













检索增强生成(RAG)是获取实时数据或根据用户文本输入从数据源获取更新数据的最流行方法。因此,为我们的所有搜索应用程序提供了最先进的神经搜索技术。
在RAG搜索系统中,每个用户请求都通过嵌入模型转换为向量表示,然后使用诸如余弦相似度、最长公共子序列等各种算法执行向量比较,与存储在我们的向量支持数据库中的现有向量表示进行比较。
向量数据库中存储的现有向量也通过单独的后台进程异步生成或更新。
 此图表提供了向量比较的概念概览
此图表提供了向量比较的概念概览
要使用RAG,我们至少需要一个嵌入模型和一个向量存储数据库供应用程序使用。社区和开源项目的贡献为我们提供了一套出色的工具,帮助我们构建有效和高效的RAG应用程序。
在本文中,我们将在一个Python应用程序中实现向量数据库和嵌入生成模型的用法。如果您是第一次或第n次阅读这个概念,您只需要工作工具,不需要订阅任何工具。您可以简单地下载工具并开始使用。
我们的技术栈包括以下开源和免费使用的工具:
- 操作系统 – Ubuntu Linux
- 向量数据库 – Apache Cassandra
- 嵌入模型 – nomic-embed-text
- 编程语言 – Python
该技术栈的主要优势
- 开源
- 隔离数据以符合数据合规标准
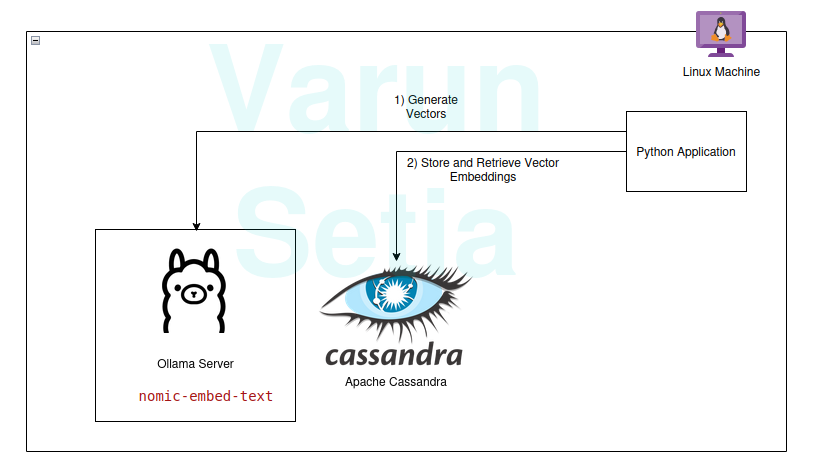
实现步骤
只有在满足先决条件的情况下,您才能实施并跟随操作;否则,请阅读到最后以理解这些概念。
先决条件
- Linux(在我这里是 Ubuntu 24.04.1 LTS)
- Java 设置(OpenJDK 17.0.2)
- Python(3.11.11)
- Ollama
Ollama 模型设置
Ollama是一个开源的中间件服务器,它充当生成式人工智能和应用程序之间的抽象层,通过安装所有必要的工具,使生成式人工智能模型能够作为CLI和API在机器上使用。它拥有大多数公开可用的模型,如llama、phi、mistral、snowflake-arctic-embed等。它是跨平台的,可以在操作系统中轻松配置。
在Ollama中,我们将拉取nomic-embed-text 模型来生成嵌入。
在命令行中运行:
ollama pull nomic-embed-text
该模型生成大小为768向量的嵌入。
Apache Cassandra设置和脚本
Cassandra是一个设计用于处理需要高扩展性的工作负载的开源NoSQL数据库,最近在版本5.0中添加了对矢量搜索的支持,这将促进我们的RAG用例。
注意: Cassandra需要Linux操作系统才能运行;也可以作为Docker镜像安装。
安装
从https://cassandra.apache.org/_/download.html下载Apache Cassandra。
将Cassandra配置到您的PATH中。
通过在命令行中运行以下命令来启动服务器:
cassandra
Table
打开一个新的Linux终端并输入cqlsh;这将打开Cassandra查询语言的shell。现在,执行以下脚本来创建embeddings键空间,document_vectors表,以及执行必要的索引edv_ann_index来执行矢量搜索。
CREATE KEYSPACE IF NOT EXISTS embeddings
WITH REPLICATION = { 'class' : 'SimpleStrategy', 'replication_factor' : '1' };
USE embeddings;
CREATE TABLE IF NOT EXISTS embeddings.document_vectors (
record_id timeuuid,
id uuid,
content_chunk text,
content_vector VECTOR <FLOAT, 768>,
created_at timestamp,
PRIMARY KEY (id, created_at)
)
WITH CLUSTERING ORDER BY (created_at DESC);
CREATE INDEX IF NOT EXISTS edv_ann_index
ON embeddings.document_vectors(content_vector) USING 'sai';
注意: content_vector VECTOR <FLOAT, 768>负责存储模型生成的长度为768的向量。
里程碑1:我们已经准备好建立用于存储向量的数据库。
Python 代码
这种编程语言无需介绍;它易于使用,受到行业的喜爱,并拥有强大的社区支持。
虚拟环境
设置虚拟环境:
sudo apt install python3-virtualenv && python3 -m venv myvenv
激活虚拟环境:
source /media/setia/Data/Tutorials/cassandra-ollama-app/myvenv/bin/activate
包
下载Datastax Cassandra包:
pip install cassandra-driver
下载requests包:
pip install requests
文件
创建名为app.py的文件。
现在,写入以下代码将示例文档插入Cassandra。这始终是插入数据库中数据的第一步;可以通过单独的异步进程完成。为了演示目的,我编写了一个将首先在数据库中插入文档的方法。稍后,一旦文档插入成功,我们可以注释掉这个方法。
from cassandra.cluster import Cluster
from cassandra.query import PreparedStatement, BoundStatement
import uuid
import datetime
import requests
cluster = Cluster(['127.0.0.1'],port=9042)
session = cluster.connect()
def generate_embedding(text):
embedding_url = 'http://localhost:11434/api/embed'
body = {
"model": "nomic-embed-text",
"input": text
}
response = requests.post(embedding_url, json = body)
return response.json()['embeddings'][0]
def insert_chunk(content, vector):
id = uuid.uuid4()
content_chunk = content
content_vector = vector
created_at = datetime.datetime.now()
insert_query = """
INSERT INTO embeddings.document_vectors (record_id, id, content_chunk, content_vector, created_at)
VALUES (now(), ?, ?, ?, ?)
"""
prepared_stmt = session.prepare(insert_query)
session.execute(prepared_stmt, [
id,
content_chunk,
content_vector,
created_at
])
def insert_sample_data_in_cassandra():
sentences = [
"The aroma of freshly baked bread wafted through the quaint bakery nestled in the cobblestone streets of Paris, making Varun feel like time stood still.",
"Sipping a spicy masala chai in a bustling tea stall in Mumbai, Varun felt he was tasting the very soul of the city.",
"The sushi in a small Tokyo diner was so fresh, it felt like Varun was on a culinary journey to the sea itself.",
"Under the starry desert sky in Morocco, Varun enjoyed a lamb tagine that tasted like a dream cooked slowly over a fire.",
"The cozy Italian trattoria served the creamiest risotto, perfectly capturing the heart of Tuscany on a plate, which Varun savored with delight.",
"Enjoying fish tacos on a sunny beach in Mexico, with the waves crashing nearby, made the flavors unforgettable for Varun.",
"The crispy waffles drizzled with syrup at a Belgian café were worth every minute of waiting, as Varun indulged in the decadent treat.",
"A bowl of warm pho in a roadside eatery in Hanoi felt like comfort wrapped in a broth of herbs and spices, giving Varun a sense of warmth.",
"Sampling chocolate truffles in a Swiss chocolate shop, Varun found himself in a moment of pure bliss amidst snow-capped mountains.",
"The street food stalls in Bangkok served fiery pad Thai that left Varun with a tangy memory of the city’s vibrant energy."
]
for sentence in sentences:
vector = generate_embedding(sentence)
insert_chunk(sentence, vector)
insert_sample_data_in_cassandra()
现在,在虚拟环境中使用命令行运行这个文件:
python app.py
一旦文件被执行并插入文档,可以通过从cqlsh并执行:
SELECT content_chunk FROM embeddings.document_vectors;
这将返回数据库中插入的10个文档,如下面的屏幕截图所示。
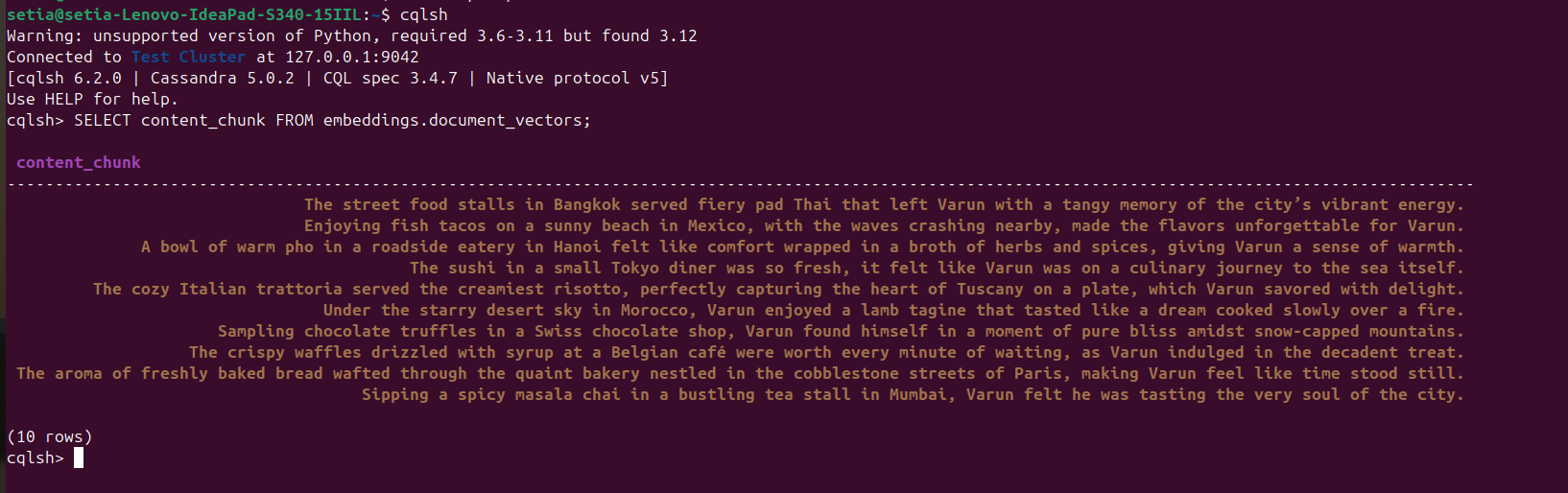
里程碑2:我们已经完成了在我们的向量数据库中的数据设置。
现在,我们将编写代码来基于余弦相似性查询文档。余弦相似性是两个向量值的点积。它的公式是A.B / |A||B|。这种余弦相似性在Apache Cassandra内部得到支持,帮助我们在数据库中计算所有内容并高效处理大量数据。
下面的代码是不言自明的;它根据余弦相似性获取前三个结果,使用ORDER BY <column name> ANN OF <text_vector>,并返回余弦相似性值。要执行此代码,我们需要确保对此向量列应用了索引。
def query_rag(text):
text_embeddings = generate_embedding(text)
select_query = """
SELECT content_chunk,similarity_cosine(content_vector, ?) FROM embeddings.document_vectors
ORDER BY content_vector ANN OF ?
LIMIT 3
"""
prepared_stmt = session.prepare(select_query)
result_rows = session.execute(prepared_stmt, [
text_embeddings,
text_embeddings
])
for row in result_rows:
print(row[0], row[1])
query_rag('Tell about my Bangkok experiences')
记得要注释插入代码:
#insert_sample_data_in_cassandra()
现在,通过使用python app.py执行Python代码。
我们将得到以下输出:
(myvenv) setia@setia-Lenovo-IdeaPad-S340-15IIL:/media/setia/Data/Tutorials/cassandra-ollama-app$ python app.py
The street food stalls in Bangkok served fiery pad Thai that left Varun with a tangy memory of the city’s vibrant energy. 0.8205469250679016
Sipping a spicy masala chai in a bustling tea stall in Mumbai, Varun felt he was tasting the very soul of the city. 0.7719690799713135
A bowl of warm pho in a roadside eatery in Hanoi felt like comfort wrapped in a broth of herbs and spices, giving Varun a sense of warmth. 0.7495554089546204
您可以看到“曼谷的街头食品摊位供应着火辣的泰式炒面,给瓦伦留下了对这座城市充满活力的记忆。”的余弦相似度为0.8205469250679016,这是最接近的匹配。
最终里程碑:我们已经实现了RAG搜索。
企业应用
Apache Cassandra
对于企业,我们可以使用Apache Cassandra 5.0,来自Microsoft Azure、AWS、GCP等热门云供应商。
Ollama
这个中间件需要与搭载Nvidia GPU的虚拟机兼容,以运行高性能模型,但对于用于生成向量的模型,我们不需要高端虚拟机。根据流量需求,可以使用多个虚拟机,或者任何生成式人工智能服务,如Open AI、Anthropy等,根据扩展需求或数据治理需求,选择总拥有成本较低的服务。
Linux虚拟机
如果用例不需要高使用率,可以将Apache Cassandra和Ollama合并放在单个Linux虚拟机中,以降低总拥有成本或满足数据治理需求。
结论
我们可以通过使用Linux操作系统、Apache Cassandra、通过Ollama使用的嵌入模型(nomic-embed-text)和Python,轻松构建RAG应用,实现良好性能,而无需在我们的设备/服务器上额外订阅云服务或服务。
然而,建议在服务器中托管虚拟机或选择云订阅进行扩展,作为符合可伸缩架构的企业应用程序。在这种情况下,Apache、Cassandra 是执行向量存储和向量比较的关键组件,Ollama 服务器用于生成向量嵌入。
就这样了!感谢您阅读到最后。
Source:
https://dzone.com/articles/build-rag-apps-apache-cassandra-python-ollama