













数据科学家很早就开始学习SQL,这是可以理解的,因为表格信息无处不在且非常有用。然而,还有其他成功的数据库格式,例如图数据库,用于存储连接数据,这些数据不适合放入关系型SQL数据库中。在本教程中,我们将学习Neo4j,这是一个流行的图数据库管理系统,您可以使用它以Python创建、管理和查询图数据库。
图数据库是什么?
在谈论Neo4j之前,让我们花一点时间更好地了解图数据库。我们有一篇完整的文章解释什么是图数据库,所以我们在这里总结一下关键点。
图形数据库是一种NoSQL数据库(它们不使用SQL),用于管理连接数据。与使用表格和行的传统关系型数据库不同,图形数据库使用由以下组成的图结构:
- 节点(实体),例如人、地点、概念
- 边(关系)连接不同节点,如人居住于一个地方, 或足球运动员在比赛中得分。
- 属性(节点/边的属性)例如一个人的年龄,或者在比赛中进球的时间。
这种结构使得图数据库在处理相互关联的数据领域和应用(如社交网络、推荐、欺诈检测等)中理想,通常在查询效率上优于关系型数据库。以下是针对足球数据集的示例图数据库的结构:
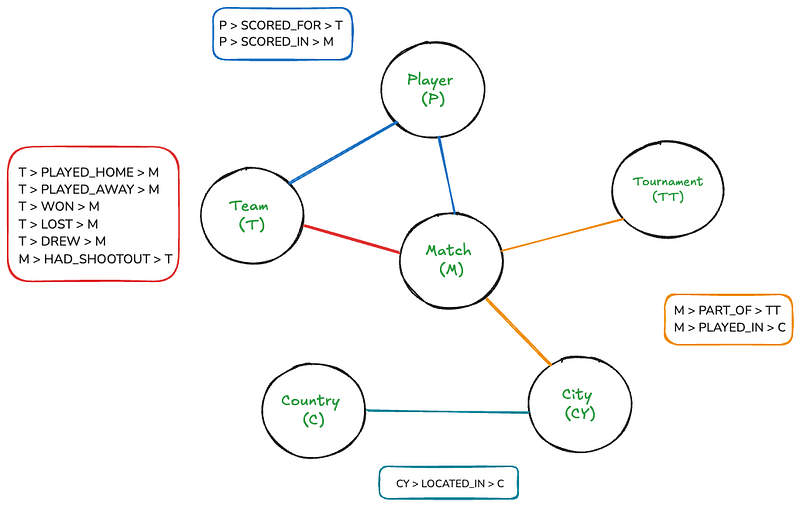
即使这个图对于人类来说相当直观,但如果在画布上绘制,它可能会变得相当复杂。但是,借助Neo4j,遍历这个图将会像编写简单的SQL连接一样简单。
这个图有六个节点:匹配、团队、锦标赛、球员、国家和城市。矩形列出了节点之间的存在关系。还有一些节点和关系的属性:
- 匹配:日期,主队得分,客队得分
- 球队:名称
- 球员:姓名
- 赛事:名称
- 城市:名称
- 国家:名称
- 得分,得分:分钟,乌龙球,点球
- 进行了点球大战:获胜者,第一射手
此架构允许我们表示:
- 所有比赛及其得分、日期和地点
- 参加每场比赛的球队(主队和客队)
- 进球的球员,包括分钟、乌龙球和点球等详细信息
- 比赛所属的赛事
- 比赛举办的城市和国家
- 射击比赛信息,包括获胜者和第一位射手(如有)
该模式捕捉了位置的层次性质(城市在国家的范围内)以及实体之间的各种关系(例如,团队在比赛中的比赛,球员为团队在比赛中的得分)。
这种结构允许灵活查询,例如查找两个团队之间的所有比赛,一名球员所踢的所有进球,或者特定锦标赛或地点内的所有比赛。
但我们不要急于求成。首先,什么是Neo4j,为什么要使用它?
什么是Neo4j?
Neo4j是图形数据库管理的领军企业,以其强大的功能和多样性而闻名。
在核心层面,Neo4j 使用原生图存储,这种存储方式针对图操作进行了高度优化。它处理复杂关系的效率使得其在连接数据方面优于传统数据库。Neo4j 的可扩展性确实令人印象深刻:它可以轻松处理数十亿个节点和关系,使其适用于从小型项目到大型企业的各种规模项目。
Neo4j 的另一个关键特性是数据完整性。它确保完全符合 ACID(原子性、一致性、隔离性、持久性)标准,为事务提供可靠性和一致性保障。
谈到事务,其查询语言 Cypher 提供了非常直观和声明式的语法,专门为图模式设计。因此,它的语法被戏称为“ASCII 艺术”。如果你熟悉 SQL,学习 Cypher 不会有任何问题。
使用Cypher,可以轻松添加新节点、关系或属性,而无需担心破坏现有查询或模式。它适应现代开发环境中不断变化的需求。
Neo4j拥有充满活力的生态系统支持。它有广泛的文档、全面的图形可视化工具、活跃的社区,以及与Python、Java和JavaScript等其他编程语言的集成。
设置Neo4j和Python环境
在我们深入使用Neo4j之前,我们需要设置我们的环境。本节将指导您创建一个云实例来托管Neo4j数据库、设置Python环境,以及建立两者之间的连接。
不安装Neo4j
如果您希望在Neo4j中使用本地的图形数据库,那么您需要 下载并安装它,以及像Java这样的依赖项。但是在大多数情况下,您将会在某个云环境中与一个现有的远程Neo4j数据库进行交互。
因此,我们不会在我们的系统上安装Neo4j。相反,我们将在Aura上创建一个免费的数据库实例,这是Neo4j的完全托管云服务。然后,我们将使用neo4j Python客户端库连接到此数据库并为其填充数据。
创建Neo4j Aura数据库实例
要免费在Aura DB上托管图形数据库,请访问 产品页面并点击“免费开始”。
注册后,您将看到可用的计划,您应该选择免费选项。然后,您将获得一个带有用户名和密码的新实例来连接到它:
复制您的密码、用户名和连接URI。
然后,创建一个新的工作目录和一个.env文件来存储您的凭据:
$ mkdir neo4j_tutorial; cd neo4j_tutorial $ touch .env
将以下内容粘贴到文件中:
NEO4J_USERNAME="YOUR-NEO4J-USERNAME" NEO4J_PASSWORD="YOUR-COPIED-NEO4J-PASSWORD" NEO4J_CONNECTION_URI="YOUR-COPIED-NEO4J-URI"
设置Python环境
现在,我们将在一个新的Conda环境中安装neo4j Python客户端库:
$ conda create -n neo4j_tutorial python=3.9 -y $ conda activate neo4j_tutorial $ pip install ipykernel # 将环境添加到Jupyter $ ipython kernel install --user --name=neo4j_tutorial $ pip install neo4j python-dotenv tqdm pandas
这些命令还会安装ipykernel库,并使用它将新创建的Conda环境作为内核添加到Jupyter中。然后,我们安装neo4j Python客户端以与Neo4j数据库交互,并python-dotenv以安全地管理我们的Neo4j凭据。
使用足球数据填充AuraDB实例
将数据吸入图数据库是一个复杂的过程,需要了解Cypher的基本原理。由于我们还没有学习Cypher的基础知识,你将使用我为文章准备的一个Python脚本,该脚本将自动吸入现实世界的足球历史数据。该脚本将使用你存储的凭据连接到你的AuraDB实例。
足球数据来源于 这个Kaggle上的国际足球比赛数据集,该数据集涵盖了从1872年到2024年之间的比赛。数据以CSV格式提供,因此脚本将其分解并使用Cypher和Neo4j将其转换为图形格式。在文章的最后部分,当我们对这些技术足够熟悉时,我们将逐行查看脚本,让您了解如何将表格信息转换为图形。
以下是运行命令(请确保您已设置AuraDB实例并将您的凭据存储在.env文件中您的 working directory):
$ wget https://raw.githubusercontent.com/BexTuychiev/medium_stories/refs/heads/master/2024/9_september/3_neo4j_python/ingest_football_data.py $ python ingest_football_data.py
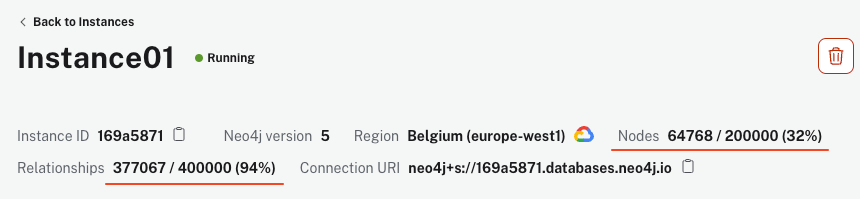
脚本可能需要几分钟才能运行,具体取决于您的机器和互联网连接。然而,一旦它完成,您的AuraDB实例必须显示超过64k节点和340k关系。
从Python连接到Neo4j
现在,我们准备连接到我们的Aura DB实例。首先,我们将从.env文件中使用dotenv读取我们的凭据:
import os from dotenv import load_dotenv load_dotenv() NEO4J_USERNAME = os.getenv("NEO4J_USERNAME") NEO4J_PASSWORD = os.getenv("NEO4J_PASSWORD") NEO4J_URI = os.getenv("NEO4J_URI")
现在,让我们建立一个连接:
from neo4j import GraphDatabase uri = NEO4J_URI username = NEO4J_USERNAME password = NEO4J_PASSWORD driver = GraphDatabase.driver(uri, auth=(username, password)) try: driver.verify_connectivity() print("Connection successful!") except Exception as e: print(f"Failed to connect to Neo4j: {e}")
输出:
Connection successful!
以下是代码解释:
- 我们从
neo4j导入了GraphDatabase,以便与Neo4j交互。 - 我们使用之前加载的环境变量来设置我们的连接(
uri,username,password)。 - 我们使用
GraphDatabase.driver()创建一个驱动对象,建立与我们的Neo4j数据库的连接。 - 在 with 块中,我们使用 verify_connectivity() 函数来检查是否建立了连接。默认情况下,如果连接成功,verify_connectivity() 函数将不返回任何内容。
教程完成后,调用driver.close()来终止连接并释放资源。驱动对象创建成本较高,因此应为您的应用程序只创建一个对象。
Cypher查询语言基础
Cypher的语法旨在直观且在视觉上代表图形结构。它依赖于以下ASCII艺术类型的语法:
(nodes)-[:CONNECT_TO]->(other_nodes)
让我们分解这个通用查询模式的关键组成部分:
1. 节点
在Cypher查询中,圆括号中的关键字表示节点名称。例如,(Player) 匹配所有的Player节点。几乎总是,节点名称通过别名来引用,以使查询更易读、更易编写且更紧凑。您可以通过在节点名称前放置一个冒号来为节点名称添加别名:(m:Match).
在圆括号内,您可以使用类似于字典的语法指定一个或多个节点属性,以进行精确匹配。例如:
// 所有FIFA世界杯的赛事节点 (t:Tournament {name: "FIFA World Cup"})
节点属性按原样编写,而您希望它们具有的值必须是一个字符串。
2. 关系
关系将节点相互连接,它们用方括号和箭头包裹:
// 匹配属于某个赛事的节点 (m:Match)-[PART_OF]->(t:Tournament)
您也可以为关系添加别名和属性:
// 匹配巴西参加了点球大战,并且是第一个射门的比赛 (p:Player) - [r:SCORED_FOR {minute: 90}] -> (t:Team)
关系用箭头包裹-[关系]->。再次,您可以在花括号内包含别名属性。例如:
// 所有得分乌龙球的球员 (p:Player)-[r:SCORED_IN {own_goal: True}]->(m:Match)
3. 子句
正如COUNT(*) FROM table_name 在 SQL 中没有SELECT 子句是不会返回任何结果的,(node) - [RELATIONSHIP] -> (node) 也不会获取任何结果。所以,就像在 SQL 中一样,Cypher 也有不同的子句来结构化您的查询逻辑,就像 SQL 一样:
MATCH:图中的模式匹配WHERE:过滤结果RETURN:指定结果集中应包含的内容CREATE:创建新节点或关系MERGE:创建唯一的节点或关系DELETE:删除节点、关系或属性SET:更新标签和属性
以下是一个演示这些概念的示例查询:
MATCH (p:Player)-[s:SCORED_IN]->(m:Match)-[PART_OF]->(t:Tournament) WHERE t.name = "FIFA World Cup" AND s.minute > 80 AND s.own_goal = True RETURN p.name AS Player, m.date AS MatchDate, s.minute AS GoalMinute ORDER BY s.minute DESC LIMIT 5
此查询找到了在世界杯比赛中80分钟后打进乌龙球的的所有球员。这几乎像SQL一样,但相应的SQL查询至少涉及一个JOIN操作。
使用Neo4j Python驱动程序分析图形数据库
使用execute_query
Neo4j Python驱动程序是官方提供的库,通过Python应用程序与Neo4j实例进行交互。它验证并将用普通Python字符串编写的Cypher查询与Neo4j服务器通信,并以统一格式检索结果。
一切都从创建一个驱动对象开始,使用GraphDatabase类。从那里,我们可以开始使用execute_query方法发送查询。
对于我们的第一个查询,让我们提出一个有趣的问题:哪支球队赢得了最多的世界杯比赛?
# 返回赢得最多世界杯比赛的球队 query = """ MATCH (t:Team)-[:WON]->(m:Match)-[:PART_OF]->(:Tournament {name: "FIFA World Cup"}) RETURN t.name AS Team, COUNT(m) AS MatchesWon ORDER BY MatchesWon DESC LIMIT 1 """ records, summary, keys = driver.execute_query(query, database_="neo4j")
首先,让我们分解这个查询:
- 以下内容为:
MATCH关闭定义了我们要的模式:队伍 -> 胜利 -> 比赛 -> 部分 -> 锦标赛 RETURN相当于 SQL 中的SELECT语句,我们可以返回返回节点的属性和关系。在这个子句中,您还可以使用 Cypher 中支持的任何聚合函数。上面,我们使用的是COUNT.- ORDER BY 子句的工作方式与SQL中的相同。
- LIMIT 用于控制返回记录的长度。
在我们将查询定义为多行字符串之后,我们将其传递给execute_query()驱动对象的方法,并指定数据库名称(默认为neo4j)。输出始终包含三个对象:
records:一个Record对象的列表,每个对象代表结果集中的一行。每个Record都是一个命名元组-like对象,您可以按名称或索引访问字段。摘要:一个包含查询执行的元数据的结果摘要对象,例如查询统计信息和时间信息。键:表示结果集中列名称的字符串列表。
我们稍后会涉及到summary对象,因为我们主要感兴趣的是记录,它们包含Record对象。我们可以通过调用它们的data()方法来获取它们的信息:
for record in records: print(record.data())
输出:
{'Team': 'Brazil', 'MatchesWon': 76}
结果显示,巴西赢得了最多的世界杯比赛。
传递查询参数
我们之前的查询不可重用,因为它只找到世界杯历史上最成功的球队。如果我们想找到欧洲历史上最成功的球队呢?
这就是查询参数的作用:
query = """ MATCH (t:Team)-[:WON]->(m:Match)-[:PART_OF]->(:Tournament {name: $tournament}) RETURN t.name AS Team, COUNT(m) AS MatchesWon ORDER BY MatchesWon DESC LIMIT $limit """
在这次查询版本中,我们使用了$符号引入了两个参数:
tournamentlimit
为了向查询参数传递值,我们在execute_query中使用关键字参数:
records, summary, keys = driver.execute_query( query, database_="neo4j", tournament="UEFA Euro", limit=3, ) for record in records: print(record.data())
输出:
{'Team': 'Germany', 'MatchesWon': 30} {'Team': 'Spain', 'MatchesWon': 28} {'Team': 'Netherlands', 'MatchesWon': 23}
始终建议在考虑将变化值引入查询时使用查询参数。这个最佳实践可以保护您的查询免受Cypher注入攻击,并允许Neo4j缓存它们。
使用CREATE和MERGE子句向数据库写入
向现有数据库写入新信息通常使用execute_query,但通过在查询中使用CREATE子句来实现。例如,我们将创建一个函数来添加一个新的节点类型 – 团队教练:
def add_new_coach(driver, coach_name, team_name, start_date, end_date): query = """ MATCH (t:Team {name: $team_name}) CREATE (c:Coach {name: $coach_name}) CREATE (c)-[r:COACHES]->(t) SET r.start_date = $start_date SET r.end_date = $end_date """ result = driver.execute_query( query, database_="neo4j", coach_name=coach_name, team_name=team_name, start_date=start_date, end_date=end_date ) summary = result.summary print(f"Added new coach: {coach_name} for existing team {team_name} starting from {start_date}") print(f"Nodes created: {summary.counters.nodes_created}") print(f"Relationships created: {summary.counters.relationships_created}")
函数add_new_coach接受五个参数:
- 驱动器:用于连接数据库的Neo4j驱动器对象。
教练名称:要添加的新教练的名称。球队名称:教练将要关联的球队名称。start_date:教练开始执教该队的日期。end_date:教练与该队任期结束的日期。
函数中的Cypher查询执行以下操作:
- 匹配一个现有团队节点,该团队节点具有给定的团队名称。
- 使用提供的教练名称创建一个新的教练节点。
- 在“教练”和“球队”节点之间创建“COACHES”关系。
- 设置
start_date和end_date属性在“COACHES”关系上。
查询使用execute_query方法执行,该方法接收一个查询字符串和一个参数字典。
执行后,函数会打印:
- 一条包含教练和球队名称以及开始日期的确认信息。
- 创建的节点数量(对于新的教练节点应该是1)。
- 创建的关系数量(对于新的
COACHES关系应该是1)。
让我们来看一下国际足球史上最成功的教练之一,莱昂内尔·斯卡洛尼,他连续赢得了三项重大国际赛事(世界杯和两次南美洲杯):
from neo4j.time import DateTime add_new_coach( driver=driver, coach_name="Lionel Scaloni", team_name="Argentina", start_date=DateTime(2018, 6, 1), end_date=None )
Output: Added new coach: Lionel Scaloni for existing team Argentina starting from 2018-06-01T00:00:00.000000000 Nodes created: 1 Relationships created: 1
在上面的代码片段中,我们正在使用DateTime类,它来自neo4j.time模块,以便将日期正确地传递到我们的Cypher查询中。 模块还包含其他有用的临时数据类型,您可能想要查看。
除了CREATE, 还有一个MERGE子句用于创建新的节点和关系。它们的主要区别是:
CREATE总是会创建新的节点/关系,可能会导致重复。合并仅在节点/关系不存在时创建它们。
例如,在稍后您将看到的数据摄取脚本中:
- 我们使用了
合并来避免团队和球员的重复。 - 我们使用自定义分隔符
CREATE来SCORED_FOR和SCORED_IN关系,因为一名球员在一场比赛中可以多次得分。 - 这些并不是真正的重复项,因为它们有不同的属性(例如,进球分钟)。
这种方法在允许存在多个相似但各不相同的关系的同时,确保了数据完整性。
运行自己的事务
当你运行execute_query时,驱动程序会在幕后创建一个事务。事务是执行工作的单元,要么完全执行,要么在失败时回滚。这意味着,当你在单个事务中创建数千个节点或关系(这是可能的)并且在中间遇到一些错误时,整个事务会失败而不会将任何新数据写入图。
为了对每个交易进行更精细的控制,您需要创建会话对象。例如,让我们创建一个函数,使用会话对象查找给定锦标赛的前K个最佳得分:
def top_goal_scorers(tx, tournament, limit): query = """ MATCH (p:Player)-[s:SCORED_IN]->(m:Match)-[PART_OF]->(t:Tournament) WHERE t.name = $tournament RETURN p.name AS Player, COUNT(s) AS Goals ORDER BY Goals DESC LIMIT $limit """ result = tx.run(query, tournament=tournament, limit=limit) return [record.data() for record in result]
首先,我们创建top_goal_scorers函数,接受三个参数,其中最重要的是tx交易对象,该对象将通过会话对象获得。
with driver.session() as session: result = session.execute_read(top_goal_scorers, "FIFA World Cup", 5) for record in result: print(record)
输出:
{'Player': 'Miroslav Klose', 'Goals': 16} {'Player': 'Ronaldo', 'Goals': 15} {'Player': 'Gerd Müller', 'Goals': 14} {'Player': 'Just Fontaine', 'Goals': 13} {'Player': 'Lionel Messi', 'Goals': 13}
然后,在用session()方法创建的上下文管理器中,我们使用execute_read(),传递top_goal_scorers()函数,以及查询所需的任何参数。
输出的execute_read是一个记录对象列表,正确显示了世界杯历史上前五名射手,包括米罗斯拉夫·克洛泽、罗纳尔多·纳萨里奥和莱昂内尔·梅西等名字。
数据摄入的execute_read()的对应方法是execute_write()。
说了这么多,现在让我们看看之前使用的摄取脚本,以了解如何使用Neo4j Python驱动程序进行数据摄取。
使用Neo4j Python驱动程序进行数据摄取
该 ingest_football_data.py 文件 从导入语句和加载必要的CSV文件开始:
import pandas as pd import neo4j from dotenv import load_dotenv import os from tqdm import tqdm import logging # CSV文件路径 results_csv_path = "https://raw.githubusercontent.com/martj42/international_results/refs/heads/master/results.csv" goalscorers_csv_path = "https://raw.githubusercontent.com/martj42/international_results/refs/heads/master/goalscorers.csv" shootouts_csv_path = "https://raw.githubusercontent.com/martj42/international_results/refs/heads/master/shootouts.csv" # 设置日志记录 logging.basicConfig(level=logging.INFO) logger = logging.getLogger(__name__) logger.info("Loading data...") # 加载数据 results_df = pd.read_csv(results_csv_path, parse_dates=["date"]) goalscorers_df = pd.read_csv(goalscorers_csv_path, parse_dates=["date"]) shootouts_df = pd.read_csv(shootouts_csv_path, parse_dates=["date"])
此代码块还设置了一个日志记录器。接下来的几行代码使用dotenv读取我的Neo4j凭据并创建一个Driver对象:
uri = os.getenv("NEO4J_URI") user = os.getenv("NEO4J_USERNAME") password = os.getenv("NEO4J_PASSWORD") try: driver = neo4j.GraphDatabase.driver(uri, auth=(user, password)) print("Connected to Neo4j instance successfully!") except Exception as e: print(f"Failed to connect to Neo4j: {e}") BATCH_SIZE = 5000
由于数据库中有超过48k个匹配项,我们定义了一个BATCH_SIZE参数以分批次导入数据。
然后,我们定义了一个名为create_indexes的函数,它接受一个会话对象:
def create_indexes(session): indexes = [ "CREATE INDEX IF NOT EXISTS FOR (t:Team) ON (t.name)", "CREATE INDEX IF NOT EXISTS FOR (m:Match) ON (m.id)", "CREATE INDEX IF NOT EXISTS FOR (p:Player) ON (p.name)", "CREATE INDEX IF NOT EXISTS FOR (t:Tournament) ON (t.name)", "CREATE INDEX IF NOT EXISTS FOR (c:City) ON (c.name)", "CREATE INDEX IF NOT EXISTS FOR (c:Country) ON (c.name)", ] for index in indexes: session.run(index) print("Indexes created.")
Cypher索引是数据库结构,可提高Neo4j中的查询性能。它们根据特定属性加快查找节点或关系的过程。我们需要它们来:
- 加快查询执行速度
- 在大数据集上提高读取性能
- 有效模式匹配
- 实施唯一约束
- 随着数据库的增长,可扩展性更好
在我们的案例中,对团队名称、比赛ID和玩家名称的索引将有助于我们在搜索特定实体或在不同节点类型之间执行连接操作时加快查询速度。为您的数据库创建此类索引是一种最佳实践。
接下来,我们有ingest_matches函数。它很大,所以让我们逐块分解:
def ingest_matches(session, df): query = """ UNWIND $batch AS row MERGE (m:Match {id: row.id}) SET m.date = date(row.date), m.home_score = row.home_score, m.away_score = row.away_score, m.neutral = row.neutral MERGE (home:Team {name: row.home_team}) MERGE (away:Team {name: row.away_team}) MERGE (t:Tournament {name: row.tournament}) MERGE (c:City {name: row.city}) MERGE (country:Country {name: row.country}) MERGE (home)-[:PLAYED_HOME]->(m) MERGE (away)-[:PLAYED_AWAY]->(m) MERGE (m)-[:PART_OF]->(t) MERGE (m)-[:PLAYED_IN]->(c) MERGE (c)-[:LOCATED_IN]->(country) WITH m, home, away, row.home_score AS hs, row.away_score AS as FOREACH(_ IN CASE WHEN hs > as THEN [1] ELSE [] END | MERGE (home)-[:WON]->(m) MERGE (away)-[:LOST]->(m) ) FOREACH(_ IN CASE WHEN hs < as THEN [1] ELSE [] END | MERGE (away)-[:WON]->(m) MERGE (home)-[:LOST]->(m) ) FOREACH(_ IN CASE WHEN hs = as THEN [1] ELSE [] END | MERGE (home)-[:DREW]->(m) MERGE (away)-[:DREW]->(m) ) """ ...
你首先会注意到的是UNWIND关键字,它用于处理一批数据。它接收$batch参数(这将是我们的DataFrame行),并遍历每一行,允许我们在单个事务中创建或更新多个节点和关系。这种方法比逐行处理更有效率,尤其是在大数据集上。
由于接下来的查询中使用了多个合并子句,所以这部分查询很熟悉。然后,我们到达了使用子句,它使用了对于每个构造以及在情况下语句。这些用于根据匹配结果有条件地创建关系。如果主队获胜,它为主队创建一个’WON’关系,为客队创建一个’LOST’关系,反之亦然。如果是平局,则两支球队都与比赛获得一个’DREW’关系。
函数的其余部分将传入的数据帧分为匹配项,并构建将传递给$batch查询参数的数据:
def ingest_matches(session, df): query = """...""" for i in tqdm(range(0, len(df), BATCH_SIZE), desc="Ingesting matches"): batch = df.iloc[i : i + BATCH_SIZE] data = [] for _, row in batch.iterrows(): match_data = { "id": f"{row['date']}_{row['home_team']}_{row['away_team']}", "date": row["date"].strftime("%Y-%m-%d"), "home_score": int(row["home_score"]), "away_score": int(row["away_score"]), "neutral": bool(row["neutral"]), "home_team": row["home_team"], "away_team": row["away_team"], "tournament": row["tournament"], "city": row["city"], "country": row["country"], } data.append(match_data) session.run(query, batch=data)
ingest_goals 和 ingest_shootouts 函数使用了类似的结构。然而,ingest_goals 有一些额外的错误和缺失值处理。
在脚本的最后,我们有main()函数,它使用会话对象执行我们的所有摄取函数:
def main(): with driver.session() as session: create_indexes(session) ingest_matches(session, results_df) ingest_goals(session, goalscorers_df) ingest_shootouts(session, shootouts_df) print("Data ingestion completed!") driver.close() if __name__ == "__main__": main()
结论和下一步
我们已经涵盖了使用Python与Neo4j图数据库工作的关键方面:
- 图数据库概念和结构
- 设置Neo4j AuraDB
- Cypher查询语言基础
- 使用Neo4j Python驱动程序
- 数据导入和查询优化
为了进一步您的Neo4j之旅,请探索这些资源:
记住,图数据库的强大之处在于表示和查询复杂的关系。继续尝试不同的数据模型,并探索高级Cypher特性。