













Введение
Машинное обучение – это подраздел искусственного интеллекта (ИИ). Основная цель машинного обучения заключается в понимании структуры данных и их вписывании в модели, которые могут быть поняты и использованы людьми.
Хотя машинное обучение является областью компьютерных наук, оно отличается от традиционных вычислительных подходов. В традиционном компьютерном подходе алгоритмы представляют собой набор явно программированных инструкций, используемых компьютерами для расчетов или решения проблем. Алгоритмы машинного обучения, напротив, позволяют компьютерам обучаться на входных данных и использовать статистический анализ для выдачи значений, попадающих в определенный диапазон. Именно поэтому машинное обучение помогает компьютерам создавать модели на основе образцов данных для автоматизации процессов принятия решений на основе входных данных.
Любой пользователь технологии сегодня извлекает пользу из машинного обучения. Технология распознавания лиц позволяет социальным медиа-платформам помогать пользователям тегировать и обмениваться фотографиями друзей. Технология оптического распознавания символов (OCR) преобразует изображения текста в подвижный тип. Рекомендательные системы, основанные на машинном обучении, предлагают, какие фильмы или телешоу посмотреть далее на основе предпочтений пользователя. Самоуправляемые автомобили, которые полагаются на машинное обучение для навигации, вскоре могут быть доступны для потребителей.
Машинное обучение – это постоянно развивающаяся область. Поэтому при работе с методиками машинного обучения или анализе влияния процессов машинного обучения необходимо учитывать некоторые аспекты.
В этом уроке мы рассмотрим общие методы машинного обучения – обучение с учителем и без учителя, а также распространенные алгоритмические подходы в машинном обучении, включая алгоритм k-ближайших соседей, обучение деревьев решений и глубокое обучение. Мы исследуем, какие языки программирования наиболее часто используются в машинном обучении, предоставляя вам некоторые положительные и отрицательные аспекты каждого из них. Кроме того, мы обсудим предвзятости, которые поддерживаются алгоритмами машинного обучения, и рассмотрим, что можно иметь в виду, чтобы предотвратить эти предвзятости при создании алгоритмов.
Методы машинного обучения
В машинном обучении задачи обычно классифицируются на широкие категории. Эти категории основаны на том, как обучение получается или как обратная связь по обучению передается разработанной системе.
Два из наиболее широко принятых методов машинного обучения – это обучение с учителем, которое обучает алгоритмы на основе примеров входных и выходных данных, размеченных людьми, и обучение без учителя, которое предоставляет алгоритму не размеченные данные, чтобы он мог находить структуру в своих входных данных. Давайте рассмотрим эти методы подробнее.
Обучение с учителем
В обучении с учителем компьютер получает примеры входных данных, помеченных своими желаемыми выходными данными. Цель этого метода заключается в том, чтобы алгоритм мог “учиться”, сравнивая свой фактический вывод с “преподаваемыми” выводами, чтобы находить ошибки и соответствующим образом модифицировать модель. Обучение с учителем использует образцы для прогнозирования значений меток на дополнительных немаркированных данных.
Например, в обучении с учителем алгоритму могут быть предоставлены данные с изображениями акул, помеченными как рыба, и изображениями океанов, помеченными как вода. Будучи обученным на этих данных, алгоритм обучения с учителем впоследствии должен быть способен определять немаркированные изображения акул как рыба и немаркированные изображения океанов как вода.
A common use case of supervised learning is to use historical data to predict statistically likely future events. It may use historical stock market information to anticipate upcoming fluctuations, or be employed to filter out spam emails. In supervised learning, tagged photos of dogs can be used as input data to classify untagged photos of dogs.
Обучение без учителя
В обучении без учителя данные не помечены, поэтому алгоритм обучения остается находить общие черты среди своих входных данных. Поскольку немаркированные данные более распространены, чем маркированные данные, методы машинного обучения, которые облегчают обучение без учителя, особенно ценны.
Целью неконтролируемого обучения может быть как обнаружение скрытых шаблонов в наборе данных, так и изучение характеристик, позволяющее вычислительной машине автоматически находить представления, необходимые для классификации исходных данных.
Неконтролируемое обучение обычно используется для транзакционных данных. У вас может быть большой набор данных о клиентах и их покупках, но вероятно, как человеку, вам будет трудно понять, какие сходные атрибуты можно выделить из профилей клиентов и их типов покупок. Подав этот набор данных на вход алгоритму неконтролируемого обучения, можно определить, что женщины определенного возрастного диапазона, покупающие непахучие мыла, вероятно, беременны, и, следовательно, рекламную кампанию, связанную с беременностью и товарами для младенцев, можно нацелить на эту аудиторию, чтобы увеличить количество их покупок.
Без сообщения о “правильном” ответе методы неконтролируемого обучения могут анализировать сложные данные, которые более обширны и кажутся несвязанными, чтобы организовать их потенциально осмысленным образом. Неконтролируемое обучение часто используется для выявления аномалий, включая мошеннические покупки с кредитных карт, и рекомендательных систем, которые рекомендуют, какие продукты покупать дальше. В неконтролируемом обучении немаркированные фотографии собак могут быть использованы в качестве входных данных для алгоритма, чтобы найти сходства и классифицировать фотографии собак вместе.
Подходы
Как область, машинное обучение тесно связано с вычислительной статистикой, поэтому знание статистики полезно для понимания и использования алгоритмов машинного обучения.
Для тех, кто не изучал статистику, может быть полезно сначала определить корреляцию и регрессию, так как они являются общепринятыми методами исследования отношений между количественными переменными. Корреляция – это мера ассоциации между двумя переменными, которые не определены как зависимые или независимые. Регрессия на базовом уровне используется для изучения отношений между одной зависимой и одной независимой переменной. Поскольку статистика регрессии может использоваться для предсказания зависимой переменной, когда известна независимая переменная, регрессия обеспечивает возможности прогнозирования.
Подходы к машинному обучению постоянно развиваются. Для наших целей мы рассмотрим несколько популярных подходов, которые используются в машинном обучении на момент написания этого текста.
k-nearest neighbor
Алгоритм k-ближайших соседей – это модель распознавания образов, которая может использоваться как для классификации, так и для регрессии. Часто сокращается как k-NN, k в алгоритме k-ближайших соседей – это положительное целое число, которое обычно небольшое. В случае классификации или регрессии ввод будет состоять из k ближайших примеров из обучающего набора в пространстве.
Мы сосредоточимся на классификации методом k-ближайших соседей. В этом методе выводом является принадлежность классу. Это присвоит новый объект классу, наиболее распространенному среди его k ближайших соседей. В случае k = 1 объект присваивается классу одного ближайшего соседа.
Давайте рассмотрим пример k-ближайших соседей. На диаграмме ниже изображены синие алмазные объекты и оранжевые звездные объекты. Они принадлежат к двум разным классам: классу алмазов и классу звезд.

Когда в пространство добавляется новый объект — в данном случае зеленое сердце — мы хотим, чтобы алгоритм машинного обучения классифицировал сердце в определенный класс.

Когда мы выбираем k = 3, алгоритм найдет три ближайших соседа зеленого сердца, чтобы классифицировать его либо как класс алмазов, либо как класс звезд.
На нашей диаграмме три ближайших соседа зеленого сердца — один алмаз и две звезды. Поэтому алгоритм классифицирует сердце как класс звезд.
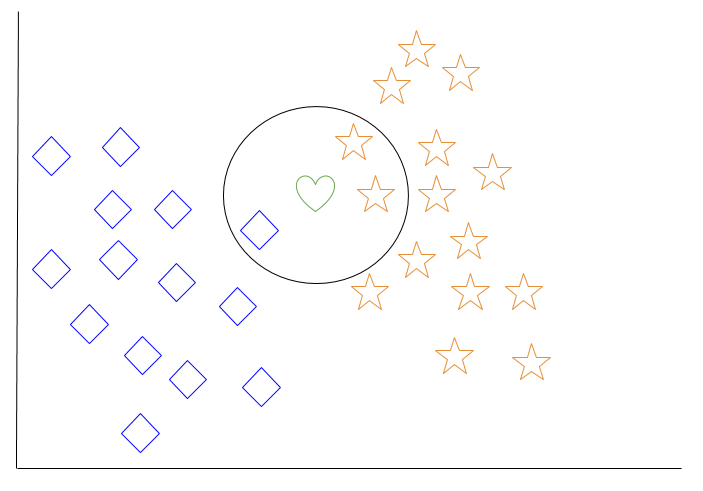
Среди самых базовых алгоритмов машинного обучения k-ближайшие соседи считаются типом “ленивого обучения”, так как обобщение за пределами обучающих данных не происходит до тех пор, пока не будет сделан запрос к системе.
Обучение решающих деревьев
Для общего использования решающие деревья используются для визуального представления решений и показа или информирования о принятии решений. При работе с машинным обучением и добычей данных решающие деревья используются в качестве прогностической модели. Эти модели сопоставляют наблюдения о данных с выводами о целевом значении данных.
Цель обучения решающих деревьев состоит в создании модели, которая будет предсказывать значение целевой переменной на основе входных переменных.
В прогностической модели атрибуты данных, которые определяются через наблюдение, представлены ветвями, в то время как выводы о целевом значении данных представлены в листьях.
При “обучении” дерева исходные данные разделяются на подмножества на основе теста значения атрибута, который повторяется для каждого полученного подмножества рекурсивно. Как только подмножество узла имеет эквивалентное значение своего целевого значения, процесс рекурсии завершается.
Давайте рассмотрим пример различных условий, которые могут определять, должен ли кто-то идти на рыбалку. Сюда входят погодные условия, а также атмосферное давление.
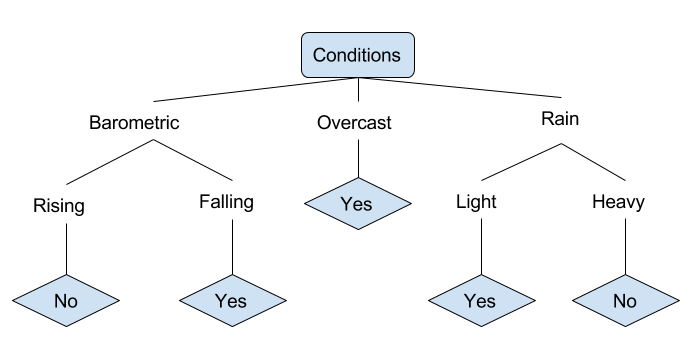
В упрощенном дереве принятия решений выше пример классифицируется путем сортировки через дерево к соответствующему листу. Затем возвращается классификация, связанная с конкретным листом, который в данном случае может быть либо Да, либо Нет. Дерево классифицирует условия дня на основе того, подходит ли он для рыбалки.
A true classification tree data set would have a lot more features than what is outlined above, but relationships should be straightforward to determine. When working with decision tree learning, several determinations need to be made, including what features to choose, what conditions to use for splitting, and understanding when the decision tree has reached a clear ending.
Глубокое обучение
Глубокое обучение пытается имитировать то, как человеческий мозг может преобразовывать свет и звук в видение и слух. Архитектура глубокого обучения вдохновлена биологическими нейронными сетями и состоит из нескольких слоев в искусственной нейронной сети, состоящей из аппаратного обеспечения и графических процессоров.
Глубокое обучение использует каскад нелинейных слоев обработки, чтобы извлечь или преобразовать признаки (или представления) данных. Выход одного слоя служит входом последующего слоя. В глубоком обучении алгоритмы могут быть как надзорными и служить для классификации данных, так и ненадзорными и выполнять анализ шаблонов.
Среди алгоритмов машинного обучения, которые в настоящее время используются и разрабатываются, глубокое обучение поглощает больше всего данных и способно превзойти человека в некоторых когнитивных задачах. Именно благодаря этим свойствам глубокое обучение стало подходом с значительным потенциалом в области искусственного интеллекта
Компьютерное зрение и распознавание речи оба достигли значительных успехов благодаря подходам глубокого обучения. IBM Watson – хороший пример системы, использующей глубокое обучение.
Языки программирования
При выборе языка для специализации в области машинного обучения можно обратить внимание на навыки, перечисленные в текущих объявлениях о вакансиях, а также на библиотеки, доступные на разных языках и используемые для процессов машинного обучения.
Python – один из самых популярных языков для работы с машинным обучением благодаря множеству доступных фреймворков, включая TensorFlow, PyTorch и Keras. Как язык с читаемым синтаксисом и возможностью использования в качестве скриптового языка, Python оказывается мощным и простым в использовании как для предварительной обработки данных, так и для работы с данными напрямую. Библиотека машинного обучения scikit-learn построена на основе нескольких существующих пакетов Python, с которыми разработчики Python могут уже быть знакомы, а именно NumPy, SciPy и Matplotlib.
Для начала работы с Python вы можете прочитать нашу серию учебных пособий о “Как программировать на Python 3”, или прочитать специфически о “Как создать классификатор машинного обучения на Python с помощью scikit-learn” или “Как выполнить перенос стиля нейросетью с использованием Python 3 и PyTorch”.
Java широко используется в корпоративном программировании и обычно применяется разработчиками настольных приложений, которые также занимаются машинным обучением на корпоративном уровне. Обычно это не первый выбор для новичков в программировании, которые хотят изучить машинное обучение, но предпочтителен для тех, кто имеет опыт разработки на Java и хочет применить его к машинному обучению. В отрасли применения машинного обучения Java обычно используется чаще, чем Python, для сетевой безопасности, включая случаи использования в обнаружении кибератак и мошенничества.
Среди библиотек машинного обучения для Java можно выделить Deeplearning4j, открытую и распределенную библиотеку глубокого обучения, написанную как на Java, так и на Scala; MALLET (MAchine Learning for LanguagE Toolkit), которая позволяет создавать приложения машинного обучения для работы с текстом, включая обработку естественного языка, моделирование тем, классификацию документов и кластеризацию; и Weka, коллекцию алгоритмов машинного обучения для выполнения задач по добыче данных.
C++ is the language of choice for machine learning and artificial intelligence in game or robot applications (including robot locomotion). Embedded computing hardware developers and electronics engineers are more likely to favor C++ or C in machine learning applications due to their proficiency and level of control in the language. Some machine learning libraries you can use with C++ include the scalable mlpack, Dlib offering wide-ranging machine learning algorithms, and the modular and open-source Shark.
Человеческие предвзятости
Хотя анализ данных и вычислительный анализ могут заставить нас думать, что мы получаем объективную информацию, это не так; то, что основано на данных, не означает, что результаты машинного обучения являются нейтральными. Человеческий предвзятый взгляд играет роль в том, как данные собираются, организуются и в конечном итоге в алгоритмах, которые определяют, как машинное обучение будет взаимодействовать с этими данными.
Например, если люди предоставляют изображения для “рыбы” в качестве данных для обучения алгоритма, и эти люди в основном выбирают изображения золотых рыбок, компьютер может не классифицировать акулу как рыбу. Это создаст предвзятость против акул как рыбы, и акулы не будут учитываться как рыба.
При использовании исторических фотографий ученых в качестве обучающих данных компьютер может неправильно классифицировать ученых, которые также являются представителями цветной расы или женщинами. Фактически, недавние исследования, опубликованные в рецензируемых журналах, указывают на то, что программы искусственного интеллекта и машинного обучения проявляют человекоподобные предвзятости, включая расовые и гендерные предрассудки. См., например, “Semantics derived automatically from language corpora contain human-like biases” и “Men Also Like Shopping: Reducing Gender Bias Amplification using Corpus-level Constraints” [PDF].
Поскольку машинное обучение все чаще используется в бизнесе, непойманные предвзятости могут поддерживать системные проблемы, которые могут помешать людям получить кредиты, быть показанными рекламой высокооплачиваемых рабочих мест или получить варианты доставки в тот же день.
Поскольку человеческий предвзятый взгляд может негативно сказаться на других, крайне важно быть осведомленным об этом и также работать над его устранением насколько это возможно. Один из способов достижения этого – обеспечение участия разнообразных людей в проекте и тестирование и проверка его разнообразными лицами. Другие призывают к независимым регулирующим органам, контролирующим и аудиторским проверкам алгоритмов, разработке альтернативных систем, способных выявлять предвзятости и этическим обзорам в рамках планирования проектов по науке о данных. Повышение осведомленности о предвзятости, осознание наших собственных неосознанных предвзятых взглядов и структурирование равенства в наших проектах и трубопроводах машинного обучения могут способствовать борьбе с предвзятостью в этой области.

Заключение
В этом обзоре были рассмотрены некоторые случаи использования машинного обучения, общие методы и популярные подходы в этой области, подходящие языки программирования для машинного обучения, а также охвачены некоторые моменты, которые следует иметь в виду в отношении неосознанных предвзятых взглядов, воспроизводимых в алгоритмах.
Поскольку машинное обучение – это область, которая продолжает развиваться, важно помнить, что алгоритмы, методы и подходы будут продолжать меняться.
Кроме того, читайте наши учебники о «Как построить классификатор машинного обучения на Python с помощью scikit-learn» или «Как выполнить перенос стиля нейронов с помощью Python 3 и PyTorch», вы можете узнать больше о работе с данными в индустрии технологий, прочитав наши учебники по анализу данных.
Source:
https://www.digitalocean.com/community/tutorials/an-introduction-to-machine-learning