













Introduction
Lors de l’événement YOLO Vision 2024, Ultralytics a annoncé un nouveau membre de la série YOLO baptisé YOLOv11. Cet article offrira un aperçu du nouveau modèle, des instructions sur comment effectuer des inférences avec YOLOv11, et les principaux progrès et points forts du modècle par rapport à son prédécesseur. Le modèle YOLOv11 est conçu pour être rapide, précis et facile à utiliser pour des tâches telles que la détection d’objets, la segmentation d’images, la classification d’images, l’estimation de la position et le suivi d’objets en temps réel.
Le nouveau modèle de pointe (SOTA) a atteint une vitesse d’inférence plus rapide et une précision améliorée par rapport aux modèles YOLO précédents. Avant de commencer, regardons les résultats de référence fournis par Ultralytics. Dans le graphique de référence, le modèle YOLOv11 a été comparé aux YOLOv5, v6, v7, v8, v9 et v10.
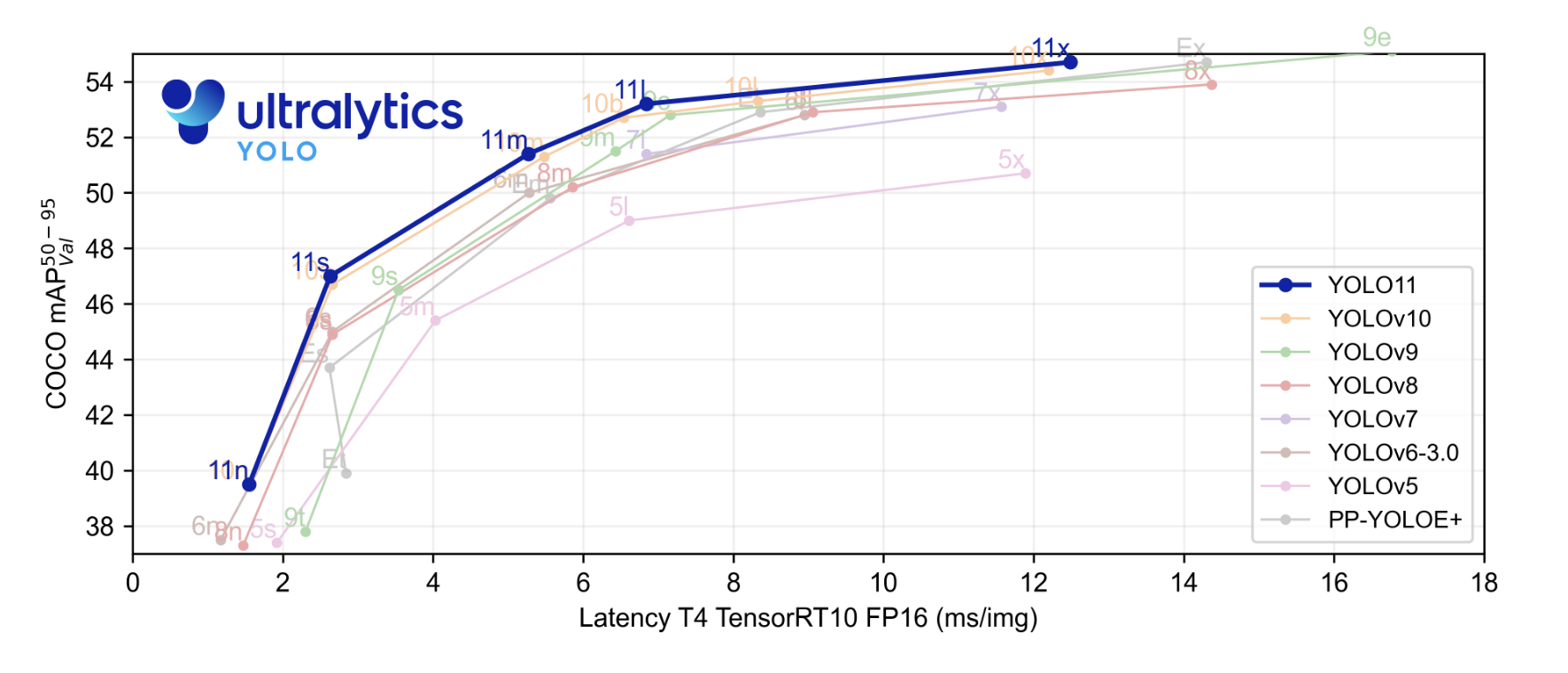
La courbe colorée en bleu ressortie est la performance de YOLOv11 et comme nous pouvons le voir, elle a dépassé presque toutes les versions de YOLO ou les séries sur mean average precision sur le jeu de données COCO ainsi que sur la vitesse d’inférence comme illustré sur l’axe des x.
Tâches prises en charge par YOLOv11
- Détection d’objets :- Localiser des objets dans une image ou une vidéo en les encadrant avec des boîtes de délimitation ainsi que des scores de confiance. Utile pour des applications telles que la conduite autonome, les caméras de surveillance ou les postes de paiement des passages routiers.
- Segmentation d’instances :- Identifier et segmenter des objets ou des individus dans une image. Utile pour l’imagerie médicale, la fabrication et plus.
- Estimation de la pose :- Identifier les points clés dans une image ou un cadre de vidéo pour surveiller les mouvements corporels ou les gestes, ce qui est utile pour des applications telles que la réalité virtuelle, l’entraînement de danse et la rééducation physique.
- Détection d’objets orientés (OBB) :- Détecter des objets avec un angle d’orientation, permettant une localisation plus précise de produits inclinés ou tournés. Cette fonctionnalité est particulièrement utile pour des applications telles que la conduite autonome, l’inspection industrielle et l’analyse d’images provenant de drones ou de satellites.
| Model | Tasks |
|---|---|
| YOLO11 | Détection (COCO) |
| YOLO11-seg | Segmentation (COCO) |
| YOLO11-pose | Pose/Points clés (COCO) |
| YOLO11-obb | Détection orientée (DOTAv1) |
| YOLO11-cls | Classification (ImageNet) |
YOLOv11 fournit des modèles pré-entraînés sur le jeu de données COCO pour la détection, la segmentation et la pose, ainsi que des modèles de classification pré-entraînés sur le jeu de données ImageNet. Un mode de suivi est également disponible pour tous les modèles de détection, de segmentation et de pose. Pour plus d’informations sur les détails des modèles et leurs différentes versions, veuillez se référer au référentiel GitHub officiel. Nous avons inclus un lien direct dans notre section des ressources pour votre commodité.

Prérequis
Voici les prérequis pour exécuter les modèles YOLO :
- Environnement Python : Installez Python 3.8 ou une version ultérieure.
- CUDA & cuDNN : Une carte graphique compatible CUDA (NVIDIA) avec CUDA et cuDNN installés pour un entraînement et une interprétation plus rapides.
- PyTorch : Installez PyTorch compatible avec votre version de CUDA.
- Cadre YOLO : Installez le package de la version spécifique de YOLO d’Ultralytics.
- Jeu de données : Jeu de données étiqueté dans le format YOLO (images et fichiers d’annotation).
- Requirements matériels : Au moins 16 Go de RAM et une carte graphique avec 4+ Go de VRAM pour un entraînement et une interprétation fluides.
Points saillants des caractéristiques du nouveau modèle
YOLOv11 apporte plusieurs améliorations qui le rendent une bonne sélection pour les tâches de vision par ordinateur. Il dispose d’un meilleur design de backbonne et de couche intermédiaire, ce qui l’aide à détecter les objets de manière plus précise et à traiter les tâches complexes avec facilité. Le modèle est optimisé pour la vitesse, offrant des temps de traitement plus rapides tout en maintenant un bon équilibre entre précision et performance. En dépit de 22% de paramètres inférieurs à ceux de YOLOv8m, ce modèle léger atteint une plus haute précision, ce qui en fait à la fois efficient et efficace. YOLOv11 possède également un temps d’inférence 2% plus rapide que celui de YOLOv10, ce qui en fait un modèle hautement adaptable, fonctionnant bien sur diverses plateformes telles que les appareils à bord, les systèmes cloud et les GPU NVIDIA. De plus, il supporte une large gamme de tâches, notamment la détection d’objets, la classification d’images, l’estimation de la position et plus.
YOLOv11 est conçu pour être facilement intégrable dans divers systèmes et plateformes. Il se fonde sur l’appui de YOLOv8 et fonctionne bien dans différents environnements pour la formation, la validation et la déploiement. Que vous utilisez des GPU NVIDIA, des appareils à bord ou des plateformes cloud, YOLOv11 s’intègre aisément à votre flux de travail.
Ces caractéristiques font de YOLOv11 adaptable pour les différentes industries.
Démonstration de YOLOv11
Lorsque YOLOv11 est exécuté sur un Droplet GPU de DigitalOcean, la vitesse d’inférence peut atteindre jusqu’à 5 à 6 ms par image, ce qui en fait une solution idéale pour les applications en temps réel exigeant un traitement rapide et efficient.
Nous commencerons par installer le package ultralytics ou mettre à jour le package.
Le training du modèle YOLOv11 pour la détection d’objets peut être effectué à la fois en Python ou à l’aide de commandes CLI.
Nous avons fourni le code pour utiliser le modèle pour détecter des objets dans un vidéo.
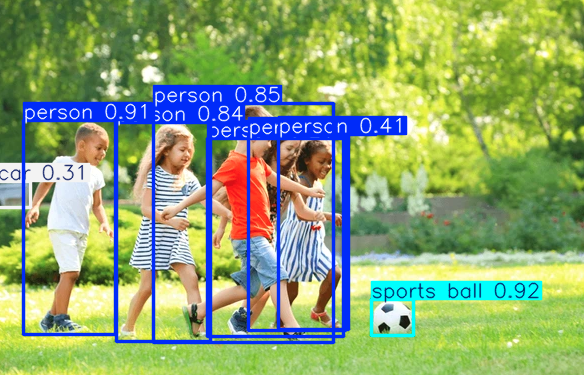
Ensuite, nous essayons le modèle pour détecter des objets dans une image.
Pour utiliser le modèle pour la segmentation, nous devons télécharger le modèle YOLO11 car l’essai du modèle directement peut lancer une erreur.

De même, pour les tâches d’estimation de position et de classification, nous devons télécharger le modèle YOLO11 et ensuite essayer le modèle sur une image.


Maintenant, il est avisable d’utiliser un GPU haut de gamme pour exécuter ou entraîner YOLOv11, sinon l’entraînement ou l’interrogation peuvent être lentes et inefficaces. Lorsqu’il s’agit d’exécuter ou d’entraîner YOLOv11, le choix d’un GPU plutôt qu’un CPU peut améliorer considérablement les performances et l’efficacité. YOLOv11, avec son extraction de caractéristiques améliorée et sa précision accrue, nécessite une grande puissance calculatoire, en particulier pour l’entraînement sur de grands jeux de données. Les GPU sont conçus spécialement pour le traitement parallèle, ce qui leur permet de gérer les opérations de matrices complexes nécessaires pour le apprentissage profond pour une vitesse beaucoup plus élevée que les CPU. Les Droplet GPU DigitalOcean sont optimisés pour les charges de travail AI/ML, offrant accès à des GPU puissantes comme la H100, conçues spécialement pour une performance avancée et un traitement intensif du calcul.
Pensées Conclusionnelles
Nous avons vu des choses sympa que le modèle peut faire avec des images et des vidéos. YOLOv11 est un modèle puissant et polyvalent pour les tâches de vision par ordinateur. Ses fonctionnalités améliorées, sa vitesse élevée et sa précision font de lui une mise à niveau significative par rapport à ses prédécesseurs.
En conclusion, YOLOv11 est une avancée importante dans la détection d’objets et la vision par ordinateur. Avec son meilleure conception architecturale, ses vitesses accrues et sa précision améliorée, il convient parfaitement pour divers usages – détection en temps réel sur de petits appareils ou une analyse plus détaillée dans le cloud. Sa capacité à fonctionner sans problème avec les systèmes existants signifie que les entreprises peuvent facilement l’intégrer à leurs opérations quotidiennes, que ce soit dans l’agriculture, la sécurité ou la robotique. La combinaison de flexibilité et de performance de YOLOv11 en fait une puissante arme pour qui traite des défis de vision par ordinateur.
Cependant, ceci est la partie 1 de la tutorial, et dans la partie 2, nous apprendrons comment peaufiner et entraîner le modèle pour la détection d’objets sur un jeu de données personnalisé.
Références
- Images utilisées Sources
- Ultralytics YOLO11
- Formation de modèles d’Ultralytics
- Github officiel de YOLOv11
Source:
https://www.digitalocean.com/community/tutorials/what-is-new-with-yolo