













介绍
机器学习是人工智能(AI)的一个子领域。机器学习的一般目标是理解数据的结构,并将该数据拟合到可以被人理解和利用的模型中。
虽然机器学习是计算机科学的一个领域,但它与传统的计算方法不同。在传统的计算中,算法是一组显式编程指令,用于计算或解决问题。相反,机器学习算法允许计算机根据数据输入进行训练,并使用统计分析来输出落在特定范围内的值。因此,机器学习有助于计算机根据样本数据构建模型,以基于数据输入自动化决策过程。
今天任何技术用户都从机器学习中受益。面部识别技术使社交媒体平台能够帮助用户标记并分享朋友的照片。光学字符识别(OCR)技术将文本图像转换为可移动类型。由机器学习驱动的推荐引擎根据用户喜好建议下一步要观看的电影或电视节目。依赖机器学习进行导航的自动驾驶汽车可能很快就会面向消费者。
机器学习是一个不断发展的领域。因此,在使用机器学习方法或分析机器学习过程的影响时,有一些考虑因素需要记在心中。
在本教程中,我们将深入探讨监督学习和无监督学习这两种常见的机器学习方法,以及机器学习中常见的算法方法,包括K最近邻算法、决策树学习和深度学习。我们将探讨在机器学习中最常用的编程语言,并为您提供每种语言的一些优点和缺点。此外,我们还将讨论由机器学习算法所固有的偏见,并考虑在构建算法时如何防止这些偏见。
机器学习方法
在机器学习中,任务通常被归类为广泛的类别。这些类别是基于学习是如何被接收的,或者反馈学习如何被提供给所开发系统的。
最广泛采用的两种机器学习方法是监督学习,它根据人类标记的示例输入和输出数据来训练算法,以及无监督学习,它不提供标记数据给算法,以便让算法在输入数据中发现结构。让我们更详细地探讨这些方法。
监督学习
在监督学习中,计算机提供带有其期望输出标签的示例输入。该方法的目的是通过将其实际输出与“教授”的输出进行比较以找到错误,并相应地修改模型,从而使算法能够“学习”。因此,监督学习使用模式来预测附加的未标记数据上的标签值。
例如,在监督学习中,算法可以被馈送带有标记为fish的鲨鱼图像数据和标记为water的海洋图像数据。通过对这些数据进行训练,监督学习算法应该能够稍后将未标记的鲨鱼图像识别为fish,未标记的海洋图像识别为water。
A common use case of supervised learning is to use historical data to predict statistically likely future events. It may use historical stock market information to anticipate upcoming fluctuations, or be employed to filter out spam emails. In supervised learning, tagged photos of dogs can be used as input data to classify untagged photos of dogs.
无监督学习
在无监督学习中,数据未标记,因此学习算法被留给在其输入数据中找到共同点。由于未标记数据比标记数据更丰富,因此促进无监督学习的机器学习方法尤其有价值。
无监督学习的目标可能就是发现数据集中的隐藏模式,但它也可能有特征学习的目标,这使得计算机可以自动发现分类原始数据所需的表示。
无监督学习通常用于交易数据。您可能有一个包括客户及其购买记录的大型数据集,但作为人类,您可能无法理解从客户资料和其购买类型中可以得出什么相似属性。将这些数据输入无监督学习算法后,可能会确定某个特定年龄段的女性购买无香皂的可能是怀孕,因此可以针对这个受众展开与怀孕和婴儿产品相关的营销活动,以增加其购买数量。
在没有被告知“正确”答案的情况下,无监督学习方法可以查看更广泛且看似无关的复杂数据,以便以潜在有意义的方式进行组织。无监督学习通常用于异常检测,包括欺诈信用卡交易,以及推荐系统,推荐下一步购买什么产品。在无监督学习中,未标记的狗照片可以作为输入数据,供算法找到相似之处并将狗照片分类在一起。
方法
作为一项领域,机器学习与计算统计密切相关,因此具备统计学背景知识对理解和利用机器学习算法很有帮助。
对于那些可能没有学过统计学的人来说,首先定义相关性和回归可能是有帮助的,因为它们是用于研究定量变量之间关系的常用技术。相关性是衡量两个未被指定为因变量或自变量的变量之间关联程度的指标。回归在基本水平上用于检查一个因变量和一个自变量之间的关系。由于回归统计可以用于在已知自变量时预测因变量,回归使得具备了预测能力。
机器学习方法不断发展。针对我们的目的,我们将介绍一些在撰写时正在使用的流行机器学习方法。
k-nearest neighbor
最近邻算法是一种模式识别模型,可用于分类和回归。通常缩写为 k-NN,最近邻中的 k 是一个正整数,通常较小。在分类或回归中,输入将包括空间内 k 个最接近的训练示例。
我们将重点介绍 k-NN 分类。在这种方法中,输出是类成员资格。这将把新对象分配给其 k 个最近邻中最常见的类。在 k = 1 的情况下,该对象被分配给单个最近邻的类。
让我们来看一个k最近邻的例子。在下面的图表中,有蓝色的菱形物体和橙色的星形物体。它们属于两个不同的类别:菱形类和星形类。

当一个新物体被添加到空间中——在这种情况下是一个绿色的心形——我们希望机器学习算法将心形分类到某个类别。

当我们选择k = 3时,算法将找到绿色心形的三个最近邻居,以便将其分类到菱形类或星形类。
在我们的图表中,绿色心形的三个最近邻居分别是一个菱形和两个星形。因此,算法将心形分类为星形类。
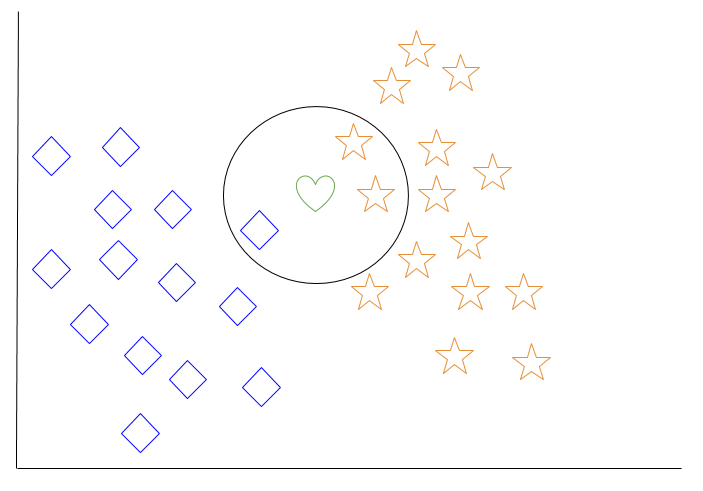
在最基本的机器学习算法中,k最近邻被认为是一种“懒惰学习”,因为除非对系统进行查询,否则不会对训练数据进行泛化。
决策树学习
在一般情况下,决策树被用来直观地表示决策并展示或通知决策制定。在机器学习和数据挖掘中,决策树被用作预测模型。这些模型将关于数据的观察映射到关于数据目标值的结论。
决策树学习的目标是创建一个模型,根据输入变量预测目标的值。
在预测模型中,通过观察确定的数据属性由分支表示,而关于数据目标值的结论则表示在叶子节点。
在“学习”树时,源数据根据属性值测试被划分为子集,这个过程在每个派生子集上递归重复进行。一旦节点上的子集具有与其目标值相等的值,递归过程将完成。
让我们看一个确定某人是否应该去钓鱼的各种条件的例子。这包括天气条件以及气压条件。
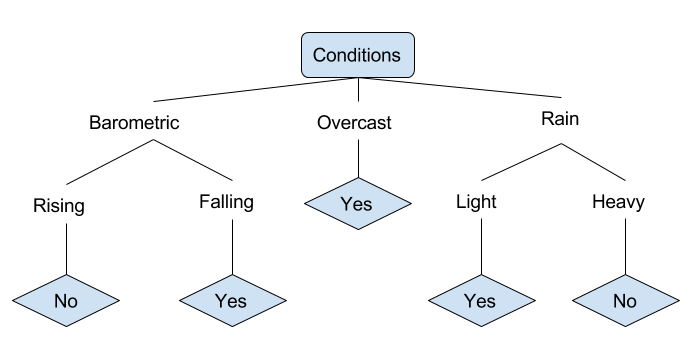
在上面简化的决策树中,通过将示例通过树分类到适当的叶节点来对其进行分类。然后返回与特定叶节点相关联的分类,这种情况下可能是一个是或否。根据一天的条件,树对是否适合去钓鱼进行分类。
A true classification tree data set would have a lot more features than what is outlined above, but relationships should be straightforward to determine. When working with decision tree learning, several determinations need to be made, including what features to choose, what conditions to use for splitting, and understanding when the decision tree has reached a clear ending.
深度学习
深度学习试图模仿人类大脑如何将光和声音刺激处理成视觉和听觉。深度学习架构受生物神经网络启发,由多个层次组成,在硬件和GPU组成的人工神经网络中进行。
深度学习使用一系列非线性处理单元层级,以提取或转换数据的特征(或表示)。一个层的输出作为后续层的输入。在深度学习中,算法可以是监督的,用于对数据进行分类,也可以是无监督的,用于执行模式分析。
在当前正在使用和开发的机器学习算法中,深度学习吸收了最多的数据,并且已经在某些认知任务中击败了人类。由于这些特性,深度学习已成为人工智能领域具有重大潜力的方法之一。
计算机视觉和语音识别都从深度学习方法中实现了显著进步。IBM Watson是一个利用深度学习的系统的知名示例。
编程语言
在选择一种专业化的机器学习语言时,您可能希望考虑当前工作广告中列出的技能,以及各种语言中可用于机器学习流程的库。
Python是最受欢迎的语言之一,用于机器学习工作,因为有许多可用的框架,包括TensorFlow、PyTorch和Keras。作为一种具有可读性语法并且能够用作脚本语言的语言,Python被证明在预处理数据和直接处理数据方面都是强大且直观的。scikit-learn机器学习库是建立在几个现有的Python包之上的,Python开发人员可能已经熟悉,即NumPy、SciPy和Matplotlib。
要开始使用Python,您可以阅读我们的教程系列“如何在Python 3中编码”,或者专门阅读“如何使用scikit-learn在Python中构建机器学习分类器”或“如何使用Python 3和PyTorch执行神经风格转移”。
Java在企业编程中被广泛使用,通常由同时从事机器学习的前端桌面应用程序开发人员使用。通常情况下,对于那些想要学习机器学习的编程新手来说,Java不是首选,但对于具有Java开发背景的人来说,它是应用于机器学习的首选语言。在工业界的机器学习应用方面,相对于Python,Java更常用于网络安全,包括网络攻击和欺诈检测等用例。
Java的机器学习库包括Deeplearning4j,一个为Java和Scala编写的开源分布式深度学习库;MALLET(MAchine Learning for LanguagE Toolkit),用于文本机器学习应用,包括自然语言处理、主题建模、文档分类和聚类;以及Weka,一个用于数据挖掘任务的机器学习算法集合。
C++ is the language of choice for machine learning and artificial intelligence in game or robot applications (including robot locomotion). Embedded computing hardware developers and electronics engineers are more likely to favor C++ or C in machine learning applications due to their proficiency and level of control in the language. Some machine learning libraries you can use with C++ include the scalable mlpack, Dlib offering wide-ranging machine learning algorithms, and the modular and open-source Shark.
人类偏见
尽管数据和计算分析可能使我们认为我们正在接收客观信息,但事实并非如此;基于数据并不意味着机器学习的输出是中立的。人类偏见在数据收集、整理以及最终确定机器学习如何与数据交互的算法中起着作用。
例如,如果人们提供“鱼”作为训练算法的数据图像,并且这些人绝大多数选择金鱼的图像,那么计算机可能不会将鲨鱼归类为鱼。这将导致对鲨鱼作为鱼的偏见,鲨鱼将不被视为鱼类。
当使用历史照片作为科学家的训练数据时,计算机可能无法正确分类肤色或女性科学家。事实上,最近的同行评审研究表明,人工智能和机器学习程序表现出类似人类的偏见,包括种族和性别偏见。例如,请参阅“从语料库自动推导出的语义包含类似人类的偏见”和“男性也喜欢购物:使用语料库级别约束减少性别偏见放大”[PDF]。
随着机器学习在业务中的应用越来越广泛,未被发现的偏见可能会持续存在系统性问题,这可能会导致人们无法获得贷款资格,无法看到高薪工作机会的广告,或无法获得当天送货选项。
由于人类偏见可能会对他人产生负面影响,因此非常重要的是意识到这一点,并尽可能地努力消除它。实现这一目标的一种方式是确保项目中有多样化的人员参与,并且多样化的人员进行测试和审核。其他人呼吁监管第三方对算法进行监控和审计,构建可以检测偏见的替代系统,以及将伦理审查纳入数据科学项目规划。提高对偏见的认识,注意我们自己的无意识偏见,并在我们的机器学习项目和流程中构建公平性,可以帮助我们应对这一领域的偏见。

结论
本教程回顾了机器学习的一些用例,该领域常用的方法和流行的方法,适用的机器学习编程语言,并介绍了一些需要注意的事项,即无意识偏见在算法中得以复制。
由于机器学习是一个不断创新的领域,重要的是要记住算法、方法和途径将继续变化。
除了阅读我们的教程“如何使用scikit-learn在Python中构建机器学习分类器”或“如何使用Python 3和PyTorch执行神经风格转移”,您还可以通过阅读我们的数据分析教程来了解更多有关在技术行业中处理数据的信息。
Source:
https://www.digitalocean.com/community/tutorials/an-introduction-to-machine-learning