













Сначала мы рассмотрим, что такое Redis и его использование, а также почему он подходит для современных сложных микросервисных приложений. Мы поговорим о том, как Redis поддерживает хранение нескольких форматов данных для различных целей с помощью своих модулей. Затем мы увидим, как Redis, как база данных в памяти, может сохранять данные и восстанавливаться после потери данных. Мы также поговорим о том, как Redis оптимизирует затраты на хранение памяти с помощью Redis on Flash.
Затем мы увидим очень интересные примеры масштабирования Redis и его репликации по нескольким географическим регионам. Наконец, поскольку одной из самых популярных платформ для запуска микросервисов является Kubernetes, а запуск состоятельных приложений в Kubernetes немного сложен, мы увидим, как легко запустить Redis на Kubernetes.
Что такое Redis?
Redis, что на самом деле означает Remote Dictionary Server, является базой данных в памяти. Многие люди использовали его в качестве кэша поверх других баз данных для улучшения производительности приложения. Однако то, о чем многие не знают, это то, что Redis является полноценной основной базой данных, которая может использоваться для хранения и сохранения нескольких форматов данных для сложных приложений.
Пример сложного приложения социальных медиа
Давайте рассмотрим обычную настройку для приложения на основе микросервисов. Предположим, у нас есть сложное приложение социальной сети с миллионами пользователей. И предположим, что наше приложение на микросервисах использует реляционную базу данных, такую как MySQL, для хранения данных. Кроме того, поскольку мы ежедневно собираем тонны данных, у нас есть база данных Elasticsearch для быстрого фильтрации и поиска данных.
Теперь пользователи все связаны друг с другом, поэтому нам нужна графовая база данных для представления этих связей. Плюс, в нашем приложении много медиа-контента, которым пользователи делятся друг с другом ежедневно, и для этого у нас есть документная база данных. Наконец, для лучшей производительности приложения у нас есть кеш-сервис, который кэширует данные из других баз данных и делает их доступными быстрее.
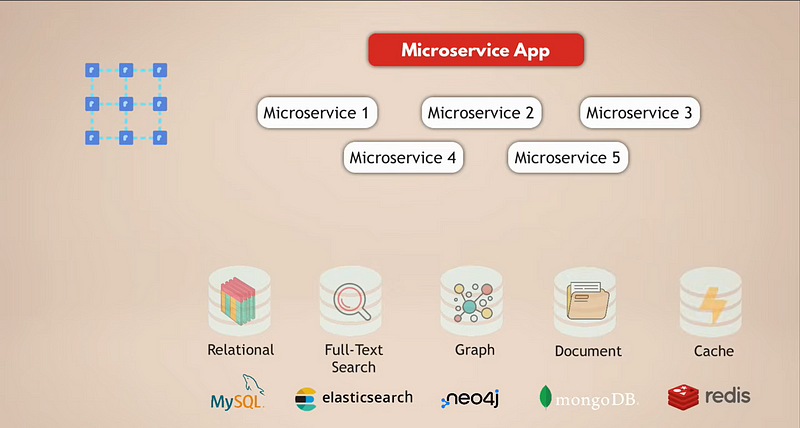
Теперь очевидно, что это довольно сложная настройка. Давайте посмотрим, каковы проблемы этой настройки:
1. Развертывание и обслуживание
Все эти сервисы данных необходимо развернуть, запускать и поддерживать. Это означает, что вашей команде нужно иметь какую-то степень знаний о том, как управлять всеми этими сервисами данных.
2. Масштабирование и требования к инфраструктуре
Для высокой доступности и лучшей производительности вы захотите масштабировать свои сервисы. Каждый из этих сервисов данных масштабируется по-разному и имеет разные требования к инфраструктуре, и это может стать дополнительной проблемой. Таким образом, в целом использование нескольких сервисов данных для вашего приложения увеличивает затраты на обслуживание всей настройки вашего приложения.
3. Затраты на облачные услуги
Конечно, в качестве более простой альтернативы запуску и управлению службами самостоятельно вы можете использовать управляемые службы данных от облачных провайдеров. Но это может быть очень дорого, потому что на облачных платформах вы платите за каждую управляемую службу данных отдельно.
4. Сложность разработки
5. Большая задержка
Почему Redis упрощает эту сложность
В сравнении с многорежимной базой данных, такой как Redis, вы решаете большинство этих проблем:
- Одна служба данных. Вы запускаете и поддерживаете только одну службу данных. Таким образом, ваше приложение также должно общаться только с одним хранилищем данных, что означает только один программный интерфейс для этой службы данных.
- Снижение задержки. Задержка будет снижена за счет перехода к одной конечной точке данных и устранения нескольких внутренних сетевых переходов.
- Несколько типов данных в одном. Имея одну базу данных, такую как Redis, которая позволяет вам хранить различные типы данных (т. е. несколько типов баз данных в одной) а также выступать в качестве кэша, решает такие проблемы.
Как Redis поддерживает несколько форматов данных
Итак, давайте посмотрим, как Redis на самом деле работает. Прежде всего, как Redis поддерживает несколько форматов данных в одной базе данных?
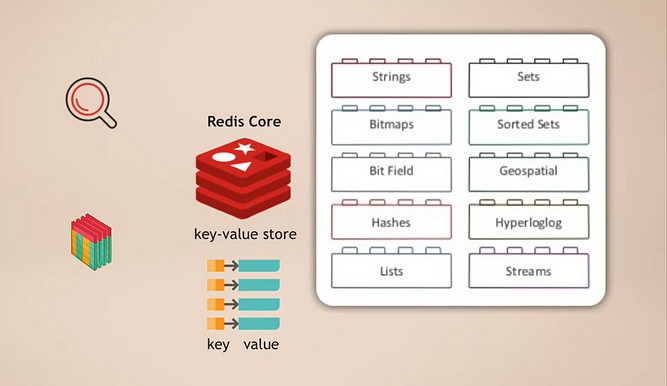
Ядро Redis и модули
Суть заключается в том, что у вас есть Redis core, который является хранилищем ключ-значение и уже поддерживает хранение различных типов данных. Затем вы можете расширить этот ядро с помощью так называемых модулей для различных типов данных, которые ваше приложение нуждается для разных целей. Например:
- RedisSearch для функциональности поиска (как Elasticsearch)
- RedisGraph для хранения графовых данных
Одним из преимуществ является то, что это модульно. Эти различные типы функциональности базы данных не тесно интегрированы в одну базу данных, как во многих других мультимодальных базах данных, а скорее, вы можете выбирать и выбирать точно ту функциональность сервиса данных, которая вам нужна для вашего приложения, а затем в основном добавить этот модуль.
Встроенное кэширование
И, конечно, используя Redis в качестве основной базы данных, вам не нужен дополнительный кэш, потому что у вас это автоматически из коробки с Redis. Это означает, снова, меньшую сложность в вашем приложении, потому что вам не нужно реализовывать логику управления, заполнения и инвалидации кэша.
Высокая производительность и более быстрое тестирование
Наконец, как база данных в памяти, Redis работает очень быстро и эффективно, что, конечно, делает само приложение быстрее. Кроме того, это также ускоряет выполнение тестов приложения, поскольку Redis не требуется схема, как у других баз данных. Поэтому перед запуском тестов не нужно инициализировать базу данных, создавать схему и т. д. Можно начинать с пустой базы данных Redis каждый раз и создавать данные для тестов по мере необходимости. Быстрые тесты могут действительно повысить вашу производительность в разработке.
Сохранение данных в Redis
Мы разобрались, как работает Redis и все его преимущества. Но сейчас вы, возможно, задаетесь вопросом: Как база данных в памяти может сохранять данные? Ведь если процесс Redis или сервер, на котором работает Redis, выйдет из строя, все данные в памяти пропадут, верно? И если я потеряю данные, как их восстановить? То есть, как мне быть уверенным, что мои данные в безопасности?
Самый простой способ резервного копирования данных – это репликация Redis. Таким образом, если основной экземпляр Redis выйдет из строя, реплики все еще будут работать и иметь все данные. Если у вас есть реплицированный Redis, реплики будут иметь данные. Но, конечно, если все экземпляры Redis выйдут из строя, вы потеряете данные, потому что не останется ни одной реплики.
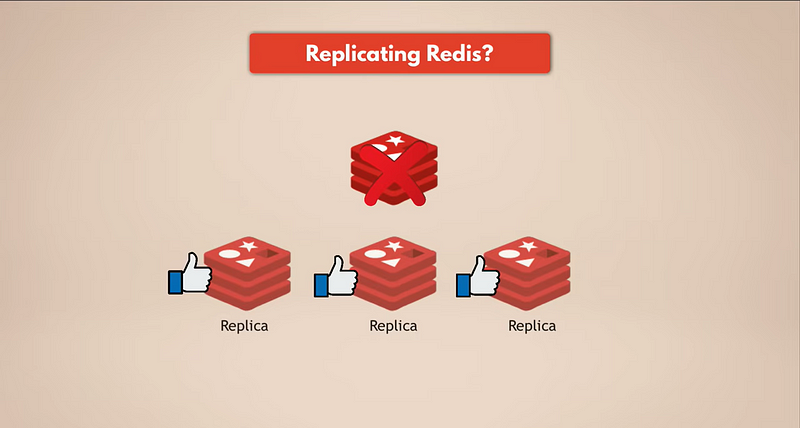
Нам нужна настоящая устойчивость.
Снимок (RDB)
Redis имеет несколько механизмов для сохранения данных и обеспечения их безопасности. Первый из них – это снимки, которые можно настроить в зависимости от времени, количества запросов и т. д. Снимки ваших данных будут сохранены на диске, с помощью которого вы сможете восстановить данные, если весь база данных Redis исчезнет. Но обратите внимание, что вы потеряете последние минуты данных, поскольку обычно создается снимок каждые пять минут или час, в зависимости от ваших потребностей.
AOF (Append Only File)
В качестве альтернативы Redis использует что-то называемое AOF, что означает Append Only File. В этом случае каждое изменение сохраняется на диске для постоянного хранения. При перезапуске Redis или после сбоя Redis воспроизведет журналы файлов Append Only File для восстановления состояния. Таким образом, AOF более надежен, но может работать медленнее, чем создание снимков.
Комбинация снимков и AOF
И, конечно же, можно также использовать комбинацию AOF и снимков, где файл с добавлением сохраняет данные из памяти на диск непрерывно, плюс у вас есть регулярные снимки, чтобы сохранить состояние данных на случай необходимости их восстановления. Это означает, что даже если сама база данных Redis или серверы, на которых работает Redis, все откажут, у вас все равно будут сохранены все ваши данные, и вы сможете легко воссоздать и перезапустить новую базу данных Redis со всеми данными.
Где находится это постоянное хранилище?
Очень интересный вопрос: где находится это постоянное хранилище? Где находится тот диск, на котором хранятся ваши снимки и журналы файлов с добавлением? Находятся ли они на тех же серверах, где работает Redis?
Этот вопрос фактически ведет нас к тенденции или лучшей практике сохранения данных в облачных средах, которая заключается в том, что всегда лучше разделять сервера, на которых запускаются ваши приложения и службы данных, от постоянного хранилища, в котором хранятся ваши данные.
С конкретным примером: если ваши приложения и службы запускаются в облаке, скажем, на экземпляре AWS EC2, вам следует использовать EBS или Elastic Block Storage для сохранения ваших данных, вместо их хранения на жестком диске экземпляра EC2. Потому что если этот экземпляр EC2 выйдет из строя, у вас не будет доступа к его хранилищу, будь то ОЗУ или дисковое хранилище или что угодно. Поэтому, если вам нужна устойчивость и долговечность для ваших данных, вы должны поместить свои данные за пределы экземпляров на внешнее сетевое хранилище.
В результате, разделяя эти два компонента, если экземпляр сервера выходит из строя или если все экземпляры выходят из строя, у вас все равно есть диск и все данные на нем остаются неприкосновенными. Вы просто запускаете другие экземпляры и забираете данные с EBS, и все. Это делает вашу инфраструктуру намного проще в управлении, потому что каждый сервер равнозначен; у вас нет никаких специальных серверов с какими-то особыми данными или файлами на них. Поэтому вам не важно, если вы потеряете всю свою инфраструктуру, потому что вы можете просто создать новую и извлечь данные из отдельного хранилища, и вы снова готовы к работе.
Вернемся к примеру с Redis: служба Redis будет работать на серверах и использовать оперативную память сервера для хранения данных, в то время как файлы журналов только для добавления и снимки будут сохраняться на диске за пределами этих серверов, что делает ваши данные более надежными.
Оптимизация стоимости с Redis on Flash
Теперь мы знаем, что вы можете сохранять данные с помощью Redis для обеспечения устойчивости и восстановления при использовании ОЗУ или памяти для отличной производительности и скорости. Так что вопрос, который у вас может возникнуть здесь: Хранение данных в памяти дорого? Потому что вам понадобится больше серверов по сравнению с базой данных, которая хранит данные на диске просто потому, что память ограничена по размеру. Существует компромисс между стоимостью и производительностью.
Ну, у Redis есть способ оптимизировать это, используя службу под названием Redis on Flash, которая является частью Redis Enterprise.
Как работает Redis on Flash
Это довольно простая концепция, на самом деле: Redis on Flash расширяет ОЗУ до флеш-накопителя или SSD, где часто используемые значения хранятся в ОЗУ, а редко используемые — на SSD. Таким образом, для Redis это просто больше ОЗУ на сервере. Это означает, что Redis может использовать больше базовой инфраструктуры или ресурсов сервера, используя как ОЗУ, так и накопитель SSD для хранения данных, увеличивая объем хранения на каждом сервере и таким образом экономя ваши затраты на инфраструктуру.
Масштабирование Redis: Репликация и шардинг
Мы говорили о хранении данных для базы данных Redis и о том, как все это работает, включая лучшие практики. Теперь еще одна очень интересная тема — как мы масштабируем базу данных Redis?
Репликация и высокая доступность
Допустим, мой один экземпляр Redis исчерпал память, так что данные стали слишком большими для хранения в памяти, или Redis стал узким местом и не может обрабатывать больше запросов. В таком случае, как я увеличу емкость и объем памяти моей базы данных Redis?
У нас есть несколько вариантов для этого. Во-первых, Redis поддерживает кластеризацию, что означает, что у вас может быть основной или главный экземпляр Redis, который можно использовать для чтения и записи данных, и у вас может быть несколько реплик этого основного экземпляра для чтения данных. Таким образом, вы можете масштабировать Redis для обработки большего количества запросов и, кроме того, увеличить отказоустойчивость вашей базы данных. Если основной экземпляр выходит из строя, одна из реплик может его заменить, и ваша база данных Redis в основном будет продолжать функционировать без проблем.
Эти реплики будут хранить копии данных основного экземпляра. Таким образом, чем больше у вас реплик, тем больше памяти вам понадобится. И одного сервера может быть недостаточно для всех ваших реплик. Кроме того, если все реплики находятся на одном сервере и этот сервер выходит из строя, ваша вся база данных Redis исчезнет, и у вас будет простой. Вместо этого вам нужно распределить эти реплики среди нескольких узлов или серверов. Например, ваш основной экземпляр будет на одном узле, а две реплики на других двух узлах.
Шардинг для больших наборов данных
Что ж, это кажется достаточно хорошим, но что, если ваш набор данных станет слишком большим, чтобы поместиться в памяти на одном сервере? Кроме того, мы увеличили чтения в базе данных, поэтому все запросы в основном просто запрашивают данные, но наш основной экземпляр все еще один и все еще должен обрабатывать все записи. Так в чем здесь решение?

Для этого мы используем концепцию шардинга, которая является общим понятием в базах данных и которую также поддерживает Redis. Шардинг в основном означает, что вы берете свой полный набор данных и разбиваете его на более мелкие куски или поднаборы данных, где каждый шард отвечает за свой собственный поднабор данных.
Это означает, что вместо того, чтобы иметь один главный экземпляр, обрабатывающий все записи в полном наборе данных; вы можете разделить его на, скажем, четыре шарда, каждый из которых отвечает за чтение и запись поднабора данных. Каждый шард также нуждается в меньшем объеме памяти, потому что у него просто четверть данных. Это означает, что вы можете распределить и запускать шарды на более маленьких узлах и в основном масштабировать ваш кластер горизонтально. И, конечно, по мере роста вашего набора данных и по мере необходимости большего количества ресурсов, вы можете перешардировать свою базу данных Redis, что в основном означает, что вы просто разбиваете свои данные на еще более мелкие куски и создаете больше шардов.

Итак, наличие нескольких узлов, на которых запускаются несколько реплик Redis, все они шардированы, предоставляет вам очень производительную, высокодоступную базу данных Redis, способную обрабатывать гораздо больше запросов без создания узких мест.
Сейчас мне следует отметить, что такая настройка отлична, но вам придется управлять ею самостоятельно, масштабировать, добавлять узлы, выполнять шардирование и затем решардирование и т. д. Для некоторых команд, более ориентированных на разработку приложений и более логику бизнеса, чем на работу и поддержку служб обработки данных, это может быть нежелательным трудом. Поэтому, в качестве более простой альтернативы, в Redis Enterprise вы получаете такую настройку автоматически, потому что масштабирование, шардирование и т. д. управляются за вас.
Глобальное реплицирование с Redis: активное развертывание.
Давайте рассмотрим еще один интересный сценарий для приложений, которым требуется еще более высокая доступность и производительность в различных географических местоположениях. Допустим, у нас есть реплицированный, разделенный на шарды кластер базы данных Redis в одном регионе, в дата-центре Лондона, Европа. Но у нас есть два следующих случая использования:
- Наши пользователи географически распределены, поэтому они обращаются к приложению со всех уголков мира. Мы хотим распределить наше приложение и службы данных по всему миру, близко к пользователям, чтобы обеспечить нашим пользователям лучшую производительность.
- Если весь дата-центр в Лондоне, Европа, например, выходит из строя, мы хотим немедленно переключиться на другой дата-центр, чтобы служба Redis оставалась доступной. Другими словами, мы хотим иметь реплики всего кластера Redis в дата-центрах в различных географических местоположениях или регионах.
Несколько кластеров Redis по регионам
Это означает, что одни и те же данные должны быть реплицированы во множество кластеров, распределенных по различным регионам, причем каждый кластер должен быть полностью готов принимать чтение и запись. В этом случае у вас будет несколько кластеров Redis, которые будут действовать как локальные экземпляры Redis в каждом регионе, и данные будут синхронизироваться между этими географически распределенными кластерами. Это функция, доступная в Redis Enterprise и называется активное-активное развертывание, потому что у вас есть несколько активных баз данных в разных местоположениях.

С такой настройкой у пользователей будет низкая задержка. И даже если база данных Redis в одном регионе полностью отключится, другие регионы не пострадают. Если соединение или синхронизация между регионами на короткое время нарушается из-за проблем сети, например, кластеры Redis в этих регионах могут обновлять данные независимо, и как только соединение восстановится, они смогут синхронизировать эти изменения снова.
Разрешение конфликтов с CRDT
Теперь, конечно, когда вы это слышите, первый вопрос, который может возникнуть в вашем уме, это: Как Redis разрешает изменения в нескольких регионах в один и тот же набор данных? Итак, если одни и те же данные изменяются в нескольких регионах, как Redis гарантирует, что изменения данных в любом регионе не потеряны, и данные правильно синхронизированы, и как он обеспечивает согласованность данных?
В частности, Redis Enterprise использует концепцию, называемую CRDTs, что означает конфликтосвободные реплицируемые типы данных, и эта концепция используется для автоматического разрешения любых конфликтов на уровне базы данных и без потери данных. Таким образом, Redis сам имеет механизм слияния изменений, внесенных в один и тот же набор данных из разных источников таким образом, что никакие изменения данных не потеряны, и любые конфликты правильно разрешены. И поскольку, как вы узнали, Redis поддерживает несколько типов данных, каждый тип данных использует собственные правила разрешения конфликтов данных, которые наиболее оптимальны для этого конкретного типа данных.

Простыми словами, вместо того чтобы просто переопределять изменения одного источника и отбрасывать все остальные, все параллельные изменения сохраняются и интеллектуально разрешаются. Опять же, это автоматически выполняется для вас с помощью этой функции активного геореплицирования, так что вам не нужно беспокоиться об этом.
Запуск Redis в Kubernetes
И последняя тема, которую я хочу затронуть с Redis, это запуск Redis в Kubernetes. Как я уже сказал, Redis отлично подходит для сложных микросервисов, которые нуждаются в поддержке нескольких типов данных и легком масштабировании базы данных без беспокойства о согласованности данных. И мы также знаем, что новым стандартом для запуска микросервисов является платформа Kubernetes. Таким образом, запуск Redis в Kubernetes является очень интересным и распространенным случаем использования. Итак, как это работает?

Открытый исходный код Redis на Kubernetes
С открытым исходным кодом Redis вы можете развернуть реплицируемый Redis как Helm-чарт или файлы манифеста Kubernetes и, в основном, используя правила репликации и масштабирования, о которых мы уже говорили, настроить и запустить высокодоступную базу данных Redis. Единственное отличие заключается в том, что хосты, на которых будет работать Redis, будут подами Kubernetes, а не, например, экземплярами EC2 или любыми другими физическими или виртуальными серверами. Но те же концепции шардирования, репликации и масштабирования применяются здесь также, когда вы хотите запустить кластер Redis в Kubernetes, и в основном вам придется самим управлять этой настройкой.
Redis Enterprise Operator
Однако, как я упоминал, многие команды не хотят затрачивать усилия на поддержку этих сторонних сервисов, потому что они предпочли бы вложить свое время и ресурсы в разработку приложений или другие задачи. Поэтому наличие более простой альтернативы здесь также важно. У Redis Enterprise есть управляемый кластер Redis, который вы можете развернуть как оператор Kubernetes.

Если вы не знаете, что такое операторы, оператор в Kubernetes, по сути, является концепцией, в рамках которой вы можете объединить все ресурсы, необходимые для работы определенного приложения или сервиса, чтобы вам не приходилось управлять им самостоятельно. Вместо того чтобы человек управлял базой данных, у вас по сути есть вся эта логика в автоматизированной форме для управления базой данных за вас. У многих баз данных есть операторы для Kubernetes, и у каждого такого оператора, конечно, есть своя логика на основе того, кто их написал и как их написали.
Оператор Redis Enterprise на Kubernetes специально автоматизирует развертывание и конфигурирование всей базы данных Redis в вашем кластере Kubernetes. Он также заботится о масштабировании, создании резервных копий и восстановлении кластера Redis при необходимости и т. д. Таким образом, он берет на себя полную операцию кластера Redis внутри кластера Kubernetes.
Заключение
Надеюсь, вы много узнали из этого блога и что я смог ответить на многие из ваших вопросов. Если вы хотите узнать больше о подобных технологиях и концепциях, то убедитесь в том, что следите за мной, потому что я регулярно пишу блоги о искусственном интеллекте, DevOps и облачных технологиях.
Также, оставьте комментарий ниже, если у вас есть вопросы относительно Redis или каких-либо новых предложений по темам. И с этим спасибо за прочтение, и до новых встреч в следующем блоге.
Давайте подключимся в LinkedIn!
Source:
https://dzone.com/articles/redis-as-a-primary-database-for-complex-applications