













데이터 科学家은 이早期에 SQL을 배우는 것을 시작합니다. 관련 정보가 omnipresent하고 high utility를 가지는 table information에 의해 이해가 되는 것입니다. 그러나, relational SQL database에 맞춰지지 않는 connected data를 저장하기 위한 다른 successful database formats도 있습니다. 이 tutorial에서는 Neo4j, Python에서 graph database를 생성, 관리, 조회하는 수dot graph database management system을 배울 것입니다.
그래프 데이터베이스는?
Neo4j에 대해서 이전에 이해하기 위해서 graph databases에 대해서 더욱 자세하게 이해하는 것을 시도합니다. 우리는 graph databases는 무엇인지에 대한 full article를 설명하고 있으며, 그러므로 여기에서 key points를 요약하겠습니다.
그래프 databases는 NoSQL database의 일종(SQL을 사용하지 않는다)로, 연결된 data를 관리하기 위해 설계되었습니다. 传统的 relational databases가 사용하는 表과 行에 비해, 그래프 databases는 다음과 같은 그래프 구조를 사용합니다:
- Nodes (entities) such as people, places, concepts
- 간선(관계)는 다양한 노드를 인물 LIVES IN 一个地方를 연결하거나, 축구 멤버 SCORED IN 一个경기.
- 노드나 エッジ의 속성(속성)는 인물의 나이나, 경기 중 골이 scored 됐는지 등이 있습니다.
이 구조는 사회 네트워크, 추천, 사기 감지 등의 필드와 응용 area에서 interconnected data를 처리하기 위해 ideal한 그래프 데이터베이스입니다. relational DBs와 비교해서 자주 querying efficiency에서 좋은 성능을 보여줍니다. 以下은 축구 데이터셋을 위한 샘플 그래프 데이터베이스의 구조입니다:
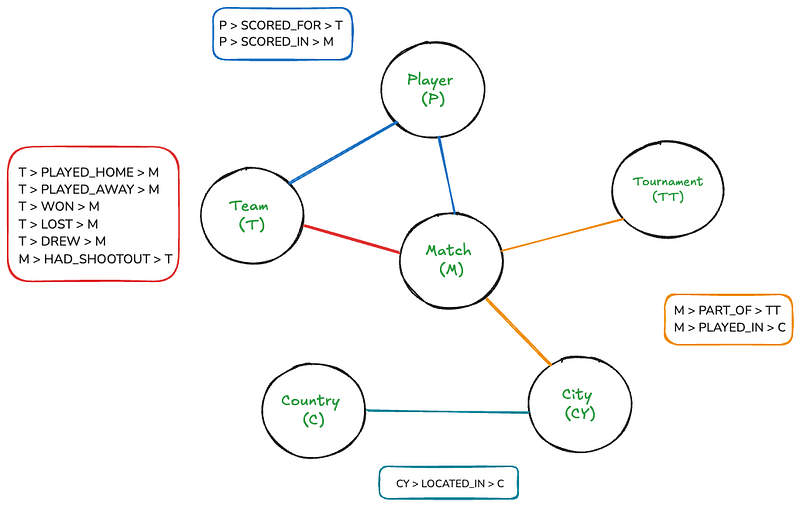
이 그래프가 사람들에게 直观적인 것을 나타내는 것 虽然如此, 캔버스에 그려지면 상당히 错綜复杂해 질 수 있습니다. 그러나 Neo4j로 이 그래프를 이용하여 탐색하는 것은 간단한 SQL 조인을 썼다는 것 同等의 것입니다.SQL 조인.
그래프는 여섯 노드가 있습니다: マッチ, 팀, 대회, プレイ어, 국가 및 도시。 사각형은 노드 사이의 관계를 列出합니다。 또한 몇몇 노드와 관계 속성이 있습니다:
- 매치: 날짜, 홈_점수, 어웨이_점수
- 팀: 이름
- 선수: 이름
- 토너AMENT: 이름
- 도시: 이름
- 국가: 이름
- SCORED_FOR, SCORED_IN: 분, 자책골, 페널티
- HAD_SHOOTOUT: 승자, 첫_슈팅자
이 스키마는 다음을 표현할 수 있습니다:
- 모든 경기及其 점수, 날짜, 그리고 장소
- 각 경기에 참가하는 팀(主队과 客队)
- 골을 踢하는 選手, 이를 위해 분, 자신의 골, 以及 ペナル티 등의 세부 정보
- 경기가 일부로 constitutive 하는 turnamnet
- 경기가 行われ는 도시及其 국가
- 이벤트 정보, 그리고 우승자와 첫 샷 촉진자(가능하면)
스키마는 지역의 层次적 性质(도시 내 국가)과 각 엔티티 간의 다양한 관계(예를 들어, 팀과 матче 사이의 경기, 경기에서 팀에 得点를 공Script 하는 선수)을 捉えます.
이 구조는 靈活한 조회를 가능하게 합니다. 예를 들어, 두 팀 사이의 모든 경기, 선수가 得分的 모든 골, 또는 특정 토urnament 또는 지역에서의 모든 경기를 찾을 수 있습니다.
하지만 자신의 이전에 가기로 해봅시다. 시작으로는 Neo4j와 그 이유가 무엇인가요?
Neo4j은 무엇입니까?
그래픽 디비 관리의 leading 명칭 Neo4j는 강력한 기능과 다양성을 知られ고 있습니다.
Neo4j은 닉named 그래프 저장소를 사용하여 그래프 opera tions를 실시하는데 대 한 고 级 적 優 良 를 이 달 로 하 고 있다. 복잡한 관계를 처리하기 위한 효율성은 연결 된 자료를 관리하는 데 전 통 적 데이터 베이스를 뛰어나게 만들었다. Neo4j의 ス케 일 러 기 능은 실제로 감 ulpriting이 되 며 数十억 단위의 노드와 관계를 어느 정도에서も 문제 없이 처리할 수 있어 대 한 규 모의 프로젝트에서 large enterprises에서 적용할 수 있다.
Neo4j의 다른 주요 부 분은 데이터 정합성이 있다. atomicity, Consistency, Isolation, Durability) 요구 사항을 전 不接受하며 트랜잭션의 신뢰성과 일관성을 제공한다.
트랜잭션을 말할 때, 그 쿼리 언어인 Cypher는 그래프 패턴을 위한 매우 直觀적이고 서술적인 문법을 제공하고 있으며 이를 原因으로 그 문법은 ASCII art라는 별칭을 얻었다. Cypher를 배우기는 SQL을 잘 알고 있다면 어려울 것이 없다.
Cypher를 사용하여 기존의 쿼리나 스키마를 突破하지 않고 新区画, 관계, 또는 속성을 추가하는 것은 簡単합니다. 현대 開発 환경의 빠른 変更 요구에 적응할 수 있습니다.
Neo4j에는 充実した 生態系 지원이 あります. 幅広い 文档, 그래프를 可视化하는 인자적인 도구, 활発한 コミュニティ, Python, Java, JavaScript 등 다양한 프로그래밍 언어와의 統合이 있습니다.
Neo4j과 Python 環境 설정
Neo4j과 工作中的하는 것에 들어가기 전に 우리의 環境을 설정해야 합니다. 이 섹션은 Neo4j 데이터베이스를 호스트하기 위한 클라우드 인스턴스를 생성하고, Python 环境을 설정하고, 두 가지를 사이에 연결하는 것을 指导할 것입니다.
Neo4j을 설치하지 않는다.
Neo4j의 로컬 그래픽 데이터베이스로 작업하려면 java를 포함한 의존성들과 함께 다운로드 및 로컬에 설치해야 합니다. 그러나 대부분의 경우에는 어느 클라oud 환경에서 존재하는 기존 remotely Neo4j 데이터베이스와 interacting하게 될 것입니다.
이 이유 때문에, 우리는 네오4j를 我们的 시스템에 설치하지 않을 것입니다. 대신, 네오4j의 完全托管 클라우드 서비스인 Aura에서 免费的 데이터베이스 인스턴스를 만들 것입니다. 그리고, neo4j Python 클라이언트 라이브러리를 사용하여 이 데이터베이스에 연결하고 데이터를 삽입하겠습니다.
Neo4j Aura DB 인스턴스 생성
Aura DB에서 무료 그래프 데이터베이스를 호스트하려면 제품 페이지에 방문하고 “무료로 시작하기”를 클릭하십시오.
등록하면 사용 가능한 플랜들이 표시되며, 무료 옵션을 선택해야 합니다. 그러면 사용자 이름과 패스워드를 가진 새 인스턴스를 받게 됩니다.:
패스워드, 사용자 이름, 그리고 연결 URI를 복사하십시오.
그다음, 新的 작업 디렉터리를 생성하고 .env 파일을 생성하여 您的 인증 정보를 저장합니다:
$ mkdir neo4j_tutorial; cd neo4j_tutorial $ touch .env
다음 내용을 파일 안에 붙여넣습니다:
NEO4J_USERNAME="YOUR-NEO4J-USERNAME" NEO4J_PASSWORD="YOUR-COPIED-NEO4J-PASSWORD" NEO4J_CONNECTION_URI="YOUR-COPIED-NEO4J-URI"
Python 환경 세팅
이제, 新的 Conda 환경에 neo4j Python 클라이언트 라이브러리를 安装합니다:
$ conda create -n neo4j_tutorial python=3.9 -y $ conda activate neo4j_tutorial $ pip install ipykernel # Jupyter에 환경을 추가하기 위한 $ ipython kernel install --user --name=neo4j_tutorial $ pip install neo4j python-dotenv tqdm pandas
이 명령은 ipykernel 라이브러리를 설치하고 이를 사용하여 새로 만든 Conda 환경을 Jupyter의 커널로 추가합니다. 그런 다음, neo4j Python 클라이언트를 설치하여 Neo4j 데이터베이스와 상호 작용하고 python-dotenv를 설치하여 Neo4j 자격 증명을 안전하게 관리합니다.
AuraDB 인스턴스에 축구 데이터 채우기
그래프 데이터베이스에 데이터 이冒着하는 과정은 Cypher 기본 지식이 필요한 错综复杂的 과정입니다. 우리는 아직 Cypher의 기본을 배웠지 않았기 때문에, 글에 错杂하게 만들었던 Python 스크립트를 사용하여 실제 세계적인 역사적 축구 데이터를 자동으로 이冒着하게 한다. 스크립트는 错杂하게 보관하신 인증정보를 사용하여 あなた의 AuraDB 인스턴스와 연결할 것입니다.
足 football 데이터는 이 Kaggle datasets 에서 국际적인 足 football 경기 를 기록한 것입니다. 1872 년부터 2024 년까지의 데이터가 CSV 형식으로 제공되어 있으며, 스크립트는 그 것을 분해하고 Cypher와 Neo4j를 사용하여 그래프 형태로 변환합니다. 記事의 뒷부분에서, 이러한 기술에 대해 충분히 자세히 알면서, 스크립트를 한 줄씩 다시 보며 足 football 데이터를 그래프로 어떻게 변환하는지 이해할 수 있습니다.
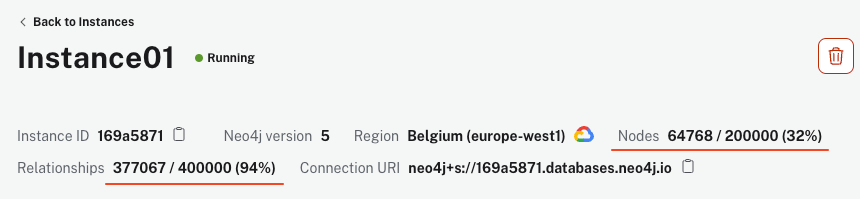
여기는 실행하기 위한 명령어들이다. AuraDB 인스턴스를 설정하고 您的 凭据을 작업 디렉터리에서 .env 파일에 저장했다고 확신하시기 바랍니다.스크립트가 실행되는 것은 计算机과 인터넷 연결의 상황에 따라 몇 분이 걸릴 수 있으며, 하지만 실행이 끝나면 AuraDB 인스턴스는 64k 이상의 노드와 340k 이상의 관계를 보여야 합니다.
$ wget https://raw.githubusercontent.com/BexTuychiev/medium_stories/refs/heads/master/2024/9_september/3_neo4j_python/ingest_football_data.py $ python ingest_football_data.py
Python에서 Neo4j로 연결하는 것
이제 우리의 Aura DB 인스턴스에 연결할 준비가 되었습니다. 우선 .env 파일에서 dotenv를 사용하여 자격 증명을 읽어들일 것입니다:
import os from dotenv import load_dotenv load_dotenv() NEO4J_USERNAME = os.getenv("NEO4J_USERNAME") NEO4J_PASSWORD = os.getenv("NEO4J_PASSWORD") NEO4J_URI = os.getenv("NEO4J_URI")
이제 연결을 설정해봅시다:
from neo4j import GraphDatabase uri = NEO4J_URI username = NEO4J_USERNAME password = NEO4J_PASSWORD driver = GraphDatabase.driver(uri, auth=(username, password)) try: driver.verify_connectivity() print("Connection successful!") except Exception as e: print(f"Failed to connect to Neo4j: {e}")
출력:
Connection successful!
다음은 코드에 대한 설명입니다:
- 우리는
GraphDatabase를neo4j에서 가져와 Neo4j와 상호 작용하기 위해서 - 이전에 로드한 환경 변수를 사용하여 我们的 연결을 설정합니다 (
uri,username,password). - 우리는
GraphDatabase.driver()을 이용하여 드라이버 오브젝트를 생성하여 Neo4j 데이터베이스에 연결하고자 합니다. -
with블록 하에서는verify_connectivity()함수를 사용하여 연결이 생성되었는지 확인합니다. 기본적으로verify_connectivity()는 연결이 성공할 경우 아무 것도 반환하지 않습니다.
튜토리얼이 끝나면, driver.close()를 호출하여 연결을 종료하고 자원을 解放하십시오. 드라이버 오브젝트는 생성하기 어려우니, 어플리케이션에 대해 단일 오브젝트만 생성해야 합니다.
Cypher 쿼리 언어 기본
Cypher의 문법은 인지하기 容易하고 그래프 구조를 直观적으로 표현할 수 있도록 設計되었습니다. 다음과 같은 ASCII-아트 유형의 문법을 사용합니다.:
(nodes)-[:CONNECT_TO]->(other_nodes)
이 일반 쿼리 패턴의 주요 组成部分을 분해해봅시다:
1. 노드
Cypher 쿼리에서 괄호안의 키워드는 노드 이름을 의미합니다. 예를 들어, (Player)는 모든 Player 노드를 일치시키고 있습니다. 대부분의 경우, 노드 이름을 별칭(alias)로 사용하여 쿼리를 더 읽기 쉽고, 쓰기 간편하며 좁혀질 수 있습니다. 노드 이름에 별칭을 추가하는 것은 colon(:)를 이전에 기술하면 가능합니다: (m:Match).
괄호 안에서는 하나 이상의 노드 속성을 지정할 수 있습니다. 이를 사전 유사의 문법을 사용하여 정확한 일치를 실시합니다. 예를 들어:
// FIFA World Cup로 모든 토너먼트 노드 (t:Tournament {name: "FIFA World Cup"})
노드 속성은 그냥 쓰면 되고, 원하는 값은 문자열이 되어야 합니다.
2. 관계
노드를 서로 연결하는 관계로, 직사각형 brackes와 화살표로 WRAP되어 있습니다.
// 某些 турнира의 PART_OF 노드와 일치 (m:Match)-[PART_OF]->(t:Tournament)
관계에 별칭과 속성을 추가하는 것도 가능합니다:
// 브라zil이 패널리 shootout에 참가하고 첫 번째 샷을 쳤다는 일치 (p:Player) - [r:SCORED_FOR {minute: 90}] -> (t:Team)
관계는 화살표로 WRAPPED-[RELATIONSHIP]->. 다시 한 번, 별명 속성을 괄호 안에 포함할 수 있습니다. 例如:
// 自己的 골을 踢scored的所有玩家 (p:Player)-[r:SCORED_IN {own_goal: True}]->(m:Match)
3. 조건문
지금처럼COUNT(*) FROM table_name SQL에서 SELECT CLAUSE를 생략하면 아무 것도 리턴하지 않는 것처럼, (node) - [RELATIONSHIP] -> (node) 也是一样, 결과를 가져올 수 없다. 따라서, SQL과 마찬가지로, Cypher는 다양한 CLAUSE를 가지고 있어 쿼리 로직을 구성할 수 있다.
MATCH: 그래프内의 패턴 매치WHERE: 결과를 過濾RETURN: 결과 집합에 포함할 것을 지정CREATE: 새로운 노드 또는 관계를 생성MERGE: 고유한 노드 또는 관계 생성DELETE: 노드, 관계 또는 속성 제거SET: 레이블 및 속성 갱신
이 주제를 보여주는 예시 쿼리가 다음과 같습니다.
MATCH (p:Player)-[s:SCORED_IN]->(m:Match)-[PART_OF]->(t:Tournament) WHERE t.name = "FIFA World Cup" AND s.minute > 80 AND s.own_goal = True RETURN p.name AS Player, m.date AS MatchDate, s.minute AS GoalMinute ORDER BY s.minute DESC LIMIT 5
이 쿼리는 80분 이후에 월드 컵 경기에서 자신의 球을 得点로 记録한 모든 선수를 찾는다. 이 쿼리는 SQL의 것처럼 보인다는 것 마저 더해, 하지만 그 쿼리의 SQL 동등물은 至少 한가지 JOIN 사용이 필요하다.
Neo4j Python Driver을 사용하여 그래프 데이터베이스를 분석하기
Python 응용 프로그램을 통해 Neo4j 인스턴스와 통신하는 공식 라이브러리인 Neo4j Python driver를 사용하여 쿼리를 실행하기execute_query
Neo4j Python driver는 Neo4j 인스턴스와 Python 응용 프로그램을 사용하여 통신하는 공식 라이브러리이다. plain Python strings로 썼던 Cypher 쿼리를 Neo4j 서버로 보낸다고 생각하면 된다. 그리고 결과를 통합 형식으로 가져온다.
모든 것은 GraphDatabase 클래스로 드라이버 객체를 생성하는 것에서 시작됩니다. 그리고서, execute_query 메서드를 사용하여 쿼리를 보낼 수 있습니다.
첫 번째 쿼리를 위해, 좀 더 흥미로운 질문을 해봅시다: 가장 많은 월드컵 경기를 이긴 팀은 무엇입니까?
# 가장 많은 월드컵 경기를 이긴 팀을 반환합니다 query = """ MATCH (t:Team)-[:WON]->(m:Match)-[:PART_OF]->(:Tournament {name: "FIFA World Cup"}) RETURN t.name AS Team, COUNT(m) AS MatchesWon ORDER BY MatchesWon DESC LIMIT 1 """ records, summary, keys = driver.execute_query(query, database_="neo4j")
우선, 쿼리를 분석해봅시다:
- 다음은
MATCH닫는 태그는 우리가 원하는 패턴을 정의합니다: 팀 -> 승리 -> 경기 -> 일부 -> 토너먼트 RETURN은 SQL의SELECT문의 pendant 입니다. 여기서는 반환된 노드 및 관계의 속성을 반환할 수 있습니다. 이 CLAUSE에서는 Cypher에서 지원하는 모든 집계 함수를 사용할 수 있습니다. 위에서는COUNT를 사용하고 있습니다.- ORDER BY 절은 SQL의 것과 같은 방식으로 작동합니다.
- LIMIT는 반환된 레코드의 길이를 제어하는 데 사용합니다.
우리는 쿼리를 다중 行 문자열로 정의한 다음, 이를 드라이버 오브젝트의 execute_query() 方法的에 전달하고 데이터베이스 이름(기본값은 neo4j)를 지정합니다. 출력은 항상 세 개의 개체를 포함합니다:
records: 결과 세트의 每一 行을 表시하는 Record 개체의 목록입니다. 각 Record는 이름이나 인덱스를 통해 필드에 アクセス 할 수 있는 이름 튜플 like 오브젝트입니다.summarize: 쿼리 실행에 대한 metadata, 如实例 통계 정보와 시간 정보를 포함하는 결과 汇总 객체keys: 결과 집합 内의 열 이름을 나타내는 문자열 리스트
우리는 summary 오브젝트에 대해 나중에 짚는 것이 因为我们主要关注的是 records, 그리고 그들은 Record 오브젝트를 포함하고 있다. 그들의 정보를 호출하면 data() 메서드를 사용하여 값을 가져올 수 있다:
for record in records: print(record.data())
결과:
{'Team': 'Brazil', 'MatchesWon': 76}
브라질이 가장 많은 월드 컵 경기를 이겼다 正確하게 보여줍니다.
조회 쿼리 パラ미터 전달
우리의 마지막 쿼리는 다시 사용할 수 없습니다, 왜냐하면 그것은 월드 컵 역사에서 가장 성공적인 팀을 찾는 것뿐입니다. 如果我们想找到 Euro 历史上的最成功的球队怎么办?
이러한 경우 쿼리 파라미터가 도움이 됩니다.:
query = """ MATCH (t:Team)-[:WON]->(m:Match)-[:PART_OF]->(:Tournament {name: $tournament}) RETURN t.name AS Team, COUNT(m) AS MatchesWon ORDER BY MatchesWon DESC LIMIT $limit """
이 버전의 쿼리에서는 $ 기호를 사용하여 두 개의 매개변수를 introduce하고 있습니다.
tournamentlimit
매개변수에 값을 전달하기 위해서는, 쿼리 매개변수로 값을 전달하는 키워드 인자를 execute_query에서 사용합니다.
records, summary, keys = driver.execute_query( query, database_="neo4j", tournament="UEFA Euro", limit=3, ) for record in records: print(record.data())
산출:
{'Team': 'Germany', 'MatchesWon': 30} {'Team': 'Spain', 'MatchesWon': 28} {'Team': 'Netherlands', 'MatchesWon': 23}
쿼리 파라미터를 사용하는 것이 任何时候 쿼리에 변하는 값을 삽입하고 있을 때에도 좋습니다. 이러한 ベスト 实践는 쿼리들을 Cypher 인젝션에 대한 보호를 제공하고 Neo4j로부터 그들을 キャッシュ할 수 있도록 지원합니다.
CREATE과 MERGE CLAUSE를 사용하여 데이터베이스에 書き込む
이미 存在하는 데이터베이스에 새로운 정보를 쓰는 것은 execute_query를 사용하여 CREATE CLAUSE를 사용하여 query를 실행하는 것과 유사합니다. 예를 들어, 새로운 노드 유형 – 팀 코칭을 추가하는 함수를 만듭니다:
def add_new_coach(driver, coach_name, team_name, start_date, end_date): query = """ MATCH (t:Team {name: $team_name}) CREATE (c:Coach {name: $coach_name}) CREATE (c)-[r:COACHES]->(t) SET r.start_date = $start_date SET r.end_date = $end_date """ result = driver.execute_query( query, database_="neo4j", coach_name=coach_name, team_name=team_name, start_date=start_date, end_date=end_date ) summary = result.summary print(f"Added new coach: {coach_name} for existing team {team_name} starting from {start_date}") print(f"Nodes created: {summary.counters.nodes_created}") print(f"Relationships created: {summary.counters.relationships_created}")
함수 add_new_coach는 다섯 개의 매개 변수를 받습니다:
- 드라이버: Neo4j 드라이버 오브젝트, 데이터베이스에 연결하는 용도입니다.
coach_name: 추가 예정인 코치의 이름입니다.team_name: 코치가 연결 될 tea m의 이름입니다.start_date: 코치가 팀을 coaching 하기 시작한 날짜.end_date: 코치가 팀과의 tenure 끝나는 날짜.
function 내에서의 Cypher 쿼리는 다음과 같은 일을 한다.
- 주어진 team name으로 existing Team node와 일치시킨다.
- 제공된 coach name로 new Coach node를 생성한다.
- 코치와 팀 노드 사이에 COACHES 관계를 생성합니다.
-
start_date와end_date속성을COACHES관계에 설정합니다.
쿼리는 execute_query 方法을 사용하여 실행되며, 쿼리 문자열과 パラメー터 딕셔너리가 제공되ます.
실행 후, 함수는 다음을 인쇄합니다:
- 코칭 과 팀 이름과 시작 날짜를 포함한 확인 메시지.
- 생성된 노드 수(新しい 코칭 노드의 경우 1이 应为).
- 생성된 관계 수(新しい
COACHES관계의 경우 1이 应为).
국제 축구 역사에서 가장 성공적인 코ACH 중 하나, 리오anel Scaloni의 샘플 실행입니다. 그는 세 연속 주요 국제 turnament(월드 컵과 두 대 아메리カ 챌린지)을 이complished 했습니다.
from neo4j.time import DateTime add_new_coach( driver=driver, coach_name="Lionel Scaloni", team_name="Argentina", start_date=DateTime(2018, 6, 1), end_date=None )
Output: Added new coach: Lionel Scaloni for existing team Argentina starting from 2018-06-01T00:00:00.000000000 Nodes created: 1 Relationships created: 1
위 샘플에서는 DateTime 클래스를 neo4j.time 모듈から 我们的Cypher 查询に正しい日付を渡すために 사용하고 있습니다. 모듈는 다른 유용한 시간 관련 자료 형식을 확인하고 싶으시면 살펴보실 수 있습니다.
CREATE 를 MERGE CLAUSE로
CREATE는 항상 새로운 노드/관계를 생성하며, 중복 발생의 가능성이 있습니다.MERGE은 이미 存在하지 않는 노드/관계가 있는지 확인하고 있다면 그들을 생성하지 않습니다.
예를 들어, 나중에 보실 데이터 인gestion 스크립트에서:
- 우리는
MERGE를 팀과 لاعب들에 대해 중복을 避ける ために 사용했습니다. - 우리는
CREATE를SCORED_FOR와SCORED_IN관계에 대해 사용하었습니다. 왜냐하면 하나의 경기에서 멀티 스코어를 할 수 있기 때문입니다. - 이러한 항목은 진짜 덮어쓰기가 아닌 것입니다. 이러한 항목은 다른 속성을 가지고 있습니다(예를 들어, 골 분).
이 방법은 데이터 整실性을 보장하면서 다양한 유사하지만 區別적인 관계를 허용합니다.
자신의 트랜잭션을 실행하는 것
当你运行execute_query时,驱动程序会在幕后创建一个事务。事务是工作单元,要么完全执行,要么在失败时回滚。这意味着当你在单个事务中创建数千个节点或关系(这是可能的)并在中间遇到错误时,整个事务会失败,而不会将任何新数据写入图形。
각 트랜잭션에 더 세micron precise control을 가지기 위해서, 세micron session objects를 생성해야 합니다. 예를 들어서, session objects를 사용하여 주어진 turnament에서 top K goal scores를 찾는 함수를 생성하겠습니다:
def top_goal_scorers(tx, tournament, limit): query = """ MATCH (p:Player)-[s:SCORED_IN]->(m:Match)-[PART_OF]->(t:Tournament) WHERE t.name = $tournament RETURN p.name AS Player, COUNT(s) AS Goals ORDER BY Goals DESC LIMIT $limit """ result = tx.run(query, tournament=tournament, limit=limit) return [record.data() for record in result]
まず, top_goal_scorers 함수를 생성하는데, 세micron 중요한 매개 변수가 있는데, 그것은 tx transaction object를 얻기 위해 session object를 사용하는 것입니다.
with driver.session() as session: result = session.execute_read(top_goal_scorers, "FIFA World Cup", 5) for record in result: print(record)
Output:
{'Player': 'Miroslav Klose', 'Goals': 16} {'Player': 'Ronaldo', 'Goals': 15} {'Player': 'Gerd Müller', 'Goals': 14} {'Player': 'Just Fontaine', 'Goals': 13} {'Player': 'Lionel Messi', 'Goals': 13}
그 다음, session() 方法으로 생성한 上下文 관리자 안에서, execute_read() 를 사용하여, top_goal_scorers() 함수를 전달하고, 쿼리에 필요한 모든 매개 변수를 함께 사용합니다.
의 출력은 execute_read는 Miroslav Klose, Ronaldo Nazario, Lionel Messi와 같은 이름들을 포함한 월드컵 역사상 상위 5위의 득점왕을 올바르게 보여주는 Record 객체 리스트입니다.
데이터 삽입을 위한 execute_read()의 상대적인 것은 execute_write()입니다.
이렇게 말하고 있어, 이제 Neo4j Python 드라이버와 데이터 인gestion의 동작 구조를 이해하기 위해 이전에 사용했던 인gestion 스크립트를 살펴봐야겠습니다.
Neo4j Python 드라이버를 사용한 데이터 인gestion
The ingest_football_data.py 파일은 import 문으로 시작하고 CSV 파일을 불러오는 과정을 포함합니다:
import pandas as pd import neo4j from dotenv import load_dotenv import os from tqdm import tqdm import logging CSV 파일 경로 results_csv_path = "https://raw.githubusercontent.com/martj42/international_results/refs/heads/master/results.csv" goalscorers_csv_path = "https://raw.githubusercontent.com/martj42/international_results/refs/heads/master/goalscorers.csv" shootouts_csv_path = "https://raw.githubusercontent.com/martj42/international_results/refs/heads/master/shootouts.csv" 로그 세팅 logging.basicConfig(level=logging.INFO) logger = logging.getLogger(__name__) logger.info("Loading data...") 데이터 로드 results_df = pd.read_csv(results_csv_path, parse_dates=["date"]) goalscorers_df = pd.read_csv(goalscorers_csv_path, parse_dates=["date"]) shootouts_df = pd.read_csv(shootouts_csv_path, parse_dates=["date"])
이 コード ブロック은 또한 로그 기록자를 세팅합니다. 다음 몇 行의 코드는 dotenv을 사용하여 나의 Neo4j 인증 정보를 읽고 Driver 오브젝트를 생성합니다:
uri = os.getenv("NEO4J_URI") user = os.getenv("NEO4J_USERNAME") password = os.getenv("NEO4J_PASSWORD") try: driver = neo4j.GraphDatabase.driver(uri, auth=(user, password)) print("Connected to Neo4j instance successfully!") except Exception as e: print(f"Failed to connect to Neo4j: {e}") BATCH_SIZE = 5000
since 我们的数据库中有48k 以上 的匹配项, 我们定义了一个 BATCH_SIZE 參數以较小样本的方式导入数据。
그리고, Neo4j에서 쿼리 성능을 개선하기 위해 사용되는 Cypher 인덱스를 정의하는 함수
def create_indexes(session): indexes = [ "CREATE INDEX IF NOT EXISTS FOR (t:Team) ON (t.name)", "CREATE INDEX IF NOT EXISTS FOR (m:Match) ON (m.id)", "CREATE INDEX IF NOT EXISTS FOR (p:Player) ON (p.name)", "CREATE INDEX IF NOT EXISTS FOR (t:Tournament) ON (t.name)", "CREATE INDEX IF NOT EXISTS FOR (c:City) ON (c.name)", "CREATE INDEX IF NOT EXISTS FOR (c:Country) ON (c.name)", ] for index in indexes: session.run(index) print("Indexes created.")
를 정의하고자 함:
- Session 오브젝트를 받는다.
- 특정 속성에 따라 노드나 관계를 찾는 과정을 속도를 높여준다.
- 다음과 같은 목적을 serve하는 것이 좋다:
쿼리 실행 속도 향상 大数据셋에서 읽기 성능 改善 패턴 매칭 효율성 改善 - 고유 제약 조건 적용
- 데이터베이스가 성장할 때의 확장성 개선
우리의 경우에는 팀 이름, 경기 ID, 선수 이름에 대한 인덱스를 생성하면 특정 엔티티를 검색하거나 서로 다른 노드 유형 사이에서 조인을 수행할 때 쿼리의 실행 속도가 빨라집니다. 자신의 데이터베이스에 이러한 인덱스를 생성하는 것은 最佳實踐입니다.
다음으로 ingest_matches 함수에 대해 알아보겠습니다. 이 함수는 크기가 크므로 블록을 하나하나 분석해보겠습니다:
def ingest_matches(session, df): query = """ UNWIND $batch AS row MERGE (m:Match {id: row.id}) SET m.date = date(row.date), m.home_score = row.home_score, m.away_score = row.away_score, m.neutral = row.neutral MERGE (home:Team {name: row.home_team}) MERGE (away:Team {name: row.away_team}) MERGE (t:Tournament {name: row.tournament}) MERGE (c:City {name: row.city}) MERGE (country:Country {name: row.country}) MERGE (home)-[:PLAYED_HOME]->(m) MERGE (away)-[:PLAYED_AWAY]->(m) MERGE (m)-[:PART_OF]->(t) MERGE (m)-[:PLAYED_IN]->(c) MERGE (c)-[:LOCATED_IN]->(country) WITH m, home, away, row.home_score AS hs, row.away_score AS as FOREACH(_ IN CASE WHEN hs > as THEN [1] ELSE [] END | MERGE (home)-[:WON]->(m) MERGE (away)-[:LOST]->(m) ) FOREACH(_ IN CASE WHEN hs < as THEN [1] ELSE [] END | MERGE (away)-[:WON]->(m) MERGE (home)-[:LOST]->(m) ) FOREACH(_ IN CASE WHEN hs = as THEN [1] ELSE [] END | MERGE (home)-[:DREW]->(m) MERGE (away)-[:DREW]->(m) ) """ ...
처음에 노출되는 것은 UNWIND 키워드입니다. 이 키워드는 하나의 バッチ 데이터를 처리하기 위해 사용되며, $batch 매개 변수(우리의 DataFrame 行)를 接纳하여 각 行을 이룰 수 있는 것을 허용합니다. 이러한 방식은 특히 大数据셋에서 각 行을 개별적으로 처리하는 것보다 효율적입니다.
쿼리의 나머지 부분은 여러 MERGE 절을 사용하므로 익숙합니다. 그 다음, WITH 절로 갑니다. 이 절은 FOREACH 구조를 IN CASE 문을 사용합니다. 이것들은 매치 결과에 따라 조건부적으로 관계를 생성하는 데 사용됩니다. 홈 팀이 이기면, 홈 팀에 대해 ‘WON’ 관계와, 어웨이 팀에 대해 ‘LOST’ 관계를 생성하고, 반대의 경우에도 마찬가지입니다. 무승부의 경우, 양 팀은 경기와 ‘DREW’ 관계를 갖게 됩니다.
기능의 나머지는 들어오는 DataFrame를 일치하는 것과 분리하고, $batch 쿼리 매개변수로 전달될 데이터를 構築합니다.
def ingest_matches(session, df): query = """...""" for i in tqdm(range(0, len(df), BATCH_SIZE), desc="Ingesting matches"): batch = df.iloc[i : i + BATCH_SIZE] data = [] for _, row in batch.iterrows(): match_data = { "id": f"{row['date']}_{row['home_team']}_{row['away_team']}", "date": row["date"].strftime("%Y-%m-%d"), "home_score": int(row["home_score"]), "away_score": int(row["away_score"]), "neutral": bool(row["neutral"]), "home_team": row["home_team"], "away_team": row["away_team"], "tournament": row["tournament"], "city": row["city"], "country": row["country"], } data.append(match_data) session.run(query, batch=data)
ingest_goals 함수와 ingest_shootouts 함수는 비슷한 구조를 사용합니다. 然而, ingest_goals는 一些额外的错误或缺失值处理.
스크립트의 끝에는 main() 함수가 있습니다. 이 함수는 세션 오브젝트를 사용하여 모든 가져오기 함수를 실행합니다:
def main(): with driver.session() as session: create_indexes(session) ingest_matches(session, results_df) ingest_goals(session, goalscorers_df) ingest_shootouts(session, shootouts_df) print("Data ingestion completed!") driver.close() if __name__ == "__main__": main()
결론과 다음 단계
Python을 사용하여 Neo4j 그래프 데이터베이스로 작업하는 주요 면에 대해 이동했습니다:
- 그래프 데이터베이스 이념과 구조
- Neo4j AuraDB 세팅
- Cypher 쿼리 언어 기본
- Neo4j Python 드라이버 사용
- 데이터 인jestion과 쿼리 최적화
Neo4j 여행을 더욱 나아가기 위해以下의 자료를 찾아보세요:
- Neo4j 문서
- Neo4j 그래프 데이터 과학 라이브러리
- Neo4j Cypher 사용자 manual
- Neo4j Python Driver 文档
- 데이터 엔지니어링 직업 cerification
- NoSQL 개념 소개
- MongoDB를 사용한 모든 것을 가진 NoSQL 튜토리얼
그래프 데이터베이스의 강력함은 복잡한 관계를 표현하고 쿼리하는 것입니다. 다양한 데이터 모델을 실험하고 고급 Cypher 기능을 구查하続けます.