













Cientistas de dados começam a aprender SQL desde cedo. Isso é compreensível, dado a ubiquidade e a alta utilidade das informações tabulares. No entanto, existem outros formatos de banco de dados bem-sucedidos, como os bancos de dados de grafos, para armazenar dados conectados que não se encaixam em um banco de dados SQL relacional. Neste tutorial, vamos aprender sobre o Neo4j, um popular sistema de gerenciamento de banco de dados de grafos que você pode usar para criar, gerenciar e consultar bancos de dados de grafos em Python.
Quais são os Bancos de Dados de Grafos?
Antes de falar sobre o Neo4j, vamos passar um momento para entender melhor os bancos de dados de grafos. Temos um artigo completo explicando o que são os bancos de dados de grafos, então vamos resumir os pontos chave aqui.
Bancos de dados em grafos são um tipo de banco de dados NoSQL (não usam SQL) projetados para gerenciar dados conectados. Ao contrário dos bancos de dados relacionais tradicionais que usam tabelas e linhas, os bancos de dados em grafos utilizam estruturas de grafos compostas por:
- Nós (entidades) como pessoas, lugares, conceitos
- Arestas (relacionamentos) que conectam diferentes nós, como pessoa VIVE EM um local, ou um jogador de futebol MARCOU EM um jogo.
- Propriedades (atributos para nós/arestas) tais como a idade de uma pessoa ou quando o gol foi marcado durante o jogo.
Esta estrutura torna os bancos de dados de grafos ideais para lidar com dados interligados em campos e aplicações como as redes sociais, recomendações, detecção de fraude, etc., frequentemente superando os bancos de dados relacionais em termos de eficiência de consulta. Aqui está a estrutura de um exemplo de banco de dados de grafos para um conjunto de dados de futebol:
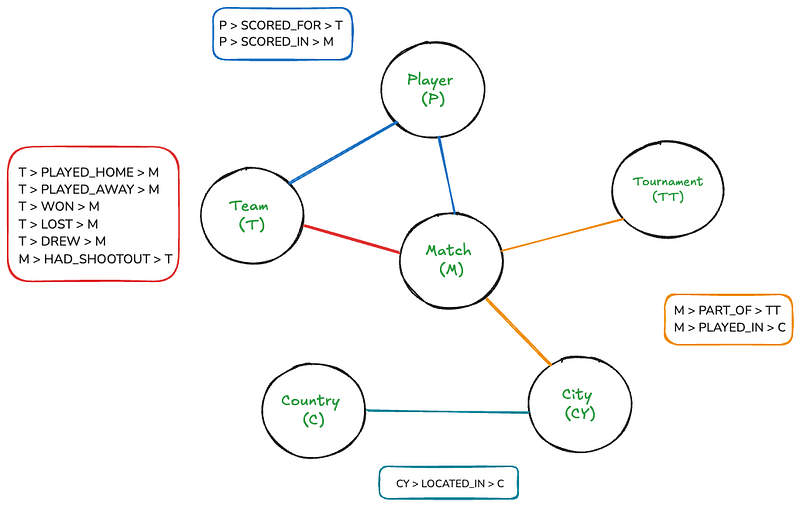
Embora este gráfico represente algo bastante intuitivo para os seres humanos, pode ficar bastante complicado se desenhado em uma tela. Mas, com o Neo4j, percorrer este gráfico será tão direto quanto escrever simples junturas SQL.
O gráfico tem seis nós: Match, Team, Tournament, Player, Country, e City. Os retângulos listam as relações que existem entre os nós. Também há algumas propriedades de nós e relações:
- Competição: data, golos_casa, golos_fora
- Time: nome
- Jogador: nome
- Torneio: nome
- Cidade: nome
- País: nome
- PONTUAÇÃO, GOLS_FEITOS: minuto, gol_propio, pênalti
- TIVE_PENALTIS: vencedor, primeiro_atirador
Este esquema permite que representemos:
- Todos os jogos com suas pontuações, datas e locais
- Times participantes em cada jogo (casa e fora)
- Jogadores que marcaram gols, incluindo detalhes como o minuto, gols contra e pênaltis
- Torneios que os jogos fazem parte
- Cidades e países onde os jogos são jogados
- Informações do duelo, incluindo vencedores e primeiros atiradores (quando disponíveis)
O esquema captura a natureza hierárquica dos locais (Cidade dentro do País) e as várias relações entre as entidades (por exemplo, Times jogando Partidas, Jogadores marcando para Times em Partidas).
Esta estrutura permite consultas flexíveis, como encontrar todas as partidas entre dois times, todos os gols marcados por um jogador ou todas as partidas em um torneio ou local específico.
Mas não nos antecipemos. Primeiramente, o que é o Neo4j e por que usá-lo?
O que é o Neo4j?
Neo4j, o nome líder no mundo da gestão de BD de grafos, é conhecido por suas poderosas funcionalidades e versatilidade.
No seu núcleo, o Neo4j utiliza armazenamento de grafo nativo, o qual é altamente otimizado para executar operações de grafo. Sua eficiência em lidar com relações complexas o torna superior a bancos de dados tradicionais para dados conectados. A escalabilidade do Neo4j é impressionante: pode manipular bilhões de nós e relações com facilidade, tornando-se adequado para projetos pequenos e grandes empresas.
Outro aspecto chave do Neo4j é a integridade dos dados. Ele garante total conformidade ACID (Atomicidade, Consistência, Isolamento, Durabilidade), fornecendo confiabilidade e consistência nas transações.
Falando em transações, seu linguagem de consulta, o Cypher, oferece uma sintaxe intuitiva e declarativa projetada para padrões de grafo. Por esse motivo, sua sintaxe recebeu o apelido de “ASCII art”. Aprender Cypher não será um problema, especialmente se você está familiarizado com SQL.
Com o Cypher, é fácil adicionar novos nós, relações ou propriedades sem se preocupar em quebrar consultas ou esquemas existentes. É adaptável aos requisitos rapidamente mudanças dos ambientes de desenvolvimento modernos.
O Neo4j tem um apoio de ecossistema vibrante. Possui documentação extensa, ferramentas completas para visualizar grafos, comunidade ativa e integrações com outras linguagens de programação como Python, Java e JavaScript.
Configurando o Neo4j e um Ambiente Python
Antes de mergulharmos no trabalho com o Neo4j, precisamos configurar nosso ambiente. Esta seção guiará você através da criação de uma instância na nuvem para hospedar bancos de dados Neo4j, configurar um ambiente Python e estabelecer uma conexão entre os dois.
Não instale o Neo4j
Se você deseja trabalhar com bases de dados de grafos locais no Neo4j, então você precisará baixar e instalá-lo localmente, juntamente com suas dependências, como o Java. Mas na maioria dos casos, você interagirá com uma base de dados Neo4j remota existente the um ambiente de nuvem.
Por esta razão, não instalaremos o Neo4j no nosso sistema. Em vez disso, criaremos uma instância de banco de dados gratuita em Aura, o serviço de nuvem totalmente gerenciado do Neo4j. Em seguida, usaremos aneo4j biblioteca de cliente Python para se conectar a este banco de dados e preencê-lo com dados.
Criando uma instância de banco de dados Neo4j Aura
Para hospedar uma base de dados gráfica gratuita no Aura DB, visite página do produto e clique em “Iniciar Gratuitamente.”
Após se registrar, você será apresentado com os planos disponíveis e deve escolher a opção gratuita. Em seguida, você receberá uma nova instância com um nome de usuário e senha para se conectar:
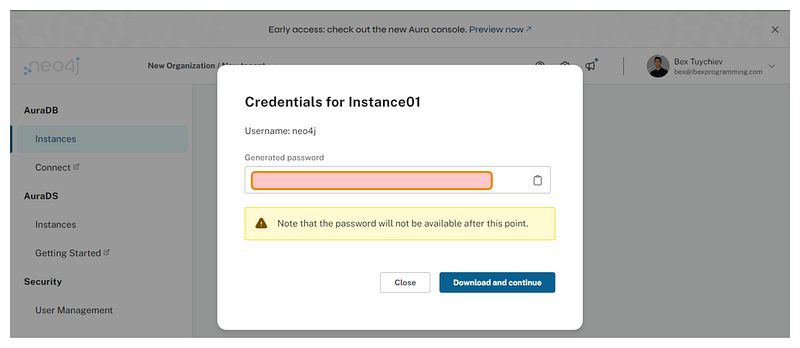
Copie sua senha, nome de usuário e a URI de conexão.
Então, crie um novo diretório de trabalho e um arquivo .env para armazenar suas credenciais:
$ mkdir neo4j_tutorial; cd neo4j_tutorial $ touch .env
Coloque o seguinte conteúdo dentro do arquivo:
NEO4J_USERNAME="YOUR-NEO4J-USERNAME" NEO4J_PASSWORD="YOUR-COPIED-NEO4J-PASSWORD" NEO4J_CONNECTION_URI="YOUR-COPIED-NEO4J-URI"
Configurando o Ambiente Python
Agora, instale a biblioteca de cliente neo4j em um novo ambiente Conda:
$ conda create -n neo4j_tutorial python=3.9 -y $ conda activate neo4j_tutorial $ pip install ipykernel # Para adicionar o ambiente ao Jupyter $ ipython kernel install --user --name=neo4j_tutorial $ pip install neo4j python-dotenv tqdm pandas
Os comandos também instalam ipykernel biblioteca e a usam para adicionar o ambiente Conda recém-criado ao Jupyter como um kernel. Em seguida, instalamos o cliente neo4j em Python para interagir com bancos de dados Neo4j e o python-dotenv para gerenciar nossas credenciais Neo4j de forma segura.
Preenchendo uma instância AuraDB com dados de futebol.
A ingestão de dados em uma base de dados de grafos é um processo complicado que requer conhecimento dos fundamentos do Cypher. Uma vez que ainda não aprendemos sobre os básicos do Cypher, você usará um script Python que preparei para o artigo que irá ingestir automaticamente dados históricos de futebol reais. O script usará as credenciais que você armazenou para se conectar à sua instância do AuraDB.
A fonte de dados de futebol vem de este conjunto de dados do Kaggle sobre partidas internacionais de futebol disputadas entre 1872 e 2024. Os dados estão disponíveis em formato CSV, então o script os analisa e os converte em formato gráfico usando Cypher e Neo4j. No final do artigo, quando estivermos suficientemente confortáveis com estas tecnologias, vamos passar o script linha por linha para que você entenda como converter informações tabulares em um gráfico.
Aqui estão os comandos para executar (certifique-se de ter configurado sua instância do AuraDB e armazenado suas credenciais em um .env arquivo em seu diretório de trabalho):
$ wget https://raw.githubusercontent.com/BexTuychiev/medium_stories/refs/heads/master/2024/9_september/3_neo4j_python/ingest_football_data.py $ python ingest_football_data.py
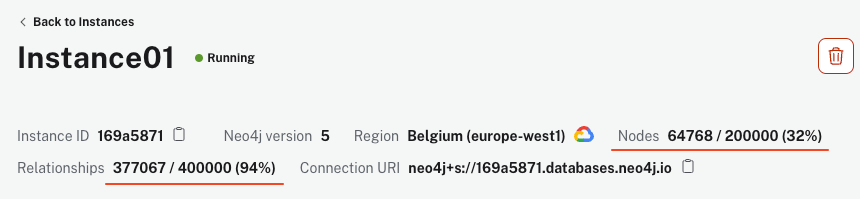
O script pode demorar alguns minutos para ser executado, dependendo da sua máquina e conexão com a Internet. No entanto, assim que terminar, sua instância do AuraDB deve mostrar mais de 64k nós e 340k relações.
Conectando ao Neo4j a partir do Python
Agora, estamos prontos para conectar-nos à nossa instância de BD Aura. Primeiro, vamos ler nossas credenciais do arquivo .env usando dotenv:
import os from dotenv import load_dotenv load_dotenv() NEO4J_USERNAME = os.getenv("NEO4J_USERNAME") NEO4J_PASSWORD = os.getenv("NEO4J_PASSWORD") NEO4J_URI = os.getenv("NEO4J_URI")
Agora, vamos estabelecer uma conexão:
from neo4j import GraphDatabase uri = NEO4J_URI username = NEO4J_USERNAME password = NEO4J_PASSWORD driver = GraphDatabase.driver(uri, auth=(username, password)) try: driver.verify_connectivity() print("Connection successful!") except Exception as e: print(f"Failed to connect to Neo4j: {e}")
Resultado:
Connection successful!
Aqui está a explicação do código:
- Nós importamos
GraphDatabasedoneo4jpara interagir com o Neo4j. - Usamos as variáveis de ambiente carregadas previamente para configurar nossa conexão (
uri,username,password). - Criamos um objeto de driver usando
GraphDatabase.driver(), estabelecendo uma conexão com o nosso banco de dados Neo4j. - Por baixo de um bloco
with, usamos a funçãoverify_connectivity()para verificar se uma conexão foi estabelecida. Por padrão,verify_connectivity()não retorna nada se a conexão for bem-sucedida.
Assim que o tutorial terminar, chame driver.close() para encerrar a conexão e liberar recursos. Os objetos driver são caros de criar, então você só deveria criar um único objeto para sua aplicação.
Essenciais da Linguagem de Consulta Cypher
A sintaxe do Cypher é projetada para ser intuitiva e representativa visualmente das estruturas de grafos. Ela se baseia na seguinte sintaxe do tipo ASCII-art:
(nodes)-[:CONNECT_TO]->(other_nodes)
Vamos quebrar os componentes chave deste padrão geral de consulta:
1. Nós
Em uma consulta Cypher, uma palavra-chave entre parêntesis representa o nome de um nó. Por exemplo, (Jogador) encontra todos os nós de Jogador. Quase sempre, os nomes de nós são referenciados com aliases para tornar as consultas mais legíveis, fáceis de escrever e compactas. Você pode adicionar um alias the um nome de nó colocando um ponto e vírgula antes dele: (m:Partida).
Dentro dos parêntesis, você pode especificar uma ou mais propriedades de nó para um encontro preciso usando uma sintaxe semelhante a um dicionário. Por exemplo:
// Todos os nós de torneio que são a Copa do Mundo FIFA (t:Tournament {name: "FIFA World Cup"})
As propriedades de nós são escritas como estão, enquanto o valor que você quer que eles tenham deve ser uma string.
2. Relações
Relações conectam nós entre si, e são envolvidas com colchetes e setas:
// Conecta nós que são PART_OF algum torneio (m:Match)-[PART_OF]->(t:Tournament)
Você pode adicionar aliases e propriedades às relações também:
// Conecta que o Brasil participou de uma cobrança de pênaltis e foi o primeiro a atirar (p:Player) - [r:SCORED_FOR {minute: 90}] -> (t:Team)
Relacionamentos são envolvidos com setas-[RELACIONAMENTO]->. Novamente, você pode incluir propriedades de aliases dentro de chaves. Por exemplo:
// Todos os jogadores que marcaram um gol contra (p:Player)-[r:SCORED_IN {own_goal: True}]->(m:Match)
3. Cláusulas
Assim como COUNT(*) FROM table_name não retornaria nada sem uma cláusula SELECT em SQL, (nó) - [RELACIONAMENTO] -> (nó) não traria nenhum resultado. Assim, tal como em SQL, o Cypher tem diferentes cláusulas para estruturar sua lógica de consulta:
CASAMENTO: Correspondência de padrões no gráficoONDE: Filtros nos resultadosRETORNAR: Especificar o que incluir no conjunto de resultadosCRIAR: Criar novos nós ou relaçõesFUSÃO: Criando nós ou relações únicosAPAGAR: Removendo nós, relações ou propriedadesDEFINIR: Atualizando rótulos e propriedades
Aqui está uma consulta de exemplo que demonstra estes conceitos:
MATCH (p:Player)-[s:SCORED_IN]->(m:Match)-[PART_OF]->(t:Tournament) WHERE t.name = "FIFA World Cup" AND s.minute > 80 AND s.own_goal = True RETURN p.name AS Player, m.date AS MatchDate, s.minute AS GoalMinute ORDER BY s.minute DESC LIMIT 5
Esta consulta encontra todos os jogadores que marcaram gols contra em partidas da Copa do Mundo após o minuto 80. Ela se parece quase com SQL, mas a versão SQL equivalente envolve pelo menos uma JUNÇÃO.
Usando o Driver Neo4j para Python para Análise de um Banco de Dados de Grafos
Executando consultas com execute_query
O driver Neo4j para Python é a biblioteca oficial que interage com uma instância Neo4j através de aplicativos Python. Ele verifica e comunica consultas Cypher escritas em strings de Python simples com um servidor Neo4j e recupera os resultados em um formato unificado.
Tudo começa criando um objeto de driver com a GraphDatabase classe. A partir daí, podemos começar a enviar consultas usando o execute_query método.
Para nossa primeira consulta, vamos fazer uma pergunta interessante: Quem venceu o maior número de partidas da Copa do Mundo?
# Retorna a equipe que venceu o maior número de partidas da Copa do Mundo query = """ MATCH (t:Team)-[:WON]->(m:Match)-[:PART_OF]->(:Tournament {name: "FIFA World Cup"}) RETURN t.name AS Team, COUNT(m) AS MatchesWon ORDER BY MatchesWon DESC LIMIT 1 """ records, summary, keys = driver.execute_query(query, database_="neo4j")
Primeiro, vamos descompactar a consulta:
- O
MATCHpróximo define o padrão que queremos: Equipe -> Vitórias -> Partida -> Parte de -> Torneio - RETURN é o equivalente ao comando SQL SELECT, onde podemos retornar as propriedades dos nós e relações retornados. Nesta cláusula, você também pode usar qualquer função de agregação suportada no Cypher. Acima, estamos usando
COUNT. ORDER BYcláusula funciona de forma semelhante à de SQL.LIMITé usado para controlar o tamanho dos registros retornados.
Após definirmos a consulta como uma string multilinha, passamos-a para o execute_query() método do objeto driver e especificamos o nome do banco de dados (o padrão é neo4j). A saída sempre contém três objetos:
records: Uma lista de objetos Record, cada um representando uma linha no conjunto de resultados. Cada Record é um objeto类似 named tuple onde você pode acessar os campos por nome ou índice.sumário: Um objeto ResultSummary contendo metadados sobre a execução da consulta, como estatísticas de consulta e informações de tempo.chaves: Uma lista de strings representando os nomes das colunas no conjunto de resultados.
Veremos o objeto sumário posteriormente, pois estamos principalmente interessados em registros, que contêm objetos Record. Podemos recuperar suas informações chamando o método data():
for record in records: print(record.data())
Resultado:
{'Team': 'Brazil', 'MatchesWon': 76}
O resultado corretamente mostra que o Brasil venceu a maioria dos jogos da Copa do Mundo.
Passando parâmetros de consulta
Nossa última consulta não é reutilizável, já que ela apenas encontra o time mais bem-sucedido da história da Copa do Mundo. O que acontece se quisermos encontrar o time mais bem-sucedido da história do Euro?
É aqui que entram os parâmetros de consulta:
query = """ MATCH (t:Team)-[:WON]->(m:Match)-[:PART_OF]->(:Tournament {name: $tournament}) RETURN t.name AS Team, COUNT(m) AS MatchesWon ORDER BY MatchesWon DESC LIMIT $limit """
Nesta versão da consulta, introduzimos dois parâmetros usando o símbolo $:
tournamentlimit
Para passar valores aos parâmetros da consulta, usamos argumentos nomeados dentro de execute_query:
records, summary, keys = driver.execute_query( query, database_="neo4j", tournament="UEFA Euro", limit=3, ) for record in records: print(record.data())
Saída:
{'Team': 'Germany', 'MatchesWon': 30} {'Team': 'Spain', 'MatchesWon': 28} {'Team': 'Netherlands', 'MatchesWon': 23}
Sempre é recomendado usar parâmetros de consulta sempre que você estiver considerando a ingestão de valores que mudam em suas consultas. Esta melhor prática protege suas consultas contra injeções de Cypher e permite que o Neo4j as cache.
Escrevendo em bancos de dados com cláusulas CREATE e MERGE
Gravar novas informações em um banco de dados existente é feito de forma semelhante com execute_query mas usando uma CREATE cláusula na consulta. Por exemplo, vamos criar uma função que adicionará um novo tipo de nó – treinadores de equipe:
def add_new_coach(driver, coach_name, team_name, start_date, end_date): query = """ MATCH (t:Team {name: $team_name}) CREATE (c:Coach {name: $coach_name}) CREATE (c)-[r:COACHES]->(t) SET r.start_date = $start_date SET r.end_date = $end_date """ result = driver.execute_query( query, database_="neo4j", coach_name=coach_name, team_name=team_name, start_date=start_date, end_date=end_date ) summary = result.summary print(f"Added new coach: {coach_name} for existing team {team_name} starting from {start_date}") print(f"Nodes created: {summary.counters.nodes_created}") print(f"Relationships created: {summary.counters.relationships_created}")
A função add_new_coach recebe cinco parâmetros:
- driver: O objeto driver Neo4j usado para se conectar à base de dados.
coach_name: O nome do novo treinador a ser adicionado.team_name: O nome da equipe com a qual o treinador será associado.data_inicio: A data em que o treinador começa a treinar a equipe.data_fim: A data em que o treinador termina seu mandato com a equipe.
A consulta Cypher na função faz o seguinte:
- Corresponde a um nó de Equipe existente com o nome de equipe fornecido.
- Cria um novo nó de Treinador com o nome do treinador fornecido.
- Cria uma relação COACHES entre os nós de Treinador e Equipe.
- Define as propriedades
start_dateeend_datena relaçãoCOACHES.
A consulta é executada usando o execute_query método, que recebe a string da consulta e um dicionário de parâmetros.
Após a execução, a função imprime:
- Uma mensagem de confirmação com os nomes do treinador e da equipe e a data de início.
- O número de nós criados (deve ser 1 para o novo nó Coach).
- O número de relacionamentos criados (deve ser 1 para o novo relacionamento
COACHES).
Vamos colocar em prática com um dos treinadores de futebol internacionais mais bem sucedidos da história, Lionel Scaloni, que ganhou três torneios internacionais consecutivos de grande importância (Copa do Mundo e duas Copas América):
from neo4j.time import DateTime add_new_coach( driver=driver, coach_name="Lionel Scaloni", team_name="Argentina", start_date=DateTime(2018, 6, 1), end_date=None )
Output: Added new coach: Lionel Scaloni for existing team Argentina starting from 2018-06-01T00:00:00.000000000 Nodes created: 1 Relationships created: 1
No trecho acima, estamos usando a classe DateTime do módulo neo4j.time para passar uma data corretamente em nossa consulta Cypher. O módulo contém outros tipos de dados temporais úteis que você pode verificar.
Além de CREATE, há também a cláusula MERGE para criar novos nós e relações. Sua principal diferença é:
CREATEsempre cria novos nós/relações, o que pode resultar em duplicatas.MERGEcria nós/relacionamentos apenas se eles ainda não existirem.
Por exemplo, em nosso script de ingestão de dados, como você verá mais tarde:
- Nós usamos
MERGEpara equipes e jogadores para evitar duplicatas. - Usamos
CREATEparaSCORED_FOReSCORED_INrelações porque um jogador pode marcar várias vezes em um único jogo. - Esses não são verdadeiros duplicatas, pois eles têm propriedades diferentes (por exemplo, minuto de gol).
Esta abordagem garante a integridade dos dados enquanto permite múltiplas relações semelhantes, mas distintas.
Executando suas próprias transações
Quando você executa execute_query, o driver cria uma transação internamente. Uma transação é uma unidade de trabalho que é executada por completo ou revertida em caso de falha. Isso significa que, quando você está criando milhares de nós ou relações em uma única transação (é possível) e ocorre algum erro no meio, toda a transação falha sem gravar quaisquer novos dados no grafo.
Para ter um controle mais fino sobre cada transação, você precisa criar objetos de sessão. Por exemplo, vamos criar uma função para encontrar as K maiores pontuações de gols em um torneio given usando um objeto de sessão:
def top_goal_scorers(tx, tournament, limit): query = """ MATCH (p:Player)-[s:SCORED_IN]->(m:Match)-[PART_OF]->(t:Tournament) WHERE t.name = $tournament RETURN p.name AS Player, COUNT(s) AS Goals ORDER BY Goals DESC LIMIT $limit """ result = tx.run(query, tournament=tournament, limit=limit) return [record.data() for record in result]
Primeiro, criamos a função top_goal_scorers que aceita três parâmetros, o mais importante sendo o objeto de transação tx que será obtido usando um objeto de sessão.
with driver.session() as session: result = session.execute_read(top_goal_scorers, "FIFA World Cup", 5) for record in result: print(record)
Saída:
{'Player': 'Miroslav Klose', 'Goals': 16} {'Player': 'Ronaldo', 'Goals': 15} {'Player': 'Gerd Müller', 'Goals': 14} {'Player': 'Just Fontaine', 'Goals': 13} {'Player': 'Lionel Messi', 'Goals': 13}
Então, sob um gerenciador de contexto criado com o session() método, nós usamos execute_read(), passando a top_goal_scorers() função, juntamente com quaisquer parâmetros que a consulta requer.
A saída de execute_read é uma lista de objetos Record que corretamente mostra os 5 maiores goleadores da história da Copa do Mundo, incluindo nomes como Miroslav Klose, Ronaldo Nazário e Lionel Messi.
O complemento de execute_read() para a ingestão de dados é execute_write().
Com isso dito, vamos agora olhar para o script de ingestão que usamos anteriormente para entender como a ingestão de dados funciona com o driver Python do Neo4j.
Ingestão de Dados Usando o Driver Python do Neo4j
O ingest_football_data.py arquivo começa com declarações de importação e carregamento dos arquivos CSV necessários:
import pandas as pd import neo4j from dotenv import load_dotenv import os from tqdm import tqdm import logging # Caminhos de arquivo CSV results_csv_path = "https://raw.githubusercontent.com/martj42/international_results/refs/heads/master/results.csv" goalscorers_csv_path = "https://raw.githubusercontent.com/martj42/international_results/refs/heads/master/goalscorers.csv" shootouts_csv_path = "https://raw.githubusercontent.com/martj42/international_results/refs/heads/master/shootouts.csv" # Configurar log logging.basicConfig(level=logging.INFO) logger = logging.getLogger(__name__) logger.info("Loading data...") # Carregar dados results_df = pd.read_csv(results_csv_path, parse_dates=["date"]) goalscorers_df = pd.read_csv(goalscorers_csv_path, parse_dates=["date"]) shootouts_df = pd.read_csv(shootouts_csv_path, parse_dates=["date"])
Este bloco de código também configura um log. As próximas linhas de código lêm as credenciais do Neo4j usandodotenv e criam um objeto Driver:
uri = os.getenv("NEO4J_URI") user = os.getenv("NEO4J_USERNAME") password = os.getenv("NEO4J_PASSWORD") try: driver = neo4j.GraphDatabase.driver(uri, auth=(user, password)) print("Connected to Neo4j instance successfully!") except Exception as e: print(f"Failed to connect to Neo4j: {e}") BATCH_SIZE = 5000
Como há mais de 48k correspondências na nossa base de dados, definimos umBATCH_SIZE parâmetro para processar dados em amostras menores.
Então, definimos uma função chamada create_indexes que aceita um objeto de sessão:
def create_indexes(session): indexes = [ "CREATE INDEX IF NOT EXISTS FOR (t:Team) ON (t.name)", "CREATE INDEX IF NOT EXISTS FOR (m:Match) ON (m.id)", "CREATE INDEX IF NOT EXISTS FOR (p:Player) ON (p.name)", "CREATE INDEX IF NOT EXISTS FOR (t:Tournament) ON (t.name)", "CREATE INDEX IF NOT EXISTS FOR (c:City) ON (c.name)", "CREATE INDEX IF NOT EXISTS FOR (c:Country) ON (c.name)", ] for index in indexes: session.run(index) print("Indexes created.")
Índices Cypher são estruturas de banco de dados que melhoram o desempenho de consultas no Neo4j. Eles aceleram o processo de encontrar nós ou relações com base em propriedades específicas. Nós precisamos deles para:
- Execução mais rápida de consultas
- Desempenho de leitura melhorado em grandes conjuntos de dados
- Correspondência de padrões eficiente
- Aplicação de restrições únicas
- Melhores capacidades de escalonamento conforme a base de dados cresce
No nosso caso, índices em nomes de times, IDs de partidas e nomes de jogadores ajudarão nossas consultas a funcionar mais rápido quando procurando entidades específicas ou realizando junções entre diferentes tipos de nós. É uma prática padrão criar tais índices nas próprias bases de dados.
A seguir, temos a função ingest_matches . É grande, portanto vamos desdobrá-la pedaço por pedaço:
def ingest_matches(session, df): query = """ UNWIND $batch AS row MERGE (m:Match {id: row.id}) SET m.date = date(row.date), m.home_score = row.home_score, m.away_score = row.away_score, m.neutral = row.neutral MERGE (home:Team {name: row.home_team}) MERGE (away:Team {name: row.away_team}) MERGE (t:Tournament {name: row.tournament}) MERGE (c:City {name: row.city}) MERGE (country:Country {name: row.country}) MERGE (home)-[:PLAYED_HOME]->(m) MERGE (away)-[:PLAYED_AWAY]->(m) MERGE (m)-[:PART_OF]->(t) MERGE (m)-[:PLAYED_IN]->(c) MERGE (c)-[:LOCATED_IN]->(country) WITH m, home, away, row.home_score AS hs, row.away_score AS as FOREACH(_ IN CASE WHEN hs > as THEN [1] ELSE [] END | MERGE (home)-[:WON]->(m) MERGE (away)-[:LOST]->(m) ) FOREACH(_ IN CASE WHEN hs < as THEN [1] ELSE [] END | MERGE (away)-[:WON]->(m) MERGE (home)-[:LOST]->(m) ) FOREACH(_ IN CASE WHEN hs = as THEN [1] ELSE [] END | MERGE (home)-[:DREW]->(m) MERGE (away)-[:DREW]->(m) ) """ ...
A primeira coisa que você notará é a palavra-chave UNWIND, usada para processar um lote de dados. Ela recebe o parâmetro $batch (que serão nossas linhas do DataFrame) e itera sobre cada linha, permitindo criar ou atualizar vários nós e relações em uma única transação. Esta abordagem é mais eficiente do que processar cada linha individualmente, especialmente para grandes conjuntos de dados.
O resto da consulta é familiar, já que ela usa várias MERGE cláusulas. Depois, chegamos à WITH cláusula, que usa FOREACH construções com IN CASE declarações. Estas são usadas para criar relações condicionalmente com base no resultado da correspondência. Se o time de casa ganhar, ela cria uma relação ‘WON’ para o time de casa e uma relação ‘LOST’ para o time visitante, e vice-versa. Em caso de empate, ambos os times obtêm uma relação ‘DREW’ com o jogo.
O resto da função divide o DataFrame de entrada em correspondências e constrói os dados que serão passados para o $batch parâmetro da consulta:
def ingest_matches(session, df): query = """...""" for i in tqdm(range(0, len(df), BATCH_SIZE), desc="Ingesting matches"): batch = df.iloc[i : i + BATCH_SIZE] data = [] for _, row in batch.iterrows(): match_data = { "id": f"{row['date']}_{row['home_team']}_{row['away_team']}", "date": row["date"].strftime("%Y-%m-%d"), "home_score": int(row["home_score"]), "away_score": int(row["away_score"]), "neutral": bool(row["neutral"]), "home_team": row["home_team"], "away_team": row["away_team"], "tournament": row["tournament"], "city": row["city"], "country": row["country"], } data.append(match_data) session.run(query, batch=data)
ingest_goals e ingest_shootouts funções usam construtos similares. No entanto, ingest_goals possui algum tratamento adicional de erros e valores ausentes.
No final do script, temos a função main() que executa todas nossas funções de ingestão com um objeto de sessão:
def main(): with driver.session() as session: create_indexes(session) ingest_matches(session, results_df) ingest_goals(session, goalscorers_df) ingest_shootouts(session, shootouts_df) print("Data ingestion completed!") driver.close() if __name__ == "__main__": main()
Conclusão e Próximas etapas
Coverdemos os aspectos chave de trabalhar com bancos de dados de grafos Neo4j usando Python:
- Conceitos e estrutura de banco de dados de grafos
- Configuração do Neo4j AuraDB
- Básicos do linguagem de consulta Cypher
- Usando o driver Python para Neo4j
- Ingestão de dados e otimização de consultas
Para avançar em sua jornada com Neo4j, explore estes recursos:
- Documentação do Neo4j
- Biblioteca de Ciência de Dados de Grafos Neo4j
- Manual do Neo4j Cypher
- Documentação do Driver Neo4j para Python
- Certificação de Carreira em Engenharia de Dados
- Introdução ao NoSQL
- Um tutorial completo de NoSQL usando MongoDB
Lembre-se, o poder dos bancos de dados de grafos reside na representação e na consulta de relações complexas. Continue a experimentar com diferentes modelos de dados e a explorar funcionalidades avançadas do Cypher.