













הקדמה
למידת מכונה היא תת־תחום של הבינה המלאכותית (AI). המטרה הכללית של למידת מכונה היא להבין את מבנה הנתונים ולהתאים אותם לתבניות שניתן להבין ולהשתמש בהן על ידי אנשים.
אף על פי שלמידת מכונה היא תחום בתוך מדעי המחשב, היא שונה מגישות חישוביות מסורתיות. בחישובים מסורתיים, אלגוריתמים הם קבוצות של הוראות שתכנתו באופן מפורש ושמשויות על ידי מחשבים כדי לחשב או לפתור בעיות. בניגוד לכך, אלגוריתמי למידת מכונה מאפשרים למחשבים להתאמן על קלטי נתונים ולהשתמש בניתוח סטטיסטי כדי ליצור ערכים הנמצאים בטווח מסוים. כתוצאה מכך, למידת מכונה מסייעת למחשבים לבנות מודלים מנתוני דוגמה כדי לאוטומטז תהליכי קבלת החלטות בהתבסס על קלטי נתונים.
כל משתמש בטכנולוגיה היום נהנה מלמידת מכונה. טכנולוגיית זיהוי פנים מאפשרת לפלטפורמות רשת חברתית לעזור למשתמשים לתייג ולשתף תמונות של חברים. טכנולוגיית זיהוי תווים אופטיים (OCR) ממירה תמונות של טקסט לסוג נייד. מנועי המלצה, המופעלים על ידי למידת מכונה, ממליצים על סרטים או תוכניות טלוויזיה לצפות בהם לפי העדפות המשתמש. רכבים עצמאיים המתבססים על למידת מכונה כדי לנווט עשויים להיות זמינים בקרוב לצרכנים.
למידת מכונה היא תחום המתפתח באופן רציף. עקב כך, ישנם מספר שיקולים לשמור עליהם בעת עבודה עם מתודולוגיות למידת מכונה או ניתוח השפעת תהליכי למידת מכונה.
במדריך זה, נבחן את השיטות הנפוצות ביותר למידת מכונה, כולל למידה מלווה ולמידה בלתי מלווה, וגישות אלגוריתמיות נפוצות בלמידת מכונה, כולל אלגוריתם השכנים הקרובים, למידת עץ ההחלטות ולמידה עמוקה. נבחן אילו שפות תכנות נפוצות ביותר בלמידת מכונה, ונספק כמה מהיתרונות והחסרונות של כל אחת. בנוסף, נדון בגיזום שמתרחש על ידי אלגוריתמי למידת מכונה, ונשקול מה יש לשמור על דעת כדי למנוע את הגיזום הזה בעת בניית האלגוריתמים.
שיטות למידת מכונה
בלמידת מכונה, המשימות מסווגות בדרך כלל לקטגוריות רחבות. הקטגוריות הללו מבוססות על אופן הלמידה או על כיצד מועבר משוב על הלמידה למערכת שפותחה.
שתי השיטות למידת מכונה הנפוצות ביותר הן למידה מלווה שמדרבנת אלגוריתמים על פי דוגמאות קלט ופלט שמתוייגו על ידי בני אדם, ולמידה בלתי מלווה המספקת לאלגוריתם נתונים לא מתוייגים כדי לאפשר לו למצוא מבנה בתוך הנתונים שלו. בואו נחקור את השיטות הללו במעמקים נוספים.
למידת מורה
בלמידת מורה, המחשב מקבל קלטים לדוגמה שמתווים עם הפלטים הרצויים שלהם. מטרת השיטה היא שהאלגוריתם יוכל "ללמוד" על ידי השוואת הפלט האמיתי שלו עם הפלטים "המלמדים" כדי למצוא שגיאות ולשנות את המודל בהתאם. לכן, בלמידת מורה משתמשים בתבניות כדי לנבא ערכי תוויות על נתונים לא מתויגים נוספים.
לדוגמה, בלמידת מורה, אלגוריתם יכול לקבל נתונים עם תמונות של כרישים המתווים כ- דג ותמונות של ימים המתווים כ- מים. בעזרת האימון על נתונים אלה, על אלגוריתם למידת מורה לזהות בהמשך תמונות של כרישים ללא תוויות כ- דג ותמונות של ימים ללא תוויות כ- מים.
A common use case of supervised learning is to use historical data to predict statistically likely future events. It may use historical stock market information to anticipate upcoming fluctuations, or be employed to filter out spam emails. In supervised learning, tagged photos of dogs can be used as input data to classify untagged photos of dogs.
למידה בלתי מורה
בלמידה בלתי מורה, הנתונים אינם מתוייגים, כך שהאלגוריתם למידה נשאר למצוא משותפים בין הנתונים שלו. מאחר שנתונים לא מתוייגים יותר רבים מנתונים מתוייגים, שיטות למידה שמקלות על למידה בלתי מורה הן על סף יקרה מאוד.
המטרה של למידה לא מפוקחת עשויה להיות פשוטה כגון גילוי דפוסים נסתרים בתוך קבוצת נתונים, אך גם עשויה להיות מטרת למידת מאפיינים, שמאפשרת למכונה החישובית לגלות באופן אוטומטי את הייצוגים הדרושים לסווג של נתונים גולמיים.
למידה לא מפוקחת נהוגה לנתונים טרנזקציונליים. יתכן ויש לך קובץ נתונים גדול של לקוחות וקניותיהם, אך כבנאדם כנראה שלא תהיה מסוגל להבין אילו מאפיינים דומים ניתן להפיק מפרופילים של לקוחות וסוגי הרכישות שלהם. עם הנתונים הללו מוזנים לאלגוריתם למידה לא מפוקחת, ניתן לקבוע כי נשים בטווח גילאים מסוים שרוכשות סבונים ללא ריח סביר שהן בהריון, ולכן ניתן לכוון קמפיין שיווקי הקשור להריון ולמוצרים לתינוקות לקהל זה כדי להגדיל את מספר הרכישות שלהם.
בלי לקבל "תשובה" נכונה, שיטות למידה לא מפוקחת יכולות להביט על נתונים מורכבים שהם יותר רחבי תיאור ונראים כלא קשורים בכדי לארגן אותם בדרכים אולי משמעותיות. למידה לא מפוקחת נהוגת לזיהוי חריגים כולל לרכישות מותרות בכרטיסי אשראי מזויפים, ולמערכות הממליצות על מה לקנות למשך. בלמידה לא מפוקחת, תמונות ללא תוויות של כלבים יכולות לשמש כנתוני קלט לאלגוריתם למציאת הדמויות ולסווג תמונות של כלבים ביחד.
שיטות
כשדוברים על שדה מדעי המחשב, למידת מכונה קשורה בקרבה לסטטיסטיקה חישובית, לכן ידע בסטטיסטיקה מועיל להבנת ולניצול של אלגוריתמי למידת מכונה.
עבור אלה שלא למדו סטטיסטיקה, יכול להיות מועיל להגדיר תחילה את הקשר וההתאמה, שכן הם טכניקות נפוצות לחקר היחסים בין משתנים כמותיים. הקשר הוא מדידת הקשר בין שני משתנים שאינם נקבעים כאשר תלויים או עצמאיים. התאמה ברמה בסיסית משמשת לבחינת היחס בין משתנה תלוי ומשתנה עצמאי אחד. מאחר וניתן להשתמש בסטטיסטיקת תאמה כדי לצפות את המשתנה התלוי כאשר המשתנה העצמאי ידוע, תאמה מאפשרת יכולות חיזוי.
גישות למידת מכונה נמצאות בפיתוח רצף. לצורך העניין שלנו, נתמקד בכמה מהגישות הפופולריות שמשמשות בלמידת מכונה בעת הכתיבה.
k-nearest neighbor
אלגוריתם השכנים הקרובים ביותר הוא דוגמה לדפוס המודל המכירתי שיכול לשמש לסיווג וגם לתחזית. בדרך כלל מקוצר כ k-NN, ה-k בקרובים הקרובים ביותר הוא מספר שלם חיובי, המועט כלל. בסיומת או בתחזית, הקלט יהיה הדוגמאות האימון הקרובות ביותר בתוך מרחב.
נתמקד בסיווג k-NN. בשיטה זו, הפלט הוא חברות במחלקה. זה יקצה אובייקט חדש למחלקה הנפוצה ביותר בין k השכנים הקרובים ביותר שלו. במקרה של k = 1, האובייקט יוקצה למחלקת השכנה היחידה ביותר.
בואו נסתכל על דוגמה של שכן הקרובים הכי קרובים. בתרשים למטה, ישנם אובייקטים בצורת יהלומים כחולים ואובייקטים בצורת כוכבים כתומים. אלה שייכים לשני מחלקות נפרדות: מחלקת היהלום ומחלקת הכוכב.

כאשר אובייקט חדש מתווסף למרחב — במקרה זה לב ירוק — אנו רוצים שאלגוריתם למידת המכונה יסווג את הלב לאחת המחלקות.

כאשר בוחרים k = 3, האלגוריתם ימצא את שלושת השכנים הקרובים ביותר של הלב הירוק כדי לסווג אותו או למחלקת היהלום או למחלקת הכוכב.
בתרשימים שלנו, שלושת השכנים הקרובים ביותר של הלב הירוק הם יהלום אחד ושני כוכבים. לכן, האלגוריתם יסווג את הלב למחלקת הכוכב.
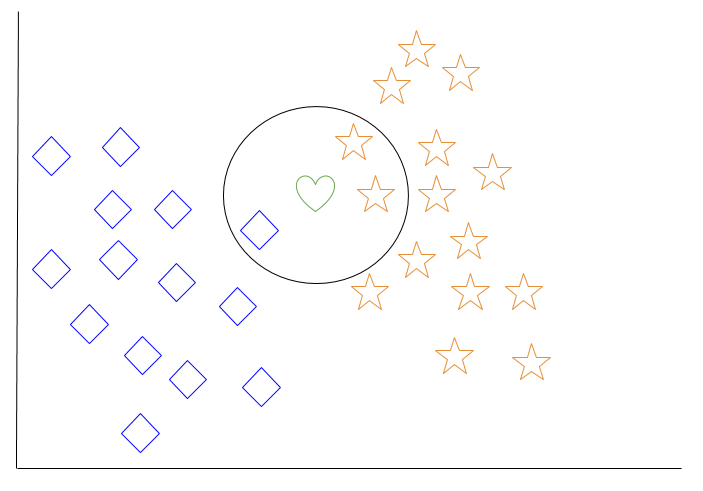
בין האלגוריתמים למידת המכונה הבסיסיים ביותר, שכן הקרובים הכי קרובים נחשב להיות סוג של "למידה עצלה", מאחר והכללה מעבר לנתוני האימון אינה קורה עד ששאילתה מתבצעת למערכת.
למידת עץ ההחלטות
לשימוש כללי, עצי ההחלטות משמשים לייצוג חזוני של החלטות ולהצגתן או להודיע על קבלת החלטות. כאשר מתעסקים בלמידת מכונה ובכריית נתונים, עצי ההחלטות משמשים כמודל תחזית. מודלים אלו מטרתם למפות תפקידים בנתונים למסקנות בנוגע לערכי היעד של הנתונים.
מטרת למידת עץ ההחלטות היא ליצור מודל שיתחזן את ערך היעד על סמך המשתנים הקלט.
במודל החיזוי, תכונות הנתונים שנקבעות דרך תצפית מיוצגות על ידי הענפים, בעוד שהמסקנות על ערך המטרה של הנתונים מיוצגות בעלים.
בעת "למידת" עץ, הנתונים ממקור מחולקים לתתי-סטים על פי בדיקת ערך תכונה, שמתבצעת מחדש על כל אחד מהתת-סטים שנוצרו. פעם אחת שהתת-סט בצומת מכיל ערך שזהה לערך המטרה שלו, התהליך הרקורסיבי יהיה מושלם.
בואו נסתכל על דוגמה של תנאים שונים שיכולים לקבוע האם מישהו צריך ללכת לדוגינג. זה כולל תנאי מזג אוויר וגם תנאי לחץ אטמוספרי.
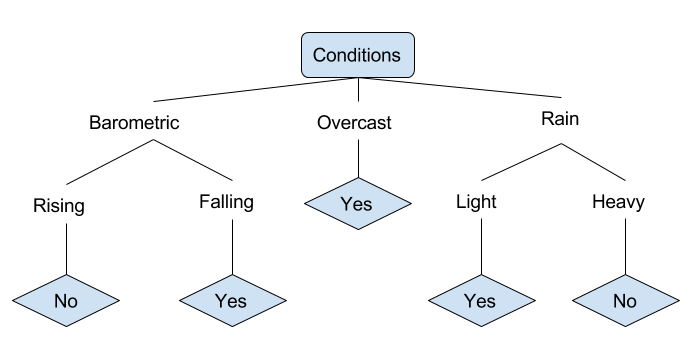
בעץ החלטות הפשוט שמופיע למעלה, דוגמה מסוימת מסויימת מסוירת על ידי מיון אותה דרך העץ אל צומת העלים המתאים. מכאן מתבצעת הסיווג הקשור בצומת המסוים, שבמקרה זה הוא או "כן" או "לא". העץ סוגר ימים בהתבסס על כך האם התנאים מתאימים לדוגינג או לא.
A true classification tree data set would have a lot more features than what is outlined above, but relationships should be straightforward to determine. When working with decision tree learning, several determinations need to be made, including what features to choose, what conditions to use for splitting, and understanding when the decision tree has reached a clear ending.
למידה עמוקה
הלמידה העמוקה מנסה לחקות איך שער המוח האנושי יכול לעבד עצמים קלים ומתח צלילים לתמונה ולשמיעה. ארכיטקטורת למידה עמוקה מושפעת מרשתות עצביות ביולוגיות ומורכבת ממספר שכבות ברשת עצבים מלאכותית המורכבת מחומרה ו-GPUs.
שיטת הלמידה העמוקה משתמשת בצורת צפיפות של שכבות יחידות עיבוד לא לינארי בכדי לייצר או להמיר תכונות (או ייצוגים) של הנתונים. פלט של שכבה אחת משמש כקלט של השכבה העוקבת. בלמידה עמוקה, האלגוריתמים יכולים להיות או על ידי הוראה ולשרת לסיווג נתונים, או על ידי למידה לא מופנית וביצוע ניתוח דפוסים.
בין האלגוריתמים למידת מכונה המשמשים כיום ומפותחים, למידת עמוקה סופגת את רוב הנתונים והצליחה לפרוץ את גבולות הבינה המלאכותית במשימות מסוימות של קוגניציה. בגלל התכונות הללו, למידה עמוקה הפכה לגישה עם פוטנציאל רב בתחום הבינה המלאכותית
תחום ראיית המחשב וזיהוי הדיבור הביאו שני מתקדמים חשובים מגישות למידת עמוקה. IBM Watson הוא דוגמה מוכרת למערכת שמנצלת למידה עמוקה.
שפות תכנות
בעת בחירת שפה להתמחות בלמידת מכונה, כדאי לשקול את הכישורים המפורטים במודעות עבודה נוכחית וגם את הספריות הזמינות בשפות שונות שניתן להשתמש בהן לתהליכי למידת מכונה.
פייתון היא אחת מהשפות הפופולריות ביותר לעבוד עם למידת מכונה בגלל המספר הרב של מסגרות זמינות, כולל TensorFlow, PyTorch, ו־Keras. כשפה שיש בה תחביר קריא ויכולת לשמש כשפת סקריפט, פייתון מוכיחה להיות עוצמתית וישירה גם בשביל עיבוד נתונים ועבודה ישירה עם נתונים. ספריית למידת המכונה scikit-learn מבוססת על מספר חבילות פייתון קיימות שפיתחנים בפייתון כבר עשויים להכיר, בעיקר NumPy, SciPy, ו־Matplotlib.
כדי להתחיל עם פייתון, אפשר לקרוא את סדרת המדריכים שלנו על "כיצד לתכנת בפייתון 3", או לקרוא באופן מפורט על "כיצד לבנות מחלקה למידת מכונה בפייתון עם scikit-learn" או "כיצד לבצע העברת סגנון עם נוירונים בפייתון 3 ו־PyTorch".
Java נמצאת בשימוש נרחב בתכנות עסקי, ובדרך כלל משמשת על ידי מפתחי אפליקציות משולבות לשולחן עבודה העוסקים גם בלמידת מכונה ברמה העסקית. בדרך כלל אינה הבחירה הראשונה עבור מתחילים בתכנות שרוצים ללמוד על למידת מכונה, אך מועדפת על ידי אלה עם רקע בפיתוח ב-Java ליישום בלמידת מכונה. בנוגע ליישומי למידת מכונה בתעשייה, נכון להשתמש ב-Java יותר מ-Python לביטחון רשת, כולל במקרים של התקפות סייבר וזיהוי הונאות.
בין הספריות ללמידת מכונה ב-Java ניתן למנות Deeplearning4j, ספריית למידת עמוק שמתפשטת וכתובה לכל מה שנוגע ל-Java ול-Scala; MALLET (MAכינה Lמידת Lשפה Eכלי T) מאפשרת ליישומי למידת מכונה על טקסט, כולל עיבוד שפה טבעית, דגימת נושאים, סיווג מסמכים וקיבוץ; ו־Weka, אוסף של אלגוריתמי למידת מכונה לשימוש במשימות של כריית נתונים.
C++ is the language of choice for machine learning and artificial intelligence in game or robot applications (including robot locomotion). Embedded computing hardware developers and electronics engineers are more likely to favor C++ or C in machine learning applications due to their proficiency and level of control in the language. Some machine learning libraries you can use with C++ include the scalable mlpack, Dlib offering wide-ranging machine learning algorithms, and the modular and open-source Shark.
עיוותים אנושיים
אף על פי שנתונים וניתוח חישובי עשויים להטיל עלינו את ההרגשה שאנו מקבלים מידע אובייקטיבי, זה אינו המצב; בהתבסס על נתונים אין להכיר בכך שפלטי למידת מכונה הם נייטרליים. הדעות האנושיות משפיעות על אופן איסוף הנתונים, ארגון שלהם, ולבסוף על האלגוריתמים שמקבעים איך למידת המכונה תידורגן עם הנתונים אלו.
לדוגמה, אם אנשים מספקים תמונות עבור "דגים" כנתונים לאימון אלגוריתם, ואנשים אלו באופן בלעדי בוחרים תמונות של דגי זהב, מחשב עשוי שלא לסווג כרעייה כדג. זה ייצור הטיות נגד כרעיות כדגים, וכרעיות ייחשבו כדגים.
כאשר משתמשים בתמונות היסטוריות של מדענים כנתוני הדרכה, מחשב עשוי שלא לסווג כרעייה בצורה נכונה למדענים שגם הם אנשים צבעוניים או נשים. למעשה, מחקר חברתי אחרון הראה כי תוכניות AI ולמידת מכונה מציגות הטיות דומות לאנושיות הכוללות הטיות גזעניות ומגדריות. ראה, לדוגמה "הבניות המופקות אוטומטית מקורפוסים שפתיים מכילות הטיות דומות לאנושיות" ו"גברים גם אוהבים קניות: הפחתת ההגברה של הטיות מגדר באמצעות הגבלות ברמת קורפוס" [PDF].
כשלמידת מכונה משמשת בגדילה בעסקים, הטיות שאינן מזוהות יכולות להפיץ בעיות מערכתיות שעשויות למנוע מאנשים להתאים להלוואות, להוצג בפניהם מודעות להזדמנויות עבודה בתשלום גבוה, או לקבל אפשרויות משלוח באותו היום.
מכיוון שההטיות האנושיות עשויות להשפיע באופן שלילי על אחרים, חשוב מאוד להיות מודעים לכך וגם לעבוד למניעתה ככל הניתן. דרך אחת לעבוד למען השגת זה על ידי ודאות שישנם אנשים מגוונים העובדים על פרויקט וכן ודאות שאנשים מגוונים מבחינים את הפרויקט ומבצעים בו בדיקות. אחרים קראו לקיומו של צדדים שלישיים מסדרתיים המנטרים ומבקרים אלגוריתמים, לבניית מערכות אלטרנטיביות המזהות פגיעות, ולביצוע בדיקות אתיות כחלק מתכנון פרויקטי מדע הנתונים. להגביר את המודעות לפגיעות, להיות מתבוננים בהטיות הבלתי מודעות שלנו, ולבנות שוויון בפרויקטי ובצינורות למידת מכונה שלנו יכולים לעבוד למען הבלימה של ההטיות בתחום זה.

מסקנה
המדריך הזה ביקש על חלק מהמקרים השימושיים של למידת מכונה, שיטות נפוצות וגישות פופולריות המשמשות בתחום, שפות תכנות מתאימות ללמידת מכונה, וגם עיסוק במקורות לתשומת הלב במובני הטיות בלתי מודעות המשוכפלות באלגוריתמים.
מכיוון שלמידת מכונה היא תחום שמשתנה באופן רציף, חשוב לשים לב כי אלגוריתמים, שיטות וגישות ימשיכו להשתנות.
איך לבנות ממחשב תיאום למידת מכונה בפייתון עם scikit-learn או איך לבצע העברת סגנון עם Python 3 ו־PyTorch ", תוכל ללמוד עוד על עבודה עם נתונים בתעשיית הטכנולוגיה על ידי קריאת המדריכים שלנו בנושא ניתוח נתונים.
Source:
https://www.digitalocean.com/community/tutorials/an-introduction-to-machine-learning