













Introducción
El aprendizaje automático es un subcampo de la inteligencia artificial (IA). El objetivo del aprendizaje automático en general es entender la estructura de los datos y ajustar esos datos en modelos que puedan ser comprendidos y utilizados por las personas.
Aunque el aprendizaje automático es un campo dentro de la ciencia de la computación, difiere de los enfoques computacionales tradicionales. En la informática tradicional, los algoritmos son conjuntos de instrucciones explícitamente programadas utilizadas por las computadoras para calcular o resolver problemas. En cambio, los algoritmos de aprendizaje automático permiten que las computadoras se entrenen en entradas de datos y utilicen análisis estadístico para producir valores que caen dentro de un rango específico. Debido a esto, el aprendizaje automático facilita a las computadoras construir modelos a partir de datos de muestra para automatizar procesos de toma de decisiones basados en entradas de datos.
Cualquier usuario de tecnología hoy en día se ha beneficiado del aprendizaje automático. La tecnología de reconocimiento facial permite a las plataformas de redes sociales ayudar a los usuarios a etiquetar y compartir fotos de amigos. La tecnología de reconocimiento óptico de caracteres (OCR) convierte imágenes de texto en tipo móvil. Los motores de recomendación, impulsados por el aprendizaje automático, sugieren qué películas o programas de televisión ver a continuación según las preferencias del usuario. Los autos autónomos que dependen del aprendizaje automático para navegar pronto podrían estar disponibles para los consumidores.
El aprendizaje automático es un campo en constante desarrollo. Debido a esto, hay algunas consideraciones a tener en cuenta al trabajar con metodologías de aprendizaje automático o al analizar el impacto de los procesos de aprendizaje automático.
En este tutorial, examinaremos los métodos comunes de aprendizaje automático supervisado y no supervisado, así como enfoques algorítmicos comunes en el aprendizaje automático, que incluyen el algoritmo de vecinos más cercanos, el aprendizaje de árboles de decisión y el aprendizaje profundo. Exploraremos qué lenguajes de programación se utilizan más en el aprendizaje automático, proporcionándote algunos de los atributos positivos y negativos de cada uno. Además, discutiremos los sesgos que son perpetuados por los algoritmos de aprendizaje automático y consideraremos qué se puede tener en cuenta para evitar estos sesgos al construir algoritmos.
Métodos de Aprendizaje Automático
En el aprendizaje automático, las tareas generalmente se clasifican en categorías amplias. Estas categorías se basan en cómo se recibe el aprendizaje o cómo se proporciona la retroalimentación sobre el aprendizaje al sistema desarrollado.
Dos de los métodos de aprendizaje automático más ampliamente adoptados son el aprendizaje supervisado, que entrena algoritmos en función de datos de entrada y salida de ejemplo que están etiquetados por humanos, y el aprendizaje no supervisado, que proporciona al algoritmo datos no etiquetados para permitirle encontrar estructura dentro de sus datos de entrada. Vamos a explorar estos métodos con más detalle.
Aprendizaje supervisado
En el aprendizaje supervisado, se proporcionan al ordenador ejemplos de entradas que están etiquetados con sus salidas deseadas. El propósito de este método es que el algoritmo pueda “aprender” comparando su salida real con las salidas “enseñadas” para encontrar errores y modificar el modelo en consecuencia. Por lo tanto, el aprendizaje supervisado utiliza patrones para predecir los valores de las etiquetas en datos adicionales no etiquetados.
Por ejemplo, con el aprendizaje supervisado, se puede alimentar a un algoritmo con datos que contienen imágenes de tiburones etiquetadas como pez e imágenes de océanos etiquetadas como agua. Al ser entrenado con estos datos, el algoritmo de aprendizaje supervisado debería poder identificar más tarde imágenes no etiquetadas de tiburones como pez e imágenes no etiquetadas de océanos como agua.
A common use case of supervised learning is to use historical data to predict statistically likely future events. It may use historical stock market information to anticipate upcoming fluctuations, or be employed to filter out spam emails. In supervised learning, tagged photos of dogs can be used as input data to classify untagged photos of dogs.
Aprendizaje no supervisado
En el aprendizaje no supervisado, los datos no están etiquetados, por lo que el algoritmo de aprendizaje se encarga de encontrar similitudes entre sus datos de entrada. Dado que los datos no etiquetados son más abundantes que los datos etiquetados, los métodos de aprendizaje automático que facilitan el aprendizaje no supervisado son particularmente valiosos.
El objetivo del aprendizaje no supervisado puede ser tan sencillo como descubrir patrones ocultos dentro de un conjunto de datos, pero también puede tener como objetivo el aprendizaje de características, lo que permite que la máquina computacional descubra automáticamente las representaciones necesarias para clasificar los datos sin procesar.
El aprendizaje no supervisado se utiliza comúnmente para datos transaccionales. Puede tener un gran conjunto de datos de clientes y sus compras, pero es probable que como humano no pueda entender qué atributos similares se pueden extraer de los perfiles de clientes y sus tipos de compras. Con estos datos alimentados en un algoritmo de aprendizaje no supervisado, puede determinarse que las mujeres de cierto rango de edad que compran jabones sin perfume probablemente estén embarazadas, y por lo tanto, una campaña de marketing relacionada con el embarazo y productos para bebés puede dirigirse a este público para aumentar su número de compras.
Sin que se le indique una respuesta “correcta”, los métodos de aprendizaje no supervisado pueden analizar datos complejos que son más extensos y aparentemente no relacionados para organizarlos de manera potencialmente significativa. El aprendizaje no supervisado se usa a menudo para la detección de anomalías, incluidas las compras fraudulentas con tarjeta de crédito, y los sistemas de recomendación que sugieren qué productos comprar a continuación. En el aprendizaje no supervisado, las fotos no etiquetadas de perros pueden usarse como datos de entrada para que el algoritmo encuentre similitudes y clasifique las fotos de perros juntas.
Enfoques
Como campo, el aprendizaje automático está estrechamente relacionado con la estadística computacional, por lo que tener conocimientos previos en estadística es útil para comprender y aprovechar los algoritmos de aprendizaje automático.
Para aquellos que quizás no hayan estudiado estadística, puede ser útil definir primero la correlación y la regresión, ya que son técnicas comúnmente utilizadas para investigar la relación entre variables cuantitativas. La correlación es una medida de asociación entre dos variables que no se designan como dependientes o independientes. La regresión en un nivel básico se utiliza para examinar la relación entre una variable dependiente y una variable independiente. Debido a que las estadísticas de regresión pueden utilizarse para anticipar la variable dependiente cuando se conoce la variable independiente, la regresión permite capacidades de predicción.
Los enfoques para el aprendizaje automático se están desarrollando continuamente. Para nuestros propósitos, repasaremos algunos de los enfoques populares que se están utilizando en el aprendizaje automático en el momento de la escritura.
k-nearest neighbor
El algoritmo de vecinos más cercanos (k-nearest neighbor) es un modelo de reconocimiento de patrones que se puede utilizar tanto para clasificación como para regresión. A menudo abreviado como k-NN, el k en vecinos más cercanos es un número entero positivo, que típicamente es pequeño. En clasificación o regresión, la entrada consistirá en los k ejemplos de entrenamiento más cercanos dentro de un espacio.
Nos enfocaremos en la clasificación k-NN. En este método, la salida es la pertenencia a una clase. Esto asignará un nuevo objeto a la clase más común entre sus k vecinos más cercanos. En el caso de k = 1, el objeto se asigna a la clase del único vecino más cercano.
Veamos un ejemplo de k-vecinos más cercanos. En el diagrama a continuación, hay objetos azules en forma de diamante y objetos naranjas en forma de estrella. Estos pertenecen a dos clases separadas: la clase de diamantes y la clase de estrellas.

Cuando se agrega un nuevo objeto al espacio, en este caso un corazón verde, querremos que el algoritmo de aprendizaje automático clasifique el corazón en cierta clase.

Cuando elegimos k = 3, el algoritmo encontrará los tres vecinos más cercanos del corazón verde para clasificarlo en la clase de diamantes o en la clase de estrellas.
En nuestro diagrama, los tres vecinos más cercanos del corazón verde son un diamante y dos estrellas. Por lo tanto, el algoritmo clasificará el corazón en la clase de estrellas.
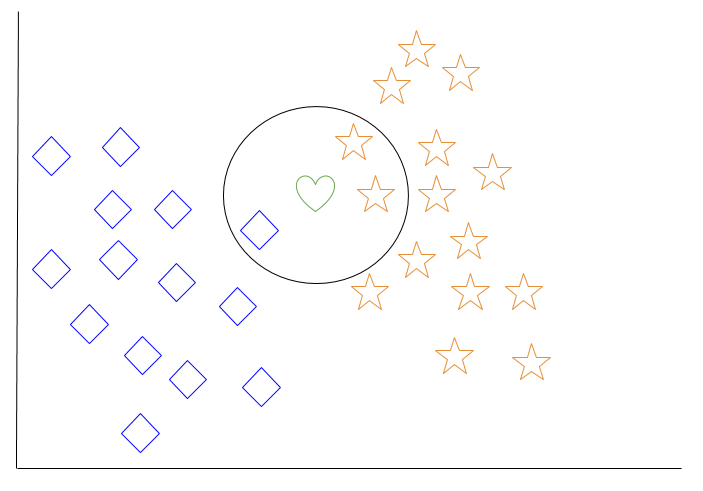
Entre los algoritmos de aprendizaje automático más básicos, el k-vecinos más cercanos se considera un tipo de “aprendizaje perezoso”, ya que la generalización más allá de los datos de entrenamiento no ocurre hasta que se realiza una consulta al sistema.
Aprendizaje de Árboles de Decisión
Para uso general, los árboles de decisión se emplean para representar visualmente decisiones y mostrar o informar la toma de decisiones. Cuando se trabaja con aprendizaje automático y minería de datos, los árboles de decisión se utilizan como modelo predictivo. Estos modelos mapean observaciones sobre datos a conclusiones sobre el valor objetivo de los datos.
El objetivo del aprendizaje de árboles de decisión es crear un modelo que prediga el valor de un objetivo basado en variables de entrada.
En el modelo predictivo, los atributos de los datos que se determinan mediante observación están representados por las ramas, mientras que las conclusiones sobre el valor objetivo de los datos están representadas en las hojas.
Al “aprender” un árbol, los datos fuente se dividen en subconjuntos basados en una prueba de valor de atributo, que se repite en cada uno de los subconjuntos derivados de manera recursiva. Una vez que el subconjunto en un nodo tiene el mismo valor que su valor objetivo, el proceso de recursión estará completo.
Veamos un ejemplo de varias condiciones que pueden determinar si alguien debería ir a pescar. Esto incluye condiciones climáticas, así como condiciones de presión barométrica.
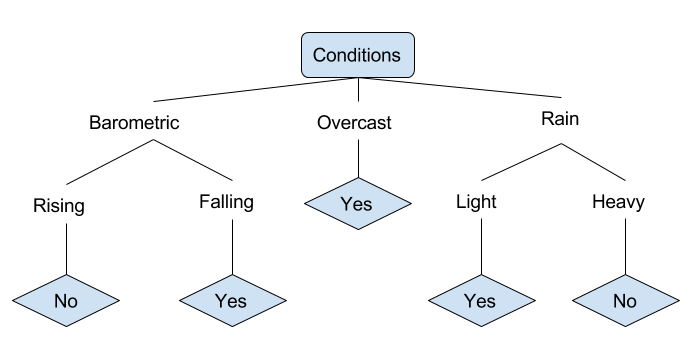
En el árbol de decisiones simplificado anterior, un ejemplo se clasifica ordenándolo a través del árbol hasta el nodo hoja apropiado. Esto luego devuelve la clasificación asociada con la hoja particular, que en este caso es o bien un Sí o un No . El árbol clasifica las condiciones de un día según si es adecuado para ir a pescar o no.
A true classification tree data set would have a lot more features than what is outlined above, but relationships should be straightforward to determine. When working with decision tree learning, several determinations need to be made, including what features to choose, what conditions to use for splitting, and understanding when the decision tree has reached a clear ending.
Aprendizaje Profundo
El aprendizaje profundo intenta imitar cómo el cerebro humano puede procesar estímulos de luz y sonido en visión y audición. Una arquitectura de aprendizaje profundo está inspirada en las redes neuronales biológicas y consta de múltiples capas en una red neuronal artificial compuesta por hardware y GPUs.
El aprendizaje profundo utiliza una cascada de capas de unidades de procesamiento no lineales para extraer o transformar características (o representaciones) de los datos. La salida de una capa sirve como entrada de la capa sucesiva. En el aprendizaje profundo, los algoritmos pueden ser supervisados y servir para clasificar datos, o no supervisados y realizar análisis de patrones.
Entre los algoritmos de aprendizaje automático que se están utilizando y desarrollando actualmente, el aprendizaje profundo absorbe la mayor cantidad de datos y ha logrado superar a los humanos en algunas tareas cognitivas. Debido a estas características, el aprendizaje profundo se ha convertido en un enfoque con un potencial significativo en el espacio de la inteligencia artificial
La visión por computadora y el reconocimiento de voz han experimentado avances significativos gracias a los enfoques de aprendizaje profundo. IBM Watson es un ejemplo conocido de un sistema que aprovecha el aprendizaje profundo.
Lenguajes de Programación
Al elegir un lenguaje para especializarse en el aprendizaje automático, es posible que desee considerar las habilidades enumeradas en los anuncios de trabajo actuales, así como las bibliotecas disponibles en varios idiomas que se pueden utilizar para procesos de aprendizaje automático.
Python es uno de los lenguajes más populares para trabajar con aprendizaje automático debido a los numerosos frameworks disponibles, incluyendo TensorFlow, PyTorch y Keras. Como un lenguaje que tiene una sintaxis legible y la capacidad de ser utilizado como un lenguaje de script, Python resulta ser poderoso y sencillo tanto para el preprocesamiento de datos como para trabajar directamente con los datos. La biblioteca de aprendizaje automático scikit-learn está construida sobre varios paquetes Python existentes con los que los desarrolladores de Python pueden estar familiarizados, a saber, NumPy, SciPy y Matplotlib.
Para comenzar con Python, puedes leer nuestra serie de tutoriales sobre “Cómo Codificar en Python 3”, o leer específicamente sobre “Cómo Construir un Clasificador de Aprendizaje Automático en Python con scikit-learn” o “Cómo Realizar Transferencia de Estilo Neural con Python 3 y PyTorch”.
Java se utiliza ampliamente en la programación empresarial y generalmente es utilizado por desarrolladores de aplicaciones de escritorio que también trabajan en aprendizaje automático a nivel empresarial. Por lo general, no es la primera opción para aquellos nuevos en la programación que desean aprender sobre aprendizaje automático, pero es preferido por aquellos con experiencia en desarrollo Java para aplicarlo al aprendizaje automático. En cuanto a las aplicaciones de aprendizaje automático en la industria, Java tiende a ser utilizado más que Python para la seguridad de redes, incluidos los casos de uso de detección de ataques cibernéticos y fraude.
Entre las bibliotecas de aprendizaje automático para Java se encuentran Deeplearning4j, una biblioteca de aprendizaje profundo de código abierto y distribuida escrita tanto para Java como para Scala; MALLET (MAchine Learning for LanguagE Toolkit) permite aplicaciones de aprendizaje automático en texto, incluido el procesamiento del lenguaje natural, modelado de temas, clasificación de documentos y clustering; y Weka, una colección de algoritmos de aprendizaje automático para tareas de minería de datos.
C++ is the language of choice for machine learning and artificial intelligence in game or robot applications (including robot locomotion). Embedded computing hardware developers and electronics engineers are more likely to favor C++ or C in machine learning applications due to their proficiency and level of control in the language. Some machine learning libraries you can use with C++ include the scalable mlpack, Dlib offering wide-ranging machine learning algorithms, and the modular and open-source Shark.
Sesgos Humanos
Aunque el análisis de datos y computacional puede hacernos pensar que estamos recibiendo información objetiva, este no es el caso; estar basado en datos no significa que los resultados del aprendizaje automático sean neutrales. El sesgo humano juega un papel en cómo se recopilan, organizan y, en última instancia, en los algoritmos que determinan cómo interactuará el aprendizaje automático con esos datos.
Por ejemplo, si las personas proporcionan imágenes de “peces” como datos para entrenar un algoritmo, y estas personas seleccionan abrumadoramente imágenes de peces dorados, una computadora puede no clasificar a un tiburón como un pez. Esto crearía un sesgo contra los tiburones como peces, y los tiburones no serían contados como peces.
Cuando se usan fotografías históricas de científicos como datos de entrenamiento, una computadora puede no clasificar adecuadamente a los científicos que también son personas de color o mujeres. De hecho, investigaciones recientes revisadas por pares han indicado que los programas de IA y aprendizaje automático exhiben sesgos similares a los humanos que incluyen prejuicios raciales y de género. Consulta, por ejemplo, “Semántica derivada automáticamente de corpora de lenguaje contiene sesgos similares a los humanos” y “A los hombres también les gusta ir de compras: Reducción de la amplificación del sesgo de género usando restricciones a nivel de corpus” [PDF].
A medida que el aprendizaje automático se utiliza cada vez más en los negocios, los sesgos no detectados pueden perpetuar problemas sistémicos que pueden evitar que las personas califiquen para préstamos, que se les muestren anuncios de oportunidades laborales bien remuneradas, o que reciban opciones de entrega el mismo día.
Debido a que el sesgo humano puede afectar negativamente a otros, es extremadamente importante ser consciente de ello y trabajar hacia su eliminación tanto como sea posible. Una forma de trabajar en esa dirección es asegurarse de que haya personas diversas trabajando en un proyecto y que personas diversas lo estén probando y revisando. Otros han pedido que terceras partes reguladoras supervisen y auditen algoritmos, que se construyan sistemas alternativos que puedan detectar sesgos, y revisiones éticas como parte de la planificación de proyectos de ciencia de datos. Crear conciencia sobre los sesgos, ser conscientes de nuestros propios sesgos inconscientes y estructurar la equidad en nuestros proyectos y procesos de aprendizaje automático puede ayudar a combatir el sesgo en este campo.

Conclusión
Este tutorial revisó algunos de los casos de uso del aprendizaje automático, métodos comunes y enfoques populares utilizados en el campo, los lenguajes de programación de aprendizaje automático adecuados, y también cubrió algunas cosas a tener en cuenta en términos de sesgos inconscientes que se replican en algoritmos.
Dado que el aprendizaje automático es un campo que se está innovando continuamente, es importante tener en cuenta que los algoritmos, métodos y enfoques seguirán cambiando.
Además de leer nuestros tutoriales sobre “Cómo construir un clasificador de aprendizaje automático en Python con scikit-learn” o “Cómo realizar transferencia de estilo neuronal con Python 3 y PyTorch“, puedes aprender más sobre trabajar con datos en la industria tecnológica leyendo nuestros tutoriales de Análisis de Datos.
Source:
https://www.digitalocean.com/community/tutorials/an-introduction-to-machine-learning