













Introduzione
Il machine learning è un sottoinsieme dell’intelligenza artificiale (AI). L’obiettivo del machine learning in generale è comprendere la struttura dei dati e adattare tali dati in modelli che possono essere compresi e utilizzati dalle persone.
Anche se il machine learning è un campo all’interno dell’informatica, differisce dagli approcci computazionali tradizionali. Nell’informatica tradizionale, gli algoritmi sono insiemi di istruzioni esplicitamente programmate utilizzate dai computer per calcolare o risolvere problemi. Gli algoritmi di machine learning consentono invece ai computer di addestrarsi su input di dati e utilizzare analisi statistiche per produrre valori che rientrano in un determinato intervallo. Grazie a questo, il machine learning permette ai computer di costruire modelli da dati di esempio per automatizzare i processi decisionali basati sugli input di dati.
Oggi ogni utente tecnologico beneficia del machine learning. La tecnologia di riconoscimento facciale consente alle piattaforme di social media di aiutare gli utenti a etichettare e condividere foto di amici. La tecnologia di riconoscimento ottico dei caratteri (OCR) converte le immagini di testo in caratteri mobili. I motori di raccomandazione, alimentati dal machine learning, suggeriscono quali film o programmi televisivi guardare successivamente in base alle preferenze dell’utente. Le auto a guida autonoma che si basano sul machine learning per navigare potrebbero presto essere disponibili per i consumatori.
Il machine learning è un campo in continuo sviluppo. A causa di ciò, ci sono alcune considerazioni da tenere presenti mentre si lavora con le metodologie di machine learning o si analizza l’impatto dei processi di machine learning.
In questo tutorial, esamineremo i comuni metodi di machine learning supervisionato e non supervisionato, e approcci algoritmici comuni nel machine learning, tra cui l’algoritmo del k-nearest neighbor, l’apprendimento dell’albero decisionale e il deep learning. Esploreremo quali linguaggi di programmazione sono più utilizzati nel machine learning, fornendoti alcuni degli attributi positivi e negativi di ciascuno. Inoltre, discuteremo i pregiudizi perpetuati dagli algoritmi di machine learning e considereremo cosa può essere tenuto presente per prevenire questi pregiudizi durante la costruzione degli algoritmi.
Metodi di Machine Learning
Nel machine learning, le attività sono generalmente classificate in categorie ampie. Queste categorie si basano su come viene ricevuto l’apprendimento o su come viene fornito il feedback sull’apprendimento al sistema sviluppato.
Due dei metodi di machine learning più ampiamente adottati sono il machine learning supervisionato che addestra gli algoritmi basandosi su dati di input ed output di esempio etichettati dagli esseri umani, e il machine learning non supervisionato che fornisce all’algoritmo dati non etichettati al fine di consentire di individuare la struttura all’interno dei suoi dati di input. Esploriamo questi metodi in dettaglio.
Apprendimento supervisionato
Nell’apprendimento supervisionato, il computer viene fornito con esempi di input che sono contrassegnati con i loro output desiderati. Lo scopo di questo metodo è far sì che l’algoritmo sia in grado di “imparare” confrontando il suo output effettivo con gli output “insegnati” per trovare errori e modificare di conseguenza il modello. Pertanto, l’apprendimento supervisionato utilizza schemi per prevedere i valori delle etichette su dati non etichettati aggiuntivi.
Ad esempio, con l’apprendimento supervisionato, un algoritmo potrebbe essere alimentato con dati contenenti immagini di squali contrassegnate come pesce e immagini di oceani contrassegnate come acqua. Essendo addestrato su questi dati, l’algoritmo di apprendimento supervisionato dovrebbe essere in grado di identificare successivamente immagini non etichettate di squali come pesce e immagini non etichettate di oceani come acqua.
A common use case of supervised learning is to use historical data to predict statistically likely future events. It may use historical stock market information to anticipate upcoming fluctuations, or be employed to filter out spam emails. In supervised learning, tagged photos of dogs can be used as input data to classify untagged photos of dogs.
Apprendimento non supervisionato
Nell’apprendimento non supervisionato, i dati non sono etichettati, quindi l’algoritmo di apprendimento è lasciato a trovare le somiglianze tra i suoi dati di input. Poiché i dati non etichettati sono più abbondanti dei dati etichettati, i metodi di apprendimento automatico che facilitano l’apprendimento non supervisionato sono particolarmente preziosi.
L’obiettivo dell’apprendimento non supervisionato può essere semplice come scoprire pattern nascosti all’interno di un insieme di dati, ma può anche avere l’obiettivo di apprendimento delle caratteristiche, che consente alla macchina computazionale di scoprire automaticamente le rappresentazioni necessarie per classificare i dati grezzi.
L’apprendimento non supervisionato è comunemente utilizzato per i dati transazionali. Potresti avere un grande insieme di dati sui clienti e sui loro acquisti, ma come essere umano probabilmente non sarai in grado di capire quali attributi simili possono essere tratti dai profili dei clienti e dai loro tipi di acquisti. Con questi dati inseriti in un algoritmo di apprendimento non supervisionato, potrebbe essere determinato che le donne di una certa fascia d’età che acquistano saponi non profumati sono probabilmente incinte, e quindi una campagna di marketing correlata alla gravidanza e ai prodotti per bambini può essere mirata a questo pubblico per aumentare il numero dei loro acquisti.
Senza essere informati di una risposta “corretta”, i metodi di apprendimento non supervisionato possono esaminare dati complessi che sono più estesi e apparentemente non correlati al fine di organizzarli in modi potenzialmente significativi. L’apprendimento non supervisionato è spesso utilizzato per il rilevamento di anomalie, incluso per gli acquisti fraudolenti con carta di credito, e per i sistemi di raccomandazione che suggeriscono quali prodotti acquistare successivamente. Nell’apprendimento non supervisionato, le foto non contrassegnate di cani possono essere utilizzate come dati di input per l’algoritmo al fine di trovare somiglianze e classificare insieme le foto di cani.
Approcci
Come campo, il machine learning è strettamente correlato alla statistica computazionale, quindi avere una conoscenza di base della statistica è utile per comprendere e sfruttare gli algoritmi di machine learning.
Per coloro che potrebbero non aver studiato statistica, può essere utile definire innanzitutto correlazione e regressione, in quanto sono tecniche comunemente utilizzate per indagare la relazione tra variabili quantitative. La correlazione è una misura di associazione tra due variabili che non sono designate né come dipendenti né come indipendenti. La regressione a un livello di base è utilizzata per esaminare la relazione tra una variabile dipendente e una variabile indipendente. Poiché le statistiche di regressione possono essere utilizzate per prevedere la variabile dipendente quando è nota la variabile indipendente, la regressione abilita capacità di previsione.
Le approcci al machine learning sono continuamente in fase di sviluppo. Per i nostri scopi, esamineremo alcuni degli approcci popolari che vengono utilizzati nel machine learning al momento della scrittura.
k-nearest neighbor
L’algoritmo dei k-NN (k-vicini più prossimi) è un modello di riconoscimento di pattern che può essere utilizzato sia per la classificazione che per la regressione. Spesso abbreviato come k-NN, il k in k-vicini più prossimi è un numero intero positivo, che di solito è piccolo. Sia nella classificazione che nella regressione, l’input consisterà nei k esempi di addestramento più vicini all’interno di uno spazio.
Ci concentreremo sulla classificazione k-NN. In questo metodo, l’output è l’appartenenza alla classe. Ciò assegnerà un nuovo oggetto alla classe più comune tra i suoi k vicini più prossimi. Nel caso di k = 1, l’oggetto viene assegnato alla classe del singolo vicino più prossimo.
Guardiamo un esempio di k-vicini più prossimi. Nel diagramma qui sotto, ci sono oggetti diamante blu e oggetti stella arancioni. Questi appartengono a due classi separate: la classe diamante e la classe stella.

Quando viene aggiunto un nuovo oggetto allo spazio – in questo caso un cuore verde – vogliamo che l’algoritmo di apprendimento automatico classifichi il cuore in una certa classe.

Quando scegliamo k = 3, l’algoritmo troverà i tre vicini più prossimi del cuore verde per classificarlo nella classe diamante o nella classe stella.
Nel nostro diagramma, i tre vicini più prossimi del cuore verde sono un diamante e due stelle. Pertanto, l’algoritmo classificherà il cuore nella classe stella.
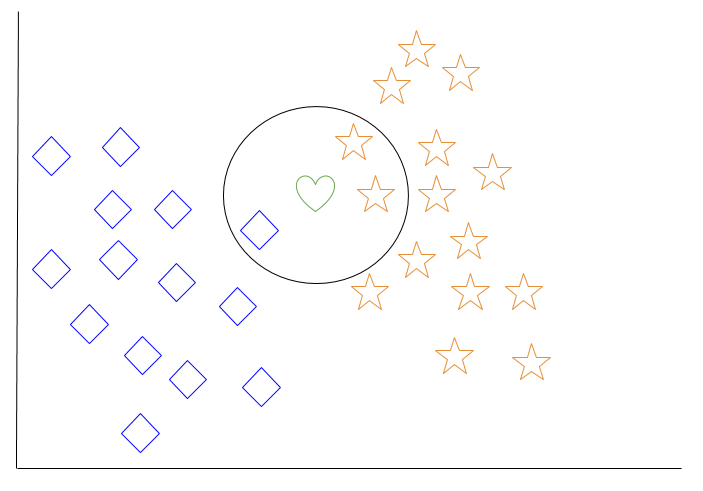
Tra gli algoritmi di apprendimento automatico più basilari, il k-vicini più prossimi è considerato un tipo di “apprendimento pigro” poiché la generalizzazione al di là dei dati di addestramento non avviene fino a quando non viene effettuata una richiesta al sistema.
Apprendimento dell’albero decisionale
Per un uso generale, gli alberi decisionali vengono impiegati per rappresentare visualmente decisioni e mostrare o informare la presa di decisioni. Quando si lavora con l’apprendimento automatico e il data mining, gli alberi decisionali vengono utilizzati come modello predittivo. Questi modelli mappano osservazioni sui dati a conclusioni sul valore di destinazione dei dati.
Lo scopo dell’apprendimento degli alberi decisionali è creare un modello che preveda il valore di una destinazione basato su variabili di input.
Nel modello predittivo, gli attributi dei dati determinati attraverso l’osservazione sono rappresentati dai rami, mentre le conclusioni sul valore target dei dati sono rappresentate nelle foglie.
Quando si “apprende” un albero, i dati di origine vengono divisi in sottoinsiemi basati su un test del valore dell’attributo, che viene ripetuto su ciascuno dei sottoinsiemi derivati in modo ricorsivo. Una volta che il sottoinsieme in un nodo ha lo stesso valore equivalente al suo valore target, il processo di ricorsione sarà completo.
Esaminiamo un esempio di varie condizioni che possono determinare se qualcuno dovrebbe andare a pescare o meno. Questo include le condizioni meteorologiche e le condizioni di pressione barometrica.
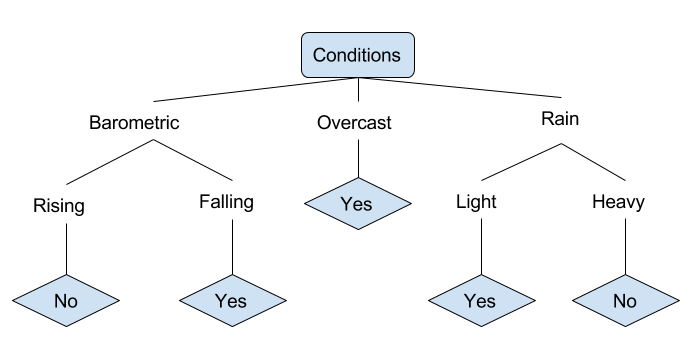
Nell’albero decisionale semplificato sopra, un esempio viene classificato ordinandolo attraverso l’albero fino al nodo foglia appropriato. Questo restituisce quindi la classificazione associata alla particolare foglia, che in questo caso è o un Sì o un No. L’albero classifica le condizioni di una giornata in base alla sua idoneità per andare a pescare.
A true classification tree data set would have a lot more features than what is outlined above, but relationships should be straightforward to determine. When working with decision tree learning, several determinations need to be made, including what features to choose, what conditions to use for splitting, and understanding when the decision tree has reached a clear ending.
Apprendimento Profondo
L’apprendimento profondo cerca di imitare come il cervello umano può elaborare gli stimoli luminosi e sonori in visione e udito. Un’architettura di apprendimento profondo è ispirata alle reti neurali biologiche e consiste in più strati in una rete neurale artificiale composta da hardware e GPU.
Il deep learning utilizza una cascata di strati di unità di elaborazione non lineare per estrarre o trasformare caratteristiche (o rappresentazioni) dei dati. L’output di uno strato funge da input per lo strato successivo. Nel deep learning, gli algoritmi possono essere sia supervisionati e servire per classificare i dati, sia non supervisionati e eseguire l’analisi dei pattern.
Tra gli algoritmi di apprendimento automatico attualmente utilizzati e sviluppati, il deep learning assorbe la maggior quantità di dati ed è stato in grado di superare gli esseri umani in alcune attività cognitive. A causa di questi attributi, il deep learning è diventato un approccio con un significativo potenziale nello spazio dell’intelligenza artificiale
La visione artificiale e il riconoscimento vocale hanno entrambi realizzato significativi progressi grazie agli approcci di deep learning. IBM Watson è un esempio ben noto di un sistema che sfrutta il deep learning.
Linguaggi di Programmazione
Quando si sceglie un linguaggio in cui specializzarsi con l’apprendimento automatico, potresti voler considerare le competenze elencate negli attuali annunci di lavoro, così come le librerie disponibili in vari linguaggi che possono essere utilizzate per processi di apprendimento automatico.
Python è uno dei linguaggi più popolari per lavorare con l’apprendimento automatico grazie ai numerosi framework disponibili, tra cui TensorFlow, PyTorch e Keras. Come linguaggio con una sintassi leggibile e la capacità di essere utilizzato come linguaggio di scripting, Python si dimostra potente e diretto sia per il pre-elaborazione dei dati che per il lavoro diretto con i dati. La libreria di apprendimento automatico scikit-learn è costruita su diversi pacchetti Python esistenti che gli sviluppatori Python potrebbero già conoscere, ovvero NumPy, SciPy e Matplotlib.
Per iniziare con Python, puoi leggere la nostra serie di tutorial su “Come Codificare in Python 3”, o leggere specificamente su “Come Costruire un Classificatore di Apprendimento Automatico in Python con scikit-learn” o “Come Eseguire il Trasferimento di Stile Neurale con Python 3 e PyTorch”.
Java è ampiamente utilizzato nella programmazione aziendale ed è generalmente utilizzato dai sviluppatori di applicazioni desktop front-end che lavorano anche su apprendimento automatico a livello aziendale. Di solito non è la prima scelta per chi è nuovo alla programmazione e vuole imparare sull’apprendimento automatico, ma è preferito da coloro con un background nello sviluppo Java da applicare all’apprendimento automatico. In termini di applicazioni di apprendimento automatico nell’industria, Java tende ad essere utilizzato più di Python per la sicurezza di rete, compresi casi d’uso come attacchi informatici e rilevamento di frodi.
Tra le librerie di apprendimento automatico per Java ci sono Deeplearning4j, una libreria di deep learning open source e distribuita scritta sia per Java che per Scala; MALLET (MAcchina Learning per Linguaggio E Toolkit) consente applicazioni di apprendimento automatico su testo, compreso il processamento del linguaggio naturale, il modellamento di argomenti, la classificazione dei documenti e il clustering; e Weka, una collezione di algoritmi di apprendimento automatico da utilizzare per compiti di data mining.
C++ is the language of choice for machine learning and artificial intelligence in game or robot applications (including robot locomotion). Embedded computing hardware developers and electronics engineers are more likely to favor C++ or C in machine learning applications due to their proficiency and level of control in the language. Some machine learning libraries you can use with C++ include the scalable mlpack, Dlib offering wide-ranging machine learning algorithms, and the modular and open-source Shark.
Preconcetti Umani
Anche se l’analisi dei dati e computazionale potrebbe farci pensare che stiamo ricevendo informazioni oggettive, questo non è il caso; essendo basati sui dati non significa che gli output dell’apprendimento automatico siano neutrali. Il pregiudizio umano gioca un ruolo nel modo in cui i dati vengono raccolti, organizzati e, alla fine, negli algoritmi che determinano come l’apprendimento automatico interagirà con quei dati.
Ad esempio, se le persone forniscono immagini di “pesci” come dati per addestrare un algoritmo, e queste persone selezionano in modo schiacciante immagini di pesci rossi, un computer potrebbe non classificare uno squalo come un pesce. Questo creerebbe un pregiudizio contro gli squali come pesci, e gli squali non verrebbero conteggiati come pesci.
Utilizzando ad esempio fotografie storiche di scienziati come dati di addestramento, un computer potrebbe non classificare correttamente gli scienziati che sono anche persone di colore o donne. Infatti, recenti ricerche revisionate dagli esperti hanno indicato che i programmi di intelligenza artificiale e apprendimento automatico mostrano pregiudizi simili a quelli umani che includono pregiudizi di razza e genere. Vedere, ad esempio, “Semantics derived automatically from language corpora contain human-like biases” e “Men Also Like Shopping: Reducing Gender Bias Amplification using Corpus-level Constraints” [PDF].
Poiché l’apprendimento automatico viene sempre più sfruttato nel mondo degli affari, i pregiudizi non rilevati possono perpetuare problemi sistemici che possono impedire alle persone di ottenere prestiti, di ricevere annunci pubblicitari per opportunità di lavoro ben remunerate o di ricevere opzioni di consegna nello stesso giorno.
Poiché il pregiudizio umano può avere un impatto negativo sugli altri, è estremamente importante essere consapevoli di esso e lavorare anche per eliminarlo il più possibile. Un modo per lavorare verso questo obiettivo è assicurarsi che ci siano persone diverse che lavorano su un progetto e che persone diverse lo stiano testando e revisionando. Altri hanno richiesto terze parti regolatorie per monitorare e verificare gli algoritmi, costruire sistemi alternativi in grado di rilevare i pregiudizi, e revisioni etiche come parte della pianificazione del progetto di scienza dei dati. Sensibilizzare sulle preclusioni, essere consapevoli dei nostri pregiudizi inconsci e strutturare l’equità nei nostri progetti e nei flussi di lavoro di apprendimento automatico può contribuire a contrastare il pregiudizio in questo campo.

Conclusione
Questo tutorial ha esaminato alcuni casi d’uso dell’apprendimento automatico, metodi comuni e approcci popolari utilizzati nel campo, linguaggi di programmazione adatti all’apprendimento automatico e ha anche affrontato alcune cose da tenere presenti in termini di pregiudizi inconsci che vengono replicati negli algoritmi.
Poiché l’apprendimento automatico è un campo che viene continuamente innovato, è importante tenere presente che algoritmi, metodi e approcci continueranno a cambiare.
Oltre a leggere i nostri tutorial su “Come Costruire un Classificatore di Apprendimento Automatico in Python con scikit-learn” o “Come Eseguire il Trasferimento dello Stile Neurale con Python 3 e PyTorch“, puoi imparare di più sul lavoro con i dati nell’industria tecnologica leggendo i nostri tutorial su Analisi dei Dati.
Source:
https://www.digitalocean.com/community/tutorials/an-introduction-to-machine-learning