













I data scientists cominciano ad imparare SQL sin da primi tempi. È comprensibile, considerando l’ubiquità e l’utilità elevata dell’informazione tabellare. Tuttavia, esistono altri formati di database di successo, come i database grafici, per memorizzare dati connessi che non si adattano in un database relazionale SQL. In questo tutorial, impareremo su Neo4j, un popolare sistema di gestione database grafici che puoi utilizzare per creare, gestire e interrogare database grafici in Python.
Cosa sono i Database Grafici?
Prima di parlare di Neo4j, dediciamo un momento alla comprensione dei database grafici. Abbiamo un articolo completo che spiega cosa sono i database grafici, quindi ne riassumiamo i punti chiave qui.
Gli archivi grafici sono un tipo di database NoSQL (non usano SQL) progettati per la gestione di dati Collegamenti. A differenza degli archivi relazionali tradizionali, che usano tabelle e righe, gli archivi grafici usano strutture grafiche composte da:
- Nodi (entità) come persone, luoghi, concetti
- Bordi (relazioni) che collegano nodi diversi come persona VIVE IN una località, o un calciatore HA SEGNATO IN una partita.
- Proprietà (attributi per nodi/arco) come l’età di una persona, o quando nella partita è stato segnato il goal.
Questa struttura rende i database grafici ideali per la gestione di dati interconnessi in campi e applicazioni come le reti sociali, le raccomandazioni, la rilevazione di frodi, ecc., spesso ottenendo risultati migliori delle DB relazionali in termini di efficienza delle query. Ecco la struttura di un database grafico di esempio per un dataset calcistico:
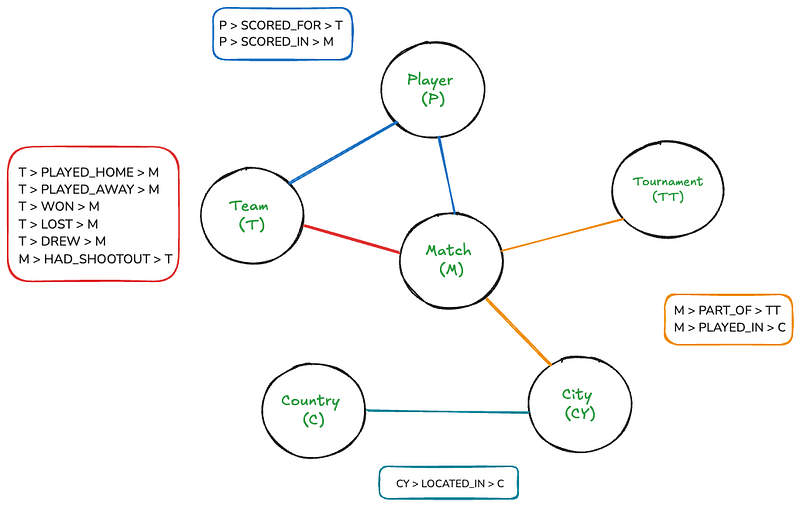
Anche se questo grafico rappresenta qualcosa di abbastanza intuitivo per gli umani, può diventare piuttosto complesso se disegnato su una canvas. Ma, con Neo4j, attraversare questo grafico sarà così semplice da scrivere semplici join SQL.
Il grafico ha sei nodi: Match, Team, Torneo, Giocatore, Nazione e Città. I rettangoli elencano le relazioni che esistono tra i nodi. Ci sono anche alcune proprietà di nodi e relazioni:
- Corrispondenza: data, punti_casa, punti_ospite
- Squadra: nome
- Calciatore: nome
- Torneo: nome
- Città: nome
- Paese: nome
- PUNTI_Ottenuti, PUNTI_Fatti: minuto, autogol, penale
- HAD_SHOOTOUT: vincitore, primo tiratore
Questo schema ci permette di rappresentare:
- Tutti i match con i relativi punteggi, date e luoghi
- Le squadre partecipanti a ciascun match (casa e in trasferta)
- I giocatori che fanno goal, inclusi dettagli come il minuto, i goal autogol e i calci pentalità
- I tornei a cui appartengono i match
- Le città e i paesi dove si disputano i match
- Informazioni sugli scontri, inclusi i vincitori e i primi tiratori (quando disponibili)
Il schema cattura la natura gerarchica delle posizioni (Città all’interno del Paese) e le varie relazioni tra entità (ad esempio, Squadre che giocano Partite, giocatori che segnano per le Squadre in Partite).
Questa struttura consente query flessibili, come trovare tutte le partite tra due squadre, tutti i gol segnati da un giocatore o tutte le partite in un determinato torneo o location.
Ma non ci spingiamo troppo avanti. Per cominciare, cos’è Neo4j e perché lo usare?
Cos’è Neo4j?
Neo4j, il principale nome nel mondo della gestione di DB grafi, è conosciuto per le sue caratteristiche potenti e la versità.
Al suo interno, Neo4j utilizza un sistema di memorizzazione grafica nativa, ottimizzato in modo significativo per eseguire operazioni grafiche. La sua efficienza nell’elaborazione di relazioni complesse lo rende superiore alle tradizionali basi di dati quando si tratta di dati Collegamenti. La scalabilità di Neo4j è davvero notevole: può gestire con facilità miliardi di nodi e relazioni, rendendolo adatto sia a piccoli progetti che a grandi aziende.
Un’altra caratteristica chiave di Neo4j è l’integrità dei dati. Garantisce pieno compliance con l’ACID (Atomicità, Consistenza, Isolamento, Durabilità), fornendo affidabilità e consistenza nelle transazioni.
Parlando di transazioni, il suo linguaggio di query, Cypher, offre una sintassi molto intuitiva e dichiarativa, progettata per i pattern grafici. Per questo motivo, questa sintassi è stata soprannominata “ASCII art”. Cypher non costerà problemi da imparare, soprattutto se sei già familiarizzato con SQL.
Con Cypher, è facile aggiungere nuovi nodi, relazioni o proprietà senza preoccuparsi di rompere query o schema esistenti. È adattabile alle rapide modifiche richieste dall’ambiente di sviluppo moderno.
Neo4j gode di un’ecosistema vibrante con supporto. Ha una documentazione estesa, strumenti completi per la visualizzazione dei grafi, una comunità attiva e integrazioni con altre lingue di programmazione come Python, Java e JavaScript.
Configurazione di Neo4j e di un ambiente Python
Prima di immergerci nel lavoro con Neo4j, dobbiamo configurare il nostro ambiente. Questa sezione vi guiderà attraverso la creazione di una istanza cloud per ospitare database Neo4j, la configurazione di un ambiente Python e la stabilizzazione di una connessione tra i due.
Non installare Neo4j
Se si desidera lavorare con database locali di grafi in Neo4j, allora sarà necessario scaricarlo e installarlo localmente, così come le sue dipendenze come Java. Ma in molti casi, interaggerai con un database Neo4j remoto esistente in qualche ambiente cloud.
Pertanto, non installerà Neo4j sul nostro sistema. Invece, creerà una istanza di database gratuita su Aura, il servizio cloud completamente gestito di Neo4j. Poi, userà laneo4j della libreria Python per connettersi a questo database e popolare con dati.
Creazione di una istanza di database Neo4j Aura
Per ospitare una grafica database gratuita su Aura DB, visitare la sua pagina prodotto e fare clic su “Inizia gratuitamente.”
Una volta registrato, verrà presentato il piano disponibile, e dovresti scegliere l’opzione gratuita. Poi riceverai una nuova istanza con un nome utente e una password per connetterti:
Copia la tua password, il tuo nome utente e l’URI di connessione.
Allora, creare una nuova directory di lavoro e un .env file per memorizzare le tue credenziali:
$ mkdir neo4j_tutorial; cd neo4j_tutorial $ touch .env
Incollare il seguente contenuto all’interno del file:
NEO4J_USERNAME="YOUR-NEO4J-USERNAME" NEO4J_PASSWORD="YOUR-COPIED-NEO4J-PASSWORD" NEO4J_CONNECTION_URI="YOUR-COPIED-NEO4J-URI"
Configurazione dell’ambiente Python
Adesso, installeremo la libreria client Python per neo4j in un nuovo ambiente Conda:
$ conda create -n neo4j_tutorial python=3.9 -y $ conda activate neo4j_tutorial $ pip install ipykernel # Per aggiungere l'ambiente a Jupyter $ ipython kernel install --user --name=neo4j_tutorial $ pip install neo4j python-dotenv tqdm pandas
I comandi installano anche la libreria ipykernel e la usano per aggiungere l’ambiente Conda appena creato a Jupyter come kernel. Quindi, installiamo il client neo4j Python per interagire con i database Neo4j e python-dotenv per gestire in modo sicuro le nostre credenziali Neo4j.
Popolare un’istanza di AuraDB con i dati del calcio
L’ingestione dei dati in un database a grafo è un processo complicato che richiede conoscenza dei fondamenti di Cypher. Poiché non abbiamo ancora imparato i concetti di base di Cypher, utilizzerai uno script Python che ho preparato per l’articolo che ingesterà automaticamente dati storici reali sul calcio. Lo script utilizzerà le credenziali che hai memorizzato per connettersi alla tua istanza di AuraDB.
I dati calcistici provengono da questo set di dati Kaggle sulle partite di calcio internazionale giocate tra il 1872 e il 2024. I dati sono disponibili in formato CSV, quindi lo script li smembra e li converte in formato grafo utilizzando Cypher e Neo4j. Alla fine dell’articolo, quando saranno abbastanza familiari con queste tecnologie, passerò in rassegna lo script riga per riga cosicché possiate capire come convertire le informazioni tabellari in un grafo.
Ecco i comandi da eseguire (assicurarsi di aver impostato l’istanza di AuraDB e di aver salvato le proprie credenziali in un .env file nel directory di lavoro):
$ wget https://raw.githubusercontent.com/BexTuychiev/medium_stories/refs/heads/master/2024/9_september/3_neo4j_python/ingest_football_data.py $ python ingest_football_data.py
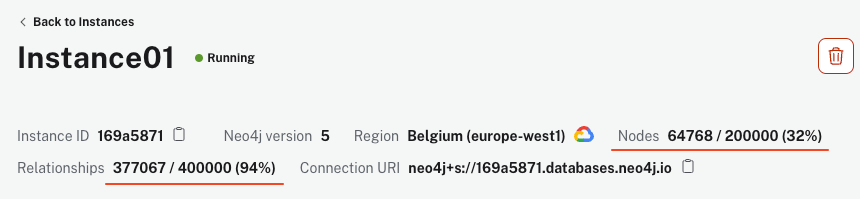
Il script potrebbe richiedere qualche minuto per essere eseguito, a seconda della macchina e della connessione Internet. Tuttavia, una volta completato, l’istanza di AuraDB deve mostrare oltre 64k nodi e 340k relazioni.
Connessione a Neo4j da Python
Ora, siamo pronti a connetterci alla nostra istanza di Aura DB. Prima di tutto, leggeremo le nostre credenziali dal file .env usando dotenv:
import os from dotenv import load_dotenv load_dotenv() NEO4J_USERNAME = os.getenv("NEO4J_USERNAME") NEO4J_PASSWORD = os.getenv("NEO4J_PASSWORD") NEO4J_URI = os.getenv("NEO4J_URI")
Ora, proviamo a stabilire una connessione:
from neo4j import GraphDatabase uri = NEO4J_URI username = NEO4J_USERNAME password = NEO4J_PASSWORD driver = GraphDatabase.driver(uri, auth=(username, password)) try: driver.verify_connectivity() print("Connection successful!") except Exception as e: print(f"Failed to connect to Neo4j: {e}")
Output:
Connection successful!
Ecco una spiegazione del codice:
- Importiamo
GraphDatabasedaneo4jper interagire con Neo4j. - Usiamo le variabili di ambiente precedentemente caricate per impostare la nostra connessione (
uri,username,password). - Creiamo un oggetto driver usando
GraphDatabase.driver(), stabilendo una connessione al nostro database Neo4j. - Sotto un
withblocco, usiamo laverify_connectivity()funzione per verificare se una connessione è stata stabilita. Per default,verify_connectivity()non restituisce nulla se la connessione è riuscita.
Una volta completato il tutorial, chiamare driver.close()per terminare la connessione e liberare le risorse. I risorse del driver sono costosi da creare, quindi dovresti creare un solo oggetto per il tuo applicativo.
Elementi chiave del linguaggio di query Cypher
La sintassi di Cypher è progettata per essere intuitiva e per rappresentare visivamente le strutture grafiche. si basa sulla seguente sintassi tipo ASCII-art:
(nodes)-[:CONNECT_TO]->(other_nodes)
Scopriamo i componenti chiave di questo schema generale di query:
1. Nodi
In una query Cypher, una parola chiave in parentesi indica il nome di un nodo. Per esempio, (Giocatore) corrisponde a tutti i nodi Giocatore. Praticamente sempre, i nomi di nodo vengono citati con alias per rendere le query più leggibili, semplici da scrivere e compressive. È possibile aggiungere un alias a un nome di nodo posizionando un punto e comma prima di esso: (m:Match).
Dentro le parentesi, è possibile specificare una o più proprietà di nodo per un’associazione precisa utilizzando una sintassi simile ad un dizionario. Per esempio:
// Tutti i nodi torneo che sono la FIFA World Cup (t:Tournament {name: "FIFA World Cup"})
Le proprietà dei nodi sono scritte come sono, mentre il valore che vuoi che abbiano deve essere una stringa.
2. Relazioni
Le relazioni connettono i nodi l’uno con l’altro e sono racchiuse fra parentesi quadre e frecce:
// Corrisponde ai nodi che sono PART_OF di qualche torneo (m:Match)-[PART_OF]->(t:Tournament)
Puoi aggiungere anche alias e proprietà alle relazioni:
// Corrisponde a quelle partite in cui il Brasile ha partecipato ad una serie di rigori e fu il primo a tirare (p:Player) - [r:SCORED_FOR {minute: 90}] -> (t:Team)
Le relazioni sono racchiuse da frecce-[RELATIONSHIP]->. Di nuovo, puoi includere proprietà alias all’interno delle parentesi graffe. Per esempio:
// Tutti i giocatori che hanno segnato un autogol (p:Player)-[r:SCORED_IN {own_goal: True}]->(m:Match)
3. Clausole
Come COUNT(*) FROM table_name non restituirebbe alcun risultato senza una SELECT clausola in SQL, (node) - [RELATIONSHIP] -> (node) non potrebbe recuperare alcun risultato. Quindi, proprio come in SQL, Cypher ha diverse clausole per strutturare la logica delle query come in SQL:
MATCH: Confronto di pattern nel grafoWHERE: Filtrare i risultatiRETURN: Specificare cosa includere nel set di risultatiCREATE: Creare nuovi nodi o relazioniMERGE: Creare nodi o relazioni uniciDELETE: Rimuovere nodi, relazioni o proprietàSET: Aggiornareetichette e proprietà
Ecco un esempio di query che dimostra questi concetti:
MATCH (p:Player)-[s:SCORED_IN]->(m:Match)-[PART_OF]->(t:Tournament) WHERE t.name = "FIFA World Cup" AND s.minute > 80 AND s.own_goal = True RETURN p.name AS Player, m.date AS MatchDate, s.minute AS GoalMinute ORDER BY s.minute DESC LIMIT 5
Questa query trova tutti i giocatori che hanno segnato autogol in partite del Mondiale dopo il minuto 80. Sembra quasi SQL, ma l’equivalente SQL richiede almeno un JOIN.
Uso del driver Python per Neo4j per analizzare una base dati grafica
Esecuzione di query con execute_query
Il driver Python per Neo4j è la libreria ufficiale che interagisce con un’istanza di Neo4j attraverso applicazioni Python. Verifica e comunica le query Cypher scritte in stringhe di Python semplici con un server Neo4j e recupera i risultati in un formato unificato.
Tutto inizia creando un oggetto driver usando la classe GraphDatabase . Da qui, possiamo iniziare a inviare query usando il metodo execute_query .
Per la nostra prima query, facciamo una domanda interessante: Chi ha vinto più partite mondiali?
# Restituisce la squadra che ha vinto il maggior numero di partite mondiali query = """ MATCH (t:Team)-[:WON]->(m:Match)-[:PART_OF]->(:Tournament {name: "FIFA World Cup"}) RETURN t.name AS Team, COUNT(m) AS MatchesWon ORDER BY MatchesWon DESC LIMIT 1 """ records, summary, keys = driver.execute_query(query, database_="neo4j")
Prima di tutto, scompariamo la query in parti:
- Il
MATCHfinale definisce il modello che cerchiamo: Squadra -> Vittorie -> Partita -> Parte di -> Torneo RETURNè equivalente alla statementSELECTdi SQL, in cui possiamo restituire le proprietà degli nodi e delle relazioni restituiti. In questa clausola, è anche possibile utilizzare qualsiasi funzione di aggregazione supportata in Cypher. E sopra, stiamo utilizzandoCOUNT.ORDER BYla clause funziona nello stesso modo della clausolaORDER BYdi SQL.LIMITviene utilizzato per controllare la lunghezza dei record restituiti.
Dopo aver definito la query come una stringa multipla, la passiamo al metodo execute_query() dell’oggetto driver e specificiamo il nome del database (il default è neo4j). L’output contiene sempre tre oggetti:
records: Una lista di oggetti Record, ognuno rappresentante una riga nell’insieme di risultati. Ogni Record è un oggetto simile a una tupla con nomi, attraverso cui è possibile accedere ai campi in base al nome o all’indice.risum: Un oggetto ResultSummary che contiene metadati riguardanti l’esecuzione della query, come ad esempio le statistiche sulla query e le informazioni sull’orario.chiavi: Un elenco di stringhe che rappresentano i nomi delle colonne nell’insieme di risultati.
Toccherà poi il summary oggetto perché ci occupiamo principalmente di records, che contengono gli Record oggetti. Possiamo recuperare le loro informazioni chiamando il loro metodo data():
for record in records: print(record.data())
Output:
{'Team': 'Brazil', 'MatchesWon': 76}
Il risultato correttamente mostra che il Brasile ha vinto più partite mondiali.
Trasmissione di parametri di ricerca
La nostra ultima ricerca non è riutilizzabile, in quanto trova solo la squadra più vincente della storia del Mondiale. E se vogliamo trovare la squadra più vincente della storia dell’Euro?
Ecco dove entra in gioco il passaggio di parametri di ricerca:
query = """ MATCH (t:Team)-[:WON]->(m:Match)-[:PART_OF]->(:Tournament {name: $tournament}) RETURN t.name AS Team, COUNT(m) AS MatchesWon ORDER BY MatchesWon DESC LIMIT $limit """
In questa versione della query, abbiamo introdotto due parametri utilizzando i $ segni:
tournamentlimit
Per passare i valori ai parametri della query, usiamo gli argomenti chiave all’interno di execute_query:
records, summary, keys = driver.execute_query( query, database_="neo4j", tournament="UEFA Euro", limit=3, ) for record in records: print(record.data())
Output:
{'Team': 'Germany', 'MatchesWon': 30} {'Team': 'Spain', 'MatchesWon': 28} {'Team': 'Netherlands', 'MatchesWon': 23}
Sempre è consigliato usare parametri di ricerca ogni volta che si considera l’ingestione di valori in cambio nelle query. questa migliore pratica protegge le query da iniezioni Cypher e consente a Neo4j di cachearle.
Scrittura su database con clausole CREATE e MERGE
Scrivere nuove informazioni in una database esistente è fatto similmente con execute_query ma utilizzando una CREATE clausola nella query. Per esempio, creiamo una funzione che aggiungerà un nuovo tipo di nodo – allenatori di squadra:
def add_new_coach(driver, coach_name, team_name, start_date, end_date): query = """ MATCH (t:Team {name: $team_name}) CREATE (c:Coach {name: $coach_name}) CREATE (c)-[r:COACHES]->(t) SET r.start_date = $start_date SET r.end_date = $end_date """ result = driver.execute_query( query, database_="neo4j", coach_name=coach_name, team_name=team_name, start_date=start_date, end_date=end_date ) summary = result.summary print(f"Added new coach: {coach_name} for existing team {team_name} starting from {start_date}") print(f"Nodes created: {summary.counters.nodes_created}") print(f"Relationships created: {summary.counters.relationships_created}")
La funzione add_new_coach prende cinque parametri:
- driver: L’oggetto driver di Neo4j utilizzato per connettersi al database.
coach_name: Il nome del nuovo allenatore da aggiungere.team_name: Il nome della squadra a cui l’allenatore sarà associato.start_date: La data di inizio dell’attività di allenamento del coach con la squadra.end_date: La data di fine del periodo di allenamento del coach con la squadra.
La query Cypher nella funzione esegue le seguenti operazioni:
- Corrisponde a un nodo Squadra esistente con il nome della squadra dato.
- Crea un nuovo nodo Allenatore con il nome dell’allenatore fornito.
- Crea una relazione COACHES tra il nodo Coach e il nodo Team.
- Imposta le proprietà
start_dateeend_datesulla relazioneCOACHES.
L’esecuzione della query avviene utilizzando la execute_query metodo, che prende la stringa di query e un dizionario di parametri.
Dopo l’esecuzione, la funzione stampa:
- Un messaggio di conferma con i nomi dell’allenatore e della squadra e la data di inizio.
- Il numero di nodi creati (deve essere 1 per il nuovo nodo Allenatore).
- Il numero di relazioni create (deve essere 1 per la nuova relazione
COACHES).
Ci occuperemo di uno degli allenatori più vincenti della storia del calcio internazionale, Lionel Scaloni, che ha vinto tre tornei internazionali di rilevanza principale (Campionato del Mondo e due Copa America):
from neo4j.time import DateTime add_new_coach( driver=driver, coach_name="Lionel Scaloni", team_name="Argentina", start_date=DateTime(2018, 6, 1), end_date=None )
Output: Added new coach: Lionel Scaloni for existing team Argentina starting from 2018-06-01T00:00:00.000000000 Nodes created: 1 Relationships created: 1
Nel snippet precedente, stiamo usando la classe DateTime del modulo neo4j.time per passare una data correttamente nella nostra query Cypher. Il modulo contiene altri utili tipi di dati temporali che potreste voler controllare.
Oltre aCREATE, esiste anche laMERGE clausola per la creazione di nuovi nodi e relazioni. La loro differenza chiave è:
CREATEcrea sempre nuovi nodi/relazioni, potenzialmente portando a duplicati.MERGEcrea nodi/relazioni solo se non esistono già.
Per esempio, nel nostro script di ingestione dati, come vedrete più avanti:
- Noi abbiamo usato
MERGEper team e giocatori per evitare duplicati. - Noi abbiamo utilizzato
CREATEperSCORED_FOReSCORED_INperché un giocatore può segnare multipli volte lo stesso match. - Queste non sono veri duplicati in quanto hanno proprietà differenti (ad esempio, minuto di rete).
Questo approcio garantisce l’integrità dei dati permettendo allo stesso tempo molteplici relazioni simili ma distinte.
Eseguire le proprie transazioni
Quando si eseguono execute_query, il driver crea una transazione in background. Una transazione è una unità di lavoro che può essere eseguita integralmente oppure annullata in caso di fallimento. Questo significa che quando si creano migliaia di nodi o relazioni in una singola transazione (è possibile) e si incontra un errore a metà strada, l’intera transazione fallisce senza scrivere alcun nuovo dato nel grafo.
Per avere un controllo più dettagliato su ciascuna transazione, è necessario creare oggetti di sessione. Ad esempio, creiamo una funzione per trovare i primi K goal scorer in un dato torneo utilizzando un oggetto di sessione:
def top_goal_scorers(tx, tournament, limit): query = """ MATCH (p:Player)-[s:SCORED_IN]->(m:Match)-[PART_OF]->(t:Tournament) WHERE t.name = $tournament RETURN p.name AS Player, COUNT(s) AS Goals ORDER BY Goals DESC LIMIT $limit """ result = tx.run(query, tournament=tournament, limit=limit) return [record.data() for record in result]
Prima di tutto, creiamotop_goal_scorersla funzione che accetta tre parametri, il più importante dei quali ètx l’oggetto di transazione che verrà ottenuto utilizzando un oggetto di sessione.
with driver.session() as session: result = session.execute_read(top_goal_scorers, "FIFA World Cup", 5) for record in result: print(record)
Output:
{'Player': 'Miroslav Klose', 'Goals': 16} {'Player': 'Ronaldo', 'Goals': 15} {'Player': 'Gerd Müller', 'Goals': 14} {'Player': 'Just Fontaine', 'Goals': 13} {'Player': 'Lionel Messi', 'Goals': 13}
Successivamente, sotto un gestore di contesto creato con il session() metodo, usiamo execute_read(), passando la funzione top_goal_scorers() insieme a tutti i parametri richiesti dalla query.
Lauscita di execute_read è una lista di oggetti Record che correttamente mostrano i primi 5 marcatori di tutti i tempi al Mondiale, inclusi nomi come Miroslav Klose, Ronaldo Nazario, e Lionel Messi.
Il corrispondente di execute_read() per l’ingestione dati è execute_write().
Detto ciò, ora guardiamo all’script di ingestione che abbiamo usato prima per capire come funziona l’ingestione dati con il driver Python di Neo4j.
Ingestione dati utilizzando il driver Python di Neo4j
Il ingest_football_data.py file inizia con dichiarazioni di import e il caricamento dei necessari file CSV:
import pandas as pd import neo4j from dotenv import load_dotenv import os from tqdm import tqdm import logging Percorsi file CSV results_csv_path = "https://raw.githubusercontent.com/martj42/international_results/refs/heads/master/results.csv" goalscorers_csv_path = "https://raw.githubusercontent.com/martj42/international_results/refs/heads/master/goalscorers.csv" shootouts_csv_path = "https://raw.githubusercontent.com/martj42/international_results/refs/heads/master/shootouts.csv" Impostazioni logging logging.basicConfig(level=logging.INFO) logger = logging.getLogger(__name__) logger.info("Loading data...") Caricamento dati results_df = pd.read_csv(results_csv_path, parse_dates=["date"]) goalscorers_df = pd.read_csv(goalscorers_csv_path, parse_dates=["date"]) shootouts_df = pd.read_csv(shootouts_csv_path, parse_dates=["date"])
Questo blocco di codice imposta anche un logger. Le prossime righe di codice leggono le credenziali di Neo4j utilizzando dotenv e creano un oggetto Driver:
uri = os.getenv("NEO4J_URI") user = os.getenv("NEO4J_USERNAME") password = os.getenv("NEO4J_PASSWORD") try: driver = neo4j.GraphDatabase.driver(uri, auth=(user, password)) print("Connected to Neo4j instance successfully!") except Exception as e: print(f"Failed to connect to Neo4j: {e}") BATCH_SIZE = 5000
Poiché ci sono più di 48k corrispondenze nel nostro database, definiamo un parametro BATCH_SIZE per l’ingestione di dati in campioni più piccoli.
Poi, definiamo una funzione chiamata create_indexes che accetta un oggetto sessione:
def create_indexes(session): indexes = [ "CREATE INDEX IF NOT EXISTS FOR (t:Team) ON (t.name)", "CREATE INDEX IF NOT EXISTS FOR (m:Match) ON (m.id)", "CREATE INDEX IF NOT EXISTS FOR (p:Player) ON (p.name)", "CREATE INDEX IF NOT EXISTS FOR (t:Tournament) ON (t.name)", "CREATE INDEX IF NOT EXISTS FOR (c:City) ON (c.name)", "CREATE INDEX IF NOT EXISTS FOR (c:Country) ON (c.name)", ] for index in indexes: session.run(index) print("Indexes created.")
Gli indici Cypher sono strutture del database che migliorano il performance delle query in Neo4j. Rendono più veloce il processo di ricerca di nodi o relazioni in base a specifiche proprietà. Ne abbiamo bisogno per:
- Esecuzione più veloce delle query
- Migliore performance di lettura su grandi set di dati
- Matchett efficienti
- Implementazione di vincoli univoci
- Migliore scalabilità man mano che il database cresce
Nel nostro caso, le index sui nomi delle squadre, sugli ID delle partite e sui nomi dei giocatori aiuteranno le nostre query a funzionare più velocemente quando si cercano specifiche entità o si eseguono join tra differenti tipi di nodi. È una pratica consigliata creare questi index nei propri database.
Poi, abbiamo la funzione ingest_matches che è piuttosto grande, quindi la smemoreremo riga per riga:
def ingest_matches(session, df): query = """ UNWIND $batch AS row MERGE (m:Match {id: row.id}) SET m.date = date(row.date), m.home_score = row.home_score, m.away_score = row.away_score, m.neutral = row.neutral MERGE (home:Team {name: row.home_team}) MERGE (away:Team {name: row.away_team}) MERGE (t:Tournament {name: row.tournament}) MERGE (c:City {name: row.city}) MERGE (country:Country {name: row.country}) MERGE (home)-[:PLAYED_HOME]->(m) MERGE (away)-[:PLAYED_AWAY]->(m) MERGE (m)-[:PART_OF]->(t) MERGE (m)-[:PLAYED_IN]->(c) MERGE (c)-[:LOCATED_IN]->(country) WITH m, home, away, row.home_score AS hs, row.away_score AS as FOREACH(_ IN CASE WHEN hs > as THEN [1] ELSE [] END | MERGE (home)-[:WON]->(m) MERGE (away)-[:LOST]->(m) ) FOREACH(_ IN CASE WHEN hs < as THEN [1] ELSE [] END | MERGE (away)-[:WON]->(m) MERGE (home)-[:LOST]->(m) ) FOREACH(_ IN CASE WHEN hs = as THEN [1] ELSE [] END | MERGE (home)-[:DREW]->(m) MERGE (away)-[:DREW]->(m) ) """ ...
La prima cosa che noterai è il UNWIND keyword, che viene utilizzato per processare un insieme di dati. Prende il $batch parametro (che saranno le nostre righe del DataFrame) e iterando su ogni riga, ci consente di creare o aggiornare molti nodi e relazioni in una singola transazione. Questo approcio è più efficiente del processare ogni riga individualmente, specialmente per grandi set di dati.
La restante parte della query è familiare poiché utilizza molte MERGE clausole. Poi, raggiungiamo la WITH clausola, che utilizza FOREACH costruttivi con IN CASE dichiarazioni. Queste sono usate per creare relazioni condizionalmente in base al risultato della corrispondenza. Se la squadra di casa vince, crea una relazione ‘WON’ per la squadra di casa e una relazione ‘LOST’ per la squadra ospite, e viceversa. In caso di pareggio, entrambe le squadre ottengono una relazione ‘DREW’ con la partita.
Il resto della funzione divide il DataFrame in ingresso in corrispondenze e costruisce i dati che verranno passati al $batch parametro della query:
def ingest_matches(session, df): query = """...""" for i in tqdm(range(0, len(df), BATCH_SIZE), desc="Ingesting matches"): batch = df.iloc[i : i + BATCH_SIZE] data = [] for _, row in batch.iterrows(): match_data = { "id": f"{row['date']}_{row['home_team']}_{row['away_team']}", "date": row["date"].strftime("%Y-%m-%d"), "home_score": int(row["home_score"]), "away_score": int(row["away_score"]), "neutral": bool(row["neutral"]), "home_team": row["home_team"], "away_team": row["away_team"], "tournament": row["tournament"], "city": row["city"], "country": row["country"], } data.append(match_data) session.run(query, batch=data)
ingest_goals e ingest_shootouts utilizzano costrutti simili. Tuttavia, ingest_goals hanno un’addizionale gestione degli errori e dei valori mancanti.
Alla fine del script, abbiamo la main()funzione che esegue tutte le nostre funzioni di ingestione con un oggetto sessione:
def main(): with driver.session() as session: create_indexes(session) ingest_matches(session, results_df) ingest_goals(session, goalscorers_df) ingest_shootouts(session, shootouts_df) print("Data ingestion completed!") driver.close() if __name__ == "__main__": main()
Conclusione e Passaggi Successivi
Abbiamo illustrato i principali aspetti del lavoro con database grafici Neo4j utilizzando Python:
- Concetti e struttura dei database grafici
- Impostazione di Neo4j AuraDB
- Basic del linguaggio di query Cypher
- Uso del driver Python per Neo4j
- Ingestione dati e ottimizzazione query
Per approfondire la tua esperienza con Neo4j, esplora queste risorse:
- Documentazione Neo4j
- Neo4j Graph Data Science Library
- Manuale di Neo4j Cypher
- Documentazione del driver Neo4j per Python
- Certificazione carriera in Ingegneria dei dati
- Introduzione a NoSQL
- Guida completa alle basi di dati NoSQL usando MongoDB
ricorda, il potere delle basi di dati grafiche è nell’ rappresentare e interrogare relazioni complesse. Continua a sperimentare con diversi modelli dati e a esplorare le funzionalità avanzate di Cypher.