













Учёные по данным начинают изучать SQL рано. Это понятно, учитывая всеобъемлющее распространение и высокую полезность табличной информации. Однако существуют и другие успешные форматы баз данных, такие как графовые базы данных, для хранения связанных данных, которые не поддаются реляционной базе данных SQL. В этом руководстве мы изучим Neo4j, популярную систему управления графовой базой данных, которую можно использовать для создания, управления и запросов графовых баз данных на Python.
Что такое графовые базы данных?
Прежде чем говорить о Neo4j, давайте немного подробнее понять графовые базы данных. У нас есть полная статья, объясняющая что такое графовые базы данных, поэтому мы расскажем здесь основные моменты.
Графовые базы данных – это тип NoSQL-баз данных (они не используют SQL) предназначенных для управления связанными данными. В отличие от традиционных реляционных баз данных, использующих таблицы и строки, графовые базы данных используют графовые структуры, состоящие из:
- Узлов (энтитетов) таких как люди, места, концепции
- Области (отношения) соединяют различные узлы, например человек живет в месте, или футболист забил в матче.
- Свойства (атрибуты для узлов/ребер) такие как возраст человека или момент, когда в матче был забит гол.
Данная структура делает графовые базы данных идеальными для работы с взаимосвязанными данными в областях и приложениях, таких как социальные сети, рекомендации, обнаружение мошенничества и т. д., и иногда они превосходят реляционные БД по эффективности запросов. Вот структура примера базы данных графа для футбольного набора данных:
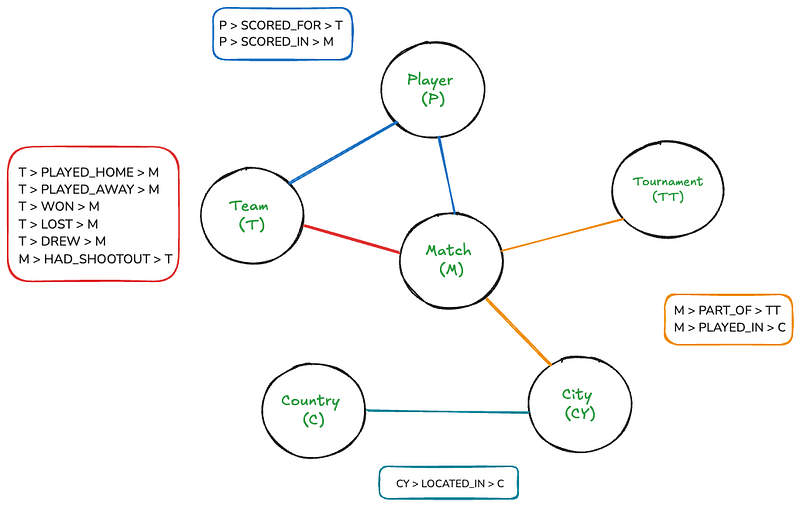
Хотя этот график представляет собой для людей довольно интуитивно понятный материал, он может стать довольно сложным, если его нарисовать на холсте. Но с Neo4j пересечение этого графика станет таким же прямолинейным, как написание простых SQL-join’ов.
В графе шесть узлов: Матч, Команда, Турнир, Игрок, Страна и Город. Прямоугольники перечисляют существующие связи между узлами. Также есть несколько свойств узлов и связей:
- Сопоставление: дата, домашняя команда – результат, гостевая команда – результат
- Команда: название
- Игрок: имя
- Турнир: название
- Город: название
- Страна: название
- SCORED_FOR, SCORED_IN: минута, собственный_гол, пенальти
- HAD_SHOOTOUT: победитель, первый_забивший.
Этот схема позволяет нам представить:
- Все встречи с их очками, датами и местами проведения
- Команды, участвующие в каждой встрече (дома и в гостях)
- Игроков, которые забивают голы, включая детали, такие как минута, собственные голы и пенальти
- Турниры, в которых состоялись встречи
- Города и страны, где проводятся матчи
- Информация о драках, включая победителей и первых стрелявших (когда это доступно)
Схема捕捉了 места (город внутри страны) и различные связи между сущностями (например, команды, играющие матчи, игроки, которые забивают для команд в матчах).
Эта структура позволяет выполнять гибкие запросы, такие как нахождение всех матчей между двумя командами, всех голов, забитых игроком, или всех матчей в определенном турнире или месте.
Но не забывайте о том, что мы уже впереди. Для начала, что такое Neo4j и зачем его использовать?
Что такое Neo4j?
Neo4j – это ведущая фирма в мире управления графовыми БД, известна своими мощными функциями и гибкостью.
В своей основе Neo4j использует собственную реализацию графового хранения, который специально оптимизирован для выполнения операций над графами. Его эффективность в обработке сложных связей делает Neo4j более эффективным, чем традиционные базы данных при обработке связанных данных. Скалярность Neo4j действительно впечатляющая: он может без труда обрабатывать миллиарды узлов и связей, что делает его подходящим как для небольших проектов, так и для крупных корпораций.
Другая ключевая особенность Neo4j — это сохранность данных. Neo4j полностью поддерживает ACID (Атоматичность, Consistency, Isolation, Durability), обеспечивая надежность и согласованность в транзакциях.
Рассмотря на это, его язык запросов Cypher предлагает очень интуитивно понятную и декларативную синтаксис, предназначенный для работы с графовыми моделями. Поэтому его синтаксис часто называют сленговым термином “ASCII-арт”. Cypher легко учиться, особенно, если вы знакомы с SQL.
С помощью Cypher легко добавлять новые узлы, отношения или свойства, не беспокоясь о нарушении существующих запросов или схем. Он адаптируется к быстро меняющимся требованиям современных сред разработки.
У Neo4j есть развитая поддержка экосистемы. Он обладает обширной документацией, комплексными инструментами для визуализации графов, активным сообществом и интеграциями с другими языками программирования, такими как Python, Java и JavaScript.
Настройка Neo4j и среды Python
Прежде чем начать работу с Neo4j, нам нужно настроить нашу среду. Этот раздел проведет вас через создание облачного экземпляра для размещения баз данных Neo4j, настройку среды Python и установление соединения между ними.
Не устанавливая Neo4j
Если вы хотите работать с локальными графовыми базами данных в Neo4j, то вам потребуется загрузить и установить ее локально, а также ее зависимости, такие как Java. Но в большинстве случаев вы будете взаимодействовать с существующим удаленным базой данных Neo4j в какой-то облачной среде.
По этой причине мы не будем устанавливать Neo4j на нашей системе. Вместо этого мы создадим бесплатную экземпляр базы данных на Aura, полностью управляемом облачном сервисе Neo4j. Затем мы будем использоватьneo4j библиотеку Python для подключения к этой базе данных и заполнения ее данными.
Создание экземпляра базы данных Neo4j Aura
Чтобы разместить бесплатную графовую базу данных на Aura DB, посетите страницу продукта и нажмите на кнопку ” начать бесплатно”.
После регистрации вам будут представлены доступные планы, и вы должны выбрать бесплатный вариант. Затем вам будет выдан новый экземпляр с учетными данными пользователя и паролем для подключения к нему:
Скопируйте ваш пароль, имя пользователя и адрес подключения.
Тогда, создайте новый рабочий каталог и .env файл, чтобы хранить ваши учетные данные:
$ mkdir neo4j_tutorial; cd neo4j_tutorial $ touch .env
Вставьте следующий контент внутрь файла:
NEO4J_USERNAME="YOUR-NEO4J-USERNAME" NEO4J_PASSWORD="YOUR-COPIED-NEO4J-PASSWORD" NEO4J_CONNECTION_URI="YOUR-COPIED-NEO4J-URI"
Установка Python Environment
Теперь мы установим neo4j Python клиентскую библиотеку в новом environment Conda:
$ conda create -n neo4j_tutorial python=3.9 -y $ conda activate neo4j_tutorial $ pip install ipykernel # Для добавления environment Jupyter $ ipython kernel install --user --name=neo4j_tutorial $ pip install neo4j python-dotenv tqdm pandas
Команды также устанавливают ipykernel библиотеку и используют ее для добавления вновь созданной среды Conda в Jupyter в качестве ядра. Затем мы устанавливаем neo4j клиент на Python для взаимодействия с базами данных Neo4j и python-dotenv для безопасного управления нашими учетными данными Neo4j.
Заполнение экземпляра AuraDB данными о футболе.
Получение данных в графовую базу данных – это сложный процесс, который требует знания основ Cypher. Поскольку мы еще не узнали о базовых принципах Cypher, вы будете использовать Python-скрипт, который я подготовил для статьи, и который автоматически захватит реальные исторические данные по футболу. Скрипт будет использовать учетные данные, которые вы храните, для подключения к вашей экземпляру AuraDB.
Футбольные данные происходят из этой выборки Kaggle о международных футбольных матчах сыгранных с 1872 по 2024 год. Данные доступны в формате CSV, поэтому скрипт разбирает их и converts it into graph format using Cypher and Neo4j. В конце статьи, когда мы будем достаточно комфортно с этими технологиями, мы пройдем скрипт по строкам, чтобы вы могли понять, как преобразовать табличную информацию в граф.
Вот команды для запуска (убедитесь, что вы установили экземпляр AuraDB и сохранили свои учетные данные в .env файле в вашем рабочем каталоге):
$ wget https://raw.githubusercontent.com/BexTuychiev/medium_stories/refs/heads/master/2024/9_september/3_neo4j_python/ingest_football_data.py $ python ingest_football_data.py
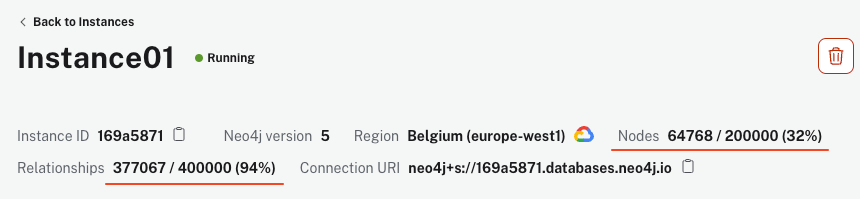
Скрипт может занять несколько минут для выполнения, в зависимости от вашего компьютера и интернет-соединения. Однако, как только он закончится, ваш экземпляр AuraDB должен показать более 64k узлов и 340k связей.
Подключение к Neo4j из Python
Теперь мы готовы соединиться с нашей инстанцией базы данных Aura. First, we will read our credentials from the .env файла с использованием dotenv:
import os from dotenv import load_dotenv load_dotenv() NEO4J_USERNAME = os.getenv("NEO4J_USERNAME") NEO4J_PASSWORD = os.getenv("NEO4J_PASSWORD") NEO4J_URI = os.getenv("NEO4J_URI")
Теперь установим соединение:
from neo4j import GraphDatabase uri = NEO4J_URI username = NEO4J_USERNAME password = NEO4J_PASSWORD driver = GraphDatabase.driver(uri, auth=(username, password)) try: driver.verify_connectivity() print("Connection successful!") except Exception as e: print(f"Failed to connect to Neo4j: {e}")
Вывод:
Connection successful!
Здесь представлена Explanation of the code:
- Мы импортируем
GraphDatabaseизneo4jдля взаимодействия с Neo4j. - Мы используем ранее загруженные средей переменных для установки нашей связи (
uri,username,password). - Мы создаем объект драйвера используя
GraphDatabase.driver(), устанавливая соединение с нашей базой данных Neo4j. - Перед
withблоком, мы используемverify_connectivity()функцию, чтобы проверить, установлен ли соединение. По умолчаниюverify_connectivity()не возвращает никакого значения, если соединение успешно установлено.
Когда урок закончится, вызвайте driver.close() для завершения соединения и освобождения ресурсов. Объекты драйвера дороги, поэтому вы должны создавать только один объект для вашего приложения.
Основы языка запросов Cypher
Синтаксис языка запросов Cypher предназначен для intuitive и визуально представлять структуры графов. Он полагается на следующий тип ASCII-арта синтаксиса:
(nodes)-[:CONNECT_TO]->(other_nodes)
Давайте разbreakdown ключевых компонентов этого общего запросного поведения:
1. Узлы
В запросе Cypher ключевое слово в круглых скобках означает имя узла. Например, (Player) соответствует всем узлам Player. almost всегда имя узла обращается с помощью алиасов, чтобы сделать запросы более читаемыми, легче для составления и компактными. Вы можете добавить алиас к имени узла, поместив запятую перед ним: (m:Match).
Внутри круглых скобок вы можете指定 одно или более свойств узла для точного соответствия с использованием словаря подобного синтаксиса. Например:
// Все узлы турнира, которые являются FIFA World Cup (t:Tournament {name: "FIFA World Cup"})
Свойства узлов записываются как есть, а значение, которое вы хотите, чтобы у них было, должно быть строкой.
2. Связи
Связи соединяют узлы друг с другом, и они ограничены квадратными скобками и стрелками:
// Судьба узлов, которые являются частью какого-то турнира (m:Match)-[PART_OF]->(t:Tournament)
Вы также можете добавлять aliases и свойства к связям:
// Соответствие тому, что Бразилия участвовала в серии пенальти и была первым стрелком (p:Player) - [r:SCORED_FOR {minute: 90}] -> (t:Team)
Отношения оборачиваются стрелами -[Отношение]->. Once again, you can include aliases properties inside braces. For example:
// Все игроки, которые пропустили свой гол (p:Player)-[r:SCORED_IN {own_goal: True}]->(m:Match)
3. Клаузы
Как COUNT(*) FROM table_name не возвращает никаких результатов без SELECT запроса в SQL, (node) - [RELATIONSHIP] -> (node) также не выполнит никаких операций. Так как в SQL, Cypher также имеет различные части, чтобы структурировать логику вашего запроса, подобно SQL:
СОВПАДЕНИЕ: Сопоставление шаблонов в графеГДЕ: Фильтрация результатовВОЗВРАЩАТЬ: Указание того, что включить в набор результатовСОЗДАТЬ: Создание новых узлов или связейMERGE: Создание уникальных узлов или связейDELETE: Удаление узлов, связей или свойствSET: Обновление метки и свойств
Вот пример запроса, который демонстрирует这些概念:
MATCH (p:Player)-[s:SCORED_IN]->(m:Match)-[PART_OF]->(t:Tournament) WHERE t.name = "FIFA World Cup" AND s.minute > 80 AND s.own_goal = True RETURN p.name AS Player, m.date AS MatchDate, s.minute AS GoalMinute ORDER BY s.minute DESC LIMIT 5
Этот запрос находит всех игроков, забивших собственные голы в матчах чемпионата мира по футболу после 80-й минуты. Он читается почти как SQL, но его SQL-эквивалент включает как минимум один JOIN.
Использование драйвера Neo4j Python для анализа базы данных графиков
Запуск запросов с помощью execute_query
Драйвер Neo4j Python – это официальная библиотека, которая взаимодействует с экземпляром Neo4j через приложения Python. Она проверяет и передает запросы Cypher, написанные в обычных строках Python, на сервер Neo4j и извлекает результаты в унифицированном формате.
Все начинается с создания объекта драйвера с помощью GraphDatabase класса. оттуда мы можем начать отправлять запросы с использованием execute_query метода.
Для нашего первого запроса, покажем интересный вопрос: Кому принадлежит наибольшая победа на чемпионате мира?
# Возвращает команду, выигравшую больше всего матчей на чемпионате мира query = """ MATCH (t:Team)-[:WON]->(m:Match)-[:PART_OF]->(:Tournament {name: "FIFA World Cup"}) RETURN t.name AS Team, COUNT(m) AS MatchesWon ORDER BY MatchesWon DESC LIMIT 1 """ records, summary, keys = driver.execute_query(query, database_="neo4j")
Первоначально, рассмотрим запрос:
- Моя
ПОДРОБНОСТИтекста показывают, что искомый шаблон выглядит следующим образом: Команда -> Победа -> Матч -> Часть -> Турнира RETURNявляется эквивалентом SQL-запросаSELECT. Здесь мы можем возвращать свойства возвращаемых узлов и связей. В этомCLAUSE также можно использовать любую поддерживаемую агрегирующую функцию в Cypher. В приведенном выше casе мы используемCOUNT.КЛАУЗАORDER BY работает так же, как в SQL.ЛИМИТиспользуется для контроля длины возвращаемых записей.
После того как мы определили запрос как многострочную строку, мы передаем его методу execute_query() объекта驱动器 и указываем имя базы данных (по умолчанию это neo4j). Вывод всегда содержит три объекта:
records: Список объектов Record, каждый из которых представляет собой строку результатов. Каждый Record – это объект с названиями полей, подобный набору с именованными полями, где можно получить доступ к полям по имени или индексу.resumen: Объект ResultSummary, содержащий метаданные о выполнении запроса, такие как статистика запроса и информация о времени.ключи: Список строк, представляющих имена колонок в наборе результатов.
Мы позже примемся за summary объект, поскольку нам более всего интересны records, которые содержат Record объекты. Мы можем извлечь информацию о них, вызвав их data() метод:
for record in records: print(record.data())
Вывод:
{'Team': 'Brazil', 'MatchesWon': 76}
Результат корректно показывает, что Бразилия выиграла больше всего матчей чемпионата мира.
Передача параметров запроса
Наш последний запрос не реusable, так как он находит самую успешную команду в истории чемпионатов мира. Что, если мы хотим найти самую успешную команду в истории Евро?
В этом месте наступает дело импорта параметров запроса:
query = """ MATCH (t:Team)-[:WON]->(m:Match)-[:PART_OF]->(:Tournament {name: $tournament}) RETURN t.name AS Team, COUNT(m) AS MatchesWon ORDER BY MatchesWon DESC LIMIT $limit """
В этой версии запроса мы введем два параметра с использованием знака $:
tournamentlimit
Для передачи значений параметрам запроса мы используем ключевые аргументы внутри execute_query:
records, summary, keys = driver.execute_query( query, database_="neo4j", tournament="UEFA Euro", limit=3, ) for record in records: print(record.data())
Вывод:
{'Team': 'Germany', 'MatchesWon': 30} {'Team': 'Spain', 'MatchesWon': 28} {'Team': 'Netherlands', 'MatchesWon': 23}
Всегда рекомендуется использовать запросные параметры, когда вы размышляете о включении изменяющихся значений в ваш запрос. Этот лучший пример защищает ваши запросы от внедрения Cypher и позволяет Neo4j кэшировать их.
Писать в базы данных с помощью разделов CREATE и MERGE
Добавление новой информации в существующую базу данных выполняется с помощью execute_query, используя CREATECLAUSE в запросе. Например, создадим функцию, которая добавит новый тип узла – тренера команды:
def add_new_coach(driver, coach_name, team_name, start_date, end_date): query = """ MATCH (t:Team {name: $team_name}) CREATE (c:Coach {name: $coach_name}) CREATE (c)-[r:COACHES]->(t) SET r.start_date = $start_date SET r.end_date = $end_date """ result = driver.execute_query( query, database_="neo4j", coach_name=coach_name, team_name=team_name, start_date=start_date, end_date=end_date ) summary = result.summary print(f"Added new coach: {coach_name} for existing team {team_name} starting from {start_date}") print(f"Nodes created: {summary.counters.nodes_created}") print(f"Relationships created: {summary.counters.relationships_created}")
Функция add_new_coach принимает пять параметров:
- драйвер: Объект драйвера Neo4j, используемый для подключения к базе данных.
coach_name: Имя нового тренера, которое будет добавлено.team_name: Имя команды, с которой будет связано имя тренера.start_date: Дата, когда тренер начинает работать с командой.end_date: Дата, когда контракт тренера с командой заканчивается.
Цифровая запрос в функции выполняет следующее:
- Соответствует существующему узлу команды с данным именем.
- Создает новый узел тренера с указанным именем.
- Создает связь
COACHESмежду узламиCoachиTeam. - Устанавливает свойства
start_dateиend_dateна связиCOACHES.
Запрос выполняется с помощью execute_query метода, который принимает строку запроса и словарь параметров.
После выполнения функция печатает:
- Сообщение подтверждения с названиями тренера и команды и датой начала.
- Количество созданных узлов (должно быть 1 для нового узла Тренера).
- Количество созданных отношений (должно быть 1 для нового отношения
COACHES).
Давайте попробуем это с одним из наиболее успешных тренеров в истории международного футбола, Леонардо Скалони, который выиграл три подряд крупных международных турнира (чемпионат мира и два Кубка Америки):
from neo4j.time import DateTime add_new_coach( driver=driver, coach_name="Lionel Scaloni", team_name="Argentina", start_date=DateTime(2018, 6, 1), end_date=None )
Output: Added new coach: Lionel Scaloni for existing team Argentina starting from 2018-06-01T00:00:00.000000000 Nodes created: 1 Relationships created: 1
В вышеприведенном фрагменте мы используем класс DateTime из модуля neo4j.time для корректного передачи даты в наш запрос Cypher. В модуле содержатся другие полезные типы данных времени, которые можно посмотреть.
Кроме CREATE, существует также MERGE clause для создания новых узлов и связей. Основное различие между ними состоит в том, что:
CREATEвсегда создает новые узлы/связи, что может привести к дублированию.MERGEтолько создает узлы/отношения, если они уже не существуют.
Например, в нашем скрипте импорта данных, как вы увидите позже:
- Мы использовали
MERGEдля команд и игроков, чтобы избегать дубликатов. - Мы использовали
CREATEдляSCORED_FORиSCORED_INсвязей, поскольку игрок может забить несколько раз за одну игру. - Эти не являются истинными дубликатами, так как у них разные свойства (например, минута гола).
Этот подход обеспечивает целостность данных, позволяя создавать несколько схожих, но различных отношений.
Выполнение ваших собственных транзакций
Когда вы выполняете execute_query, в драйвере создается транзакция на заднем футе. Транзакция является единицей работы, которая или выполняется полностью, или отменяется в случае ошибки. Это意味着, что при создании тысяч узлов или отношений в одной транзакции (это возможно) и встречении какой-либо ошибки в середине, вся транзакция провальна и никаких новых данных в графе не будет записано.
Для более тонкой настройки каждой транзакции вам нужно создавать объекты сессии. Например, создадим функцию для нахождения топ-K лучших счетчиков голов в данном турнире с использованием объекта сессии:
def top_goal_scorers(tx, tournament, limit): query = """ MATCH (p:Player)-[s:SCORED_IN]->(m:Match)-[PART_OF]->(t:Tournament) WHERE t.name = $tournament RETURN p.name AS Player, COUNT(s) AS Goals ORDER BY Goals DESC LIMIT $limit """ result = tx.run(query, tournament=tournament, limit=limit) return [record.data() for record in result]
Сначала мы создаем top_goal_scorers функцию, которая принимает три параметра, самым важным из которых является tx объект транзакции, который будет получен с использованием объекта сессии.
with driver.session() as session: result = session.execute_read(top_goal_scorers, "FIFA World Cup", 5) for record in result: print(record)
Вывод:
{'Player': 'Miroslav Klose', 'Goals': 16} {'Player': 'Ronaldo', 'Goals': 15} {'Player': 'Gerd Müller', 'Goals': 14} {'Player': 'Just Fontaine', 'Goals': 13} {'Player': 'Lionel Messi', 'Goals': 13}
Тогда, в контекст менеджера, созданного с помощью session() метода, мы используем execute_read(), передавая top_goal_scorers() функцию, а также все необходимые для запроса параметры.
На выходе execute_read – список объектов Record, в котором правильно указаны 5 лучших бомбардиров в истории Кубка мира, включая такие имена, как Мирослав Клозе, Роналдо Назарио и Лионель Месси.
Только execute_read() для ввода данных – execute_write().
В связи с этим давайте рассмотрим скрипт захвата данных, который мы использовали ранее, чтобы понять, как работает захват данных с помощью драйвера Neo4j Python.
Data Ingestion Using Neo4j Python Driver
The ingest_football_data.py file начинается с операторов import и загрузки необходимых файлов CSV:
import pandas as pd import neo4j from dotenv import load_dotenv import os from tqdm import tqdm import logging Пути к файлам CSV results_csv_path = "https://raw.githubusercontent.com/martj42/international_results/refs/heads/master/results.csv" goalscorers_csv_path = "https://raw.githubusercontent.com/martj42/international_results/refs/heads/master/goalscorers.csv" shootouts_csv_path = "https://raw.githubusercontent.com/martj42/international_results/refs/heads/master/shootouts.csv" Настройка журналирования logging.basicConfig(level=logging.INFO) logger = logging.getLogger(__name__) logger.info("Loading data...") Загрузка данных results_df = pd.read_csv(results_csv_path, parse_dates=["date"]) goalscorers_df = pd.read_csv(goalscorers_csv_path, parse_dates=["date"]) shootouts_df = pd.read_csv(shootouts_csv_path, parse_dates=["date"])
Этот блок кода также настраивает журнал. Следующие несколько строк кода читают мои учетные данные Neo4j с использованием dotenv и создает объект Driver:
uri = os.getenv("NEO4J_URI") user = os.getenv("NEO4J_USERNAME") password = os.getenv("NEO4J_PASSWORD") try: driver = neo4j.GraphDatabase.driver(uri, auth=(user, password)) print("Connected to Neo4j instance successfully!") except Exception as e: print(f"Failed to connect to Neo4j: {e}") BATCH_SIZE = 5000
Поскольку в нашей базе данных более 48 тыс. совпадений, мы определяем параметр BATCH_SIZE для обработки данных в более меньших образцах.
Тогда мы определяем функцию, названную create_indexes, которая принимает объект сессии:
def create_indexes(session): indexes = [ "CREATE INDEX IF NOT EXISTS FOR (t:Team) ON (t.name)", "CREATE INDEX IF NOT EXISTS FOR (m:Match) ON (m.id)", "CREATE INDEX IF NOT EXISTS FOR (p:Player) ON (p.name)", "CREATE INDEX IF NOT EXISTS FOR (t:Tournament) ON (t.name)", "CREATE INDEX IF NOT EXISTS FOR (c:City) ON (c.name)", "CREATE INDEX IF NOT EXISTS FOR (c:Country) ON (c.name)", ] for index in indexes: session.run(index) print("Indexes created.")
Индексы Cypher являются структурами базы данных, улучшающими производительность запросов в Neo4j. Они ускоряют процесс поиска узлов или связей на основании определенных свойств. Нам их нужны для:
- Ускорения выполнения запросов
- Улучшения производительности чтения на больших наборах данных
- Эффективной совпадения моделей
- Обновление уникальных ограничений
- Лучшая масштабность при росте базы данных
В нашем случае индексы на имена команд, идентификаторы матчей и имена игроков помогут нам ускорить выполнение запросов при поиске определенных элементов или выполнении JOIN-пераций между различными типами узлов. Это хорошая практика создавать такие индексы в ваших собственных базах данных.
Далее у нас естьingest_matches функция. Она довольно крупная, поэтому давайте поделим ее по блокам:
def ingest_matches(session, df): query = """ UNWIND $batch AS row MERGE (m:Match {id: row.id}) SET m.date = date(row.date), m.home_score = row.home_score, m.away_score = row.away_score, m.neutral = row.neutral MERGE (home:Team {name: row.home_team}) MERGE (away:Team {name: row.away_team}) MERGE (t:Tournament {name: row.tournament}) MERGE (c:City {name: row.city}) MERGE (country:Country {name: row.country}) MERGE (home)-[:PLAYED_HOME]->(m) MERGE (away)-[:PLAYED_AWAY]->(m) MERGE (m)-[:PART_OF]->(t) MERGE (m)-[:PLAYED_IN]->(c) MERGE (c)-[:LOCATED_IN]->(country) WITH m, home, away, row.home_score AS hs, row.away_score AS as FOREACH(_ IN CASE WHEN hs > as THEN [1] ELSE [] END | MERGE (home)-[:WON]->(m) MERGE (away)-[:LOST]->(m) ) FOREACH(_ IN CASE WHEN hs < as THEN [1] ELSE [] END | MERGE (away)-[:WON]->(m) MERGE (home)-[:LOST]->(m) ) FOREACH(_ IN CASE WHEN hs = as THEN [1] ELSE [] END | MERGE (home)-[:DREW]->(m) MERGE (away)-[:DREW]->(m) ) """ ...
Первым, что вы заметите, это UNWIND ключевое слово, которое используется для обработки набора данных. Оно принимает $batch параметр (который будет нашими строками DataFrame) и итерает по каждой строке, позволяя нам создавать или обновлять множество узлов и связей в одной транзакции. Этот подход более эффективен, чем обработка каждой строки отдельно, особенно для больших наборов данных.
Остальная часть запроса знакома, так как она использует несколько MERGEklausulas. Затем мы достигаем WITHklausulas, которая использует FOREACH конструкты с IN CASE утверждениями. Эти используются для условного создания связей на основе результата соответствия. Если побеждает домашняя команда, то для домашней команды создается ‘WON’ связь, а для команды-отряда ‘LOST’, и наоборот. В случае ничьей обе команды получают ‘DREW’ связь с матчем.
Остальная часть функции разделяет исходящий DataFrame на совпадения и строит данные, которые будут передаваться в $batch параметр запроса:
def ingest_matches(session, df): query = """...""" for i in tqdm(range(0, len(df), BATCH_SIZE), desc="Ingesting matches"): batch = df.iloc[i : i + BATCH_SIZE] data = [] for _, row in batch.iterrows(): match_data = { "id": f"{row['date']}_{row['home_team']}_{row['away_team']}", "date": row["date"].strftime("%Y-%m-%d"), "home_score": int(row["home_score"]), "away_score": int(row["away_score"]), "neutral": bool(row["neutral"]), "home_team": row["home_team"], "away_team": row["away_team"], "tournament": row["tournament"], "city": row["city"], "country": row["country"], } data.append(match_data) session.run(query, batch=data)
ingest_goals и ingest_shootouts функции используют схожие конструкции. However, ingest_goals имеют некоторые дополнительные обработки ошибок и отсутствующих значений.
В конце скрипта у нас есть main() функция, которая выполняет все наши функции по импорту с помощью объекта сессии:
def main(): with driver.session() as session: create_indexes(session) ingest_matches(session, results_df) ingest_goals(session, goalscorers_df) ingest_shootouts(session, shootouts_df) print("Data ingestion completed!") driver.close() if __name__ == "__main__": main()
Заключение и следующие шаги
Мы рассмотрели ключевые аспекты работы с графскими базами данных Neo4j на Python:
- Основные понятия и структура графских баз данных
- Установка Neo4j AuraDB
- Основы языка запросов Cypher
- Использование Python-драйвера Neo4j
- Обработка данных и оптимизация запросов
Для продолжения путешествия с Neo4j, исследователями этих ресурсов:
- Документация Neo4j
- Библиотека графовой data science Neo4j
- Руководство по Cypher Neo4j
- Документация Python Driver Neo4j
- Сертификация по профессии в области данных и инженерии
- Введение в NoSQL
- Объемный учебник по NoSQL с использованием MongoDB
Помните, что сила графовых баз данных заключается в представлении и запросе сложных отношений. Продолжайте экспериментировать с различными моделями данных и изучать расширенные возможности Cypher.