













Data scientists beginnen al vroeg met leren over SQL. Dat is begrijpelijk, gezien de alomvattende en hoge nuttigheid van tabulaire informatie. Echter, er zijn andere succesvolle databaseformaten, zoals grafische databases, om verbonden data op te slaan die niet passen in een relationele SQL-database. In deze handleiding zullen we leren over Neo4j, een populaire grafische databasebeheerstelsel dat u kunt gebruiken om in Python grafische databases te creëren, beheren en aanroepen.
Wat zijn grafische databases?
Voordat we over Neo4j gaan, nemen we even tijd om beter te begrijpen wat grafische databases zijn. We hebben een artikel volend aan uitlegd wat grafische databases zijn, dus zullen we de belangrijkste punten hier samenvatten.
Grafische databases zijn een type NoSQL-database (ze gebruiken geen SQL) ontworpen voor het beheren van geïntegreerde data. In tegenstelling tot traditionele relationele databases die tabellen en rijen gebruiken, gebruiken grafische databases grafische structuren die bestaan uit:
- Knopen (entiteiten) zoals mensen, plaatsen, concepten
- Randen (relaties) die verschillende knopen aan elkaar verbinden, zoals persoon LIVES IN een plaats, of een voetballer SCORED IN een wedstrijd.
- Eigenschappen (attributen voor knooppunten/kanten) zoals de leeftijd van een persoon, of wanneer in de wedstrijd doel werd gemaakt.
Deze structuur maakt graph databases ideaal voor het behandelen van door elkaar verbonden data in velden en toepassingen zoals sociale netwerken, aanbevelingen, fraude detectie, enzovoort, vaak met betere prestaties dan relatieve databaseën op het gebied van query-efficiëntie. Hier is de structuur van een voorbeeld graph database voor een voetbal dataset:
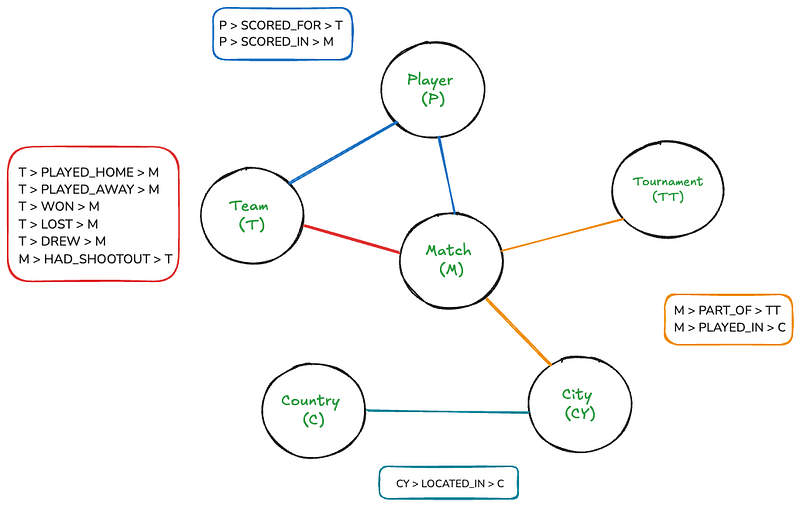
Hoewel deze grafiek voor mensen vrij intuïerend is, kan het heel ingewikkeld worden als ze op een canvas getekend wordt. Maar met Neo4j is het doorlopen van deze grafiek net zo eenvoudig als het schrijven van eenvoudigeSQL-join‘s.
De grafiek heeft zes knooppunten: Match, Team, Toernooi, Speler, Land en Stad. De rechthoeken geven de relaties weer die bestaan tussen knooppunten. Er zijn ook enkele knooppunten- en relatieseigenschappen:
- Vergelijk: datum, thuis_score, uit_score
- Team: naam
- Speler: naam
- Toernooi: naam
- Stad: naam
- Land: naam
- GESCORED_VOR, GESCORED_IN: minuut, eigen doelpunt, penalty
- HAD_SHOOTOUT: winnaar, eerste schutter
Dit schema laat ons toe om te representeren:
- Alle wedstrijden met hun score, data en locaties
- Teams die deelnemen aan elke wedstrijd (thuis en uit)
- Spelers die doelpunten scoren, inclusief details zoals de minuut, eigen doelpunten en straffen
- Toernooien waar de wedstrijden deel van uitmaken
- Steden en landen waar wedstrijden worden gespeeld
- Schietpartijgegevens, inclusief winnaars en eerste schutters (wanneer beschikbaar)
Het schema omvat de hiërarchische aard van locaties (Stad binnen Land) en de diverse relaties tussen entiteiten (bijv. Teams die Matches spelen, Spelers die voor Teams in Matches scoren).
Deze structuur biedt flexibele query’s mogelijk, zoals het vinden van alle matchen tussen twee teams, alle doelpunten die een speler heeft gemaakt, of alle matchen in een specifiek toernooi of locatie.
Maar laten we niet te vroeg beginnen. Voor starters, wat is Neo4j en waarom gebruik je het?
Wat is Neo4j?
Neo4j, de vooraanstaande naam in de wereld van grafische databasebeheer, is bekend om zijn krachtige functionaliteiten en veelzijdigheid.
Neo4j gebruikt bij het core van de applicatie de native graph storage, die zeer geoptimaliseerd is voor het uitvoeren van grafiekoperaties. Door zijn efficientie in het behandelen van complexe relaties, overtreft Neo4j traditionele databases voor verbonden data. De schaalbaarheid van Neo4j is echt indrukwekkend: het kan miljarden noden en relaties gemakkelijk afhandelen, waardoor het geschikt is voor zowel kleine projecten als grote ondernemingen.
Een ander belangrijk aspect van Neo4j is de data integriteit. Het garandeert volledige ACID- (Atomicity, Consistency, Isolation, Durability) compliantie, biedende betrouwbaarheid en consistentie in transacties.
Over transacties gaande, biedt zijn querytaal Cypher een zeer intuitieve en declaraire syntaxis die ontworpen is voor grafiek patronen. Om deze reden heeft zijn syntaxis de bijnaam “ASCII art” gekregen. Cypher zal geen probleem zijn om te leren, vooral als je bekend bent met SQL.
Met Cypher is het gemakkelijk om nieuwe nodes, relaties of eigenschappen toe te voegen zonder zich te hoeven afvragen of bestaande queries of schema’s kapotgaan. Het is aanpasbaar aan de snel veranderende eisen van moderne ontwikkelingsomgevingen.
Neo4j heeft een levendige ondersteuningsecosysteem. Het beschikt over uitgebreide documentatie, alomvattende tools om grafen te visualiseren, een actieve community en integraties met andere programmeertalen zoals Python, Java en JavaScript.
Instellen van Neo4j en een Python-omgeving
Voordat we aan de slag gaan met Neo4j, moeten we onze omgeving instellen. In dit gedeelte wordt u geleid door het maken van een cloud-instance om Neo4j-databassen te hosten, het instellen van een Python-omgeving en het opbouwen van een verbinding tussen beide.
Neo4j niet installeren.
Als u met lokale grafiekdatabassen in Neo4j wilt werken, dan zou u het downloaden en lokaal installeren nodig hebben, evenals afhankelijkheden zoals Java. Maar in de meeste gevallen zult u zich afwisselend met een bestaande externe Neo4j-databank op een bepaald cloudomgeving bewegen.
Daarom zullen we Neo4j niet installeren op ons systeem. In plaats daarvan zullen we een gratis databaseinstantie aanmaken op Aura, de volledig beheerde cloudservice van Neo4j. Vervolgens zullen we de neo4j Python-cliëntbibliotheek gebruiken om verbinding te maken met deze database en deze te vullen met gegevens.
Aanmaken van een Neo4j Aura DB-instantie
Om een gratis grafische database te hosten op Aura DB, bezoek de productpagina en klik op “Gratis beginnen.”
Nadat u geregistreerd bent, zult u de beschikbare plannen krijgen en u moet de gratis optie kiezen. U krijgt dan een nieuwe instantie met een gebruikersnaam en wachtwoord om eraan te connecteren:
Kopieer uw wachtwoord, gebruikersnaam en de verbindings-URI.
Maak dan een nieuwe werkdirectory en een .env bestand aan om uw gegevens op te slaan:
$ mkdir neo4j_tutorial; cd neo4j_tutorial $ touch .env
Plak het volgende inhoud van het bestand binnen:
NEO4J_USERNAME="YOUR-NEO4J-USERNAME" NEO4J_PASSWORD="YOUR-COPIED-NEO4J-PASSWORD" NEO4J_CONNECTION_URI="YOUR-COPIED-NEO4J-URI"
Instellen van de Python omgeving
Nu zal u de neo4j Python client bibliotheek installeren in een nieuwe Conda omgeving:
$ conda create -n neo4j_tutorial python=3.9 -y $ conda activate neo4j_tutorial $ pip install ipykernel # Om de omgeving toe te voegen aan Jupyter $ ipython kernel install --user --name=neo4j_tutorial $ pip install neo4j python-dotenv tqdm pandas
De commando’s installeren ookipykernel bibliotheek en gebruiken hem om de nieuw aangemaakte Conda omgeving toe te voegen aan Jupyter als een kernel. Vervolgens installeren we deneo4j Python-client om te communiceren met Neo4j-databases enpython-dotenv om onze Neo4j-referenties veilig te beheren.
Bevullen van een AuraDB-instance met voetbalgegevens
Gegevensinvoer in een grafenedatabank is een ingewikkeld proces dat kennis vereist van de basisprincipes van Cypher. Aangezien we nog niet over de Cypher-basisprincipes hebben geleerd, zul je een Python-script gebruiken dat ik voor het artikel heb voorbereid, dat automatisch historische voetbalgegevens uit de echte wereld invoert. Het script zal de inloggegevens gebruiken die je hebt opgeslagen om verbinding te maken met je AuraDB-exemplaar.
De voetbalgegevens komen van dit Kaggle-dataset over internationale voetbalwedstrijden gespeeld tussen 1872 en 2024. De gegevens zijn beschikbaar in CSV-formaat, dus het script doorsnijdt het en converteert het naar een grafiekformaat met behulp van Cypher en Neo4j. Naarmate we het artikel aan het eind zijn en voldoende comfortabel zijn met deze technologieën, zullen we door het script regel voor regel gaan om u te laten zien hoe tabulaire informatie in een grafiek kan worden geconverteerd.
Hier zijn de commando’s om uit te voeren (zorg ervoor dat u de AuraDB-instantie heeft ingesteld en uw inloggegevens opgeslagen hebt in een .env bestand in uw werkmap):
$ wget https://raw.githubusercontent.com/BexTuychiev/medium_stories/refs/heads/master/2024/9_september/3_neo4j_python/ingest_football_data.py $ python ingest_football_data.py
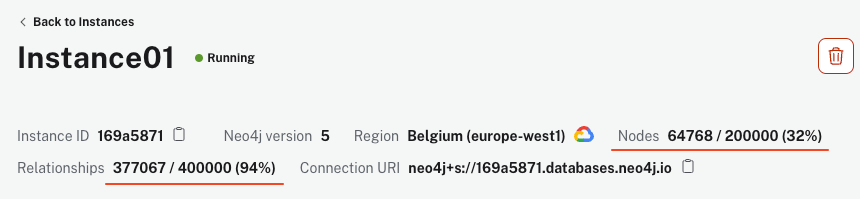
Het script kan enkele minuten duren om uit te voeren, afhankelijk van uw machine en internetverbinding. Echter, zodra het klaar is, moet uw AuraDB-instantie meer dan 64k nodes en 340k relaties weergeven.
Connecteren met Neo4j vanuit Python
Nu zijn we klaar om verbinding te maken met onze Aura DB-instance. eerst zullen we onze inloggegevens lezen uit het .env bestand met behulp van dotenv:
import os from dotenv import load_dotenv load_dotenv() NEO4J_USERNAME = os.getenv("NEO4J_USERNAME") NEO4J_PASSWORD = os.getenv("NEO4J_PASSWORD") NEO4J_URI = os.getenv("NEO4J_URI")
Nu laten we een verbinding opbouwen:
from neo4j import GraphDatabase uri = NEO4J_URI username = NEO4J_USERNAME password = NEO4J_PASSWORD driver = GraphDatabase.driver(uri, auth=(username, password)) try: driver.verify_connectivity() print("Connection successful!") except Exception as e: print(f"Failed to connect to Neo4j: {e}")
Uitvoer:
Connection successful!
Hier volgt een uitleg van de code:
- We importeren
GraphDatabasevanneo4jom te communiceren met Neo4j. - We gebruiken de eerder geladen omgevingsvariabelen om onze verbinding in te stellen (
uri,username,password). - We maken een bestuurdersobject aan met
GraphDatabase.driver(), waarmee we een verbinding maken met onze Neo4j-database. - Bij een
with-blok gebruiken we de verify_connectivity()-functie om te controleren of een verbinding is opgebouwd. Standaard verify_connectivity() retourneert niets als de verbinding succesvol is.
Als de handleiding klaar is, roepdriver.close() aan om de verbinding te beëindigen en resources vrij te maken. Driver-objecten zijn kostbaar om te maken, dus je moet slechts een enkel object voor uw toepassing aanmaken.
Cypher Query Language Essentials
De syntaxis van Cypher is ontworpen om intuitief en visueel representatief van grafiekstructuren te zijn. Hij berust op de volgende ASCII-kunsttype syntaxis:
(nodes)-[:CONNECT_TO]->(other_nodes)
Laat ons de belangrijkste componenten van dit algemeen querypatroon uiteenbreken:
1. Nodes
In een Cypher-query is een keyword in haakjes een knooppuntnaam. Bijvoorbeeld, (Speler) matchen alle Speler-knoop punten. Meestal worden knooppuntnamen verwezen naar met aliassen om queries beter leesbaar, gemakkelijker schrijfbaar en compact te maken. U kunt een alias aan een knooppuntnaam toevoegen door er een dubbele punt voor te zetten: (m:Match).
Binnen de haakjes kunt u een of meerdere knooppunten eigenschappen specificeren voor een nauwkeurige overeenkomst met een woordenboekachtige syntax. Bijvoorbeeld:
// Alle toernooiknoppen die zijn FIFA Wereldbeker (t:Tournament {name: "FIFA World Cup"})
Knoppertoegangen worden zoals ze zijn geschreven, terwijl de waarde die u wilt dat ze hebben een tekst moet zijn.
2. Relaties
Relaties verbinden knooppunten met elkaar, en ze worden afgebeeld met vierkante haakjes en pijlen:
// Matcht knooppunten die deel uitmaken van een bepaald toernooi (m:Match)-[PART_OF]->(t:Tournament)
U kunt ook aliassen en eigenschappen aan relaties toevoegen:
// Matcht gevallen waarin Brazilië een strafschoppenserie deelgenomen heeft en de eerste schutter was (p:Player) - [r:SCORED_FOR {minute: 90}] -> (t:Team)
Relaties zijn afgebeeld met pijlen-[RELATIE]->. Opnieuw kun je aliassen eigenschappen binnen haakjes opnemen. Bijvoorbeeld:
// Alle spelers die een eigen doelpunt hebben gemaakt (p:Player)-[r:SCORED_IN {own_goal: True}]->(m:Match)
3. Clausules
Net als COUNT(*) FROM tabel_naam zou niets teruggeven zonder een SELECT clause in SQL, (node) - [RELATIE] -> (node) zou geen resultaten opleveren. Dus, net zoals in SQL, heeft Cypher verschillende clausules om je querylogica te structureren:
MATCH: Patroonafwijking in het graafWHERE: Filteren van de resultatenRETURN: Specificeren wat erin moet worden opgenomen in de resultaatsetCREATE: Nieuwe knooppunten of relaties aanmakenMERGE: Het maken van unieke knooppunten of relatiesDELETE: Verwijderen van knooppunten, relaties of eigenschappenSET: Bijwerken van labels en eigenschappen
Hier is een voorbeeldquery die deze concepten demonstreert:
MATCH (p:Player)-[s:SCORED_IN]->(m:Match)-[PART_OF]->(t:Tournament) WHERE t.name = "FIFA World Cup" AND s.minute > 80 AND s.own_goal = True RETURN p.name AS Player, m.date AS MatchDate, s.minute AS GoalMinute ORDER BY s.minute DESC LIMIT 5
Deze query zoekt alle spelers die own goals hebben gemaakt in Wereldkampioenschap wedstrijden na de 80e minuut. Het lijkt bijna op SQL, maar de SQL-equivalent betreft minstens een JOIN.
Gebruik van de Neo4j Python Driver om een grafische database te analyseren
Queries uitvoeren met execute_query
De Neo4j Python driver is de officiële bibliotheek die met een Neo4j-instantie communiceert via Python-toepassingen. Het valideert en communiceert Cypher-query’s geschreven in eenvoudige Python-strings met een Neo4j-server en haalt de resultaten op in een geünificeerde opmaak.
Het allemaal begint door een driverobject te maken met deGraphDatabaseklasse. Daarvan kunnen we beginnen om query’s uit te voeren met deexecute_querymethode.
Voor onze eerste query, laat ons een interessante vraag stellen: Wie won de meeste Wereldkampioenschap wedstrijden?
# Geef het team terug dat de meeste Wereldkampioenschap wedstrijden heeft gewonnen query = """ MATCH (t:Team)-[:WON]->(m:Match)-[:PART_OF]->(:Tournament {name: "FIFA World Cup"}) RETURN t.name AS Team, COUNT(m) AS MatchesWon ORDER BY MatchesWon DESC LIMIT 1 """ records, summary, keys = driver.execute_query(query, database_="neo4j")
Eerst laten we de query opdelen:
- De
MATCHsluit de patroon af dat we willen: Team -> Overwinningen -> Wedstrijd -> Deel van -> Toernooi RETURNis het equivalent van SQL’sSELECTstatement, waarin we de eigenschappen van de teruggegeven nodes en relaties kunnen teruggeven. In deze clausule kun je ook elke ondersteunde aggregatiefunctie in Cypher gebruiken. Bovenaan gebruiken weCOUNT.ORDER BYclause werkt op dezelfde manier als de SQL-.LIMITwordt gebruikt om de lengte van de teruggegeven records te controleren.
Nadat we de query definiëren als een meerregelige string, geven we hem door aan de execute_query()methode van het stuurprogrammaobject en specificeren we de databasenaam (de standaard is neo4j). De uitvoer bevat altijd drie objecten:
records: Een lijst van Record objecten, elk representerend een rij in het resultaatset. Elk Record is een aangeduid tuple-achtig object waarin u velden kunt bereiken door middel van namen of indexen.samenvatting: Een ResultSummary-object dat metadata bevat over de uitvoering van de query, zoals querystatistieken en tijdgegevens.sleutels: Een lijst van strings die de kolomnamen in de resultaatset voorstellen.
We zullen later terugkomen op het summary object want we zijn vooral geïnteresseerd in records, die Record objecten bevatten. We kunnen hun informatie op halen door hun data() methode aan te roepen:
for record in records: print(record.data())
Uitvoer:
{'Team': 'Brazil', 'MatchesWon': 76}
Het resultaat toont correct dat Brazilië de meeste wereldbekerduels heeft gewonnen.
Doorgaan met queryparameters
Onze laatste zoekopdracht is niet herbruikbaar, omdat ze alleen de meest succesvolle ploeg in de wereldbekerhistorie vindt. Wat als we willen weten wie de meest succesvolle ploeg is in de EK-historie?
Dat is waar queryparameters komen in:
query = """ MATCH (t:Team)-[:WON]->(m:Match)-[:PART_OF]->(:Tournament {name: $tournament}) RETURN t.name AS Team, COUNT(m) AS MatchesWon ORDER BY MatchesWon DESC LIMIT $limit """
In deze versie van de query introduceren we twee parameters met behulp van de $ teken:
tournamentlimit
Om waarden aan de queryparameters over te geven, gebruiken we keyword-argumenten binnen execute_query:
records, summary, keys = driver.execute_query( query, database_="neo4j", tournament="UEFA Euro", limit=3, ) for record in records: print(record.data())
Uitvoer:
{'Team': 'Germany', 'MatchesWon': 30} {'Team': 'Spain', 'MatchesWon': 28} {'Team': 'Netherlands', 'MatchesWon': 23}
Er wordt altijd aangeraden queryparameters te gebruiken wanneer u over het inslaan van veranderende waarden in uw query denkt. Deze best practice beschermt uw query’s tegen Cypher injecties en laat Neo4j toe om ze te cacheren.
Schrijven naar databases met CREATE en MERGE clausules
Het schrijven van nieuwe informatie naar een bestaande database wordt op dezelfde manier uitgevoerd met execute_query maar door een CREATE clause in de query te gebruiken. Bijvoorbeeld, laten we een functie aanmaken die een nieuw knoppentype toevoegt – teamcoaches:
def add_new_coach(driver, coach_name, team_name, start_date, end_date): query = """ MATCH (t:Team {name: $team_name}) CREATE (c:Coach {name: $coach_name}) CREATE (c)-[r:COACHES]->(t) SET r.start_date = $start_date SET r.end_date = $end_date """ result = driver.execute_query( query, database_="neo4j", coach_name=coach_name, team_name=team_name, start_date=start_date, end_date=end_date ) summary = result.summary print(f"Added new coach: {coach_name} for existing team {team_name} starting from {start_date}") print(f"Nodes created: {summary.counters.nodes_created}") print(f"Relationships created: {summary.counters.relationships_created}")
De functie add_new_coach neemt vijf parameters in:
- driver: Het Neo4j-stuurprogrammaobject dat wordt gebruikt om met de database te verbinden.
coach_name: De naam van de nieuwe coach die moet worden toegevoegd.team_name: De naam van het team waar de coach aan verbonden zal worden.start_date: De datum waarop de coach begint met het coachen van het team.eind_date: De datum waarop de periode van de coach bij het team eindigt.
De Cypher-query in de functie doet het volgende:
- Kruist een bestaand Team-node met de gegeven teamnaam.
- Maakt een nieuwe Coach-node aan met de geleverde coachnaam.
- Maakt een COACHES relatie tussen de Coach en Team knooppunten.
- Stel de
start_dateenend_dateeigenschappen in op deCOACHESrelatie.
De query wordt uitgevoerd met behulp van de execute_query methode, die de query string en een dictionary van parameters neemt.
Na uitvoering print de functie:
- Een bevestigingsbericht met de coach en teamnamen en startdatum.
- Het aantal nodes gemaakt (moet 1 zijn voor de nieuwe Coach node).
- Het aantal relaties gemaakt (moet 1 zijn voor de nieuwe
COACHESrelatie).
Laat ons het voor één van de meest succesvolle coaches in de geschiedenis van het internationale voetbal, Lionel Scaloni, die drie opeenvolgende belangrijke internationale toernooien ( Wereldkampioenschap en twee Copa América’s) heeft gewonnen:
from neo4j.time import DateTime add_new_coach( driver=driver, coach_name="Lionel Scaloni", team_name="Argentina", start_date=DateTime(2018, 6, 1), end_date=None )
Output: Added new coach: Lionel Scaloni for existing team Argentina starting from 2018-06-01T00:00:00.000000000 Nodes created: 1 Relationships created: 1
In het bovenstaande fragment gebruiken we de DateTime klasse uit het neo4j.time module om een datum correct mee te geven in onze Cypher-query. Het module bevat andere nuttige tijdgerelateerde data types die u misschien wilt bekijken.
NaastCREATE bestaat er ook deMERGE clausule voor het maken van nieuwe knopen en relaties. hun belangrijkste verschil is:
CREATEmaakt altijd nieuwe knopen/relaties, wat potentieel duplicaten kan veroorzaken.MERGEmaakt alleen nodes/relaties aan als ze nog niet bestaan.
Bijvoorbeeld, in ons data ingestion script, zoals u later zult zien:
- We hebben
MERGEgebruikt voor teams en spelers om duplicaten te vermijden. - We gebruikten
CREATEvoorSCORED_FORenSCORED_INrelaties omdat een speler meerdere malen in één wedstrijd kan scoren. - Dit zijn geen ware dubbelingen omdat ze verschillende eigenschappen hebben (bijv., minuut van doelpunt).
Deze aanpak waarborgt de data integriteit terwijl het toegestane wordt om meerdere gelijkaardige, maar verschillende relaties te hebben.
Uw eigen transacties uitvoeren
Wanneer u execute_query uitvoert, maakt de driver een transactie aan de achterkant. Een transactie is een eenheid van werk die ofwel zijn gehele uitvoering voltooid wordt ofwel teruggetrokken wordt als een fout. Dit betekend dat wanneer u in één transactie duizenden knooppunten of relaties aanmaakt (het is mogelijk) en er een fout wordt ondervonden in het midden, de gehele transactie mislukt zonder enige nieuwe gegevens te schrijven naar het graafschap.
Om elke transactie fijnere controle over te hebben, moet je sessieobjecten aanmaken. Bijvoorbeeld, laten we een functie maken om de top K doelpunten te vinden in een gegeven toernooi met behulp van een sessieobject:
def top_goal_scorers(tx, tournament, limit): query = """ MATCH (p:Player)-[s:SCORED_IN]->(m:Match)-[PART_OF]->(t:Tournament) WHERE t.name = $tournament RETURN p.name AS Player, COUNT(s) AS Goals ORDER BY Goals DESC LIMIT $limit """ result = tx.run(query, tournament=tournament, limit=limit) return [record.data() for record in result]
Eerst maken we top_goal_scorers functie die drie parameters accepteert, waarvan het belangrijkste het tx transactieobject is dat verkregen wordt met behulp van een sessieobject.
with driver.session() as session: result = session.execute_read(top_goal_scorers, "FIFA World Cup", 5) for record in result: print(record)
Output:
{'Player': 'Miroslav Klose', 'Goals': 16} {'Player': 'Ronaldo', 'Goals': 15} {'Player': 'Gerd Müller', 'Goals': 14} {'Player': 'Just Fontaine', 'Goals': 13} {'Player': 'Lionel Messi', 'Goals': 13}
Vervolgens gebruikt men onder een context manager aangemaakt met de session()methode, deexecute_read()functie, door detop_goal_scorers()functie mee te geven, en eventuele parameters die de query nodig heeft.
De uitvoer vanexecute_read is een lijst van Record objecten die correct de top 5 doelpuntenmakers in de geschiedenis van het Wereldkampioenschap weergeven, inclusief namen als Miroslav Klose, Ronaldo Nazario en Lionel Messi.
Het tegenovergestelde vanexecute_read() voor gegevens invoer isexecute_write().
Met dat gezegd, laten we nu kijken naar het innamescript dat we eerder gebruikten om een idee te krijgen over hoe gegevens inname werkt met de Neo4j Python driver.
Gegevensinname met de Neo4j Python driver
Het ingest_football_data.py bestand begint met import statements en het laden van de nodige CSV bestanden:
import pandas as pd import neo4j from dotenv import load_dotenv import os from tqdm import tqdm import logging CSV bestandpaden results_csv_path = "https://raw.githubusercontent.com/martj42/international_results/refs/heads/master/results.csv" goalscorers_csv_path = "https://raw.githubusercontent.com/martj42/international_results/refs/heads/master/goalscorers.csv" shootouts_csv_path = "https://raw.githubusercontent.com/martj42/international_results/refs/heads/master/shootouts.csv" Logboek instellen logging.basicConfig(level=logging.INFO) logger = logging.getLogger(__name__) logger.info("Loading data...") Data laden results_df = pd.read_csv(results_csv_path, parse_dates=["date"]) goalscorers_df = pd.read_csv(goalscorers_csv_path, parse_dates=["date"]) shootouts_df = pd.read_csv(shootouts_csv_path, parse_dates=["date"])
Dit codeblok stelt ook een logboeker in. De volgende enkele regels van code lezen mijn Neo4j-gegevens in met behulp van dotenv en maakt een Driver-object aan:
uri = os.getenv("NEO4J_URI") user = os.getenv("NEO4J_USERNAME") password = os.getenv("NEO4J_PASSWORD") try: driver = neo4j.GraphDatabase.driver(uri, auth=(user, password)) print("Connected to Neo4j instance successfully!") except Exception as e: print(f"Failed to connect to Neo4j: {e}") BATCH_SIZE = 5000
Omdat er meer dan 48k overeenkomsten in onze database zijn, definiëren we een BATCH_SIZE parameter om data in kleinere monsters in te zetten.
Dan definieerden we een functie genaamdcreate_indexes die een sessieobject accepteert:
def create_indexes(session): indexes = [ "CREATE INDEX IF NOT EXISTS FOR (t:Team) ON (t.name)", "CREATE INDEX IF NOT EXISTS FOR (m:Match) ON (m.id)", "CREATE INDEX IF NOT EXISTS FOR (p:Player) ON (p.name)", "CREATE INDEX IF NOT EXISTS FOR (t:Tournament) ON (t.name)", "CREATE INDEX IF NOT EXISTS FOR (c:City) ON (c.name)", "CREATE INDEX IF NOT EXISTS FOR (c:Country) ON (c.name)", ] for index in indexes: session.run(index) print("Indexes created.")
Cypher indexen zijn databasestructuren die de queryprestaties verbeteren in Neo4j. Ze versnellen het proces van het vinden van knoopkenmerken of relaties op basis van specifieke eigenschappen. We hebben ze nodig voor:
- Snellere queryuitvoering
- Verbeterde leesprestaties op grote datasets
- Efficiente patronenmatchen
- Enforcing unique constraints
- Beter schaalbaarheid als de database groeit
In ons geval zullen indexen op teamnamen, match ID’s en spelernamen helpen onze queries sneller te worden bij het zoeken naar specifieke entiteiten of het uitvoeren van joins over verschillende node typen. Het is een best practice om dergelijke indexen voor uw eigen databases aan te maken.
Volgend hebben we deingest_matchesfunctie. Het is groot, dus laten we het op blokken breken:
def ingest_matches(session, df): query = """ UNWIND $batch AS row MERGE (m:Match {id: row.id}) SET m.date = date(row.date), m.home_score = row.home_score, m.away_score = row.away_score, m.neutral = row.neutral MERGE (home:Team {name: row.home_team}) MERGE (away:Team {name: row.away_team}) MERGE (t:Tournament {name: row.tournament}) MERGE (c:City {name: row.city}) MERGE (country:Country {name: row.country}) MERGE (home)-[:PLAYED_HOME]->(m) MERGE (away)-[:PLAYED_AWAY]->(m) MERGE (m)-[:PART_OF]->(t) MERGE (m)-[:PLAYED_IN]->(c) MERGE (c)-[:LOCATED_IN]->(country) WITH m, home, away, row.home_score AS hs, row.away_score AS as FOREACH(_ IN CASE WHEN hs > as THEN [1] ELSE [] END | MERGE (home)-[:WON]->(m) MERGE (away)-[:LOST]->(m) ) FOREACH(_ IN CASE WHEN hs < as THEN [1] ELSE [] END | MERGE (away)-[:WON]->(m) MERGE (home)-[:LOST]->(m) ) FOREACH(_ IN CASE WHEN hs = as THEN [1] ELSE [] END | MERGE (home)-[:DREW]->(m) MERGE (away)-[:DREW]->(m) ) """ ...
De eerste zaak die u opmerkt is het UNWIND keyword, dat wordt gebruikt om een batch gegevens te verwerken. Het neemt de $batch parameter (die onze DataFrame-rijen zullen zijn) en itereert over elke rij, waardoor we meerdere nodes en relaties in één transactie kunnen aanmaken of bijwerken. Deze aanpak is efficienter dan elke rij individueel te verwerken, vooral voor grote datasets.
Het overige deel van de query is bekend omdat het meerdere MERGE clauses gebruikt. Vervolgens komt de WITH clause, die FOREACH constructs gebruikt met IN CASE statements. Deze worden gebruikt om conditioneel relaties te maken op basis van het resultaat van de wedstrijd. Als de thuisspelende ploeg wint, maakt het een ‘WON’ relatie voor de thuisspelende ploeg en een ‘LOST’ relatie voor de uitgeschakelde ploeg, en vice versa. In geval van een gelijkspel krijgen beide teams een ‘DREW’ relatie met de wedstrijd.
De rest van de functie deelt de inkomende DataFrame in in overeenkomsten en bouwt de gegevens op die doorgegeven zullen worden aan de $batch queryparameter:
def ingest_matches(session, df): query = """...""" for i in tqdm(range(0, len(df), BATCH_SIZE), desc="Ingesting matches"): batch = df.iloc[i : i + BATCH_SIZE] data = [] for _, row in batch.iterrows(): match_data = { "id": f"{row['date']}_{row['home_team']}_{row['away_team']}", "date": row["date"].strftime("%Y-%m-%d"), "home_score": int(row["home_score"]), "away_score": int(row["away_score"]), "neutral": bool(row["neutral"]), "home_team": row["home_team"], "away_team": row["away_team"], "tournament": row["tournament"], "city": row["city"], "country": row["country"], } data.append(match_data) session.run(query, batch=data)
ingest_goals en ingest_shootouts functies gebruiken vergelijkbare constructies. Echter, ingest_goals hebben enige extra fout- en ontbrekende waarden behandeling.
Aan het einde van het script hebben we de main()functie die alle onze invoerfuncties uitvoert met een sessieobject:
def main(): with driver.session() as session: create_indexes(session) ingest_matches(session, results_df) ingest_goals(session, goalscorers_df) ingest_shootouts(session, shootouts_df) print("Data ingestion completed!") driver.close() if __name__ == "__main__": main()
Conclusie en volgende stappen
We hebben de belangrijkste aspecten behandeld van het werken met Neo4j-graaf databases met Python:
- Graafdatabase concepten en structuur
- Instellen van Neo4j AuraDB
- Basis van de Cypher-querytaal
- Gebruik van de Neo4j Python stuurprogramma
- Data ingevoerden en query optimalisatie
Om uw Neo4j reis verder te zetten, ontdek deze bronnen:
- Neo4j Documentatie
- Neo4j Graph Data Science Bibliotheek
- Neo4j Cypher Handleiding
- Neo4j Python Stuurprogramma Documentatie
- Data Engineering Carrièrecertificering
- Inleiding tot NoSQL
- Een uitgebreide NoSQL-handleiding gebruikmakend van MongoDB
Onthoud, de kracht van grafische databases ligt in het weergeven en doorstellen van complexe relaties. Blijf experimenteren met verschillende datamodellen en ontdek de geavanceerde Cypher-mogelijkheden.