













Introdução
A aprendizagem de máquina é um subcampo da inteligência artificial (IA). O objetivo da aprendizagem de máquina, em geral, é entender a estrutura dos dados e ajustar esses dados em modelos que possam ser compreendidos e utilizados por pessoas.
Embora a aprendizagem de máquina seja um campo dentro da ciência da computação, difere das abordagens computacionais tradicionais. Na computação tradicional, os algoritmos são conjuntos de instruções explicitamente programadas usadas pelos computadores para calcular ou resolver problemas. Em vez disso, os algoritmos de aprendizagem de máquina permitem que os computadores sejam treinados em entradas de dados e usem análise estatística para produzir valores que estejam dentro de uma faixa específica. Por causa disso, a aprendizagem de máquina facilita aos computadores a construção de modelos a partir de dados de amostra para automatizar processos de tomada de decisão com base em entradas de dados.
Qualquer usuário de tecnologia hoje tem se beneficiado da aprendizagem de máquina. A tecnologia de reconhecimento facial permite que plataformas de mídia social ajudem os usuários a marcar e compartilhar fotos de amigos. A tecnologia de reconhecimento óptico de caracteres (OCR) converte imagens de texto em tipos móveis. Motores de recomendação, impulsionados pela aprendizagem de máquina, sugerem quais filmes ou programas de televisão assistir com base nas preferências do usuário. Carros autônomos que dependem da aprendizagem de máquina para navegação podem em breve estar disponíveis para os consumidores.
A aprendizagem de máquina é um campo em constante desenvolvimento. Devido a isso, existem algumas considerações a ter em mente ao trabalhar com metodologias de aprendizagem de máquina ou analisar o impacto dos processos de aprendizagem de máquina.
Neste tutorial, vamos explorar os métodos comuns de aprendizagem de máquina supervisionada e não supervisionada, e abordagens algorítmicas comuns na aprendizagem de máquina, incluindo o algoritmo de vizinhos mais próximos, aprendizagem de árvore de decisão e aprendizagem profunda. Vamos explorar quais linguagens de programação são mais usadas na aprendizagem de máquina, fornecendo algumas das características positivas e negativas de cada uma. Além disso, vamos discutir os preconceitos perpetuados por algoritmos de aprendizagem de máquina e considerar o que pode ser mantido em mente para prevenir esses preconceitos ao construir algoritmos.
Métodos de Aprendizagem de Máquina
Na aprendizagem de máquina, as tarefas geralmente são classificadas em categorias amplas. Essas categorias são baseadas em como a aprendizagem é recebida ou como o feedback sobre a aprendizagem é dado ao sistema desenvolvido.
Dois dos métodos de aprendizagem de máquina mais amplamente adotados são a aprendizagem supervisionada, que treina algoritmos com base em dados de entrada e saída de exemplo que são rotulados por humanos, e a aprendizagem não supervisionada, que fornece ao algoritmo dados não rotulados para permitir que ele encontre estrutura dentro de seus dados de entrada. Vamos explorar esses métodos com mais detalhes.
Aprendizado Supervisionado
No aprendizado supervisionado, o computador recebe exemplos de entradas que são rotuladas com suas saídas desejadas. O objetivo deste método é permitir que o algoritmo “aprenda” comparando sua saída real com as saídas “ensinadas” para encontrar erros e modificar o modelo em conformidade. Portanto, o aprendizado supervisionado usa padrões para prever valores de rótulos em dados adicionais não rotulados.
Por exemplo, com aprendizado supervisionado, um algoritmo pode receber dados com imagens de tubarões rotuladas como peixe e imagens de oceanos rotuladas como água. Ao ser treinado com esses dados, o algoritmo de aprendizado supervisionado deve ser capaz de identificar posteriormente imagens de tubarões não rotuladas como peixe e imagens de oceanos não rotuladas como água.
A common use case of supervised learning is to use historical data to predict statistically likely future events. It may use historical stock market information to anticipate upcoming fluctuations, or be employed to filter out spam emails. In supervised learning, tagged photos of dogs can be used as input data to classify untagged photos of dogs.
Aprendizado Não Supervisionado
No aprendizado não supervisionado, os dados não são rotulados, então o algoritmo de aprendizado é deixado para encontrar similaridades entre seus dados de entrada. Como os dados não rotulados são mais abundantes do que os dados rotulados, os métodos de aprendizado de máquina que facilitam o aprendizado não supervisionado são particularmente valiosos.
O objetivo da aprendizagem não supervisionada pode ser tão simples quanto descobrir padrões ocultos dentro de um conjunto de dados, mas também pode ter como objetivo a aprendizagem de características, o que permite que a máquina computacional descubra automaticamente as representações necessárias para classificar dados brutos.
A aprendizagem não supervisionada é comumente usada para dados transacionais. Você pode ter um grande conjunto de dados de clientes e suas compras, mas, como humano, provavelmente não conseguirá entender quais atributos semelhantes podem ser extraídos dos perfis dos clientes e seus tipos de compras. Com esses dados inseridos em um algoritmo de aprendizagem não supervisionada, pode-se determinar que mulheres de uma determinada faixa etária que compram sabonetes sem perfume provavelmente estão grávidas e, portanto, uma campanha de marketing relacionada à gravidez e produtos para bebês pode ser direcionada a esse público para aumentar o número de suas compras.
Sem ser informado de uma resposta “correta”, os métodos de aprendizagem não supervisionada podem examinar dados complexos que são mais expansivos e aparentemente não relacionados para organizá-los de maneiras potencialmente significativas. A aprendizagem não supervisionada é frequentemente usada para detecção de anomalias, incluindo compras fraudulentas com cartão de crédito, e sistemas de recomendação que recomendam quais produtos comprar a seguir. Na aprendizagem não supervisionada, fotos não marcadas de cachorros podem ser usadas como dados de entrada para o algoritmo encontrar semelhanças e classificar fotos de cachorros juntas.
Abordagens
Como campo, o aprendizado de máquina está intimamente relacionado à estatística computacional, então ter conhecimento prévio em estatística é útil para entender e aproveitar os algoritmos de aprendizado de máquina.
Para aqueles que talvez não tenham estudado estatística, pode ser útil primeiro definir correlação e regressão, pois são técnicas comumente utilizadas para investigar a relação entre variáveis quantitativas. Correlação é uma medida de associação entre duas variáveis que não são designadas como dependentes ou independentes. Regressão, em um nível básico, é usada para examinar a relação entre uma variável dependente e uma variável independente. Como as estatísticas de regressão podem ser usadas para antecipar a variável dependente quando a variável independente é conhecida, a regressão possibilita capacidades de previsão.
As abordagens para o aprendizado de máquina estão continuamente sendo desenvolvidas. Para nossos propósitos, vamos passar por algumas das abordagens populares que estão sendo usadas no aprendizado de máquina no momento da escrita.
k-nearest neighbor
O algoritmo dos k-vizinhos mais próximos é um modelo de reconhecimento de padrões que pode ser usado para classificação, bem como regressão. Frequentemente abreviado como k-NN, o k em k-vizinhos mais próximos é um número inteiro positivo, que é tipicamente pequeno. Em classificação ou regressão, a entrada consistirá nos k exemplos de treinamento mais próximos dentro de um espaço.
Nós nos concentraremos na classificação k-NN. Neste método, a saída é a pertinência à classe. Isso atribuirá um novo objeto à classe mais comum entre seus k vizinhos mais próximos. No caso de k = 1, o objeto é atribuído à classe do único vizinho mais próximo.
Vamos dar uma olhada em um exemplo de k-vizinhos mais próximos. No diagrama abaixo, existem objetos de diamante azul e objetos de estrela laranja. Estes pertencem a duas classes separadas: a classe diamante e a classe estrela.

Quando um novo objeto é adicionado ao espaço — neste caso, um coração verde — queremos que o algoritmo de aprendizado de máquina classifique o coração em uma determinada classe.

Ao escolher k = 3, o algoritmo encontrará os três vizinhos mais próximos do coração verde para classificá-lo na classe diamante ou na classe estrela.
No nosso diagrama, os três vizinhos mais próximos do coração verde são um diamante e duas estrelas. Portanto, o algoritmo classificará o coração na classe estrela.
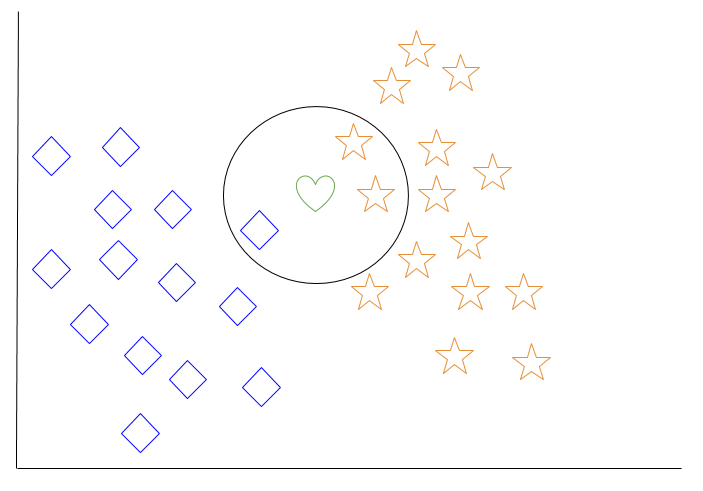
Entre os algoritmos de aprendizado de máquina mais básicos, o k-vizinhos mais próximos é considerado um tipo de “aprendizado preguiçoso”, pois a generalização além dos dados de treinamento não ocorre até que uma consulta seja feita ao sistema.
Aprendizado de Árvore de Decisão
Para uso geral, árvores de decisão são empregadas para representar visualmente decisões e mostrar ou informar a tomada de decisão. Ao trabalhar com aprendizado de máquina e mineração de dados, árvores de decisão são usadas como um modelo preditivo. Esses modelos mapeiam observações sobre dados para conclusões sobre o valor alvo dos dados.
O objetivo do aprendizado de árvore de decisão é criar um modelo que preverá o valor de um alvo com base em variáveis de entrada.
No modelo preditivo, os atributos dos dados que são determinados por meio de observação são representados pelos ramos, enquanto as conclusões sobre o valor alvo dos dados são representadas nas folhas.
Ao “aprender” uma árvore, os dados de origem são divididos em subconjuntos com base em um teste de valor de atributo, que é repetido em cada um dos subconjuntos derivados recursivamente. Uma vez que o subconjunto em um nó tem o mesmo valor equivalente ao seu valor alvo, o processo de recursão estará completo.
Vamos dar um exemplo de várias condições que podem determinar se alguém deve ou não pescar. Isso inclui condições climáticas, bem como condições de pressão barométrica.
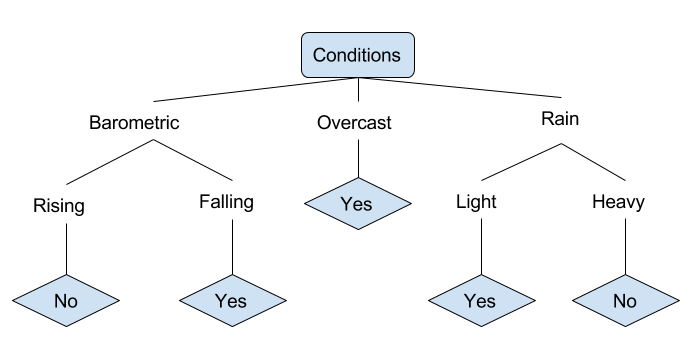
No diagrama de árvore de decisão simplificado acima, um exemplo é classificado ao passar pela árvore até o nó folha apropriado. Isso então retorna a classificação associada ao nó folha específico, que neste caso é ou um Sim ou um Não. A árvore classifica as condições de um dia com base em se é adequado ou não para ir pescar.
A true classification tree data set would have a lot more features than what is outlined above, but relationships should be straightforward to determine. When working with decision tree learning, several determinations need to be made, including what features to choose, what conditions to use for splitting, and understanding when the decision tree has reached a clear ending.
Aprendizado Profundo
O aprendizado profundo tenta imitar como o cérebro humano pode processar estímulos de luz e som em visão e audição. Uma arquitetura de aprendizado profundo é inspirada em redes neurais biológicas e consiste em múltiplas camadas em uma rede neural artificial composta por hardware e GPUs.
A aprendizagem profunda utiliza uma cascata de camadas de unidades de processamento não lineares para extrair ou transformar características (ou representações) dos dados. A saída de uma camada serve como entrada para a camada sucessiva. Na aprendizagem profunda, os algoritmos podem ser supervisionados e servir para classificar dados, ou não supervisionados e realizar análise de padrões.
Entre os algoritmos de aprendizado de máquina que estão sendo atualmente utilizados e desenvolvidos, a aprendizagem profunda absorve a maior quantidade de dados e tem sido capaz de superar humanos em algumas tarefas cognitivas. Devido a esses atributos, a aprendizagem profunda tornou-se uma abordagem com um potencial significativo no espaço da inteligência artificial
A visão computacional e o reconhecimento de fala obtiveram avanços significativos a partir das abordagens de aprendizado profundo. O IBM Watson é um exemplo conhecido de um sistema que utiliza aprendizado profundo.
Linguagens de Programação
Ao escolher uma linguagem para se especializar em aprendizado de máquina, você pode querer considerar as habilidades listadas em anúncios de emprego atuais, bem como bibliotecas disponíveis em várias linguagens que podem ser usadas para processos de aprendizado de máquina.
O Python é uma das linguagens mais populares para trabalhar com aprendizado de máquina devido aos muitos frameworks disponíveis, incluindo TensorFlow, PyTorch e Keras. Como uma linguagem que possui uma sintaxe legível e a capacidade de ser usada como uma linguagem de script, o Python prova ser poderoso e direto tanto para pré-processamento de dados quanto para trabalhar com dados diretamente. A biblioteca de aprendizado de máquina scikit-learn é construída sobre vários pacotes Python existentes com os quais os desenvolvedores Python podem já estar familiarizados, nomeadamente NumPy, SciPy e Matplotlib.
Para começar com o Python, você pode ler nossa série de tutoriais sobre “Como Codificar em Python 3“, ou ler especificamente sobre “Como Construir um Classificador de Aprendizado de Máquina em Python com scikit-learn” ou “Como Realizar Transferência de Estilo Neural com Python 3 e PyTorch“.
O Java é amplamente utilizado na programação empresarial e geralmente é utilizado por desenvolvedores de aplicativos de desktop front-end que também trabalham em aprendizado de máquina em nível empresarial. Normalmente, não é a primeira escolha para aqueles novos na programação que desejam aprender sobre aprendizado de máquina, mas é preferido por aqueles com experiência em desenvolvimento Java para aplicar ao aprendizado de máquina. Em termos de aplicações de aprendizado de máquina na indústria, o Java tende a ser usado mais do que o Python para segurança de rede, incluindo casos de uso de detecção de ataques cibernéticos e fraudes.
Entre as bibliotecas de aprendizado de máquina para Java estão Deeplearning4j, uma biblioteca de aprendizado profundo distribuída e de código aberto escrita tanto para Java quanto para Scala; MALLET (MAchine Learning for LanguagE Toolkit) permite aplicações de aprendizado de máquina em texto, incluindo processamento de linguagem natural, modelagem de tópicos, classificação de documentos e agrupamento; e Weka, uma coleção de algoritmos de aprendizado de máquina para tarefas de mineração de dados.
C++ is the language of choice for machine learning and artificial intelligence in game or robot applications (including robot locomotion). Embedded computing hardware developers and electronics engineers are more likely to favor C++ or C in machine learning applications due to their proficiency and level of control in the language. Some machine learning libraries you can use with C++ include the scalable mlpack, Dlib offering wide-ranging machine learning algorithms, and the modular and open-source Shark.
Preconceitos Humanos
Embora a análise de dados e computacional possa nos fazer pensar que estamos recebendo informações objetivas, esse não é o caso; ser baseado em dados não significa que as saídas de aprendizado de máquina sejam neutras. O viés humano desempenha um papel na forma como os dados são coletados, organizados e, em última análise, nos algoritmos que determinam como o aprendizado de máquina interagirá com esses dados.
Se, por exemplo, as pessoas estiverem fornecendo imagens de “peixes” como dados para treinar um algoritmo, e essas pessoas selecionarem esmagadoramente imagens de peixes dourados, um computador pode não classificar um tubarão como peixe. Isso criaria um viés contra os tubarões como peixes, e os tubarões não seriam contados como peixes.
Ao usar fotografias históricas de cientistas como dados de treinamento, um computador pode não classificar adequadamente cientistas que também são pessoas de cor ou mulheres. Na verdade, pesquisas recentes revisadas por pares indicaram que programas de IA e aprendizado de máquina exibem preconceitos semelhantes aos humanos, incluindo preconceitos de raça e gênero. Veja, por exemplo, “Semântica derivada automaticamente de corpora de linguagem contém preconceitos semelhantes aos humanos” e “Homens Também Gostam de Fazer Compras: Reduzindo a Amplificação de Viés de Gênero Usando Restrições em Nível de Corpus” [PDF].
À medida que o aprendizado de máquina é cada vez mais utilizado nos negócios, viés não detectado pode perpetuar problemas sistêmicos que podem impedir as pessoas de se qualificarem para empréstimos, de serem mostradas anúncios de oportunidades de emprego bem remuneradas, ou de receberem opções de entrega no mesmo dia.
Porque o viés humano pode impactar negativamente outras pessoas, é extremamente importante estar ciente disso e também trabalhar para eliminá-lo o máximo possível. Uma maneira de trabalhar para alcançar isso é garantir que haja pessoas diversas trabalhando em um projeto e que pessoas diversas estejam testando e revisando-o. Outros têm pedido por terceiros regulatórios para monitorar e auditar algoritmos, construir sistemas alternativos que possam detectar viés, e revisões éticas como parte do planejamento de projetos de ciência de dados. A conscientização sobre viés, estar atento aos nossos próprios preconceitos inconscientes e estruturar equidade em nossos projetos e pipelines de aprendizado de máquina podem trabalhar para combater o viés nesse campo.

Conclusão
Este tutorial revisou alguns dos casos de uso de aprendizado de máquina, métodos comuns e abordagens populares usadas no campo, linguagens de programação de aprendizado de máquina adequadas, e também abordou algumas coisas a serem consideradas em termos de preconceitos inconscientes sendo replicados em algoritmos.
Como o aprendizado de máquina é um campo que está continuamente sendo inovado, é importante ter em mente que algoritmos, métodos e abordagens continuarão a mudar.
Além de ler nossos tutoriais sobre “Como Construir um Classificador de Aprendizado de Máquina em Python com scikit-learn” ou “Como Realizar Transferência de Estilo Neural com Python 3 e PyTorch“, você pode aprender mais sobre trabalhar com dados na indústria de tecnologia lendo nossos tutoriais de Análise de Dados.
Source:
https://www.digitalocean.com/community/tutorials/an-introduction-to-machine-learning