11을 실행하거나 트레이닝할 때 CPU를 선택하는 것보다 GPU를 선택하면 パフォーマンス와 효율을 substantially 높일 수 있습니다. 향상된 feature extraction과 향상된 accuracy를 제공하는 YOLOv11은 특히 대형 데이터셋에서 트레이닝 시에 high computational power를 요구합니다. GPU는 paralle processing를 위한 特化 design되어 있으며 deep learning을 위해 必要한 complex matrix operations를 快速发展하도록 해줍니다. DigitalOcean GPU Droplets는 AI/ML workloads를 위한 최적화되었으며 H100과 같은 強力な GPU에 대한 接入를 제공합니다. H100은 进阶 performance를 위해 特化 design되었고 重荷 computing를 처리하기 위해서입니다.
Concluding Thoughts
우리는 모델이 이미지와 동영상을 사용하여 一些 멋진 것을 봤습니다. YOLOv11은 컴퓨터 시각 任务에 強力하고 다양한 능력을 보인다. 그의 개선된 특징, 고 속도 및 정확성은 이전 모델들을 대 laughingly 할 수 있는 중요한 upgrade를 제공한다.
결론적으로, YOLOv11은 대型 검출과 컴퓨터 시각에서 큰 한 歩进一步가 되었습니다. 그의 좋은 구조 설계, 빠른 속도, 정확성 향상은 다양한 用途에 딱 맞는다-소형 기기에서 실시간 검출 或者 облаке에서 더 자세한 분석을 할 수 있습니다. 现存的 시스템과 똑똑하게 동작하는 능력은 기업들이 일상적인 业务에 쉽게 통합할 수 있다는 의미가 있습니다, 모바일 Filed, 보안, 로봇 등에서 사용할 수 있습니다. YOLOv11은 유연성과 パフォーマンス의 妥协로 컴퓨터 시각의 도전을 이룰 수 있는 강력한 도구가 되었습니다.
그러나 이 튜orial의 일부로, 튜orial 2에서는 사용자 데이터셋에 대한 대型 검출 도중 모델을 精调 및 트레이닝 하는 方法을 배울 것입니다.
References
- Images used Sources
- Ultralytics YOLO11
- Ultralytics 모델 트레이닝
- YOLOv11 공식 Github
Source:
https://www.digitalocean.com/community/tutorials/what-is-new-with-yolo