













مقدمة
التعلم الآلي هو فرع من الذكاء الاصطناعي (AI). الهدف العام من التعلم الآلي هو فهم بنية البيانات وتناسب تلك البيانات في نماذج يمكن فهمها واستخدامها من قبل الأشخاص.
على الرغم من أن التعلم الآلي هو مجال داخل علم الحاسوب، إلا أنه يختلف عن النهج الحوسبة التقليدية. في الحوسبة التقليدية، الخوارزميات هي مجموعات من التعليمات المبرمجة صراحة تستخدمها الحواسيب لحساب أو حل مشكلة. بدلاً من ذلك، تسمح خوارزميات التعلم الآلي للحواسيب بالتدريب على مدخلات البيانات واستخدام التحليل الإحصائي من أجل إخراج قيم تقع ضمن نطاق معين. وبسبب ذلك، يسهل التعلم الآلي للحواسيب بناء نماذج من البيانات العينية من أجل أتمتة عمليات اتخاذ القرارات استنادًا إلى مدخلات البيانات.
يستفيد أي مستخدم للتكنولوجيا اليوم من التعلم الآلي. تتيح تقنية التعرف على الوجوه لمنصات التواصل الاجتماعي مساعدة المستخدمين في تسمية ومشاركة صور الأصدقاء. تقنية التعرف الضوئي على النص (OCR) تحول صور النص إلى نوع متحرك. يقترح محركات الاقتراح، التي تعمل بتقنية التعلم الآلي، الأفلام أو البرامج التلفزيونية التي يجب مشاهدتها بناءً على تفضيلات المستخدم. قد تكون السيارات القيادية الذاتية التي تعتمد على التعلم الآلي للتنقل متاحة قريبًا للمستهلكين.
التعلم الآلي هو مجال متطور باستمرار. وبسبب هذا، هناك بعض الاعتبارات التي يجب أن تخذها في الاعتبار أثناء العمل مع منهجيات التعلم الآلي، أو تحليل تأثير عمليات التعلم الآلي.
في هذا البرنامج التعليمي، سنتعرض لأساليب التعلم الآلي الشائعة للتعلم المراقب وغير المراقب، والنهج الخوارزمية الشائعة في التعلم الآلي، بما في ذلك خوارزمية أقرب جار، وتعلم شجرة القرارات، والتعلم العميق. سنستكشف اللغات البرمجية التي تستخدم بشكل أكبر في التعلم الآلي، ونقدم لك بعض السمات الإيجابية والسلبية لكل منها. بالإضافة إلى ذلك، سنناقش التحيزات التي يُعاني منها خوارزميات التعلم الآلي، وننظر في ما يمكن أن يُراعى لمنع هذه التحيزات عند بناء الخوارزميات.
أساليب التعلم الآلي
في التعلم الآلي، يتم تصنيف المهام عمومًا إلى فئات واسعة. تستند هذه الفئات إلى كيفية استقبال التعلم أو كيفية تقديم التغذية الراجعة على التعلم للنظام المطور.
اثنتان من أكثر أساليب التعلم الآلي اعتماداً هي التعلم المراقب الذي يدرب الخوارزميات بناءً على بيانات الإدخال والإخراج الأمثل التي تم تسميتها من قبل البشر، والتعلم غير المراقب الذي يوفر للخوارزمية بيانات غير مسماة للسماح لها بالعثور على هيكل داخل بيانات الإدخال الخاصة بها. دعونا نستكشف هذه الأساليب بمزيد من التفصيل.
التعلم الإشرافي
في التعلم الإشرافي، يتم تزويد الكمبيوتر بمدخلات أمثلة موسومة بمخرجاتها المرغوبة. الغرض من هذه الطريقة هو أن يكون بإمكان الخوارزمية “تعلم” عن طريق مقارنة مخرجاتها الفعلية مع المخرجات “المعلمة” للعثور على الأخطاء وتعديل النموذج وفقًا لذلك. بالتالي، يستخدم التعلم الإشرافي الأنماط لتوقع قيم العلامات على البيانات الغير موسومة إضافية.
على سبيل المثال، في التعلم الإشرافي، قد يتم تغذية خوارزمية ببيانات تحتوي على صور لأسماك موسومة باسم fish وصور لمحيطات موسومة باسم water. من خلال تدريب هذه البيانات، يجب أن تكون الخوارزمية التعلم الإشرافي قادرة لاحقًا على تحديد صور الأسماك غير الموسومة باسم fish وصور المحيطات غير الموسومة باسم water.
A common use case of supervised learning is to use historical data to predict statistically likely future events. It may use historical stock market information to anticipate upcoming fluctuations, or be employed to filter out spam emails. In supervised learning, tagged photos of dogs can be used as input data to classify untagged photos of dogs.
التعلم غير الإشرافي
في التعلم غير الإشرافي، لا تكون البيانات موسومة، لذا يترك الخوارزمية التعلمية للبحث عن التشابهات بين بياناتها الداخلية. نظرًا لأن البيانات غير الموسومة أكثر وفرة من البيانات الموسومة، فإن الأساليب في التعلم الآلي التي تسهل التعلم غير الإشرافي تكون قيمة بشكل خاص.
الهدف من التعلم غير المراقب يمكن أن يكون بسيطًا مثل اكتشاف الأنماط المخفية داخل مجموعة بيانات، ولكن قد يكون له أيضًا هدف في تعلم الميزات، مما يسمح للآلة الحاسبة باكتشاف التمثيلات التي يتم تصنيف البيانات الخام على أساسها.
يُستخدم التعلم غير المراقب عادةً للبيانات المعاملية. قد تمتلك مجموعة بيانات كبيرة للعملاء ومشترياتهم، ولكن كبشر، ربما لن تكون قادرًا على فهم أي ما يمكن استنتاجه من الملامح المماثلة لملامح العملاء وأنواع مشترياتهم. باستخدام هذه البيانات في خوارزمية التعلم غير المراقب، قد يتم تحديد أن النساء في نطاق عمر معين يشترين الصابون غير المعطر على الأرجح حوامل، وبالتالي يمكن استهداف حملة تسويقية متعلقة بالحمل ومنتجات الأطفال لهذه الجمهور لزيادة عدد مشترياتهم.
دون أن يُخبر بـ “إجابة” صحيحة، يمكن لطرق التعلم غير المراقب أن تنظر إلى بيانات معقدة تكون أوسع وتبدو غير متصلة لتنظيمها بطرق معنوية بالإمكان. يُستخدم التعلم غير المراقب في كثير من الأحيان لاكتشاف الشواذ بما في ذلك للمشتريات الاحتيالية باستخدام بطاقات الائتمان، ونظم التوصيات التي توصي بالمنتجات التي يمكن شراؤها بعد ذلك. في التعلم غير المراقب، يمكن استخدام الصور غير الموسومة للكلاب كبيانات مدخلة للخوارزمية للعثور على التشابهات وتصنيف صور الكلاب معًا.
النهج
كحقل، يرتبط التعلم الآلي ارتباطًا وثيقًا بالإحصاءات الحاسوبية، لذا فإن وجود معرفة أساسية في الإحصاءات مفيد لفهم واستغلال خوارزميات التعلم الآلي.
بالنسبة لأولئك الذين قد لا يكونون قد درسوا الإحصاءات، يمكن أن يكون من المفيد تعريف الارتباط والانحدار أولاً، حيث أنهما تقنيتان شائعتان لاستكشاف العلاقة بين المتغيرات الكمية. الارتباط هو قياس للارتباط بين متغيرين لم يتم تحديدهما كمتغيرات تابعة أو مستقلة. الانحدار على المستوى الأساسي يُستخدم لفحص العلاقة بين متغير تابع واحد ومتغير مستقل واحد. بسبب إمكانية استخدام إحصاءات الانحدار لتوقع المتغير التابع عندما يُعرف المتغير المستقل، يمكن للانحدار تمكين إمكانيات التنبؤ.
تتم متابعة تطوير النهج للتعلم الآلي باستمرار. لأغراضنا، سنتناول بعض النهج الشائعة التي يتم استخدامها في التعلم الآلي في وقت الكتابة.
k-nearest neighbor
خوارزمية أقرب الجيران k-NN هي نموذج للاعتراف بالأنماط يمكن استخدامه للتصنيف بالإضافة إلى الانحدار. غالبًا ما يُختصر باسم k-NN، و k في أقرب الجيران k-NN هو عدد صحيح موجب، والذي يكون عادة صغيرًا. في التصنيف أو الانحدار، سيتكون المدخل من أقرب k أمثلة تدريب داخل مساحة ما.
سنركز على تصنيف k-NN. في هذه الطريقة، الناتج هو عضوية الفئة. سيتم تعيين كائن جديد إلى الفئة الأكثر شيوعًا بين أقرب k جيران له. في حالة k = 1، يتم تعيين الكائن إلى فئة الجار الأقرب الواحد.
لنلقِ نظرة على مثال لأقرب جار k-nearest neighbor. في الرسم البياني أدناه، هناك كائنات ماسية زرقاء وكائنات نجمية برتقالية. تنتمي هذه إلى فئتين مختلفتين: فئة الماس وفئة النجمة.

عند إضافة كائن جديد إلى الفضاء — في هذه الحالة قلب أخضر — سنريد من خوارزمية تعلم الآلة تصنيف القلب إلى فئة معينة.

عندما نختار k = 3، ستجد الخوارزمية الأقرب ثلاثة جيران للقلب الأخضر لتصنيفه إما إلى فئة الماس أو فئة النجمة.
في رسمنا البياني، الجيران الثلاثة الأقرباء للقلب الأخضر هم ماسة ونجمتين. لذا، ستصنف الخوارزمية القلب مع فئة النجمة.
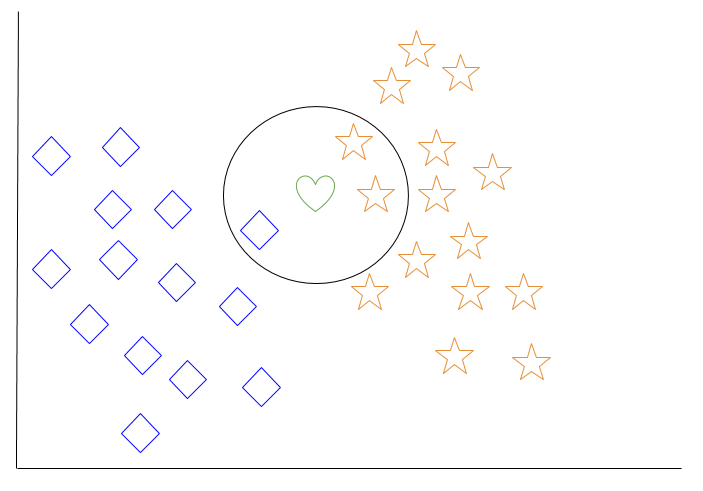
من بين أبسط خوارزميات التعلم الآلي، يُعتبر أقرب جار k-nearest من نوع “التعلم الكسول” حيث لا يحدث تعميم خارج بيانات التدريب إلا عند إجراء استعلام على النظام.
تعلم شجرة القرار
للاستخدام العام، يُستخدم شجر القرار لتمثيل القرارات بصورة بصرية وإظهارها أو إبلاغ عملية اتخاذ القرار. عند العمل مع التعلم الآلي وتنقيب البيانات، يُستخدم شجر القرار كنموذج تنبؤي. تربط هذه النماذج الملاحظات حول البيانات باستنتاجات حول قيمة الهدف في البيانات.
هدف تعلم شجرة القرار هو إنشاء نموذج يتنبأ بقيمة هدف معينة بناءً على المتغيرات المدخلة.
في النموذج التنبؤي، تُمثِّل الفروع السمات التي تم تحديدها من خلال الملاحظة، بينما تُمثِّل الأوراق الاستنتاجات حول قيمة الهدف من البيانات.
عند “تعلم” الشجرة، يتم تقسيم بيانات المصدر إلى مجموعات فرعية بناءً على اختبار قيمة السمة، والذي يُكرَّر على كل من مجموعات الناتج تكرارًا. بمجرد أن يكون لمجموعة الفرع قيمة مكافئة لقيمة هدفها، سيكون عملية الاستدعاء قد اكتملت.
دعونا نلقي نظرة على مثال لظروف مختلفة يمكن أن تحدد ما إذا كان الشخص يجب أن يذهب للصيد أم لا. يتضمن ذلك الظروف الجوية بالإضافة إلى ظروف الضغط الجوي.
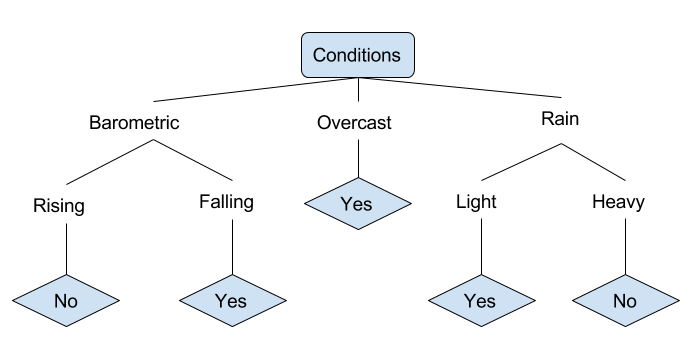
في الشجرة القرارية المبسطة أعلاه، يتم تصنيف المثال عن طريق تمريره من خلال الشجرة إلى العقدة الورقية المناسبة. يتم بعد ذلك إعادة التصنيف المرتبط بالورقة المعينة، والتي في هذه الحالة هي إما نعم أو لا. تصنف الشجرة ظروف اليوم بناءً على ما إذا كانت مناسبة للذهاب للصيد أم لا.
A true classification tree data set would have a lot more features than what is outlined above, but relationships should be straightforward to determine. When working with decision tree learning, several determinations need to be made, including what features to choose, what conditions to use for splitting, and understanding when the decision tree has reached a clear ending.
التعلم العميق
يحاول التعلم العميق تقليد كيف يمكن للدماغ البشري معالجة المحفزات الضوئية والصوتية إلى رؤية وسماع. يستلهم تصميم التعلم العميق من الشبكات العصبية الحيوية ويتكون من عدة طبقات في شبكة عصبية اصطناعية مكونة من الأجهزة ووحدات معالجة الرسومات.
تستخدم التعلم العميق سلسلة من طبقات وحدات معالجة غير خطية لاستخراج أو تحويل ميزات (أو تمثيلات) البيانات. يعمل إخراج طبقة واحدة كمدخل للطبقة اللاحقة. في التعلم العميق، يمكن أن تكون الخوارزميات إما مراقبة وتخدم في تصنيف البيانات، أو غير مراقبة وتنفذ تحليل الأنماط.
من بين خوارزميات التعلم الآلي التي يتم استخدامها وتطويرها حاليًا، يستوعب التعلم العميق أكبر كمية من البيانات وقد تمكن من تغلب البشر في بعض المهام المعرفية. نظرًا لهذه الخصائص، أصبح التعلم العميق نهجًا ذا إمكانيات كبيرة في مجال الذكاء الاصطناعي
لقد تحقق كل من رؤية الحاسوب والتعرف على الكلام تقدمات كبيرة من النهج التعليمي العميق. IBM Watson هو مثال معروف على نظام يستفيد من التعلم العميق.
لغات البرمجة
عند اختيار لغة للتخصص في مجال التعلم الآلي، قد ترغب في النظر في المهارات المدرجة في إعلانات الوظائف الحالية، فضلاً عن المكتبات المتوفرة في مختلف اللغات التي يمكن استخدامها في عمليات التعلم الآلي.
بايثون هو واحد من أشهر اللغات للعمل مع تعلم الآلة بسبب الإطارات المتاحة بشكل كبير، بما في ذلك TensorFlow، PyTorch، و Keras. كلغة لها بناء قراءة والقدرة على استخدامها كلغة نصية، يثبت بايثون أنه قوي ومباشر لكل من معالجة البيانات والعمل معها مباشرة. تم بناء مكتبة التعلم الآلي scikit-learn على عدة حزم Python موجودة بالفعل وقد يكون المطورون الذين يستخدمون Python بالفعل ملمين بها، وهي NumPy، SciPy، و Matplotlib.
للبدء بـ Python، يمكنك قراءة سلسلة البرامج التعليمية على “كيفية كتابة التعليمات البرمجية باستخدام Python 3“، أو القراءة بشكل مخصص على “كيفية بناء فئة معالجة التعلم الآلي في Python باستخدام scikit-learn” أو “كيفية القيام بنقل النمط العصبي باستخدام Python 3 و PyTorch.”
Java مستخدم على نطاق واسع في برمجة المؤسسات، ويستخدم بشكل عام من قبل مطوري تطبيقات الواجهة الأمامية المكتبية الذين يعملون أيضًا على التعلم الآلي على مستوى المؤسسة. عادة ما لا يكون الخيار الأول لأولئك الذين يبدؤون في البرمجة ويرغبون في تعلم التعلم الآلي، ولكنه يُفضل من قبل أولئك الذين لديهم خلفية بالبرمجة باستخدام Java لتطبيقها على التعلم الآلي. من حيث تطبيقات التعلم الآلي في الصناعة، يُستخدم Java بشكل أكثر من Python للأمن الشبكي، بما في ذلك في حالات استخدام الهجوم السيبراني والكشف عن الاحتيال.
بين مكتبات تعلم الآلة للغة البرمجة Java هي Deeplearning4j، وهي مكتبة عميقة التعلم مفتوحة المصدر وموزعة مكتوبة لكل من Java وScala؛ MALLET (MAchine Learning for LanguagE Toolkit) تسمح بتطبيقات تعلم الآلة على النص، بما في ذلك معالجة اللغة الطبيعية، ونمذجة الموضوع، وتصنيف المستندات، والتجميع؛ و Weka، وهي مجموعة من خوارزميات تعلم الآلة لاستخدامها في مهام استخراج البيانات.
C++ is the language of choice for machine learning and artificial intelligence in game or robot applications (including robot locomotion). Embedded computing hardware developers and electronics engineers are more likely to favor C++ or C in machine learning applications due to their proficiency and level of control in the language. Some machine learning libraries you can use with C++ include the scalable mlpack, Dlib offering wide-ranging machine learning algorithms, and the modular and open-source Shark.
الانحياز البشري
على الرغم من أن البيانات والتحليل الحسابي قد يجعلنا نعتقد أننا نتلقى معلومات موضوعية، فإن هذا ليس هو الحال؛ كونها تستند إلى البيانات لا يعني أن نتائج تعلم الآلة محايدة. يلعب الانحياز البشري دورًا في كيفية جمع البيانات وتنظيمها وفي النهاية في الخوارزميات التي تحدد كيف ستتفاعل تعلم الآلة مع تلك البيانات.
إذا كان الناس، على سبيل المثال، يقدمون صورًا لـ “الأسماك” كبيانات لتدريب خوارزمية، وكان هؤلاء الأشخاص يختارون بشكل غير متناسب صور السمك الذهبي، قد لا يصنف الكمبيوتر سمكة القرش على أنها سمكة. هذا سيخلق تحيزًا ضد سمكة القرش كسمكة، ولن يتم عد سمكة القرش كسمكة.
عند استخدام صور تاريخية للعلماء كبيانات تدريبية، قد لا يتم تصنيف العلماء الذين هم أيضًا من أصل أجنبي أو نساء بشكل صحيح. في الواقع، أشارت الأبحاث المعتمدة مؤخرًا إلى أن برامج الذكاء الاصطناعي وتعلم الآلة يظهرون تحيزات تشبه البشر تشمل العنصرية والتحيزات الجندرية. انظر، على سبيل المثال “إن المعاني المستخرجة تلقائيًا من المجموعات اللغوية تحتوي على تحيزات تشبه البشر” و “رجال يحبون أيضًا التسوق: تقليل تضخيم التحيز الجندري باستخدام قيود المستندات على المستوى العالمي” [PDF].
مع تحقيق التعلم الآلي أكثر في الأعمال، قد يولد التحيزات غير المكتشفة جراءات إحداثية قد تمنع الناس من الحصول على قروض، أو من رؤية الإعلانات عن فرص عمل عالية الدخل، أو من تلقي خيارات التوصيل في نفس اليوم.
لأن التحيز الإنساني يمكن أن يؤثر سلبًا على الآخرين، فمن الأمر حيوي للغاية التأكد من أننا ندرك ذلك، والعمل جاهدين نحو التخلص منه بقدر الإمكان. إحدى الطرق للوصول إلى هذا الهدف هي التأكد من وجود أشخاص متنوعين يعملون على مشروع وأن يتم اختبار ومراجعته من قبل أشخاص متنوعين. يطالب آخرون بوجود أطراف إدارية ثالثة لمراقبة ومراجعة الخوارزميات، بناء أنظمة بديلة قادرة على الكشف عن التحيزات، و مراجعات أخلاقية كجزء من تخطيط مشاريع علم البيانات. رفع الوعي بشأن التحيزات، والتحقق من تحيزاتنا اللاوعية، وتنظيم العدل في مشاريع تعلم الآلة وقنواتها يمكن أن يساعد في مكافحة التحيز في هذا المجال.

الخاتمة
هذا البرنامج التعليمي يستعرض بعض حالات استخدام تعلم الآلة، والأساليب الشائعة المستخدمة في هذا المجال، واللغات البرمجية المناسبة لتعلم الآلة، ويغطي أيضًا بعض الأشياء التي يجب أخذها في الاعتبار من حيث تكرار التحيزات اللاوعية في الخوارزميات.
بما أن تعلم الآلة هو مجال يتجدد باستمرار، من المهم أن نضع في اعتبارنا أن الخوارزميات والأساليب والنهج سيستمرون في التغيير.
بالإضافة إلى قراءة البرامج التعليمية الخاصة بنا حول “كيفية بناء مصنف تعلم الآلة باستخدام Python مع scikit-learn” أو “كيفية أداء نقل النمط العصبي باستخدام Python 3 و PyTorch”، يمكنك أن تتعلم المزيد حول العمل مع البيانات في صناعة التكنولوجيا من خلال قراءة برامجنا التعليمية حول تحليل البيانات.
Source:
https://www.digitalocean.com/community/tutorials/an-introduction-to-machine-learning