













Datenwissenschaftler beginnen früh mit der Erforschung von SQL. Verständlich, angesichts der Allgegenwart und der hohen Nutzlichkeit von tabellarischen Informationen. Es gibt jedoch andere erfolgreiche Datenbankformate, wie beispielsweise Graphendatenbanken, um verknüpfte Daten zu speichern, die nicht in eine relationale SQL-Datenbank passen. In diesem Tutorial werden wir Neo4j kennenlernen, ein beliebtes System zur Verwaltung von Graphendatenbanken, das Sie verwenden können, um Graphendatenbanken in Python zu erstellen, zu verwalten und abzufragen.
Was sind Graphendatenbanken?
Bevor wir über Neo4j sprechen, sollten wir uns etwas genauer mit Graphendatenbanken beschäftigen. Wir haben einen ausführlichen Artikel, der erklärt, was Graphendatenbanken sind, daher werden wir hier die wesentlichen Punkte zusammenfassen.
Graphdatenbanken sind eine Art NoSQL-Datenbank (sie verwenden kein SQL), die für die Verwaltung verknüpfter Daten konzipiert sind. Im Gegensatz zu traditionellen relationalen Datenbanken, die Tabellen und Zeilen verwenden, verwenden Graphdatenbanken Graphstrukturen, die aus folgenden bestehen:
- Knoten (Entitäten) wie Personen, Orten, Konzepte
- Ecken (Beziehungen), die verschiedene Knoten verbinden, wie PersonLEBT IN einem Ort, oder ein FußballspielerERZIELT IN einem Spiel.
- Eigenschaften (Attribute für Knoten/ Kanten) wie das Alter einer Person oder in welchem Spielzug das Tor erzielt wurde.
Diese Struktur macht Graphdatenbanken ideal für die Verarbeitung interagierten Daten in Bereichen und Anwendungen wie sozialen Netzwerken, Empfehlungen, Betrugserkennung etc., und erzielt oft bessere Leistungen als relationale Datenbanken im Hinblick auf die Abfrageeffizienz. Hier ist die Struktur eines Beispielgraphdatenbanken für ein Fußballdatensatz:
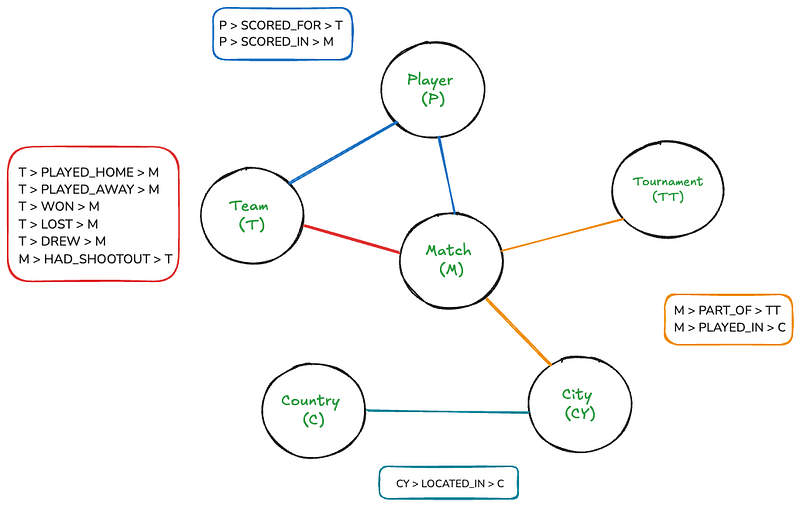
Obwohl dieser Graph für Menschen recht intuitiv ist, kann er auf einer Leinwand ziemlich kompliziert werden. Mit Neo4j jedoch wird das Durchlaufen dieses Graphen so einfach sein, wie einfache SQL-Joins zu schreiben.
Der Graph hat sechs Knotenpunkte: Match, Team, Tournament, Player, Country und City. Die Rechtecke listen die bestehenden Beziehungen zwischen den Knotenpunkten auf. Es gibt auch einige Knoten- und Beziehungsattribute:
- Match: Datum, Heimmannschaft, Gastmannschaft
- Team: Name
- Spieler: Name
- Turnier: Name
- Stadt: Name
- Land: Name
- ERSTES TOR, TOR IN DER: Minute, Eigentor, Elfmeter
- HAT EIN PENALTY-SCHIESSEN: Sieger, Erster Schütze
Dieses Schema ermöglicht es uns, Folgendes darzustellen:
- Alle Spiele mit ihren Ergebnissen, Daten und Orten
- Die Teams, die an jedem Spiel teilnehmen (Heim und Auswärts)
- Die Spieler, die Tore erzielen, einschließlich Details wie die Minute, Eigentore und Elfmeter
- Turniere, denen die Spiele zugehören
- Städte und Länder, in denen die Spiele stattfinden
- Schussabgabe-Informationen, einschließlich Sieger und erster Schützen (wenn verfügbar)
Das Schema greift die hierarchische Struktur von Orten (Stadt innerhalb von Land) und die verschiedenen Beziehungen zwischen Entitäten auf (z.B., Teams, die Spiele bestreiten, Spieler, die für Teams in Spielen punkten).
Diese Struktur ermöglicht flexible Abfragen, wie z.B. das Finden aller Spiele zwischen zwei Teams, aller Tore, die ein Spieler erzielt hat, oder aller Spiele in einer bestimmten Turnier oder Ort.
Lassen Sie uns jedoch nicht zu schnell von uns selbst überrumpelt werden. Zunächst einmal, was ist Neo4j und warum sollte man es verwenden?
Was ist Neo4j?
Neo4j ist der führende Name auf dem Gebiet der grafischen Datenbanken und bekannt für seine leistungsstarken und variantenreichen Features.
An derückseite von Neo4j verwendet es eine native Graph-Speicherung, die sehr optimiert ist, um Grafoperationen durchzuführen. Seine Effizienz in der Behandlung von komplexen Relationen macht es besser als traditionelle Datenbanken für verknüpfte Daten. Die Skalierbarkeit von Neo4j ist wirklich beeindruckend: Es kann Milliarden von Knoten und Beziehungen mit Leichtigkeit verwalten, was es für sowohl kleine Projekte als auch große Unternehmen geeignet macht.
Ein weiterer wichtiger Aspekt von Neo4j ist die Datenintegrität. Es gewährleistet vollständige ACID-Konformität (Atomität, Konsistenz, Isolierung, Dauerhaftigkeit), was zuverlässige und konsistente Transaktionen bietet.
Bei der Rede von Transaktionen ist es die Sprache Cypher, die eine sehr intuitiv und deklarative Syntax bietet und für Grafikmodelle entwickelt wurde. Daher hat ihre Syntax den Spitznamen „ASCII-Kunst“. Cypher lernen wird für Sie kein Problem sein, insbesondere, wenn Sie mit SQL vertraut sind.
Mit Cypher ist es einfach, neue Knoten, Beziehungen oder Eigenschaften hinzuzufügen, ohne sich Sorgen machen zu müssen, bestehende Abfragen oder Schemata zu brechen. Es ist anpassungsfähig an die schnell ändernden Anforderungen moderner Entwicklungsumgebungen.
Neo4j hat eine lebendige Ecosystem-Unterstützung. Es verfügt über umfangreiche Dokumentation, umfassende Tools zum Visualisieren von Graphen, eine aktive Gemeinschaft und Integrationen mit anderen Programmiersprachen wie Python, Java und JavaScript.
Einrichten von Neo4j und einer Python-Umgebung
Bevor wir uns in die Arbeit mit Neo4j stürzen, müssen wir unsere Umgebung einrichten. In diesem Abschnitt bekommen Sie Anweisungen, wie Sie eine Cloud-Instanz erstellen, um Neo4j-Datenbanken zu hosten, eine Python-Umgebung einzurichten und eine Verbindung zwischen beiden herstellen.
Neo4j nicht installieren
Wenn Sie mit lokalen Graphendatenbanken in Neo4j arbeiten möchten, müssten Sie es lokal herunterladen und installieren, zusammen mit seinen Abhängigkeiten wie Java. In den meisten Fällen werden Sie jedoch mit einer bestehenden, entfernten Neo4j-Datenbank in einer Cloudumgebung interagieren.
Aus diesem Grund werden wir Neo4j nicht auf unserem System installieren. Stattdessen werden wir eine kostenlose Datenbankinstanz auf Aura, dem vollständig verwalteten Cloud-Service von Neo4j, erstellen. Dann verwenden wir die neo4j Python-Client-Bibliothek, um uns mit dieser Datenbank zu verbinden und sie mit Daten zu füllen.
Erstellen einer Neo4j Aura DB-Instanz
Um eine kostenlose Grafendatenbank auf Aura DB zu hosten, besuchen seine Produktseite und klicken Sie auf „Gratis starten“.
Sobald Sie sich registriert haben, werden Ihnen die verfügbaren Pläne präsentiert, und Sie sollten die kostenlose Option wählen. Daraufhin erhalten Sie eine neue Instanz mit einem Benutzernamen und einem Passwort, um sich mit ihr zu verbinden:
Kopieren Sie Ihr Passwort, Ihren Benutzernamen und die Verbindungs-URI.
Dann erstellen Sie ein neues Arbeitsverzeichnis und eine .env Datei, um Ihre Zugangsdaten zu speichern:
$ mkdir neo4j_tutorial; cd neo4j_tutorial $ touch .env
Fügen Sie folgenden Inhalt in die Datei ein:
NEO4J_USERNAME="YOUR-NEO4J-USERNAME" NEO4J_PASSWORD="YOUR-COPIED-NEO4J-PASSWORD" NEO4J_CONNECTION_URI="YOUR-COPIED-NEO4J-URI"
Einrichten des Python-Umgebung
Nun installieren wir den neo4j Python-Client-Library in einem neuen Conda-Umgebung:
$ conda create -n neo4j_tutorial python=3.9 -y $ conda activate neo4j_tutorial $ pip install ipykernel # Zum Hinzufügen der Umgebung zu Jupyter $ ipython kernel install --user --name=neo4j_tutorial $ pip install neo4j python-dotenv tqdm pandas
Die Befehle installieren auch ipykernel Bibliothek und verwenden sie, um das neu erstellte Conda-Umgebung zu Jupyter als Kernel hinzuzufügen. Danach installieren wir den neo4j Python-Client, um mit Neo4j-Datenbanken zu interagieren, und python-dotenv, um unsere Neo4j-Zugangsdaten sicher zu verwalten.
Ein AuraDB-Instanz mit Fußballdaten füllen.
Das Einlesen von Daten in eine Graphendatenbank ist ein komplizierter Prozess, der Kenntnisse der Cypher-Grundlagen erfordert. Da wir noch nichts über die Cypher-Grundlagen gelernt haben, werden Sie ein Python-Skript verwenden, das ich für den Artikel vorbereitet habe, das automatisch historische Fußballdaten aus der Realität einliest. Das Skript verwendet die Anmeldedaten, die Sie gespeichert haben, um sich mit Ihrer AuraDB-Instanz zu verbinden.
Die Fußballdaten stammen aus diesem Kaggle-Datensatz über internationale Fußballspiele, die zwischen 1872 und 2024 stattfanden. Die Daten sind im CSV-Format verfügbar, daher zerlegt das Skript sie und wandelt sie mithilfe von Cypher und Neo4j in ein Grafikformat um. Am Ende des Artikels, wenn wir uns mit diesen Technologien ausreichend vertraut gemacht haben, werden wir das Skript zeilenweise durchgehen, sodass Sie verstehen, wie Sie tabellierte Informationen in ein Graph umwandeln.
Hier sind die Befehle, die Sie ausführen sollen (stellen Sie sicher, dass Sie eine AuraDB-Instanz eingerichtet haben und Ihre Zugangsdaten in einer .env-Datei in Ihrem Arbeitsverzeichnis gespeichert haben):
$ wget https://raw.githubusercontent.com/BexTuychiev/medium_stories/refs/heads/master/2024/9_september/3_neo4j_python/ingest_football_data.py $ python ingest_football_data.py
Das Skript kann je nach Ihrer Maschine und Ihrer Internetverbindung einige Minuten dauern. Sobald es jedoch beendet ist, sollte Ihre AuraDB-Instanz über 64k Knoten und 340k Beziehungen anzeigen.
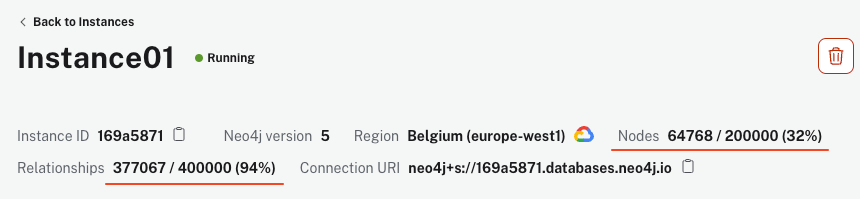
Verbinden Sie sich von Python aus mit Neo4j.
Jetzt sind wir bereit, uns mit unserer Aura DB-Instanz zu verbinden. Zuerst werden wir unsere Zugangsdaten aus der .env Datei lesen, indem wir dotenv verwenden:
import os from dotenv import load_dotenv load_dotenv() NEO4J_USERNAME = os.getenv("NEO4J_USERNAME") NEO4J_PASSWORD = os.getenv("NEO4J_PASSWORD") NEO4J_URI = os.getenv("NEO4J_URI")
Jetzt legen wir eine Verbindung an:
from neo4j import GraphDatabase uri = NEO4J_URI username = NEO4J_USERNAME password = NEO4J_PASSWORD driver = GraphDatabase.driver(uri, auth=(username, password)) try: driver.verify_connectivity() print("Connection successful!") except Exception as e: print(f"Failed to connect to Neo4j: {e}")
Ausgabe:
Connection successful!
Hier ist eine Erläuterung des Codes:
- Wir importieren
GraphDatabaseausneo4jum mit Neo4j zu interagieren. - Wir verwenden die zuvor geladenen Umgebungsvariablen, um unsere Verbindung einzurichten (
uri,username,password). - Wir erstellen ein Driver-Objekt mit
GraphDatabase.driver(), um eine Verbindung zu unserer Neo4j-Datenbank herzustellen. - Unter einem
with-Block verwenden wir dieverify_connectivity()Funktion, um zu überprüfen, ob eine Verbindung hergestellt wurde. Standardmäßig liefertverify_connectivity()nichts zurück, wenn die Verbindung erfolgreich ist.
Wenn das Tutorial beendet ist, rufen Sie driver.close() auf, um die Verbindung zu beenden und Ressourcen freizugeben. Treiberobjekte sind teuer in der Erstellung, daher sollten Sie nur ein einziges Objekt für Ihre Anwendung erstellen.
Cypher Query Language Essentials
Die Syntax von Cypher ist so konzipiert, dass sie intuitiv ist und Graphenstrukturen visuell darstellt. Sie basiert auf der folgenden ASCII-Art-Syntax:
(nodes)-[:CONNECT_TO]->(other_nodes)
Lassen Sie uns die Schlüsselkomponenten dieses allgemeinen Abfragemusters aufschlüsseln:
1. Knotenpunkte
In einer Cypher-Abfrage bedeutet ein Schlüsselwort in Klammern einen Knotennamen. Zum Beispiel: (Spieler) passt auf alle Spieler-Knoten. Nahezu immer werden Knotennamen mit Aliassen bezeichnet, um Abfragen lesbarer, einfacher zu schreiben und kompakter zu machen. Du kannst einem Knotennamen einen Alias hinzufügen, indem du ein Doppelpunkt voranstellst: (s: Spiel).
Innerhalb der Klammern kannst du eine oder mehrere Knoteneigenschaften für eine präzise Übereinstimmung mithilfe einer Wörterbuch-artigen Syntax angeben. Zum Beispiel:
// Alle Turnier-Knoten, die FIFA Weltmeisterschaft sind (t:Tournament {name: "FIFA World Cup"})
Knotenattribute werden direkt geschrieben, während der Wert, den du ihnen geben möchtest, ein String sein muss.
2. Beziehungen
Beziehungen verbinden Knoten untereinander und werden mit Quadraten und Pfeilen umgeben:
// Findet Knoten, die Teil eines Turniers sind (m:Match)-[PART_OF]->(t:Tournament)
Du kannst auch Aliasse und Attribute zu Beziehungen hinzufügen:
// Sucht nach Spielen, in denen Brasilien im Elfmeterschießen angetreten ist und der erste Schütze war (p:Player) - [r:SCORED_FOR {minute: 90}] -> (t:Team)
Beziehungen sind mit Pfeilen umwickelt -[BEZIEHUNG]->. Auch hier können Sie Alias-Eigenschaften in Klammern einfügen. Zum Beispiel:
// Alle Spieler, die ein Eigentor geschossen haben (p:Player)-[r:SCORED_IN {own_goal: True}]->(m:Match)
3. Klauseln
Genau wie COUNT(*) FROM table_name nichts ohne eine SELECT-Klausel in SQL zurückgeben würde, würde (node) - [BEZIEHUNG] -> (node) ohne Ergebnisse. Also, wie in SQL, hat Cypher verschiedene Klauseln, um Ihre Abfragenlogik zu strukturieren:
- y9>
DELETE: Entfernen von Knoten oder Beziehungen SET: Ändern von Eigenschaftswerten von Knoten oder Beziehungen Übersetzung:
MATCH: Musterabgleich im Graphen WHERE: Ergebnisse filternRETURN: Festlegen, was in den Ergebnismenge aufgenommen werden sollCREATE: Erstellen neuer Knoten oder BeziehungenDELETE: Entfernen von Knoten oder Beziehungen SET: Ändern von Eigenschaftswerten von Knoten oder Beziehungen VERKNÜPFEN: Erstellen von einzigartigen Knoten oder BeziehungenLÖSCHEN: Entfernen von Knoten, Beziehungen oder EigenschaftenSETZEN: Aktualisieren von Labels und Eigenschaften
Hier ist ein Beispielabfrage, die diese Konzepte demonstriert:
MATCH (p:Player)-[s:SCORED_IN]->(m:Match)-[PART_OF]->(t:Tournament) WHERE t.name = "FIFA World Cup" AND s.minute > 80 AND s.own_goal = True RETURN p.name AS Player, m.date AS MatchDate, s.minute AS GoalMinute ORDER BY s.minute DESC LIMIT 5
Diese Abfrage findet alle Spieler, die nach der 80. Spielminute in WM-Spielen ein Eigentor geschossen haben. Sie liest sich fast wie SQL, aber die SQL-Äquivalente beinhaltet mindestens einen JOIN.
Verwenden des Neo4j Python Drivers zum Analysezieren einer Graphendatenbank
Abfragen mit execute_query ausführen
Der Neo4j Python Driver ist die offizielle Bibliothek, die mit Python-Anwendungen mit einer Neo4j-Instanz interagiert. Er überprüft und kommuniziert Cypher-Abfragen, die in einfachen Python-Strings geschrieben sind, mit einem Neo4j-Server und holt sich die Ergebnisse in einem einheitlichen Format.
Alles beginnt mit der Erstellung eines Treiberobjekts mit der GraphDatabase Klasse. Von dort können wir mit dem execute_query Methode beginnen, Queries zu senden.
Für unsere erste Query, lassen Sie uns eine interessante Frage stellen: — Welches Team hat die meisten WM-Spiele gewonnen?
# Gib das Team zurück, das die meisten WM-Spiele gewonnen hat query = """ MATCH (t:Team)-[:WON]->(m:Match)-[:PART_OF]->(:Tournament {name: "FIFA World Cup"}) RETURN t.name AS Team, COUNT(m) AS MatchesWon ORDER BY MatchesWon DESC LIMIT 1 """ records, summary, keys = driver.execute_query(query, database_="neo4j")
Zuerst verwirfern wir die Query auf:
- Der
MATCHSchließende definieren das Muster, das wir wollen: Team -> Siege -> Spiel -> Teil von -> Turnier RETURNentspricht dem SQL-BefehlSELECT, mit dem wir Eigenschaften von zurückgegebenen Knoten und Beziehungen zurückgeben können. In dieser Klausel kannst du auch jede unterstützte Aggregationsfunktion in Cypher verwenden. Oben verwenden wirCOUNT.ORDER BYKlausel funktioniert auf die gleiche Weise wie in SQL.LIMITwird verwendet, um die Länge der zurückgegebenen Datensätze zu steuern.
Nachdem wir die Abfrage als mehrzeilige Zeichenkette definiert haben, geben wir sie an die execute_query() Methode des Treiberobjekts weiter und指定 Datenbankname (der Standard ist neo4j). Die Ausgabe enthält immer drei Objekte:
records: Eine Liste von Record-Objekten, die jeweils ein Zeile im Ergebnissatz repräsentieren. Jeder Record ist ein benanntes Tupel-ähnliches Objekt, in dem Sie Felder nach Namen oder Index zugreifen können.Zusammenfassung: Ein ResultSummary-Objekt, das Metadaten über die Abarbeitung einer Abfrage enthält, wie z.B. Statistiken und Zeitinformationen zur Abfrage.Schlüssel: Eine Liste von String-Werten, die die Spaltennamen im Ergebnis集表示.
Auf das summary-Objekt gehen wir später ein, denn wir sind hauptsächlich an Records, die Record Objekte enthalten. Wir können ihre Informationen abrufen, indem wir ihre data() Methode aufrufen:
for record in records: print(record.data())
Ausgabe:
{'Team': 'Brazil', 'MatchesWon': 76}
Das Ergebnis zeigt korrekt, dass Brasilien die meisten WM-Spiele gewonnen hat.
Übergabe von Abfrageparametern
Unsere letzte Abfrage ist nicht wiederverwendbar, da sie nur das erfolgreichste Team in der WM-Geschichte findet. Was, wenn wir das erfolgreichste Team in der Euro-Geschichte finden wollen?
Hier kommen Abfrageparameter ins Spiel:
query = """ MATCH (t:Team)-[:WON]->(m:Match)-[:PART_OF]->(:Tournament {name: $tournament}) RETURN t.name AS Team, COUNT(m) AS MatchesWon ORDER BY MatchesWon DESC LIMIT $limit """
In dieser Version der Anfrage werden wir zwei Parameter mithilfe des $-Zeichen einführen:
turnierlimit
Um Werte an die Anfrageparameter zu übergeben, verwenden wir Schlüsselwortargumente innerhalb von execute_query:
records, summary, keys = driver.execute_query( query, database_="neo4j", tournament="UEFA Euro", limit=3, ) for record in records: print(record.data())
Ausgabe:
{'Team': 'Germany', 'MatchesWon': 30} {'Team': 'Spain', 'MatchesWon': 28} {'Team': 'Netherlands', 'MatchesWon': 23}
Es wird immer empfohlen, Query-Parameter zu verwenden, wenn Sie überlegen, sich ändernde Werte in Ihre Anfrage einzubinden. Diese Best Practice schützt Ihre Abfragen vor Cypher-Injektionen und ermöglicht es Neo4j, sie zu cachen.
Schreiben in Datenbanken mit CREATE- und MERGE-Klauseln
Die Schreibung neuer Informationen in eine bestehende Datenbank erfolgt auf eine ähnliche Weise mit execute_query, indem jedoch ein CREATE-Aussage in der Abfrage verwendet wird. Zum Beispiel lassen Sie uns eine Funktion erstellen, die ein neues Knotentyp – Teamtrainer – hinzufügt:
def add_new_coach(driver, coach_name, team_name, start_date, end_date): query = """ MATCH (t:Team {name: $team_name}) CREATE (c:Coach {name: $coach_name}) CREATE (c)-[r:COACHES]->(t) SET r.start_date = $start_date SET r.end_date = $end_date """ result = driver.execute_query( query, database_="neo4j", coach_name=coach_name, team_name=team_name, start_date=start_date, end_date=end_date ) summary = result.summary print(f"Added new coach: {coach_name} for existing team {team_name} starting from {start_date}") print(f"Nodes created: {summary.counters.nodes_created}") print(f"Relationships created: {summary.counters.relationships_created}")
Die Funktion add_new_coach nimmt fünf Parameter auf:
- Driver: Das Neo4j-Treiberobjekt, das zum Verbinden mit der Datenbank verwendet wird.
coach_name: Der Name des neuen Trainers, der hinzugefügt werden soll.team_name: Der Name des Teams, mit dem der Trainer in Verbindung gebracht werden soll.start_date: Das Datum, an dem der Trainer das Team trainiert.end_date: Das Datum, an dem die Amtszeit des Trainers beim Team endet.
Die Cypher-Abfrage in der Funktion macht Folgendes:
- Findet einen bestehenden Team-Knoten mit dem angegebenen Teamnamen.
- Erstellt einen neuen Trainer-Knoten mit dem bereitgestellten Trainernamen.
- Erstellt eine COACHES-Beziehung zwischen den Knoten Coach und Team.
- Setzt die Eigenschaften
start_dateundend_dateauf derCOACHES-Beziehung.
Die Abfrage wird mit Hilfe der execute_query Methode ausgeführt, die die Abfragezeichenfolge und ein Dictionary von Parametern nimmt.
Nach der Ausführung gibt die Funktion folgendes aus:
- Eine Bestätigungsnachricht mit den Trainer- und Mannschaftsnamen und der Startdatum.
- Die Anzahl der erstellten Knoten (sollte 1 für den neuen Trainerknoten sein).
- Die Anzahl der erstellten Beziehungen (sollte 1 für die neue
COACHES-Beziehung sein).
Lasst uns es für einen der erfolgreichsten Trainer in der Geschichte des internationalen Fußballs laufen, Lionel Scaloni, der drei aufeinanderfolgende große internationale Turniere gewann (Weltmeisterschaft und zwei Copa Americas):
from neo4j.time import DateTime add_new_coach( driver=driver, coach_name="Lionel Scaloni", team_name="Argentina", start_date=DateTime(2018, 6, 1), end_date=None )
Output: Added new coach: Lionel Scaloni for existing team Argentina starting from 2018-06-01T00:00:00.000000000 Nodes created: 1 Relationships created: 1
In dem obenstehenden Snippet verwenden wir die DateTime Klasse aus dem neo4j.time Modul, um eine Datumsangabe korrekt in unsere Cypher-Abfrage einzubinden. Das Modul enthält weitere nützliche zeitliche Datentypen, die du anschauen könntest.
Apart from CREATE, gibt es auch die MERGE-Klausel zum Erstellen neuer Knoten und Beziehungen. Ihren wesentlichen Unterschied ist:
CREATEerzeugt immer neue Knoten/Beziehungen und kann zu Duplikaten führen.MERGEerstellt nur Knoten/Beziehungen, wenn sie noch nicht existieren.
In unserem Skript zur Dateneingabe zum Beispiel, wie Sie später sehen werden:
- Wir haben
MERGEfür Teams und Spieler, um Duplikate zu vermeiden. - Wir haben
CREATEverwendetSCORED_FORundSCORED_INfür die Beziehungen, da ein Spieler mehrmals in einem einzigen Spielpunkt punkten kann. - Diese sind keine wirklichen Duplikate, da sie verschiedene Eigenschaften haben (z.B., Torminute).
Dieser Ansatz sichert die Datenintegrität und ermöglicht zugleich mehrere ähnliche, aber unterschiedliche Beziehungen.
Eigene Transaktionen ausführen
Wenn du execute_query ausführst, erstellt der Treiber eine Transaktion im Hintergrund. Eine Transaktion ist eine Arbeits Einheit, die entweder in ihrem gesamten Ausführungsvorgang durchgeführt wird oder im Falle eines Fehlers zurückgenommen wird. Dies bedeutet, dass bei der Erstellung tausender Knoten oder Beziehungen in einer einzigen Transaktion (das ist möglich) und bei Encountere eines Fehlers in der Mitte, die gesamte Transaktion fehlschlägt und keine neuen Daten in den Graph geschrieben werden.
Um über jede Transaktion eine genauere Kontrolle zu haben, müssen Sie Sitzungsobjekte erzeugen. Zum Beispiel werden wir eine Funktion erstellen, um die besten K Zieleinsätze in einem gegebenen Turnier zu finden, indem wir ein Sitzungsobjekt verwenden:
def top_goal_scorers(tx, tournament, limit): query = """ MATCH (p:Player)-[s:SCORED_IN]->(m:Match)-[PART_OF]->(t:Tournament) WHERE t.name = $tournament RETURN p.name AS Player, COUNT(s) AS Goals ORDER BY Goals DESC LIMIT $limit """ result = tx.run(query, tournament=tournament, limit=limit) return [record.data() for record in result]
Zuerst erzeugen wirtop_goal_scorersFunktion, die drei Parameter annimmt, wobei der wichtigste der txTransaktionsobjekt ist, das mit einem Sitzungsobjekt erhalten wird.
with driver.session() as session: result = session.execute_read(top_goal_scorers, "FIFA World Cup", 5) for record in result: print(record)
Ausgabe:
{'Player': 'Miroslav Klose', 'Goals': 16} {'Player': 'Ronaldo', 'Goals': 15} {'Player': 'Gerd Müller', 'Goals': 14} {'Player': 'Just Fontaine', 'Goals': 13} {'Player': 'Lionel Messi', 'Goals': 13}
Dann verwenden wir unter einem mit der session()-Methode erstellten Kontextmanager execute_read(), wobei wir die top_goal_scorers()-Funktion übergeben, zusammen mit allen benötigten Parametern für die Abfrage.
Das Ergebnis von execute_read ist eine Liste von Record-Objekten, die korrekt die fünf besten Torschützen in der WM-Geschichte anzeigen, einschließlich Namen wie Miroslav Klose, Ronaldo Nazário und Lionel Messi.
Das Gegenstück zu execute_read() für die Dateneingabe ist execute_write().
Mit diesem gesagt, schauen wir uns nun das_INGESTION-Skript an, das wir zuvor verwendet haben, um einen Eindruck von der Funktionsweise der Dateningestion mit dem Neo4j Python-Treiber zu erhalten.
Dateningestion mit Neo4j Python-Treiber
Der ingest_football_data.py Datei beginnt mit Import-Anweisungen und dem Laden der notwendigen CSV-Dateien:
import pandas as pd import neo4j from dotenv import load_dotenv import os from tqdm import tqdm import logging # CSV-Dateipfade results_csv_path = "https://raw.githubusercontent.com/martj42/international_results/refs/heads/master/results.csv" goalscorers_csv_path = "https://raw.githubusercontent.com/martj42/international_results/refs/heads/master/goalscorers.csv" shootouts_csv_path = "https://raw.githubusercontent.com/martj42/international_results/refs/heads/master/shootouts.csv" # Logging einrichten logging.basicConfig(level=logging.INFO) logger = logging.getLogger(__name__) logger.info("Loading data...") # Daten laden results_df = pd.read_csv(results_csv_path, parse_dates=["date"]) goalscorers_df = pd.read_csv(goalscorers_csv_path, parse_dates=["date"]) shootouts_df = pd.read_csv(shootouts_csv_path, parse_dates=["date"])
Dieser Codeblock richtet auch einen Logger ein. Die nächsten Zeilen Code lesen meine Neo4j-Anmeldedaten mit dotenv und erstellen ein Driver-Objekt:
uri = os.getenv("NEO4J_URI") user = os.getenv("NEO4J_USERNAME") password = os.getenv("NEO4J_PASSWORD") try: driver = neo4j.GraphDatabase.driver(uri, auth=(user, password)) print("Connected to Neo4j instance successfully!") except Exception as e: print(f"Failed to connect to Neo4j: {e}") BATCH_SIZE = 5000
Da es mehr als 48.000 Übereinstimmungen in unserer Datenbank gibt, definieren wir einen BATCH_SIZE-Parameter, um Daten in kleineren Proben zu importieren.
Dann definieren wir eine Funktion namens create_indexes, die ein Session-Objekt akzeptiert:
def create_indexes(session): indexes = [ "CREATE INDEX IF NOT EXISTS FOR (t:Team) ON (t.name)", "CREATE INDEX IF NOT EXISTS FOR (m:Match) ON (m.id)", "CREATE INDEX IF NOT EXISTS FOR (p:Player) ON (p.name)", "CREATE INDEX IF NOT EXISTS FOR (t:Tournament) ON (t.name)", "CREATE INDEX IF NOT EXISTS FOR (c:City) ON (c.name)", "CREATE INDEX IF NOT EXISTS FOR (c:Country) ON (c.name)", ] for index in indexes: session.run(index) print("Indexes created.")
Cypher-Indizes sind Datenbankstrukturen, die die Abfrageleistung in Neo4j verbessern. Sie beschleunigen den Prozess der Aufsuchung von Knoten oder Beziehungen auf Basis von bestimmten Eigenschaften. Wir brauchen sie für:
- Schnellere Abfrageausführung
- Verbesserte Leseleistung auf großen Datensätzen
- Effiziente Musterabgleich
- Einhalten von eindeutigen Einschränkungen
- Bessere Skalierbarkeit mit wachsender Datenbank
Bei uns werden Indizes über Teamnamen, Spiel-IDs und Spielernamen die Abfragen beschleunigen, wenn nach bestimmten Entitäten gesucht wird oder Joins über verschiedene Knotentypen durchgeführt werden. Es ist eine beste Praxis, solche Indizes für Ihre eigenen Datenbanken zu erstellen.
Als nächstes haben wir die ingest_matches-Funktion. Sie ist groß, lassemus sie blockweise durchgehen:
def ingest_matches(session, df): query = """ UNWIND $batch AS row MERGE (m:Match {id: row.id}) SET m.date = date(row.date), m.home_score = row.home_score, m.away_score = row.away_score, m.neutral = row.neutral MERGE (home:Team {name: row.home_team}) MERGE (away:Team {name: row.away_team}) MERGE (t:Tournament {name: row.tournament}) MERGE (c:City {name: row.city}) MERGE (country:Country {name: row.country}) MERGE (home)-[:PLAYED_HOME]->(m) MERGE (away)-[:PLAYED_AWAY]->(m) MERGE (m)-[:PART_OF]->(t) MERGE (m)-[:PLAYED_IN]->(c) MERGE (c)-[:LOCATED_IN]->(country) WITH m, home, away, row.home_score AS hs, row.away_score AS as FOREACH(_ IN CASE WHEN hs > as THEN [1] ELSE [] END | MERGE (home)-[:WON]->(m) MERGE (away)-[:LOST]->(m) ) FOREACH(_ IN CASE WHEN hs < as THEN [1] ELSE [] END | MERGE (away)-[:WON]->(m) MERGE (home)-[:LOST]->(m) ) FOREACH(_ IN CASE WHEN hs = as THEN [1] ELSE [] END | MERGE (home)-[:DREW]->(m) MERGE (away)-[:DREW]->(m) ) """ ...
Das erste, was Sie feststellen werden, ist das UNWIND Schlüsselwort, das verwendet wird, um einen Datensatz zu verarbeiten. Es nimmt den $batch Parameter (der unsere DataFrame-Zeilen sein werden) und iteriert über jede Zeile, ermöglicht es uns also, mehrere Knoten und Beziehungen in einer einzigen Transaktion zu erstellen oder zu aktualisieren. Diese Methode ist effizienter als das Verarbeiten jeder Zeile einzeln, besonders bei großen Datensätzen.
Der Rest der Anfrage ist vertraut, da er mehrere MERGE– Klauseln verwendet. Danach erreichen wir die WITH-Klausel, die FOREACH-Konstrukte mit IN CASE-Anweisungen verwendet. Diese werden verwendet, um abhängig vom Ergebnis der Übereinstimmung Beziehungen zu erstellen. Wenn das Heimteam gewinnt, wird eine ‚WON‘-Beziehung für das Heimteam und eine ‚LOST‘-Beziehung für das Auswärtsteam erstellt und umgekehrt. Im Falle eines Unentschiedens erhalten beide Teams eine ‚DREW‘-Beziehung mit dem Spiel.
Der Rest der Funktion teilt den eingehenden DataFrame in Matches auf und konstruiert die Daten, die an den $batch Abfrageparameter übergeben werden:
def ingest_matches(session, df): query = """...""" for i in tqdm(range(0, len(df), BATCH_SIZE), desc="Ingesting matches"): batch = df.iloc[i : i + BATCH_SIZE] data = [] for _, row in batch.iterrows(): match_data = { "id": f"{row['date']}_{row['home_team']}_{row['away_team']}", "date": row["date"].strftime("%Y-%m-%d"), "home_score": int(row["home_score"]), "away_score": int(row["away_score"]), "neutral": bool(row["neutral"]), "home_team": row["home_team"], "away_team": row["away_team"], "tournament": row["tournament"], "city": row["city"], "country": row["country"], } data.append(match_data) session.run(query, batch=data)
ingest_goals und ingest_shootouts Funktionen verwenden ähnliche Konstrukte. Allerdings besitzt ingest_goals einige zusätzliche Fehler- und Fehlwertbehandlung.
Am Ende des Skripts haben wir die main()-Funktion, die alle unsere Ingestionsfunktionen mit einem Sitzungsobjekt ausführt:
def main(): with driver.session() as session: create_indexes(session) ingest_matches(session, results_df) ingest_goals(session, goalscorers_df) ingest_shootouts(session, shootouts_df) print("Data ingestion completed!") driver.close() if __name__ == "__main__": main()
Fazit und Nächste Schritte
Wir haben wichtige Aspekte der Arbeit mit Neo4j-Graphdatenbanken auf Basis von Python behandelt:
- Graphdatenbank-Konzepte und -Struktur
- Neo4j AuraDB einrichten
- Grundlagen der Cypher-Abfragesprache
- Verwendung des Neo4j Python-Treibers
- Dateningestion und Abfragenoptimierung
Weitere Ressourcen für Ihre Neo4j-Reise:
- Neo4j-Dokumentation
- Neo4j Graph Data Science Bibliothek
- Neo4j Cypher-Handbuch
- Neo4j Python-Treiber-Dokumentation
- Zertifizierung für Dateningenieurskarriere
- Einführung in NoSQL
- Ein umfassendes NoSQL-Tutorial mit MongoDB
Behalten Sie im Gedächtnis, dass die Stärke von Graphendatenbanken in der Darstellung und Abfrage komplexer Beziehungen liegt. Experimentieren Sie weiterhin mit verschiedenen Datenmodellen und erkunden Sie fortgeschrittene Cypher-Funktionen.