













データ科学家はSQLを早く学ぶことが一般的です。これは、テーブル情報の普遍性と高い有用性によるものです。しかし、連関的SQLデータベースには合わない連関的なデータを保存するために、他にも成功したデータベース形式があります。このチュートリアルでは、Pythonでグラフデータベースを作成、管理、クエリすることができる人気のグラフデータベース管理システム、Neo4jについて学びます。
グラフデータベースとは?
Neo4jについて話す前に、グラフデータベースについてよりよく理解するために一瞬を取りましょう。私たちにはグラフデータベースとはを説明する完全な記事がありますので、ここでは主要な点を簡単にまとめます。
グラフデータベースは、接続されたデータを管理するために設計されたノンSQLデータベース(SQLを使用しない)の一型です。従来の関連型データベースがテーブルと行を使用していることに対して、グラフデータベースは以下のようなグラフ構造を使用します。
- ノード(エンティティ) 例如、人々、場所、概念
- 関連性は、異なるノードを結びつける人物 LIVES IN 場所、またはフットボール選手 SCORED IN 試合.
- ノードやエッジの属性(プロパティ)というのは、人物の年齢や、ゴールがあった試合の時間などです。
この構造により、グラフデータベースは、ソーシャルネットワーク、推奨、フラッド検出などの領域やアプリケーションにおいて、连环的なデータを処理するのに理想的であり、選択の効率性において通常、关系型DBを上回る绩效を示します。以下は、フットボールデータセット用のサンプルグラフデータベースの構造です。
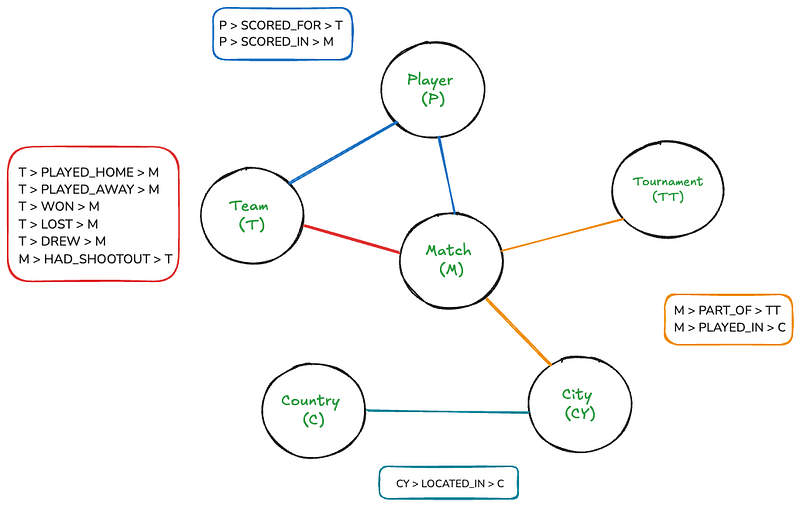
このグラフは人間にとっては直观的なものを表していますが、キャンバスに描かれると相当に複雑になります。しかし、Neo4jを使用することで、このグラフを探索することは、簡単なSQL結合を書くのと同じくらい簡単に
このグラフには6つのノードがあります:マッチ、チーム、トーナメント、プレイヤー、国、都市。矩形はノード間の存在する関係をリストに示しています。また、いくつかのノードと関係のプロパティもあります:
- 対応: 日付、主場得点、客場得点
- チーム: チーム名
- プレイヤー: プレイヤー名
- 試合: 試合名
- 都市: 名前
- 国: 名前
- 得点時刻、得点方法: 分、自滅、ペナルティ
- PK戦: 勝者、初シューティング
このスキーマは、以下を表現することができます。
- 試合する全てのチームとそのスコア、日付、場所
- 各試合に参加しているチーム(ホームとアウェイ)
- ゴールを得る選手について、分かち書きの時間、自分のゴール、ペナルティなどの詳細
- 試合が属するトーナメント
- 試合が行われる都市と国
- 試合の情報を包括しており、勝者や最初のシューター(提供可能な場合)を含む
このスキーマは、場所の階層性(市国の中)と实体間のさまざまな関係(たとえば、試合をプレイするチーム、試合でチームに得点を上げるプレイヤーなど)を捉えることができます。
この構造は、2チーム間のすべての試合、プレイヤーによるすべてのゴール、または特定のトーナメントや場所でのすべての試合を探すような柔軟なクエリングを可能にします。
しかし、自分たちの頭を邪魔しないでください。まず、Neo4jとは何であり、なぜそれを使用するのか?
Neo4jとは?
グラフDB管理の世界の先駆者であるNeo4jは、強力な機能と多様性によって知られています。
Neo4jはその核にてネイティブなグラフストORAGEを使用しており、グラフ操作を行うために高度に最適化されています。これにより、複雑な関係を処理する効率が高く、接続されたデータに対する従来のデータベースを凌駕しています。Neo4jのスケーラビリティは実に印象的で、数十億のノードと関係を簡単に処理できるため、小さいプロジェクトから大企業までに応用できます。
Neo4jのもう一つの重要な特徴はデータの整性です。完全なACID(原子性、一致性、 isolation、耐久性)準拠を保証しており、トランザクションの信頼性と一致性を提供します。
トランザクションについて語ると、そのクエリ言語、Cypherは非常に直观的で宣言的な構文を提供しており、グラフパターンに設計されています。このため、その構文は「ASCIIアート」というニックネームを付けられています。CypherはSQLに熟悉であれば学習には問題ありません。
Cypherを使用すると、既存のクエリーやスキーマを破壊する心配なしに新しいノード、関係、またはプロパティを追加することが簡単です。これは現代の開発環境に迅速に変化する要望に適応することができます。
Neo4jは豊かなエコシステムサポートを持っています。幅広い文書化、グラフを可視化する包括的なツール、活発なコミュニティ、Python、Java、JavaScriptなど他のプログラミング言語との統合があります。
Neo4jとPython環境のセットアップ
Neo4jで作業を始める前に、環境をセットアップする必要があります。このセクションでは、Neo4jデータベースをホストするクラウドインスタンスを作成し、Python環境を設定し、両者間の接続を確立する方法を説明します。
Neo4jをインストールしないでください
Neo4jのローカルグラフデータベースと共に作業したい場合、 Javaと同様にダウンロードしてインストールする必要があります。しかし、ほとんどの場合、いくつかのクラウド環境上の既存のネイティブNeo4jデータベースとやりとりすることになります。
この理由で、私たちはNeo4jを私たちのシステムにインストールしないでください。代わりに、Neo4jの完全に管理されたクラウドサービスである Aura上で無料のデータベースインスタンスを作成します。その後、neo4j Pythonクライアントライブラリを使用して、このデータベースに接続し、データを投入します。
Neo4j Aura DBインスタンスの作成
Aura DBに無料のグラフデータベースをホストするために、 製品ページにアクセスし、「無料で始める」をクリックしてください。
登録を完了すると、利用可能なプランが表示され、無料のオプションを選択する必要があります。その後、新しいインスタンスに対してユーザー名とパスワードが割り当てられ、それに接続することができます:
パスワード、ユーザー名、および接続URIをコピーしてください。
次に、新しいワークディレクトリと.envファイルを作成し、認証情報を保存します。
$ mkdir neo4j_tutorial; cd neo4j_tutorial $ touch .env
以下の内容をファイルに貼り付けます。
NEO4J_USERNAME="YOUR-NEO4J-USERNAME" NEO4J_PASSWORD="YOUR-COPIED-NEO4J-PASSWORD" NEO4J_CONNECTION_URI="YOUR-COPIED-NEO4J-URI"
Python環境の設定
次に、新しいConda環境にneo4j Pythonクライアントライブラリをインストールします。
$ conda create -n neo4j_tutorial python=3.9 -y $ conda activate neo4j_tutorial $ pip install ipykernel # Jupyterに環境を追加するには $ ipython kernel install --user --name=neo4j_tutorial $ pip install neo4j python-dotenv tqdm pandas
コマンドはまた ipykernel ライブラリをインストールし、それを使用して新しく作成されたConda環境をJupyterのカーネルとして追加します。その後、Neo4jデータベースと対話するための neo4j PythonクライアントとNeo4jの認証情報を安全に管理するための python-dotenv をインストールします。
AuraDBインスタンスにフットボールデータを投入します。
グラフデータベースにデータを取り込むことは、Cypherの基本を理解する必要がある複雑なプロセスです。まだCypherの基本を学んでいないため、私が記事用意したPythonスクリプトを使用して、自動的に実際の世界の歴史的なフットボールデータを取り込むことします。スクリプトは、あなたが保管している認証情報を使用して、あなたのAuraDBインスタンスに接続します。
フットボールのデータは Kaggleの国際サッカー試合のデータセットから来ています。このデータはCSV形式で提供されているため、スクリプトはそれを分解し、CypherとNeo4jを使用してグラフ形式に変換します。記事の最後になると、これらの技術に十分に惯れたとき、スクリプトを1行ずつ見て、タブル情報をグラフに変換する方法を理解することができます。
以下は、AuraDBのインスタンスを設定し、資格情報を作業ディレクトリ内の.envファイルに保存した後に実行するコマンドです。
$ wget https://raw.githubusercontent.com/BexTuychiev/medium_stories/refs/heads/master/2024/9_september/3_neo4j_python/ingest_football_data.py $ python ingest_football_data.py
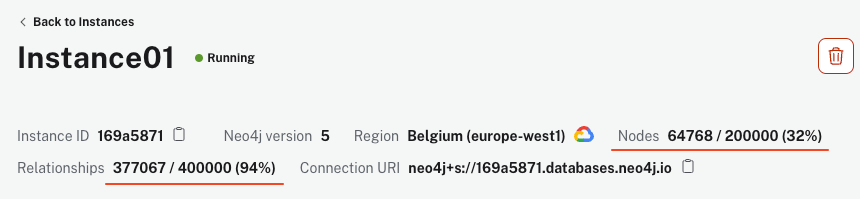
スクリプトの実行には、マシンとインターネット接続の状況によって数分かかる可能性があります。しかし、実行が完了すると、AuraDBのインスタンスは64kノード以上および340k関連性以上を示す必要があります。
PythonからNeo4jに接続する方法
今、私たちはAura DBインスタンスに接続する準備ができています。まず、私たちは.envファイルからdotenvを使用して資格情報を読み取ります:
import os from dotenv import load_dotenv load_dotenv() NEO4J_USERNAME = os.getenv("NEO4J_USERNAME") NEO4J_PASSWORD = os.getenv("NEO4J_PASSWORD") NEO4J_URI = os.getenv("NEO4J_URI")
今は接続を確立しましょう:
from neo4j import GraphDatabase uri = NEO4J_URI username = NEO4J_USERNAME password = NEO4J_PASSWORD driver = GraphDatabase.driver(uri, auth=(username, password)) try: driver.verify_connectivity() print("Connection successful!") except Exception as e: print(f"Failed to connect to Neo4j: {e}")
出力:
Connection successful!
このコードの説明は以下の通りです:
- 私たちは
GraphDatabaseをneo4jから導入して、Neo4jとやりとりする。 - 以前に読み込まれた環境変数を使用して、接続を設定します(
uri,username,password). - 私たちは
GraphDatabase.driver()を使用してドライバーオブジェクトを作成し、ネオ4jデータベースに接続します。 - With
をブロックの接続が有効なverify_connectivity()関数を使用して確認します。デフォルトでは、 verify_connectivity()接続が成功した場合は何も返りません。
チュートリアルが完了する後、driver.close()を呼び出して、接続を終了しリソースを解放してください。ドライバーオブジェクトは生成するのには昂贵であるため、アプリケーションには単一のオブジェクトしか生成しないことが推奨されます。
Cypher クエリ言語の基本
Cypherの構文は、インテリジェントで、グラフ構造を視覚的に表現することが目的である。以下のASCIIアート型の構文に依存しています。
(nodes)-[:CONNECT_TO]->(other_nodes)
以下は一般的なクエリパターンの主要なコンポーネントを分解します。
1. ノード
Cypherクエリでは、parantheses()に入るキーワードはノード名を示します。たとえば、(Player)はすべてのPlayerノードをマッチングします。几乎、ノード名は别名を使用して参照されます。これによりクエリがより可読性があり、書きやすく、compact(简洁的)になります。ノード名に別名を追加するには、その前にコロンを付けます:(m:Match)。
parantheses()の中で、dictionary(辞書)のような構文を使用して、正確なマッチングにたくさんのノード属性を指定することができます。たとえば:
// FIFA World Cupのすべてのトーナメントノード (t:Tournament {name: "FIFA World Cup"})
ノードの属性はそのまま書かれますが、それらに必要な値は文字列でなければなりません。
2. 関係
ノードを互いに結びつける関係は、角括弧と矢印で囲まれます。
// 某一のトーナメントに参加しているノードと一致 (m:Match)-[PART_OF]->(t:Tournament)
関係に别名と属性を追加することもできます。
// ブラジルが点球決勝で最初の射手となった試合に一致 (p:Player) - [r:SCORED_FOR {minute: 90}] -> (t:Team)
関係は矢印で囲まれています-[関係]->. もう一度、引数の中に别名属性を含めることができます。たとえば:
// 自身ゴールを得たすべてのプレイヤー (p:Player)-[r:SCORED_IN {own_goal: True}]->(m:Match)
3. 節
同様にCOUNT(*) FROM table_nameというSQLはSELECT句を含まない場合、何も返却しません。(node) - [RELATIONSHIP] -> (node)も同様に結果を取得することはできません。そのため、SQLのように、Cypherも異なる句を用いてクエリロジックを構築することができます。
MATCH: 图のパターンマッチングWHERE: 結果の絞り込みRETURN: 結果セットに含める内容の指定CREATE: 新しいノードまたは関係を作成MERGE: ユニークなノードやリレーションシップを作成するDELETE: ノード、リレーションシップまたはプロパティを削除するSET: ラベルとプロパティを更新する
これらの概念を示すサンプルクエリを以下に示します。
MATCH (p:Player)-[s:SCORED_IN]->(m:Match)-[PART_OF]->(t:Tournament) WHERE t.name = "FIFA World Cup" AND s.minute > 80 AND s.own_goal = True RETURN p.name AS Player, m.date AS MatchDate, s.minute AS GoalMinute ORDER BY s.minute DESC LIMIT 5
このクエリは、80分後にワールドカップの試合で自分たちのゴールを得たプレイヤーすべてを見つけます。それはSQLに似ていますが、そのSQLの等価物は少なくとも1つのJOINを含んでいます。
Neo4j Python Driverを使用してグラフデータベースを分析する
execute_query
Neo4j Pythonドライバーは、Pythonアプリケーションを通じてNeo4jインスタンスとやりとりする公式なライブラリです。これは、Plain Python stringsで書かれたCypherクエリをNeo4jサーバーに確認し、统一された形式で結果を取り出すことができます。
は、GraphDatabaseクラスを使用してドライバーオブジェクトを作成します。そこから、execute_queryメソッドを使用してクエリを送信することができます。
まず、面白い質問に答えましょう: 世界カップで最も多くの試合を勝ったチームはどこですか?
# 世界カップで最も多くの試合を勝ったチームを返却する query = """ MATCH (t:Team)-[:WON]->(m:Match)-[:PART_OF]->(:Tournament {name: "FIFA World Cup"}) RETURN t.name AS Team, COUNT(m) AS MatchesWon ORDER BY MatchesWon DESC LIMIT 1 """ records, summary, keys = driver.execute_query(query, database_="neo4j")
まず、クエリを分割しましょう:
- 以下は
MATCHの終了部分で、我々が指定したいパターンを定義しています:チーム -> 勝利 ->試合 -> トーナメントの一部 -> RETURNは、SELECTステートメントと同じ機能を持っており、返却されるノードと関係の属性を返すことができます。この節では、Cypherで サポートされている集積関数をCOUNT.を使用することもできます。上記はCOUNTを使用しています。ORDER BY句とSQLのORDER BY句の機能は同様です。LIMITは、返却されるレコードの長さを制御するために使用されます。
クエリを多行文字列として定義した後、それをドライバーオブジェクトのexecute_query()メソッドに渡し、データベース名(デフォルトはneo4j)を指定する。出力には常に3つのオブジェクトが含まれます。
records: 結果セットの各行を表すRecrodオブジェクトのリスト。各Recrodは名前付きタプルのようなオブジェクトで、名前やインデックスを使ってフィールドにアクセスすることができます。概要: クエリ実行に関するメタデータを含むResultSummaryオブジェクト,如火災統計と時間情報です。キー: 結果集合の列名を表す文字列のリストです。
後でsummary オブジェクトに触れますが、我々は主にrecordsについて関心があります。これらはRecord オブジェクトを含んでいます。これらの情報を取得するためには、彼らのdata() メソッドを呼び出すことができます。
for record in records: print(record.data())
出力:
{'Team': 'Brazil', 'MatchesWon': 76}
結果は正しく、ブラジルが世界カップの試合を最多勝ち取ったと示しています。
クエリパラメーターの渡し
私たちの最後のクエリは再利用可能ではありません。なぜなら、世界カップ歴史上最も成功したチームだけを見つけるだけですから。欧元歴史で最も成功したチームを見つけたいとしたらどうすればよいでしょうか?
ここでクエリパラメーターが役立ちます。
query = """ MATCH (t:Team)-[:WON]->(m:Match)-[:PART_OF]->(:Tournament {name: $tournament}) RETURN t.name AS Team, COUNT(m) AS MatchesWon ORDER BY MatchesWon DESC LIMIT $limit """
このバージョンのクエリで、$記号を使用して2つのパラメータを導入しています。
tournamentlimit
パラメータに値を渡すために、execute_queryの中でキーワード引数を使用します。
records, summary, keys = driver.execute_query( query, database_="neo4j", tournament="UEFA Euro", limit=3, ) for record in records: print(record.data())
出力:
{'Team': 'Germany', 'MatchesWon': 30} {'Team': 'Spain', 'MatchesWon': 28} {'Team': 'Netherlands', 'MatchesWon': 23}
常に、查询に変更する値を吸収する際に、查询パラメータを使用することを推奨します。この最佳实践中で、您的查询をCypher注入から守り、Neo4jによってキャッシュすることができます。
CREATEとMERGE節を使用してデータベースに書き込む
既存のデータベースに新しい情報を書き込むことは、execute_queryを使用して行われますが、CREATE節をクエリ中で使用しています。たとえば、新しいノードタイプ – チームコーチを追加する関数を作成しましょう。
def add_new_coach(driver, coach_name, team_name, start_date, end_date): query = """ MATCH (t:Team {name: $team_name}) CREATE (c:Coach {name: $coach_name}) CREATE (c)-[r:COACHES]->(t) SET r.start_date = $start_date SET r.end_date = $end_date """ result = driver.execute_query( query, database_="neo4j", coach_name=coach_name, team_name=team_name, start_date=start_date, end_date=end_date ) summary = result.summary print(f"Added new coach: {coach_name} for existing team {team_name} starting from {start_date}") print(f"Nodes created: {summary.counters.nodes_created}") print(f"Relationships created: {summary.counters.relationships_created}")
関数add_new_coachは5つの引数を取ります。
- ドライバー: Neo4jのデータベースに接続するために使用されるドライバーオブジェクト。
coach_name: 新しく追加するコーチの名前。team_name: このコーチが関連付けられるチームの名前。start_date: コーチがチームを指導を始めた日付。end_date: コーチのチームとの合同を終了した日付。
この機能内のCypherクエリは以下のようなことを行います。
- 与えられたチーム名で既存のチームノードと一致する。
- 与えられたコーチ名で新しいコーチノードを作成します。
- コーチとチームノード間に「COACHES」関連を作成します。
- 「
start_date」と「end_date」のプロパティをCOACHES関連に設定します。
クエリはexecute_queryメソッドを使用して実行されます。これはクエリ文字列とパラメーターの辞書を引数とします。
実行後、関数は以下の内容を出力します。
- コーチとチーム名、開始日という確認メッセージ。
- 作成されたノードの数(新しいコーチノードには1つが必要です)。
- 作成された関連性の数(新しい
COACHES関連性には1つが必要です)。
国際サッカー史上最も成功したコーチの1人、リオネル・スカロニにもそれを試すべきです。彼は3つの連続した主要な国際試合(ワールドカップと2つのコパアメリカズ)を勝ち取りました。
from neo4j.time import DateTime add_new_coach( driver=driver, coach_name="Lionel Scaloni", team_name="Argentina", start_date=DateTime(2018, 6, 1), end_date=None )
Output: Added new coach: Lionel Scaloni for existing team Argentina starting from 2018-06-01T00:00:00.000000000 Nodes created: 1 Relationships created: 1
上のスニペットでは、DateTimeクラスをneo4j.timeモジュールから 呼び出して、正しい日付をCypherクエリに渡すためです。
「CREATE」以外には、新しいノードとリレーションシップを作成するためのMERGE句式もあります。彼らの主要な違いは以下の通りです。
CREATEは常に新しいノードやリレーションシップを作成し、重複する可能性があります。MERGEは、既に存在しない場合にのみノード/リレーションシップを作成します。
たとえば、後で見ることができるデータの取り込みスクリプトでは:
- 私たちは
MERGEをチームとプレイヤーに使用して重複を避けました。 - 私たちは
CREATEをSCORED_FORおよびSCORED_IN関係の中で使用しています。これは、プレイヤーが1つの試合で複数回得点することができるからです。 - これらは真の重複ではなく、異なる属性(例:ゴール分刻み)を持っています。
この手法は、データの整合性を保ちながら、似ているが異なる関連性を複数つまり可能にする。
自分でトランザクションを実行する
execute_queryを実行すると、ドライバーは背後でトランザクションを作成します。トランザクションは、完全に実行されるか失敗して取り消される必要がある作业の単位です。これは、单 transactionで何千ものノードや関連性を作成しているとき(可能です)に、中途でエラーが発生したとき、すべてのトランザクションが失敗し、グラフに新しいデータを書き込むことはないという意味です。
各トランザクションにより詳細なコントロールを持つために、セッションオブジェクトを作成する必要があります。たとえば、セッションオブジェクトを使用して、あるトーナメントの最も得点の高いK人を探す関数を作成しましょう。
def top_goal_scorers(tx, tournament, limit): query = """ MATCH (p:Player)-[s:SCORED_IN]->(m:Match)-[PART_OF]->(t:Tournament) WHERE t.name = $tournament RETURN p.name AS Player, COUNT(s) AS Goals ORDER BY Goals DESC LIMIT $limit """ result = tx.run(query, tournament=tournament, limit=limit) return [record.data() for record in result]
まず、top_goal_scorers関数を作成します。この関数には3つの引数を受け取り、最も重要なのはtxトランザクションオブジェクトです。これはセッションオブジェクトを使用して取得されます。
with driver.session() as session: result = session.execute_read(top_goal_scorers, "FIFA World Cup", 5) for record in result: print(record)
出力:
{'Player': 'Miroslav Klose', 'Goals': 16} {'Player': 'Ronaldo', 'Goals': 15} {'Player': 'Gerd Müller', 'Goals': 14} {'Player': 'Just Fontaine', 'Goals': 13} {'Player': 'Lionel Messi', 'Goals': 13}
次に、session()メソッドで作成された上下文管理器の下で、execute_read()を使用し、top_goal_scorers()関数を渡し、クエリに必要な任何のパラメーターを提供する。
以下のexecute_readの出力は、Miroslav Klose、Ronaldo Nazario、Lionel Messiなどの名前を含む、ワールドカップ史上のトップ5のゴール得点者を正しく示すRecordオブジェクトのリストです。
データ取り込みのためのexecute_read()の対応する機能はexecute_write()です。
ということで、Neo4j Pythonドライバーを使用したデータ取り込みがどのように動作するのかを理解するために、先程使用した取り込みスクリプトを見ていきましょう。
Neo4j Python Driverを使用したデータ取り込み
以下の ingest_football_data.py ファイル は、import文と必要なCSVファイルの読み込みから始まります:
import pandas as pd import neo4j from dotenv import load_dotenv import os from tqdm import tqdm import logging CSVファイルのパス results_csv_path = "https://raw.githubusercontent.com/martj42/international_results/refs/heads/master/results.csv" goalscorers_csv_path = "https://raw.githubusercontent.com/martj42/international_results/refs/heads/master/goalscorers.csv" shootouts_csv_path = "https://raw.githubusercontent.com/martj42/international_results/refs/heads/master/shootouts.csv" ログ設定 logging.basicConfig(level=logging.INFO) logger = logging.getLogger(__name__) logger.info("Loading data...") データの読み込み results_df = pd.read_csv(results_csv_path, parse_dates=["date"]) goalscorers_df = pd.read_csv(goalscorers_csv_path, parse_dates=["date"]) shootouts_df = pd.read_csv(shootouts_csv_path, parse_dates=["date"])
このコードブロックは、ロガーの設定も行います。次の数行のコードは、dotenvを使用してNeo4jの認証情報を読み込み、Driverオブジェクトを作成します:
uri = os.getenv("NEO4J_URI") user = os.getenv("NEO4J_USERNAME") password = os.getenv("NEO4J_PASSWORD") try: driver = neo4j.GraphDatabase.driver(uri, auth=(user, password)) print("Connected to Neo4j instance successfully!") except Exception as e: print(f"Failed to connect to Neo4j: {e}") BATCH_SIZE = 5000
データベース内に48k以上の一致があるため、より小さなサンプルにデータを取り込むためのBATCH_SIZEパラメータを定義します。
次に、私たちはcreate_indexesと名付けた関数を定義します。
def create_indexes(session): indexes = [ "CREATE INDEX IF NOT EXISTS FOR (t:Team) ON (t.name)", "CREATE INDEX IF NOT EXISTS FOR (m:Match) ON (m.id)", "CREATE INDEX IF NOT EXISTS FOR (p:Player) ON (p.name)", "CREATE INDEX IF NOT EXISTS FOR (t:Tournament) ON (t.name)", "CREATE INDEX IF NOT EXISTS FOR (c:City) ON (c.name)", "CREATE INDEX IF NOT EXISTS FOR (c:Country) ON (c.name)", ] for index in indexes: session.run(index) print("Indexes created.")
Cypherインデックスは、Neo4jのクエリパフォーマンスを向上させるデータベース構造です。特定のプロパティに基づいてノードやリレーションシップを見つける過程を速めます。私たちは以下の目的で使用する必要があります。
- より速いクエリ実行
- 大きなデータセットでの読み取り性能の向上
- 効率的なパターンマッチング
- 唯一の制約を適用する
- データベースが成長するに伴ってより良いスケール性
私たちの場合、チーム名、マッチID、およびプレイヤー名に索引を作成することが、特定の实体を查找したり、異なるノードタイプ間でJOIN操作を行ったりする際に、クエリの実行速度を高速化するのに役立つ。自分のデータベースに索引を作成するのにこれらの索引を作成するのは最佳実践です。
次に、私たちにはingest_matches関数があります。これは大きいので、ブロックごとに分割してみましょう。
def ingest_matches(session, df): query = """ UNWIND $batch AS row MERGE (m:Match {id: row.id}) SET m.date = date(row.date), m.home_score = row.home_score, m.away_score = row.away_score, m.neutral = row.neutral MERGE (home:Team {name: row.home_team}) MERGE (away:Team {name: row.away_team}) MERGE (t:Tournament {name: row.tournament}) MERGE (c:City {name: row.city}) MERGE (country:Country {name: row.country}) MERGE (home)-[:PLAYED_HOME]->(m) MERGE (away)-[:PLAYED_AWAY]->(m) MERGE (m)-[:PART_OF]->(t) MERGE (m)-[:PLAYED_IN]->(c) MERGE (c)-[:LOCATED_IN]->(country) WITH m, home, away, row.home_score AS hs, row.away_score AS as FOREACH(_ IN CASE WHEN hs > as THEN [1] ELSE [] END | MERGE (home)-[:WON]->(m) MERGE (away)-[:LOST]->(m) ) FOREACH(_ IN CASE WHEN hs < as THEN [1] ELSE [] END | MERGE (away)-[:WON]->(m) MERGE (home)-[:LOST]->(m) ) FOREACH(_ IN CASE WHEN hs = as THEN [1] ELSE [] END | MERGE (home)-[:DREW]->(m) MERGE (away)-[:DREW]->(m) ) """ ...
最初に気付くのはUNWINDキーワードで、一つのデータベースのバッチを処理するために使用されます。これは$batchパラメーター(これは私たちのDataFrameの行となる)を取り、各行を順番に処理して、単一のトランザクションで複数のノードやリレーションシップを作成または更新することができます。この手法は、大きなデータセットにおいて、各行を個別に処理するよりも効果的です。
残りのクエリは熟悉なように、複数のMERGE節点を使用しています。次に、私たちはWITH節点に達し、FOREACH構文とIN CASE声明を使用しています。これらは、マッチングの結果に基づいて条件付きの関連性を作成するために使用されます。ホームチームが勝つ場合、ホームチームには「WON」関連性、アウェイチームには「LOST」関連性を作成し、その逆も成り立てます。引き分けの場合、両チームはマッチに「DREW」関連性を得ます。
残りの機能は、入力のDataFrameをマッチングに分割し、$batchクエリパラメーターに渡されるデータを構築します。
def ingest_matches(session, df): query = """...""" for i in tqdm(range(0, len(df), BATCH_SIZE), desc="Ingesting matches"): batch = df.iloc[i : i + BATCH_SIZE] data = [] for _, row in batch.iterrows(): match_data = { "id": f"{row['date']}_{row['home_team']}_{row['away_team']}", "date": row["date"].strftime("%Y-%m-%d"), "home_score": int(row["home_score"]), "away_score": int(row["away_score"]), "neutral": bool(row["neutral"]), "home_team": row["home_team"], "away_team": row["away_team"], "tournament": row["tournament"], "city": row["city"], "country": row["country"], } data.append(match_data) session.run(query, batch=data)
ingest_goalsとingest_shootouts関数は似た構文を使用しています。しかし、ingest_goalsには追加のエラーと欠けている値の処理があります。
スクリプトの最後に、私たちはmain()関数を持っています。この関数は、セッションオブジェクトを使って、すべての取り込み関数を実行します。
def main(): with driver.session() as session: create_indexes(session) ingest_matches(session, results_df) ingest_goals(session, goalscorers_df) ingest_shootouts(session, shootouts_df) print("Data ingestion completed!") driver.close() if __name__ == "__main__": main()
結論と次の手順
私たちは、Pythonを使用してNeo4j图型データベースと共に作業するための重要な要素を説明しました。
- 图型データベースの概念と構造
- Neo4j AuraDBの設定
- Cypherクエリ言語の基礎
- Neo4j Python ドライバーを使用して
- データの取り込みとクエリの最適化
Neo4j の学習を進めるために、以下のリソースを参照してください:
- Neo4j 文档
- Neo4j グラフデータ科学ライブラリ
- Neo4j Cypherマニュアル
- Neo4j Pythonドライバードキュメント
- データエンジニアリングキャリア cerification
- NoSQLの入門
- MongoDBを使用した Comprehensive NoSQL 教程
图形データベースの強みは、複雑な関係を表現し、クエリすることである。異なるデータモデルを試し、高度なCypher機能を探求し続けます。