













紹介
機械学習は人工知能(AI)の一部門です。機械学習の一般的な目標は、データの構造を理解し、そのデータを人々が理解して利用できるモデルに適合させることです。
機械学習はコンピュータサイエンスの一部門ですが、従来の計算アプローチとは異なります。従来のコンピューティングでは、アルゴリズムは明示的にプログラムされた命令のセットであり、コンピュータが計算や問題解決に使用します。一方、機械学習アルゴリズムでは、コンピュータがデータ入力で訓練し、統計分析を使用して特定の範囲内の値を出力することができます。このため、機械学習はサンプルデータからモデルを構築し、データ入力に基づいて意思決定プロセスを自動化するのに役立ちます。
今日のどの技術ユーザーも機械学習の恩恵を受けています。顔認識技術により、ソーシャルメディアプラットフォームはユーザーが友達の写真にタグ付けして共有するのを支援します。光学文字認識(OCR)技術は、テキストの画像を可動式のタイプに変換します。機械学習によって推進される推薦エンジンは、ユーザーの好みに基づいて次に視聴すべき映画やテレビ番組を提案します。機械学習を利用してナビゲートする自動運転車は、まもなく消費者に提供されるかもしれません。
機械学習は絶えず発展している分野です。そのため、機械学習手法を扱ったり、機械学習プロセスの影響を分析したりする際に考慮すべき点がいくつかあります。
このチュートリアルでは、教師あり学習と教師なし学習の一般的な機械学習手法や、k最近傍法、決定木学習、深層学習などの機械学習の一般的なアルゴリズムアプローチについて調査します。また、機械学習で最も使用されているプログラミング言語とその利点や欠点についても検討します。さらに、機械学習アルゴリズムによって永続化されるバイアスについて議論し、アルゴリズムを構築する際にこれらのバイアスを防ぐために考慮すべき点についても考えます。
機械学習手法
機械学習では、一般的にタスクは広範なカテゴリに分類されます。これらのカテゴリは、学習がどのように受け取られるか、または学習に関するフィードバックがどのようにシステムに与えられるかに基づいています。
最も広く採用されている2つの機械学習手法は、人間によってラベル付けされた例の入力と出力データに基づいてアルゴリズムを訓練する教師あり学習と、ラベルの付いていないデータをアルゴリズムに提供して、入力データ内の構造を見つけることを許可する教師なし学習です。これらの方法を詳しく調査してみましょう。教師あり学習とは、人間によってラベル付けされた例の入力と出力データに基づいてアルゴリズムを訓練する手法であり、教師なし学習は、アルゴリズムにラベルのないデータを提供して、入力データ内の構造を見つけることを許可する手法です。これらの手法を詳しく見てみましょう。
教師付き学習
教師付き学習では、コンピューターに望ましい出力とラベル付けされた例の入力が提供されます。この方法の目的は、アルゴリズムが実際の出力と「教えられた」出力を比較してエラーを見つけ、モデルを修正できるようにすることです。したがって、教師付き学習はパターンを使用して追加の未ラベルデータのラベル値を予測します。
たとえば、教師付き学習では、アルゴリズムに、サメの画像が魚としてラベル付けされ、海の画像が水としてラベル付けされたデータを提供することができます。このデータでトレーニングされることで、教師付き学習アルゴリズムは後で未ラベルのサメの画像を魚として、未ラベルの海の画像を水として識別できるはずです。
A common use case of supervised learning is to use historical data to predict statistically likely future events. It may use historical stock market information to anticipate upcoming fluctuations, or be employed to filter out spam emails. In supervised learning, tagged photos of dogs can be used as input data to classify untagged photos of dogs.
教師なし学習
教師なし学習では、データにはラベルが付いていないため、学習アルゴリズムは入力データの共通点を見つけることになります。ラベルが付いていないデータはラベルが付いているデータよりも豊富なので、教師なし学習を促進する機械学習手法は特に価値があります。
教師なし学習の目標は、データセット内の隠れたパターンを発見するという点で単純かもしれませんが、特徴学習の目標もあります。これにより、計算機は自動的に、生データを分類するために必要な表現を発見できます。
教師なし学習は、取引データに一般的に使用されます。顧客とその購入品の大規模なデータセットがあるかもしれませんが、人間としては、顧客プロファイルや購入品の種類からどのような類似した属性が引き出されるかを理解するのは難しいでしょう。このデータを教師なし学習アルゴリズムにフィードすると、特定の年齢層の女性が無香料の石鹸を購入することから、彼らが妊娠している可能性が高いことが判明し、したがって妊娠と赤ちゃんの商品に関連したマーケティングキャンペーンがこの対象客にターゲットされ、購入数が増加する可能性があります。
「正しい」答えを教えられないまま、教師なし学習手法は、より広範で見かけ上関連性のない複雑なデータを見て、それを潜在的に意味のある方法で整理することができます。教師なし学習は、詐欺クレジットカード取引の異常検知や、次に何を購入するかを推奨するレコメンデーションシステムなどによく使用されます。教師なし学習では、犬のタグのない写真をアルゴリズムの入力データとして使用して、類似点を見つけて犬の写真を分類することができます。
アプローチ
機械学習は、計算統計学と密接に関連しており、統計学のバックグラウンド知識を持つことは、機械学習アルゴリズムを理解し活用するために役立ちます。
統計学を学んでいない人々にとっては、まず相関と回帰を定義することが役立ちます。これらは、量的変数の関係を調査するためによく使用される技術です。相関は、依存変数または独立変数として指定されていない2つの変数間の関連性の尺度です。回帰は、基本レベルでは1つの依存変数と1つの独立変数の関係を調べるために使用されます。回帰統計は、独立変数が既知の場合に依存変数を予測する能力を提供するため、予測能力を可能にします。
機械学習のアプローチは、継続的に開発されています。ここでは、執筆時点で使用されているいくつかの人気のあるアプローチをいくつか紹介します。
k-nearest neighbor
k最近傍法は、分類および回帰に使用できるパターン認識モデルです。一般的にk-NNと略され、k最近傍法のkは通常小さい正の整数です。分類または回帰のいずれかの場合でも、入力は空間内のk個の最も近いトレーニング例で構成されます。
ここでは、k-NN分類に焦点を当てます。この方法では、出力はクラスのメンバーシップです。これにより、新しいオブジェクトは、そのk個の最近傍の中で最も一般的なクラスに割り当てられます。k = 1の場合、オブジェクトは単一の最近傍のクラスに割り当てられます。
k-最近傍法の例を見てみましょう。下の図では、青のダイヤモンドのオブジェクトとオレンジの星のオブジェクトがあります。これらは2つの異なるクラスに属しています:ダイヤモンドクラスとスタークラス。

新しいオブジェクトがスペースに追加されるとき、この場合は緑のハートが、機械学習アルゴリズムがハートを特定のクラスに分類することを望むでしょう。

k = 3を選択すると、アルゴリズムは緑のハートの3つの最近傍を見つけて、それをダイヤモンドクラスまたはスタークラスに分類します。
図では、緑のハートの3つの最近傍は1つのダイヤモンドと2つの星です。したがって、アルゴリズムはハートをスタークラスで分類します。
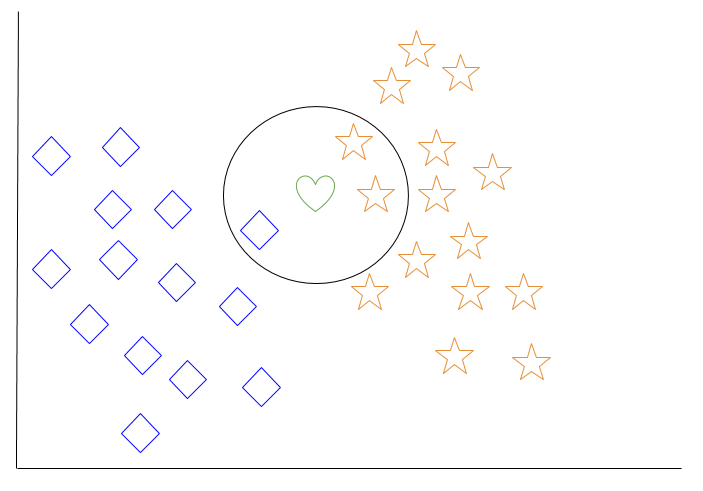
機械学習アルゴリズムの中でも、k-最近傍法は「怠惰な学習」と見なされており、トレーニングデータを超えた一般化は、システムにクエリが行われるまで発生しません。
決定木学習
一般的な使用では、決定木は意思決定を視覚的に表現し、意思決定を示したり、通知したりするために使用されます。機械学習やデータマイニングを行う際には、決定木が予測モデルとして使用されます。これらのモデルは、データに関する観察結果をデータのターゲット値に関する結論にマップします。
決定木学習の目標は、入力変数に基づいてターゲットの値を予測するモデルを作成することです。
予測モデルでは、観察によって決定されたデータの属性は枝で表され、データの目標値に関する結論は葉に表されます。
ツリーを「学習」する際、ソースデータは属性値テストに基づいてサブセットに分割され、それぞれの派生したサブセットで再帰的に繰り返されます。ノードのサブセットがその目標値と同等の値を持つと、再帰プロセスは完了します。
釣りに行くべきかどうかを決定するさまざまな条件の例を見てみましょう。これには天候条件や気圧条件が含まれます。
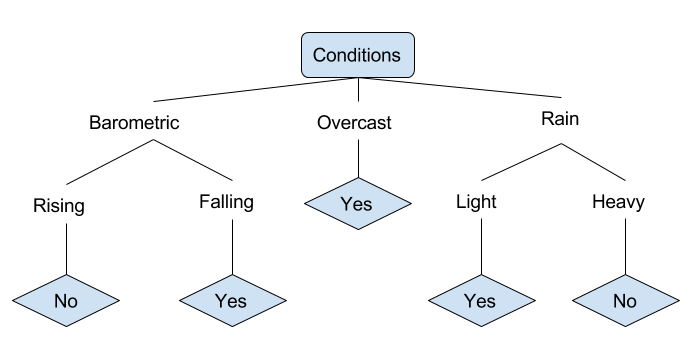
上記の簡略化された決定木では、例は木を通して適切な葉ノードに分類されます。これにより、特定の葉に関連付けられた分類が返されます。この場合、YesまたはNoです。この木は、釣りに適しているかどうかを基準に、1日の状況を分類します。
A true classification tree data set would have a lot more features than what is outlined above, but relationships should be straightforward to determine. When working with decision tree learning, several determinations need to be made, including what features to choose, what conditions to use for splitting, and understanding when the decision tree has reached a clear ending.
ディープラーニング
ディープラーニングは、人間の脳が光や音の刺激をビジョンや聴覚に処理する方法を模倣しようとします。ディープラーニングアーキテクチャは、生物学的なニューラルネットワークに触発されており、ハードウェアとGPUで構成された人工ニューラルネットワーク内の複数の層で構成されています。
深層学習は、データの特徴(または表現)を抽出または変換するために非線形処理ユニットレイヤーのカスケードを使用します。1つのレイヤーの出力は、次のレイヤーの入力として機能します。深層学習では、アルゴリズムはデータを分類するための教師ありであるか、パターン分析を実行するための教師なしであるかのいずれかになります。
現在使用されているおよび開発されている機械学習アルゴリズムの中で、深層学習は最も多くのデータを吸収し、一部の認知タスクで人間を打ち負かすことができました。これらの特性のため、深層学習は人工知能領域で大きなポテンシャルを持つアプローチとなっています。
コンピュータビジョンと音声認識は、ともに深層学習アプローチから重要な進歩を遂げています。IBM Watsonは、深層学習を活用するシステムのよく知られた例です。
プログラミング言語
機械学習に特化した言語を選択する際には、現在の求人広告に記載されているスキルと、機械学習プロセスに使用できるさまざまな言語のライブラリを考慮することが望ましいかもしれません。
Pythonは、TensorFlow、PyTorch、およびKerasなど、多くの利用可能なフレームワークがあるため、機械学習との作業に最も人気のある言語の一つです。読みやすい構文を持ち、スクリプト言語として使用する能力があるため、Pythonはデータの前処理や直接データを扱うために強力でわかりやすいと証明されています。scikit-learn機械学習ライブラリは、Python開発者がすでに馴染みのあるいくつかの既存のPythonパッケージをベースに構築されています。それらはNumPy、SciPy、およびMatplotlibです。
Pythonを始めるには、「Python 3でコーディングする方法」のチュートリアルシリーズを読んだり、「scikit-learnを使用してPythonで機械学習分類器を構築する方法」や「Python 3とPyTorchを使用したニューラルスタイル転送の実行方法」について特に読むことができます。
Javaは企業プログラミングで広く使用されており、一般的には機械学習を企業レベルで行うフロントエンドデスクトップアプリケーション開発者によって使用されます。通常、プログラミングの初心者が機械学習を学びたい場合には最初の選択肢ではありませんが、Java開発のバックグラウンドを持つ人々には機械学習に適用するために好まれます。産業界における機械学習の応用に関しては、JavaがPythonよりもネットワークセキュリティにおいて、サイバー攻撃や不正検出のユースケースを含めて、より多く使用される傾向があります。
Java向けの機械学習ライブラリには、Deeplearning4j(JavaとScalaの両方に対応したオープンソースかつ分散型のディープラーニングライブラリ)、MALLET(MAchine Learning for LanguagE Toolkit、テキスト上での自然言語処理、トピックモデリング、文書分類、クラスタリングなどの機械学習アプリケーションを可能にする)、そしてWeka(データマイニングタスクに使用する機械学習アルゴリズムのコレクション)があります。
C++ is the language of choice for machine learning and artificial intelligence in game or robot applications (including robot locomotion). Embedded computing hardware developers and electronics engineers are more likely to favor C++ or C in machine learning applications due to their proficiency and level of control in the language. Some machine learning libraries you can use with C++ include the scalable mlpack, Dlib offering wide-ranging machine learning algorithms, and the modular and open-source Shark.
人間の偏見
データと計算解析が客観的な情報を提供していると考えるかもしれませんが、実際にはそうではありません。データに基づいているからと言って、機械学習の出力が中立であるとは限りません。人間の偏見は、データの収集や整理、そして最終的には機械学習がそのデータとどのように相互作用するかを決定するアルゴリズムに影響を与えます。
例えば、人々がアルゴリズムを訓練するためのデータとして「魚」の画像を提供している場合、これらの人々が圧倒的に金魚の画像を選択していると、コンピューターはサメを魚として分類しないかもしれません。これにより、サメが魚として数えられなくなる偏見が生まれます。
歴史的な科学者の写真を訓練データとして使用する場合、コンピューターは肌の色が黒人や女性である科学者を適切に分類しないかもしれません。実際、最近の査読付き研究によると、AIや機械学習プログラムは人種や性別の偏見を含む人間のような偏見を示しています。たとえば、”言語コーパスから自動的に派生した意味には人間のような偏見が含まれています“や”男性もショッピングが好き:コーパスレベルの制約を使用して性別バイアスの増幅を減らす“などの研究が挙げられます [PDF]。
機械学習がビジネスでますます活用される中、見逃された偏見は、ローンの資格が得られない、高給の仕事の機会が示されない、または即日配達のオプションを受け取れないなど、制度的な問題を持続させる可能性があります。
人間の偏見が他者に悪影響を与える可能性があるため、それに気づくことと、できるだけそれを排除する努力をすることは非常に重要です。これを実現する方法の一つは、プロジェクトに多様な人々が参加し、多様な人々がそれをテストしてレビューすることを確認することです。他の人々は、規制当局の第三者にアルゴリズムを監視および審査させること、偏見を検出できる代替システムを構築すること、およびデータサイエンスプロジェクト計画の一環として倫理的なレビューを求めています。偏見についての認識を高め、自分自身の無意識の偏見に気を配り、機械学習プロジェクトやパイプラインでの公平性を構築することは、この分野での偏見と戦うために役立ちます。

結論
このチュートリアルでは、機械学習のユースケース、分野で使用される一般的な方法と人気のあるアプローチ、適切な機械学習プログラミング言語をいくつか紹介し、アルゴリズムに無意識の偏見が再現される点についてもいくつかの注意事項をカバーしました。
機械学習は常に革新されている分野であるため、アルゴリズム、方法、アプローチが変わり続けることを念頭に置くことが重要です。
さらに、「Pythonとscikit-learnを使用して機械学習分類器を構築する方法」や「Python 3とPyTorchを使用したニューラルスタイル転送の実行方法」などのチュートリアルを読むだけでなく、テクノロジー業界でのデータ処理についても、弊社のデータ分析チュートリアルを読むことで学ぶことができます。
Source:
https://www.digitalocean.com/community/tutorials/an-introduction-to-machine-learning