













數據科學家早期開始學習SQL是完全可以理解的,考慮到表格信息的普遍性和高实用性。然而,还有其他成功的數據庫格式,例如圖形數據庫,用來存放不能適合關係SQL數據庫的互联數據。在這個教程中,我們將學習關於Neo4j,一個流行的圖形數據庫管理系統,你可以在Python中使用它來創建、管理以及查詢圖形數據庫。
圖形數據庫是什麼?
在談論Neo4j之前,讓我們花一点時間更好地理解圖形數據庫。我們有一篇完整的文章解釋圖形數據庫是什麼,因此我們将在這裡簡要概述關鍵點。
圖形數據庫是一種NoSQL數據庫(它們不使用SQL)設計用來管理連接到數據。與使用表和行的傳統關聯數據庫不同,圖形數據庫使用由以下組成的圖結構:
- 節點(实体)如人、地點、概念
- 邊界(關係) 將不同的節點連接起來,例如 個人 居住在 一個地方,或是 一名足球运动员 在 比赛中进球。
- 屬性 (節點/邊界的屬性)例如一个人的年龄,或者在比赛中进球的时间。
这种结构使得图数据库在处理社交网络、推荐、欺诈检测等领域的相互关联数据方面理想,通常在查询效率上优于关系型数据库。以下是用于足球数据集的示例图数据库的结构:
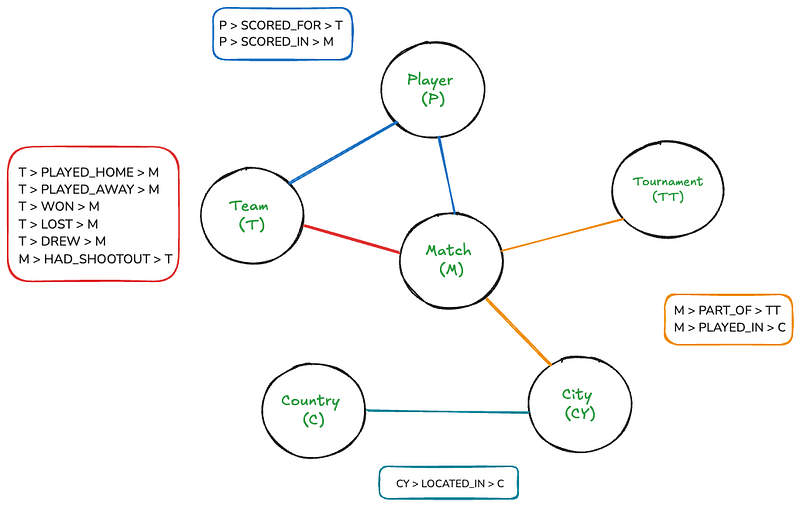
即使這個圖表對人類來說相對直觀,但如果在畫布上繪製,可能會變得相当複雜。但是,透過 Neo4j,浏览這個圖表將像寫簡單的SQL 連接一樣直觀。
該圖有六個節點:匹配、團隊、比賽、球員、國家和城市。矩形列出了節點之間的關係。还有一些節點和關係屬性:
- 對戰:日期,主隊得分,客隊得分
- 球隊:名稱
- 球員:名稱
- 比賽:名稱
- 城市:名稱
- 國家:名稱
- 得分, 射進:分鐘, 自家球門, 十二碼
- 曾有点球大战:勝者, 第一位射门球員
此架構容許我們表示:
- 所有比賽及其比分、日期和地點
- 參與每場比賽的球隊(主場和客場)
- 射進球的球員,包括像是分鐘、烏龙球和罰球等詳細資料
- 比賽所属的賽事
- 比賽举行的都市和國家
- 射擊比賽資訊,包括得獎者和首位射手(有情況下)
該架构捕捉了地點的阶层性(城市在國家內)以及各種实体之間的關係(例如,團隊在比賽中對戰,球員在比賽中為團隊射進球)。
這種結構允許靈活的查找,例如尋找兩支球隊之间的所有比賽、一個球員射進的所有球,或特定比賽或地點的所有比賽。
但我們不要超前。首先,Neo4j是什麼以及為什麼使用它?
Neo4j是什麼?
Neo4j是圖形數據庫管理领域的佼佼者,以其強大的功能和多用途著稱。
Neuro4j 核心使用了原生圖形儲存,這種儲存方式針對圖形操作進行了高度優化。它在處理複雜關係方面的效率,使其在連接數據方面遠超市面上的傳統數據庫。Neo4j 的擴展性 truly impressive:它能輕鬆處理十億個節點和關係,使其適合大小项目和大型企业。
Neuro4j 的另一項关键特點是數據完整性。它確保完全符合 ACID (原子性, 一致性, 孤立性, 持久性) 標準,提供交易中的可靠性和一致性。
谈到交易,它的查询语言 Cypher 提供了一种非常直观和声明性的语法,旨在应对图模式。因此,其语法被昵称为“ASCII 艺术”。如果你熟悉 SQL,学习 Cypher 不会有问题。
使用Cypher,可以輕鬆新增節點、關係或屬性,而不需擔心會损坏既有查詢或架構。它能夠適應現代開發環境快速變化的需求。
Neo4j拥有充滿活力的生態系統支持。它有廣泛的文檔、全面的圖形可视化工具、活躍的社區以及與如Python、Java和JavaScript等其他程式語言的整合。
設定Neo4j和Python環境
在我們開始使用Neo4j之前,需要設定我們的環境。本節將引导您通過創建一個雲端實例以主持Neo4j數據庫、設定Python環境,以及建立兩者之間的連接。
未安裝Neo4j
如果你希望與Neo4j的本地圖形數據庫合作,那麼你將需要 下載並在本機安裝它,以及像Java這樣的依賴關係。但是在大部分情況下,你將與某個雲環境中存在的现有遠程Neo4j數據庫互動。
因此,我們不會在我們的系統上安裝Neo4j。取而代之的是,我們將在 Aura上創建一個免费的數據庫實例,這是Neo4j的全托管雲服務。然後,我們將使用neo4j Python客戶端庫來連接到這個數據庫並用數據填充它。
創建Neo4j Aura數據庫實例
要在Aura DB上托管一個免费的圖形數據庫,請訪問 其產品頁面並點選「免费開始」。
註冊後,您將看到可用的計劃,您應該選擇免費選項。然後,您將獲得一個新實例以及用於連接的用戶名和密碼:
複製您的密碼、用戶名和連接URI。
然後,創建一個新的工作目錄和一個.env文件來存儲您的凭據:
$ mkdir neo4j_tutorial; cd neo4j_tutorial $ touch .env
將以下內容粘贴到文件內:
NEO4J_USERNAME="YOUR-NEO4J-USERNAME" NEO4J_PASSWORD="YOUR-COPIED-NEO4J-PASSWORD" NEO4J_CONNECTION_URI="YOUR-COPIED-NEO4J-URI"
設定Python環境
現在,我們將在一個新的Conda環境中安裝neo4j Python客戶端庫:
$ conda create -n neo4j_tutorial python=3.9 -y $ conda activate neo4j_tutorial $ pip install ipykernel # 將環境添加到Jupyter $ ipython kernel install --user --name=neo4j_tutorial $ pip install neo4j python-dotenv tqdm pandas
該命令亦會安裝 ipykernel 函式庫,並利用它將新建立的Conda環境添加到Jupyter作為一個核心。然後,我們安裝 neo4j Python客戶端以與Neo4j數據庫進行互動,以及 python-dotenv 以安全地管理我們的Neo4j憑據。
使用足球數據填充AuraDB實例
數據吸入圖形數據庫是一個複雜的過程,需要對Cypher基礎知識有所了解。由於我們尚未學習Cypher的基本概念,您將使用我為文章準備的Python腳本,該腳本將自動吸入现实世界的歷史足球數據。腳本將使用您儲存的凭证來連接您的AuraDB實例。
足球數據來自 Kaggle 上的一個國際足球比賽數據集,該比賽從 1872 年至 2024 年不等。這些數據以 CSV 格式提供,因此腳本將其拆分並使用 Cypher 和 Neo4j 將其轉換為圖形格式。在文章的最後部分,當我們对这些技術感到足夠舒適時,我們將逐行查看腳本,让您了解如何將表格信息轉換為圖形。
以下是運行命令的指示(請確保您已設定AuraDB實例並將您的憑據存儲在.env文件中,該文件位於您的工作目錄內):
$ wget https://raw.githubusercontent.com/BexTuychiev/medium_stories/refs/heads/master/2024/9_september/3_neo4j_python/ingest_football_data.py $ python ingest_football_data.py
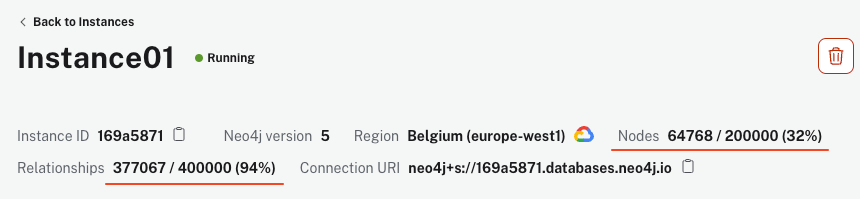
脚本運行時間可能取決於您的電腦和互聯網連接,但它完成後,您的AuraDB實例必須顯示超過64k節點和340k關係。
從Python連接到Neo4j
現在,我們準備連接到我們的Aura DB實例。首先,我們將從.env文件中使用dotenv讀取我們的憑据:
import os from dotenv import load_dotenv load_dotenv() NEO4J_USERNAME = os.getenv("NEO4J_USERNAME") NEO4J_PASSWORD = os.getenv("NEO4J_PASSWORD") NEO4J_URI = os.getenv("NEO4J_URI")
現在,讓我們建立一個連接:
from neo4j import GraphDatabase uri = NEO4J_URI username = NEO4J_USERNAME password = NEO4J_PASSWORD driver = GraphDatabase.driver(uri, auth=(username, password)) try: driver.verify_connectivity() print("Connection successful!") except Exception as e: print(f"Failed to connect to Neo4j: {e}")
輸出:
Connection successful!
以下是代碼的解釋:
- 我們從
neo4j引入GraphDatabase來與 Neo4j 進行互動。 - 我們使用之前載入的環境變量來設定我們的連接 (
uri,username,password). - 我們使用
GraphDatabase.driver()建立一個 driver 物件,建立與我們的 Neo4j 數據庫的連接。 - 在
with區塊下,我們使用verify_connectivity()這個函數來檢查是否已經建立了連接。預設情況下,verify_connectivity()如果連接成功則不返回任何東西。
教程結束後,呼叫driver.close()來結束连线並釋放資源。 Driver 物件的創建成本較高,因此您應該仅为您的應用程序創建一個物件。
Cypher 查詢語言 essentials
Cypher 的語法設計旨在 intuitive 並能直觀地表示圖結構。它依賴於以下類似的 ASCII 藝術語法:
(nodes)-[:CONNECT_TO]->(other_nodes)
讓我們分解這個一般查詢模式的主要组成部分:
1. 節點
在Cypher查詢中,括號内的關鍵字表示節點名稱。例如,(玩家) 會匹配所有的「玩家」節點。幾乎總是,節點名稱會透過別名來引用,以使查詢更易於閱讀、撰寫和精簡。您可以通过在節點名稱前放置冒號來為節點名稱添加別名:(m: Match).
在括號內,您可以使用类似于詞典的語法指定一個或多個節點屬性,以進行精確匹配。例如:
// 所有「世界杯」比賽節點 (t:Tournament {name: "FIFA World Cup"})
節點屬性照样子寫,而您希望它們拥有的值必須是一個字符串。
2. 關係
關係將節點相互連接,它們被方括號和箭頭包圍:
// 匹配那些是某些比賽的一部分的節點 (m:Match)-[PART_OF]->(t:Tournament)
您也可以為關係添加別名和屬性:
// 匹配巴西參加了点球大战,並且是第一位射門者 (p:Player) - [r:SCORED_FOR {minute: 90}] -> (t:Team)
關係被箭頭包圍-[關係]->. 同樣地,您可以在大括號內包含別名屬性。例如:
// 所有射進自家球門的球員 (p:Player)-[r:SCORED_IN {own_goal: True}]->(m:Match)
3. 子在句
就像COUNT(*) FROM table_name 在 SQL 中沒有SELECT 子句的話不會返回任何东西,(node) - [RELATIONSHIP] -> (node) 也無法取得任何結果。因此,就像在 SQL 中一樣,Cypher 也有不同的子句來結構化您的查詢邏輯,就像 SQL 一樣:
MATCH:圖中的模式匹配WHERE:過濾結果RETURN:指定結果集中要包含的内容CREATE:創建新的節點或關係MERGE:建立唯一節點或關係DELETE:移除節點、關係或屬性SET:更新標籤和屬性
以下是一個示例查詢,展示了這些概念:
MATCH (p:Player)-[s:SCORED_IN]->(m:Match)-[PART_OF]->(t:Tournament) WHERE t.name = "FIFA World Cup" AND s.minute > 80 AND s.own_goal = True RETURN p.name AS Player, m.date AS MatchDate, s.minute AS GoalMinute ORDER BY s.minute DESC LIMIT 5
此查詢找出在世界杯比賽中80分鐘後mark scored own goals的球員。它幾乎像SQL一樣,但其SQL等效涉及至少一個JOIN。
使用Neo4j Python Driver分析圖形數據庫
使用execute_query
Neo4j Python driver是通過Python應用程序與Neo4j實例交互的官方庫。它驗證並通過plain Python strings寫成的Cypher查詢與Neo4j服務器進行通信,並以 unified format返回結果。
一切都是從使用GraphDatabase類別來創建一個驅動物件開始。從那裡,我們可以使用execute_query方法來傳送查詢。
對於我們的第一個查詢,讓我們問一個有趣的问题: — 哪支球隊赢得了最多的世界杯比賽?
# 返回赢得最多世界杯比賽場次的主力球隊 query = """ MATCH (t:Team)-[:WON]->(m:Match)-[:PART_OF]->(:Tournament {name: "FIFA World Cup"}) RETURN t.name AS Team, COUNT(m) AS MatchesWon ORDER BY MatchesWon DESC LIMIT 1 """ records, summary, keys = driver.execute_query(query, database_="neo4j")
首先,讓我們拆解查詢:
- The
MATCH關閉定了我們想要的格局:團隊 -> 勝 -> 比賽 -> 賽事的一部份 RETURN係 SQL 内SELECT語句嘅替換,我地可以返回返回節點同關係嘅屬性。喺呢個語句入面,你仲可以任用 任何支援嘅聚合函數 喺 Cypher 度使用。上面,我地用到COUNT.ORDER BY語句的运作方式與 SQL 相同。LIMIT用來控制在返回的記錄長度。
在我們將查詢定義為多行字串後,我們將它傳遞給駕駛程式對象的execute_query()方法,並指定數據庫名稱(預設為neo4j)。輸出總是包含三個物件:
records:一系列的Record物件,每個代表結果集的一行。每個Record是一個類似命名元組的物件,您可以透過名稱或索引來訪問字段。摘要:一個包含有關查詢執行 metadata 的 ResultSummary 物件,如查詢統計和時間信息。鍵值:表示結果集中的列名的字符串列表。
我們稍後會觸及summary物件,因為我們主要负责記錄,這些記錄含有Record物件。我們可以通過調用它們的data()方法來獲取它們的資訊:
for record in records: print(record.data())
输出:
{'Team': 'Brazil', 'MatchesWon': 76}
結果正確地顯示巴西赢得了最多的世界杯比賽。
傳遞查詢參數
我們上一次的查詢不可重用,因為它只找到世界杯史上最成功的球隊。那麼,如果我们想找到歐盟史上最成功的球隊怎麼办?
這就是查詢參數的作用:
query = """ MATCH (t:Team)-[:WON]->(m:Match)-[:PART_OF]->(:Tournament {name: $tournament}) RETURN t.name AS Team, COUNT(m) AS MatchesWon ORDER BY MatchesWon DESC LIMIT $limit """
在這個版本的查詢中,我們使用$符號引入了兩個參數:
tournamentlimit
為了將值傳遞給查詢參數,我們在execute_query內使用關鍵詞參數:
records, summary, keys = driver.execute_query( query, database_="neo4j", tournament="UEFA Euro", limit=3, ) for record in records: print(record.data())
输出:
{'Team': 'Germany', 'MatchesWon': 30} {'Team': 'Spain', 'MatchesWon': 28} {'Team': 'Netherlands', 'MatchesWon': 23}
总是在考慮將變動值融入您的查詢時使用查詢參數,這是一種最佳的實踐。這能保護您的查詢不受Cypher注入的攻擊,並讓Neo4j能夠將它們缓存起來。
使用CREATE和MERGE子句寫入數據庫
向既存資料庫寫入新資訊,亦可使用execute_query,但其 query 中需要使用CREATE語句。例如,我們可以建立一個函式以新增一種節點类型 – 團隊教練:
def add_new_coach(driver, coach_name, team_name, start_date, end_date): query = """ MATCH (t:Team {name: $team_name}) CREATE (c:Coach {name: $coach_name}) CREATE (c)-[r:COACHES]->(t) SET r.start_date = $start_date SET r.end_date = $end_date """ result = driver.execute_query( query, database_="neo4j", coach_name=coach_name, team_name=team_name, start_date=start_date, end_date=end_date ) summary = result.summary print(f"Added new coach: {coach_name} for existing team {team_name} starting from {start_date}") print(f"Nodes created: {summary.counters.nodes_created}") print(f"Relationships created: {summary.counters.relationships_created}")
函式 add_new_coach 取五次參數:
- 驅動程式:用來連接到數據庫的 Neo4j 驅動程式物件。
coach_name:要新增的新教練的姓名。team_name:教練將 associat ed 的球隊名稱。start_date:教練開始执教队伍的日期。end_date:教練與队伍建设結束的日期。
函數中的Cypher查詢做了以下事情:
- 與給定的队伍建设名稱匹配现有的Team節點。
- 使用提供的教練名稱創建新的Coach節點。
- 建立Coach與Team節點之間的COACHES關係。
- 設定
start_date和end_date屬性在COACHES關係上。
查詢是使用execute_query方法執行,此方法需要一個查詢字串和一個參數字典。
執行後,函式會列印:
- 一個確認訊息,包含教練和球隊名稱以及開始日期。
- 創建的節點數量(對於新的教練節點應該是1)。
- 創建的關係數量(對於新的
COACHES關係應該是1)。
讓我們為國際足球史上最成功的教練之一,連贏三個大型國際錦標賽(世界盃和兩屆美洲盃)的利昂內爾·斯卡洛尼運行這個:
from neo4j.time import DateTime add_new_coach( driver=driver, coach_name="Lionel Scaloni", team_name="Argentina", start_date=DateTime(2018, 6, 1), end_date=None )
Output: Added new coach: Lionel Scaloni for existing team Argentina starting from 2018-06-01T00:00:00.000000000 Nodes created: 1 Relationships created: 1
在上述片段中,我們使用了DateTime類從neo4j.time模組來正確傳遞日期至我們的Cypher查詢中。這個 模組包含了其他可能有用的時間數據類型,您可以去查看一下。
除了CREATE 之外,還有一個MERGE 語法可以用來創建新的節點和關係。它們的主要差異是:
CREATE總是創建新的節點/關係,有可能會導致重複。MERGE只会在它們不存在時創建節點/關係。
例如,在我們的数据吸入脚本中,你稍后会看到:
- 我們使用
MERGE來避免團隊和球員的重複。 - 我們使用
CREATE對於SCORED_FOR和SCORED_IN關係,因為一位球員在單場比賽中可以射進多個球。 - 這些并不是真正的重複,因為它們有不同的屬性(例如,進球分鐘)。
这种方法在允许多個類似但相互区别的關係同時存在的情況下,確保了數據完整性。
運行自己的事務
當您運行execute_query時,驅動程式會在后台創建一個事務。事務是一個工作單元,它要么完全執行,要么在失敗時回滚。這意味著當您在一個事務中創建數千個節點或關係(這是可能的)並且在途中遇到一些錯誤時,整個事務會失敗而沒有將任何新數據寫入圖形。
為了对每個交易進行更精細的控制,您需要創建會話物件。例如,讓我們使用會話物件創建一個函數來查找給定比賽中排名前K的进球得分:
def top_goal_scorers(tx, tournament, limit): query = """ MATCH (p:Player)-[s:SCORED_IN]->(m:Match)-[PART_OF]->(t:Tournament) WHERE t.name = $tournament RETURN p.name AS Player, COUNT(s) AS Goals ORDER BY Goals DESC LIMIT $limit """ result = tx.run(query, tournament=tournament, limit=limit) return [record.data() for record in result]
首先,我們創建top_goal_scorers函數,該函數接受三個參數,最重要的是一個tx交易物件,該物件將使用會話物件獲得。
with driver.session() as session: result = session.execute_read(top_goal_scorers, "FIFA World Cup", 5) for record in result: print(record)
結果:
{'Player': 'Miroslav Klose', 'Goals': 16} {'Player': 'Ronaldo', 'Goals': 15} {'Player': 'Gerd Müller', 'Goals': 14} {'Player': 'Just Fontaine', 'Goals': 13} {'Player': 'Lionel Messi', 'Goals': 13}
然後,在用session()方法創建的上下文管理器中,我們使用execute_read(),傳遞top_goal_scorers()函數,以及查詢需要的任何參數。
执行力 execute_read 的結果是一個記錄物件清單,正確地顯示了世界盃歷史上的前五名最佳射手,包括米洛斯拉夫·克洛斯、羅纳尔多· Nazario和利昂內爾·梅西等名字。
對於數據導入,execute_read() 的對應功能是 execute_write()。
來說到這邊,我們現在来看看較早時使用的吞噬腳本,以了解如何使用Neo4j Python驱动程序進行數據吞噬。
使用Neo4j Python驱动程序進行數據吞噬
這個 ingest_football_data.py 文件從導入声明和加载必要的CSV文件開始:
import pandas as pd import neo4j from dotenv import load_dotenv import os from tqdm import tqdm import logging # CSV 檔案路徑 results_csv_path = "https://raw.githubusercontent.com/martj42/international_results/refs/heads/master/results.csv" goalscorers_csv_path = "https://raw.githubusercontent.com/martj42/international_results/refs/heads/master/goalscorers.csv" shootouts_csv_path = "https://raw.githubusercontent.com/martj42/international_results/refs/heads/master/shootouts.csv" # 設定日誌 logging.basicConfig(level=logging.INFO) logger = logging.getLogger(__name__) logger.info("Loading data...") # 載入數據 results_df = pd.read_csv(results_csv_path, parse_dates=["date"]) goalscorers_df = pd.read_csv(goalscorers_csv_path, parse_dates=["date"]) shootouts_df = pd.read_csv(shootouts_csv_path, parse_dates=["date"])
這個代碼區塊也設定了一個日誌。接下來的幾行代碼使用dotenv 讀取我的 Neo4j 憑據並創建一個 Driver 物件:
uri = os.getenv("NEO4J_URI") user = os.getenv("NEO4J_USERNAME") password = os.getenv("NEO4J_PASSWORD") try: driver = neo4j.GraphDatabase.driver(uri, auth=(user, password)) print("Connected to Neo4j instance successfully!") except Exception as e: print(f"Failed to connect to Neo4j: {e}") BATCH_SIZE = 5000
由於我們的數據庫中有超過 48k 的匹配项,我們定義了一個BATCH_SIZE 參數以較小的樣本大小引入數據。
然後,我們定義一個叫做create_indexes的函數,該函數接受一個會話物件:
def create_indexes(session): indexes = [ "CREATE INDEX IF NOT EXISTS FOR (t:Team) ON (t.name)", "CREATE INDEX IF NOT EXISTS FOR (m:Match) ON (m.id)", "CREATE INDEX IF NOT EXISTS FOR (p:Player) ON (p.name)", "CREATE INDEX IF NOT EXISTS FOR (t:Tournament) ON (t.name)", "CREATE INDEX IF NOT EXISTS FOR (c:City) ON (c.name)", "CREATE INDEX IF NOT EXISTS FOR (c:Country) ON (c.name)", ] for index in indexes: session.run(index) print("Indexes created.")
Cypher索引是Neo4j中的數據庫結構,它能夠提高查詢效能。它們能夠加速根據特定屬性尋找節點或關係的過程。我們需要它們來:
- 加快查詢執行速度
- 在大型數據集上提高讀取性能
- 有效進行模版匹配
- 实施唯一約束
- 隨著數據庫增長,更好的可擴展性
在我們的案例中,對團隊名稱、對戰ID和玩家名稱建立的索引,當尋找特定實體或跨不同節點類型執行連接時,將有助於我們的查詢運行得更快。為您的數據庫創建此類索引是一種最佳實踐。
接下來,我們有ingest_matches函數。它非常大,所以讓我們逐區段拆解:
def ingest_matches(session, df): query = """ UNWIND $batch AS row MERGE (m:Match {id: row.id}) SET m.date = date(row.date), m.home_score = row.home_score, m.away_score = row.away_score, m.neutral = row.neutral MERGE (home:Team {name: row.home_team}) MERGE (away:Team {name: row.away_team}) MERGE (t:Tournament {name: row.tournament}) MERGE (c:City {name: row.city}) MERGE (country:Country {name: row.country}) MERGE (home)-[:PLAYED_HOME]->(m) MERGE (away)-[:PLAYED_AWAY]->(m) MERGE (m)-[:PART_OF]->(t) MERGE (m)-[:PLAYED_IN]->(c) MERGE (c)-[:LOCATED_IN]->(country) WITH m, home, away, row.home_score AS hs, row.away_score AS as FOREACH(_ IN CASE WHEN hs > as THEN [1] ELSE [] END | MERGE (home)-[:WON]->(m) MERGE (away)-[:LOST]->(m) ) FOREACH(_ IN CASE WHEN hs < as THEN [1] ELSE [] END | MERGE (away)-[:WON]->(m) MERGE (home)-[:LOST]->(m) ) FOREACH(_ IN CASE WHEN hs = as THEN [1] ELSE [] END | MERGE (home)-[:DREW]->(m) MERGE (away)-[:DREW]->(m) ) """ ...
你會 Firstly, you will notice the UNWIND 關鍵詞,用來處理一批數據。它取$batch 參數(這將是我們的 DataFrame 行)並遍歷每一行,讓我們能在一個交易中創建或更新多個節點和關係。這種方法比逐行處理更有效率,特別是對於大數據集。
余下之查詢較熟悉,因為它使用了多個MERGE 語句。然後,我們達到WITH 語句,它使用FOREACH 結構與IN CASE 語句。這些用於根據對戰結果有條件地創建關係。如果主隊获胜,則為主隊創建一個’WON’關係,為客隊創建一個’LOST’關係,反之亦然。平局的場合,兩隊都与比賽建立一個’DREW’關係。
其他功能將 incoming DataFrame 分割成匹配與非匹配,並構建成將傳遞至$batch 查詢參數的數據:
def ingest_matches(session, df): query = """...""" for i in tqdm(range(0, len(df), BATCH_SIZE), desc="Ingesting matches"): batch = df.iloc[i : i + BATCH_SIZE] data = [] for _, row in batch.iterrows(): match_data = { "id": f"{row['date']}_{row['home_team']}_{row['away_team']}", "date": row["date"].strftime("%Y-%m-%d"), "home_score": int(row["home_score"]), "away_score": int(row["away_score"]), "neutral": bool(row["neutral"]), "home_team": row["home_team"], "away_team": row["away_team"], "tournament": row["tournament"], "city": row["city"], "country": row["country"], } data.append(match_data) session.run(query, batch=data)
ingest_goals 和 ingest_shootouts 函數使用類似的結構。然而,ingest_goals 有一些额外的錯誤和缺失值處理。
在腳本的結尾,我們有main()函數,它使用一個會話物件執行所有的吸入函數:
def main(): with driver.session() as session: create_indexes(session) ingest_matches(session, results_df) ingest_goals(session, goalscorers_df) ingest_shootouts(session, shootouts_df) print("Data ingestion completed!") driver.close() if __name__ == "__main__": main()
結論與下一步
我們涵蓋了使用Python與Neo4j圖形資料庫的關鍵方面:
- 圖形資料庫概念與結構
- 設定Neo4j AuraDB
- Cypher查詢語言基礎
- 使用Neo4j Python驅動程式
- 數據攝取和查詢優化
為了進展您的Neo4j之旅, Explore這些資源:
- Neo4j 文档
- Neo4j 圖形數據科學庫
- Neo4j Cypher 手冊
- Neo4j Python Driver 文檔
- 數據工程職業證照
- NoSQL 簡介
- 使用MongoDB的綜合性NoSQL教程
記住,圖形數據庫的威力在於中表示和查詢複雜的關係。繼續嘗試不同的數據模型並探索進階的Cypher功能。