













Einführung
Machine Learning ist ein Teilgebiet der künstlichen Intelligenz (KI). Das Ziel des Machine Learnings besteht im Allgemeinen darin, die Struktur von Daten zu verstehen und diese Daten in Modelle zu integrieren, die von Menschen verstanden und genutzt werden können.
Obwohl Machine Learning ein Bereich der Informatik ist, unterscheidet es sich von traditionellen rechnergestützten Ansätzen. Bei traditioneller Berechnung handelt es sich um Algorithmen, die ausdrücklich programmierte Anweisungen sind, die von Computern verwendet werden, um zu berechnen oder Probleme zu lösen. Machine-Learning-Algorithmen ermöglichen es Computern jedoch, anhand von Dateninputs zu trainieren und statistische Analysen durchzuführen, um Werte auszugeben, die in einen bestimmten Bereich fallen. Aus diesem Grund unterstützt Machine Learning Computer dabei, Modelle aus Beispieldaten zu erstellen, um Entscheidungsprozesse auf der Grundlage von Dateninputs zu automatisieren.
Jeder Technologiebenutzer heute hat vom Machine Learning profitiert. Die Gesichtserkennungstechnologie ermöglicht es Social-Media-Plattformen, Benutzern dabei zu helfen, Fotos von Freunden zu markieren und zu teilen. Die optische Zeichenerkennung (OCR)-Technologie wandelt Bilder von Text in bewegliche Schrift um. Empfehlungsmaschinen, die von Machine Learning betrieben werden, schlagen basierend auf Benutzerpräferenzen vor, welche Filme oder Fernsehsendungen als nächstes angesehen werden sollen. Selbstfahrende Autos, die sich auf Machine Learning zur Navigation verlassen, könnten bald für Verbraucher verfügbar sein.
Das maschinelle Lernen ist ein kontinuierlich entwickelndes Feld. Aus diesem Grund gibt es einige Überlegungen, die Sie im Umgang mit Methoden des maschinellen Lernens oder bei der Analyse der Auswirkungen von maschinellem Lernen im Hinterkopf behalten sollten.
In diesem Tutorial werden wir die gängigen Methoden des maschinellen Lernens, überwachtes und unüberwachtes Lernen, sowie gängige algorithmische Ansätze im maschinellen Lernen wie den k-nearest neighbor Algorithmus, das Entscheidungsbaum-Lernen und Deep Learning genauer betrachten. Wir werden erkunden, welche Programmiersprachen im maschinellen Lernen am häufigsten verwendet werden, und Ihnen einige der positiven und negativen Eigenschaften jeder Sprache aufzeigen. Zusätzlich werden wir Vorurteile diskutieren, die durch maschinelle Lernalgorithmen aufrechterhalten werden, und darüber nachdenken, was berücksichtigt werden kann, um diese Vorurteile bei der Entwicklung von Algorithmen zu verhindern.
Methoden des maschinellen Lernens
Im maschinellen Lernen werden Aufgaben im Allgemeinen in breite Kategorien eingeteilt. Diese Kategorien basieren darauf, wie das Lernen empfangen wird oder wie das Feedback zum Lernen dem entwickelten System gegeben wird.
Zwei der am weitesten verbreiteten Methoden des maschinellen Lernens sind überwachtes Lernen, bei dem Algorithmen auf der Grundlage von beispielhaften Eingabe- und Ausgabedaten trainiert werden, die von Menschen gelabelt wurden, und unüberwachtes Lernen, bei dem dem Algorithmus keine gelabelten Daten zur Verfügung gestellt werden, um ihm zu ermöglichen, Strukturen innerhalb seiner Eingabedaten zu finden. Lassen Sie uns diese Methoden genauer untersuchen.
Überwachtes Lernen
Beim überwachten Lernen erhält der Computer beispielhafte Eingaben, die mit ihren gewünschten Ausgaben gekennzeichnet sind. Der Zweck dieser Methode besteht darin, dass der Algorithmus durch den Vergleich seiner tatsächlichen Ausgabe mit den „gelehrt“ Ausgaben Fehler findet und das Modell entsprechend ändert. Das überwachte Lernen verwendet daher Muster, um Labelwerte auf zusätzlichen unbeschrifteten Daten vorherzusagen.
Zum Beispiel kann ein Algorithmus beim überwachten Lernen mit Daten von Bildern von Haien, die als Fisch und Bilder von Ozeanen, die als Wasser gekennzeichnet sind, gefüttert werden. Indem er mit diesen Daten trainiert wird, sollte der überwachte Lernalgorithmus später unbeschriftete Haibilder als Fisch und unbeschriftete Ozeanbilder als Wasser identifizieren können.
A common use case of supervised learning is to use historical data to predict statistically likely future events. It may use historical stock market information to anticipate upcoming fluctuations, or be employed to filter out spam emails. In supervised learning, tagged photos of dogs can be used as input data to classify untagged photos of dogs.
Unüberwachtes Lernen
Beim unüberwachten Lernen sind die Daten unbeschriftet, sodass der Lernalgorithmus Gemeinsamkeiten zwischen seinen Eingabedaten finden muss. Da unbeschriftete Daten häufiger vorkommen als beschriftete Daten, sind Methoden des maschinellen Lernens, die unüberwachtes Lernen ermöglichen, besonders wertvoll.
Das Ziel des unüberwachten Lernens kann so einfach sein wie das Entdecken versteckter Muster innerhalb eines Datensatzes, aber es kann auch das Ziel des Merkmal-Lernens haben, das es der Rechenmaschine ermöglicht, automatisch die Darstellungen zu entdecken, die benötigt werden, um Rohdaten zu klassifizieren.
Unüberwachtes Lernen wird häufig für Transaktionsdaten verwendet. Sie könnten einen großen Datensatz von Kunden und deren Einkäufen haben, aber als Mensch werden Sie wahrscheinlich nicht in der Lage sein, zu verstehen, welche ähnlichen Attribute aus Kundenprofilen und deren Arten von Einkäufen abgeleitet werden können. Wenn diese Daten in einen unüberwachten Lernalgorithmus eingespeist werden, kann festgestellt werden, dass Frauen in einem bestimmten Altersbereich, die unparfümierte Seifen kaufen, wahrscheinlich schwanger sind, und daher kann eine Marketingkampagne im Zusammenhang mit Schwangerschafts- und Babyprodukten gezielt an dieses Publikum gerichtet werden, um ihre Anzahl von Einkäufen zu erhöhen.
Ohne ein „richtiges“ Ergebnis zu kennen, können unüberwachte Lernmethoden komplexe Daten betrachten, die umfangreicher und scheinbar nicht verwandt sind, um sie potenziell sinnvoll zu organisieren. Unüberwachtes Lernen wird oft für die Anomalieerkennung verwendet, einschließlich betrügerischer Kreditkartentransaktionen, und für Empfehlungssysteme, die empfehlen, welche Produkte als nächstes gekauft werden sollen. Beim unüberwachten Lernen können unmarkierte Fotos von Hunden als Eingabedaten für den Algorithmus verwendet werden, um Ähnlichkeiten zu finden und Hundefotos zusammen zu klassifizieren.
Ansätze
Als Feld ist maschinelles Lernen eng mit der statistischen Berechnung verbunden, daher ist es nützlich, ein Hintergrundwissen in Statistik zu haben, um maschinelles Lernen zu verstehen und Algorithmen zu nutzen.
Für diejenigen, die möglicherweise keine Statistik studiert haben, kann es hilfreich sein, zunächst Korrelation und Regression zu definieren, da sie gängige Techniken zur Untersuchung der Beziehung zwischen quantitativen Variablen sind. Korrelation ist ein Maß für die Assoziation zwischen zwei Variablen, die nicht als abhängig oder unabhängig gekennzeichnet sind. Regression wird auf grundlegender Ebene verwendet, um die Beziehung zwischen einer abhängigen und einer unabhängigen Variablen zu untersuchen. Da Regressionsstatistiken verwendet werden können, um die abhängige Variable vorherzusagen, wenn die unabhängige Variable bekannt ist, ermöglicht Regression Vorhersagefähigkeiten.
Ansätze zum maschinellen Lernen werden kontinuierlich weiterentwickelt. Für unsere Zwecke werden wir einige der beliebten Ansätze durchgehen, die zum Zeitpunkt der Abfassung verwendet werden.
k-nearest neighbor
Der k-nearest neighbor Algorithmus ist ein Mustererkennungsmodell, das sowohl für Klassifikation als auch für Regression verwendet werden kann. Oft als k-NN abgekürzt, ist das k in k-nearest neighbor eine positive ganze Zahl, die typischerweise klein ist. In der Klassifikation oder Regression besteht die Eingabe aus den k nächsten Trainingsbeispielen innerhalb eines Raums.
Wir werden uns auf die k-NN Klassifikation konzentrieren. In dieser Methode ist die Ausgabe die Klassenmitgliedschaft. Dies weist einem neuen Objekt die Klasse zu, die unter seinen k nächsten Nachbarn am häufigsten ist. Im Fall von k = 1 wird das Objekt der Klasse des einzelnen nächsten Nachbarn zugeordnet.
Lassen Sie uns ein Beispiel für k-nearest neighbor betrachten. Im Diagramm unten gibt es blaue Diamantobjekte und orangefarbene Sternobjekte. Diese gehören zu zwei separaten Klassen: der Diamantklasse und der Sternklasse.

Wenn ein neues Objekt dem Raum hinzugefügt wird — in diesem Fall ein grünes Herz — möchten wir, dass der maschinelle Lernalgorithmus das Herz einer bestimmten Klasse zuordnet.

Wenn wir k = 3 wählen, wird der Algorithmus die drei nächsten Nachbarn des grünen Herzens finden, um es entweder der Diamantklasse oder der Sternklasse zuzuordnen.
In unserem Diagramm sind die drei nächsten Nachbarn des grünen Herzens ein Diamant und zwei Sterne. Daher wird der Algorithmus das Herz der Sternklasse zuordnen.
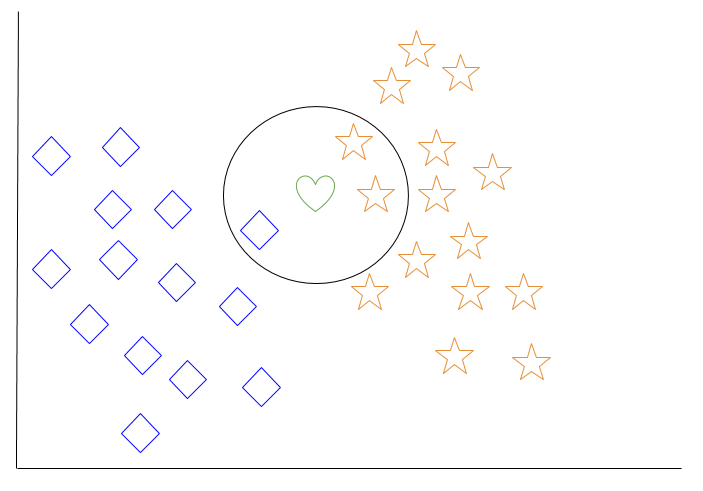
Unter den grundlegendsten maschinellen Lernalgorithmen gilt k-nearest neighbor als eine Art „träges Lernen“, da eine Verallgemeinerung über die Trainingsdaten erst erfolgt, wenn eine Abfrage an das System gestellt wird.
Entscheidungsbaum-Lernen
Zur allgemeinen Verwendung werden Entscheidungsbäume verwendet, um Entscheidungen visuell darzustellen und Entscheidungsfindungsprozesse zu zeigen oder zu informieren. Bei der Arbeit mit maschinellem Lernen und Datenanalyse werden Entscheidungsbäume als Vorhersagemodell verwendet. Diese Modelle ordnen Beobachtungen zu Daten Schlussfolgerungen über den Zielwert der Daten zu.
Das Ziel des Entscheidungsbaum-Lernens ist es, ein Modell zu erstellen, das den Wert eines Ziels basierend auf Eingabevariablen vorhersagen wird.
Im Vorhersagemodell werden die Attribute der Daten, die durch Beobachtung bestimmt werden, durch die Äste dargestellt, während die Schlussfolgerungen über den Zielwert der Daten in den Blättern dargestellt werden.
Beim „Lernen“ eines Baumes wird die Ausgangsdaten in Teilmengen auf der Grundlage eines Attributwerttests unterteilt, der auf jede der abgeleiteten Teilmengen rekursiv wiederholt wird. Sobald die Teilmengen an einem Knoten den gleichen Wert wie ihren Zielwert haben, wird der Rekursionsprozess abgeschlossen sein.
Lassen Sie uns ein Beispiel für verschiedene Bedingungen betrachten, die darüber entscheiden können, ob jemand angeln gehen sollte oder nicht. Dies umfasst Wetterbedingungen sowie barometrische Druckbedingungen.
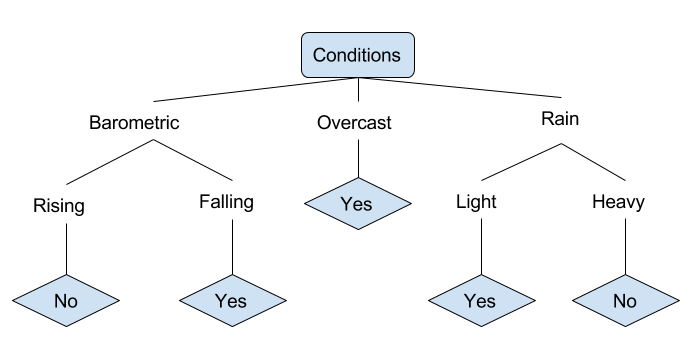
In dem vereinfachten Entscheidungsbaum oben wird ein Beispiel klassifiziert, indem es durch den Baum zum entsprechenden Blattknoten sortiert wird. Dies gibt dann die Klassifizierung zurück, die mit dem bestimmten Blatt verbunden ist, was in diesem Fall entweder ein Ja oder ein Nein ist. Der Baum klassifiziert die Bedingungen eines Tages basierend darauf, ob sie zum Angeln geeignet sind.
A true classification tree data set would have a lot more features than what is outlined above, but relationships should be straightforward to determine. When working with decision tree learning, several determinations need to be made, including what features to choose, what conditions to use for splitting, and understanding when the decision tree has reached a clear ending.
Tiefes Lernen
Tiefes Lernen versucht, nachzuahmen, wie das menschliche Gehirn Licht- und Schallreize in Sehen und Hören verarbeiten kann. Eine Deep-Learning-Architektur ist von biologischen neuronalen Netzwerken inspiriert und besteht aus mehreren Schichten in einem künstlichen neuronalen Netzwerk, das aus Hardware und GPUs besteht.
Tiefes Lernen verwendet eine Kaskade von nichtlinearen Verarbeitungseinheiten-Schichten, um Merkmale (oder Darstellungen) der Daten zu extrahieren oder zu transformieren. Die Ausgabe einer Schicht dient als Eingabe der nachfolgenden Schicht. Im Deep Learning können Algorithmen entweder überwacht sein und dazu dienen, Daten zu klassifizieren, oder unüberwacht sein und Musteranalysen durchführen.
Unter den maschinellen Lernalgorithmen, die derzeit verwendet und entwickelt werden, absorbiert Deep Learning die meisten Daten und konnte bei einigen kognitiven Aufgaben Menschen übertreffen. Aufgrund dieser Eigenschaften hat sich Deep Learning zu einem Ansatz mit bedeutendem Potenzial im Bereich der künstlichen Intelligenz entwickelt
Die Computer Vision und die Spracherkennung haben beide erhebliche Fortschritte durch Deep-Learning-Ansätze erzielt. IBM Watson ist ein bekanntes Beispiel für ein System, das Deep Learning nutzt.
Programmiersprachen
Bei der Auswahl einer Sprache, auf die Sie sich mit maschinellem Lernen spezialisieren möchten, sollten Sie die in aktuellen Stellenanzeigen aufgeführten Fähigkeiten sowie Bibliotheken in verschiedenen Sprachen berücksichtigen, die für maschinelles Lernen verwendet werden können.
Python ist eine der beliebtesten Sprachen für die Arbeit mit maschinellem Lernen aufgrund der vielen verfügbaren Frameworks, darunter TensorFlow, PyTorch und Keras. Als Sprache mit einer lesbaren Syntax und der Möglichkeit, als Skriptsprache verwendet zu werden, erweist sich Python sowohl für die Vorverarbeitung von Daten als auch für die direkte Arbeit mit Daten als leistungsstark und unkompliziert. Die maschinelle Lernbibliothek scikit-learn ist auf mehreren vorhandenen Python-Paketen aufgebaut, mit denen Python-Entwickler möglicherweise bereits vertraut sind, nämlich NumPy, SciPy und Matplotlib.
Um mit Python zu beginnen, können Sie unsere Tutorial-Serie „Wie man in Python 3 kodiert“ lesen oder speziell lesen, wie man „einen maschinellen Lernklassifikator in Python mit scikit-learn erstellt“ oder „wie man neuronales Stiltransfer mit Python 3 und PyTorch durchführt“.
Java wird weit verbreitet in der Unternehmensprogrammierung eingesetzt und wird im Allgemeinen von Entwicklern von Front-End-Desktopanwendungen verwendet, die auch auf Unternehmensebene an maschinellem Lernen arbeiten. Normalerweise ist es nicht die erste Wahl für Anfänger in der Programmierung, die sich mit maschinellem Lernen beschäftigen möchten, wird jedoch von Personen mit Erfahrung in der Java-Entwicklung bevorzugt, um es auf maschinelles Lernen anzuwenden. In Bezug auf maschinelles Lernen in der Industrie wird Java tendenziell häufiger als Python für Netzwerksicherheit verwendet, einschließlich in Anwendungsfällen für Cyberangriffe und Betrugserkennung.
Zu den maschinellen Lernbibliotheken für Java gehören Deeplearning4j, eine Open-Source- und verteilte Deep-Learning-Bibliothek, die sowohl für Java als auch für Scala geschrieben wurde; MALLET (MAchine Learning for LanguagE Toolkit) ermöglicht maschinelles Lernen auf Texten, einschließlich natürlicher Sprachverarbeitung, Themenmodellierung, Dokumentenklassifizierung und Clustering; und Weka, eine Sammlung von maschinellen Lernalgorithmen für Data-Mining-Aufgaben.
C++ is the language of choice for machine learning and artificial intelligence in game or robot applications (including robot locomotion). Embedded computing hardware developers and electronics engineers are more likely to favor C++ or C in machine learning applications due to their proficiency and level of control in the language. Some machine learning libraries you can use with C++ include the scalable mlpack, Dlib offering wide-ranging machine learning algorithms, and the modular and open-source Shark.
Menschliche Vorurteile
Obwohl Daten- und Rechenanalysen uns glauben machen können, dass wir objektive Informationen erhalten, ist dies nicht der Fall; basierend auf Daten bedeutet nicht, dass die Ausgaben des maschinellen Lernens neutral sind. Menschliche Vorurteile spielen eine Rolle dabei, wie Daten gesammelt, organisiert und letztendlich in den Algorithmen verwendet werden, die bestimmen, wie das maschinelle Lernen mit diesen Daten interagieren wird.
Wenn zum Beispiel Menschen Bilder für „Fische“ als Daten zur Schulung eines Algorithmus bereitstellen und diese Menschen überwiegend Bilder von Goldfischen auswählen, könnte ein Computer einen Hai möglicherweise nicht als Fisch klassifizieren. Dies würde eine Voreingenommenheit gegen Haie als Fische schaffen, und Haie würden nicht als Fische gezählt.
Bei der Verwendung historischer Fotografien von Wissenschaftlern als Trainingsdaten könnte ein Computer Wissenschaftler, die auch Menschen mit Farbe oder Frauen sind, möglicherweise nicht ordnungsgemäß klassifizieren. Tatsächlich hat jüngste, peer-reviewed Forschung darauf hingewiesen, dass KI- und maschinelle Lernprogramme menschenähnliche Vorurteile aufweisen, darunter Rassen- und Geschlechtervorurteile. Siehe zum Beispiel „Semantik automatisch aus Sprachkorpora abgeleitet, enthält menschenähnliche Vorurteile“ und „Auch Männer mögen Einkaufen: Reduzierung der Verstärkung von Geschlechtervorurteilen unter Verwendung von Korpus-Level-Beschränkungen“ [PDF].
Da maschinelles Lernen in zunehmendem Maße im Geschäftsbereich eingesetzt wird, können unentdeckte Vorurteile systemische Probleme perpetuieren, die Menschen davon abhalten können, sich für Kredite zu qualifizieren, Anzeigen für gut bezahlte Jobmöglichkeiten zu sehen oder Optionen für eine Lieferung am selben Tag zu erhalten.
Da menschliche Vorurteile andere negativ beeinflussen können, ist es äußerst wichtig, sich dessen bewusst zu sein und auch daran zu arbeiten, sie so weit wie möglich zu eliminieren. Ein Weg, um dies zu erreichen, ist sicherzustellen, dass verschiedene Menschen an einem Projekt arbeiten und dass diverse Personen es testen und überprüfen. Andere haben vorgeschlagen, dass regulatorische Drittparteien Algorithmen überwachen und prüfen, alternative Systeme entwickeln, die Vorurteile erkennen können, und Ethikprüfungen als Teil der Planung von Datenwissenschaftsprojekten durchführen. Das Bewusstsein für Vorurteile zu schärfen, auf unsere eigenen unbewussten Vorurteile zu achten und Gerechtigkeit in unsere maschinellen Lernprojekte und -pipelines einzubauen, kann dazu beitragen, Vorurteile in diesem Bereich zu bekämpfen.

Abschluss
In diesem Tutorial wurden einige Anwendungsfälle des maschinellen Lernens, gängige Methoden und beliebte Ansätze in diesem Bereich, geeignete Programmiersprachen für maschinelles Lernen sowie einige Dinge, die in Bezug auf unbewusste Vorurteile, die in Algorithmen repliziert werden, beachtet werden müssen, überprüft.
Weil maschinelles Lernen ein Bereich ist, der kontinuierlich innoviert wird, ist es wichtig, im Hinterkopf zu behalten, dass sich Algorithmen, Methoden und Ansätze weiterhin ändern werden.
Zusätzlich zum Lesen unserer Anleitungen zu „Wie man einen Machine-Learning-Klassifizierer in Python mit scikit-learn erstellt“ oder „Wie man Neural Style Transfer mit Python 3 und PyTorch durchführt„, können Sie mehr über die Arbeit mit Daten in der Technologiebranche erfahren, indem Sie unsere Datenanalyse-Tutorials lesen.
Source:
https://www.digitalocean.com/community/tutorials/an-introduction-to-machine-learning