













مقدمة
في event YOLO Vision 2024، أعلنت Ultralytics عن أعضاء جديد في سلسلة YOLO يُدعى YOLOv11. سيتم في هذه المقالة إعطاء منظور عام للنموذج الجديد، وتعليمات حول كيفية تنفيذ التخمينات بواسطة YOLOv11، والتطورات والميزات الرئيسية للنموذج مقارنة بأقدم نموذجها السابق. يتم تصميم نموذج YOLOv11 لكي يكون سريعًا ودقيقًا وسهل الاستخدام للمهام التي تشمل التحديد الأشياء، والتسيير الصوري، وتصنيف الصور، وتقدير الوضع، والتتبع المباشر للأشياء.
وتم إنجاز نموذج معايير حديثة (SOTA) يحظى بسرعة تخمينات أسرع ودقة أفضل مقارنة بنماذج YOLO السابقة. قبل أن نبدأ، دعونا ننظر إلى نتائج المراكز التي قدمتها Ultralytics. في مخطط المراكز، قام نموذج YOLOv11 بمقارنة مع YOLOv5، v6، v7، v8، v9 و v10.
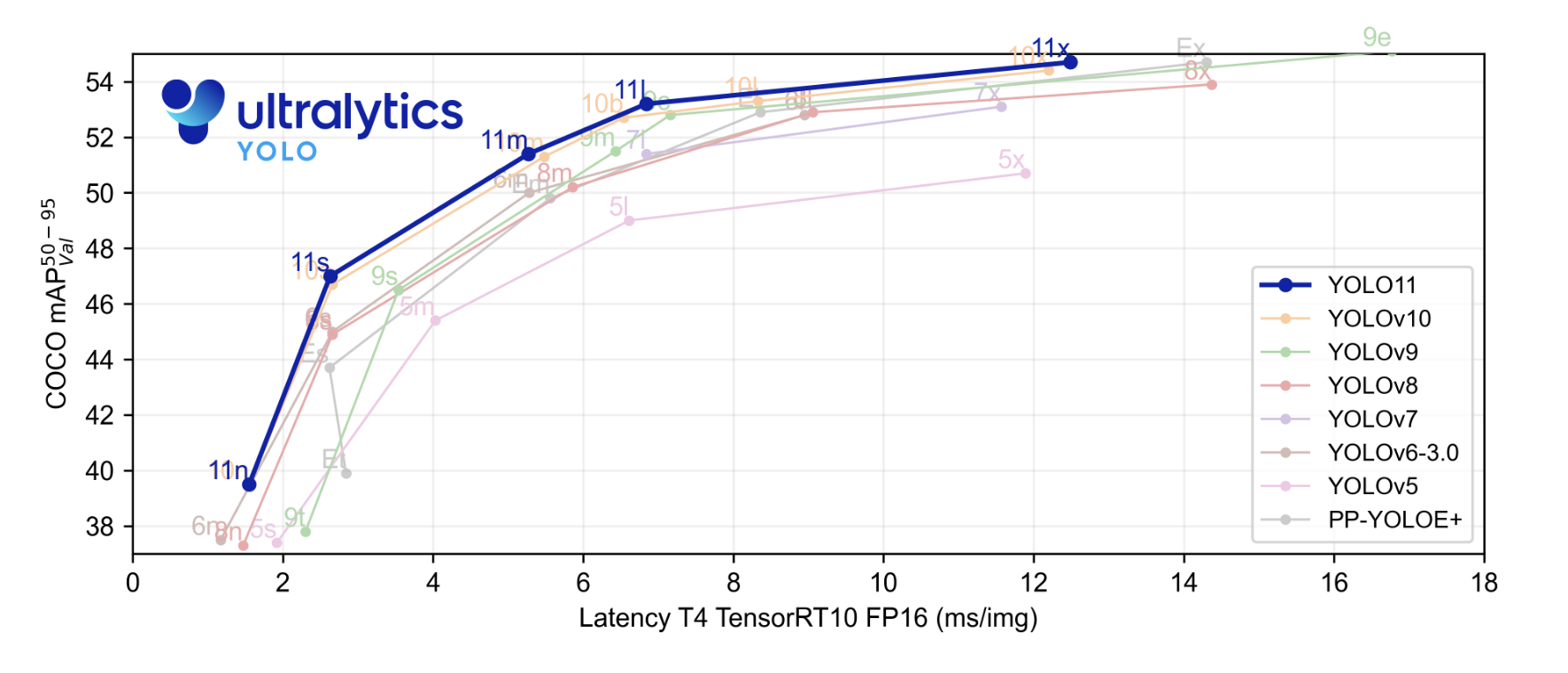
يوجد مخطط أزرق مبرز هو أداء YOLOv11 وكما نراه قد تجاوز كثيراً كل نموذج YOLO أو السلسلة في معدل الدقة المتوسطة على مجموعة COCO وفي سرعة التخمينات كما يظهر في المحور الأفقي.
المهام التي يدعمها YOLOv11
- الكشف عن الأجسام:- تحديد الأجسام في الصورة أو الفيديو برسم خطوط التحديد مع معدلات الثقة. ذلك مفيد للتطبيقات مثل القيادة الautonomous، أماكن المراقبة، أو مخابز الجريمة.
- التسييس الشخصي:- تحديد وتسييس الأجسام أو الأشخاص في الصورة. مفيد للتصوير الطبي، التصنيع والمزيد.
- تقدير المواقف:- تحديد النقاط الرئيسية في الصورة أو الشريحة الفيديوية للمراقبة على تحركات الجسم أو الإيماءات، مما يجعله مفيدًا للتطبيقات مثل الواقع الإفتراضي، تدريب الرقص، والعلاج الجسد.
- كشف الأجسام المتجهي (OBB):- تكشف الأجسام بوجهات تجهية، مما يسمح له بالتحديد الأكثر دقة للأجسام المنحرفة أو المدولة. تلك الوظيفة مفيدة خاصةً للتطبيقات مثل القيادة الautonomous، فحص الصناعي، وتحليل الصور من أجهزة الطائرات أو الأقمار.
| Model | Tasks |
|---|---|
| YOLO11 | Detection (COCO) |
| YOLO11-seg | Segmentation (COCO) |
| YOLO11-pose | Pose/Keypoints (COCO) |
| YOLO11-obb | الكشف التوجهي (DOTAv1) |
| YOLO11-cls | التصنيف (ImageNet) |
يوفر YOLOv11 النماذج المسبق التدريب على مجموعة COCO للكشف والتوزيع والوضع الجسمي، والنماذج المسبق التدريب على مجموعة ImageNet للتصنيف. يوفر أيضًا وضع التتبع لجميع النماذج المسبق التدريب على الكشف والتوزيع والوضع الجسمي. لمعلومات أكثر عن تفاصيل النموذج وأصدراته المختلفة، يرجى مراجعة المستودع الرسمي GitHub. قمنا بتضمين رابط مباشر في قسم مواردنا للوصول بسهولة.

الأحتياجات السابقة
هذه هي الأحتياجات لتشغيل نماذج YOLO:
- بينات البرمجيات: تثبيت Python 3.8 أو أحد الأصدرات الأحدث.
- CUDA و cuDNN: جهاز غرفة متوافق مع CUDA (NVIDIA) بتثبيت CUDA و cuDNN للتدريب الأسرع والتقدم النهائي.
- PyTorch: تثبيت PyTorch متوافق مع إصدرة CUDA الخاصة بك.
- الهياكل الخاصة ب YOLO: تثبيت حزمة النسخ الخاصة ب YOLO الإصدرة من Ultralytics.
- قاعدة بيانات: قاعدة بيانات متوسطة بالتسميات الYOLO (صور وملفات التوثيق).
- الrequirments الهاتفي: 16 جيغا بايت على الأقل من ذاكرة وجهاز غرفة مع 4+ جيغا بايت من VRAM للتدريب والتقدم النهائي بسهولة.
أبرز ميزات النموذج الجديد
يولوف11 يحمل مساعدات عديدة تجعله خيار قوي للمهام البصرية الحاسوبية. ولديه تصميم أساسي وعنق أفضل، وهذا يساعده في إكتشاف الأجسام بدقة أعلى ومعالجة المهام المعقدة بسهولة. وتم تنظيم النموذج للسرعة، مما يوفر وقت معالجة أسرع بينما يحتفظ بتوازن جيد بين الدقة والأداء. حتى بعد ذلك الـ22% من البندرمات بالمقارنة مع YOLOv8m، يحصل هذا النموذج الخفيف بالوزن على دقة أعلى، مما يجعله فعال وفعالي. وليولوف11 أيضًا وقت تخمين أسرع ب2% من ال YOLOv10، مما يجعله قابل للتكيف بشكل عالٍ، يعمل جيدًا في مختلف الأنظمة مثل الأجهزة الحاسوبية الخارجية، والأنظمة السحابية، والـGPUs النويدية. بالإضافة إلى ذلك، يدعم مجموعة واسعة من المهام، بما في ذلك إكتشاف الأجسام، تصنيف الصور، وتخمين الوضع.
يهدف YOLOv11 إلى تكامل بسهولة مع أنظمة وأراضي مختلفة. ويقوم بمساعدة YOLOv8، يعمل جيدًا في بيئات مختلفة للتدريب، الاختبار، والتنفيذ. سواء استخدمت الـGPUs النويدية، أو الأجهزة الحاسوبية الخارجية، أو أنظمة السحاب، يتماشى يولوف11 بكل سهولة في تنقلك.
هذه الميزات تجعل YOLOv11 مناسبًا للصناعة المختلفة.
تمثال YOLOv11
عندما يتم تشغيل YOLOv11 على دراجة GPU ديجيتالأوسك، يصل سرعة التخمينات إلى 5 إلى 6 ميليسيكس لكل صورة، مما يجعله خيار مثالي للتطبيقات الحالية التي تتطلب معالجة سريعة وفعالة.
سنبدأ بتثبيت الحزمة ultralytics أو تحديث الحزمة.
يمكن تدريب نموذج YOLOv11 للكشف عن الأجسام كليفًا باستخدام Python أو باستخدام أوامر الإنترفايزير (CLI).
قمنا بتوفير البرمجيات لإستخدام النموذج لكشف الأجسام في الفيديو.
من ثم، سنجرب تشغيل النموذج لكشف الأجسام في الصورة.
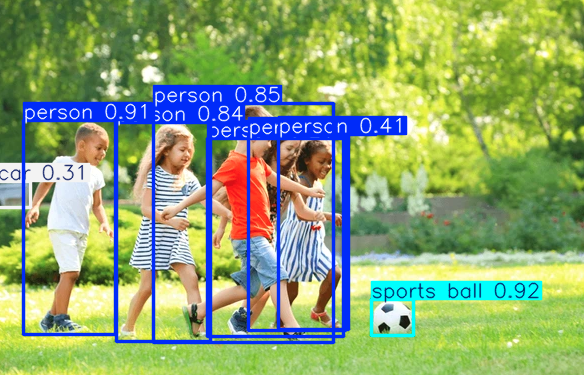
للاستخدام النموذج للتسيير، يتوجب علينا تحميل YOLO11 لأن محاولة استخدامه مباشرة قد تسبب خطأ.

بما في ذلك، فل التقدير البدني والتصنيف المستقبلي، يتوجب علينا تحميل نموذج YOLO11 ثم محاولة النموذج في الصورة.


الآن من الأفضل الاستفادة من جهاز معالج رأسمالي مرتفع المستوى لتشغيل أو تدريب YOLOv11، وإلا سيكون التدريب أو التخمين بطءًا وغير كفيًا. حينما يتعلق الأمر بتشغيل أو تدريب YOLOv11، يمكنك تحسين الأداء والكفاءة باختيار المعالج الجامد عوضاً عن المعالج العام. YOLOv11 ومعها التقنية المحسوسة المعززة والدقة المحسوسة الأفضل، تتطلب قوة حاسوبية عالية للتدريب خاصة عندما يتم تدريبها على مجموعات كبيرة. تمت المعالجات الجامدة بهدف معالجة العمليات الموازية، مما يسمح لها بمعالجة المتغيرات الرسمية المعقدة المتطلبة للتعلم العميق بمعدل أسرع بكثير من المعالجات العامة. القمامات GPU DigitalOcean مُتَعْ optimization للعمليات التي تتمتع بمعالجات رأسمالية قوية مثل ال H100، وهي مصممة خصيصًا للأداء المتقدم ومعالجة الحجم الكبير.
مذكرات ختامية
لقد رأينا بعض الأشياء المثيرة التي يمكن للنموذج أن يفعلها مع الصور والفيديوهات. YOLOv11 هو نموذج قوي ومتنوع للمهام الفيديوجرافية. ميزاته المحسونة وأعلى سرعة ودقة تجعله تحسين كبير بالنسبة لأباقائه سلفه.
في الختام، YOLOv11 هو خطوة كبيرة للأمام في تحديد الأجسام والمهام الفيديوجرافية. مع تصميمه الأفضل والأسرع والدقة المحسونة، فهو من الأصلح للعديد من الاستخدامات — تحديد فوري على الأجهزة الصغيرة أو تحليل أكثر تفاصيلًا في السحابة. قدرته على العمل بسلاسة مع الأنظمة الحالية تعني أن الشركات يمكن لها أن تدمجه بسهولة في عملياتها اليومية، سواء كان في الزراعة، الأمن أو الروبوتات. تتكامل ميزات YOLOv11 المرنة والأداء لتكون أداة قوية لأي شخص يتعامل مع تحديات المنظور الحاسوبي.
ومع ذلك، هذه جزء 1 من التورية، وفي جزء 2، سنتعلم كيفية تنقيح وتدريب النموذج للتحديد الشخصي على مجموعة بيانات خاصة.
المراجعات
- مصادر الصور المستخدمة
- Ultralytics YOLO11
- تمويل نموذج UltraLytics
- Github رسمي YOLOv11
Source:
https://www.digitalocean.com/community/tutorials/what-is-new-with-yolo