













Tout d’abord, nous verrons ce qu’est Redis et son utilisation, ainsi que pourquoi il convient aux applications modernes de microservices complexes. Nous parlerons de la manière dont Redis prend en charge le stockage de plusieurs formats de données à des fins différentes grâce à ses modules. Ensuite, nous verrons comment Redis, en tant que base de données en mémoire, peut persister les données et récupérer en cas de perte de données. Nous parlerons également de la manière dont Redis optimise les coûts de stockage de la mémoire en utilisant Redis on Flash.
Ensuite, nous verrons des cas d’utilisation très intéressants de mise à l’échelle de Redis et de sa réplication dans plusieurs régions géographiques. Enfin, étant donné que l’une des plateformes les plus populaires pour exécuter des microservices est Kubernetes, et que l’exécution d’applications avec état dans Kubernetes est un peu complexe, nous verrons comment vous pouvez facilement exécuter Redis sur Kubernetes.
Qu’est-ce que Redis?
Redis, qui signifie en réalité Serveur de Dictionnaire à Distance, est une base de données en mémoire. Beaucoup de gens l’ont utilisé comme cache par-dessus d’autres bases de données pour améliorer les performances de l’application. Cependant, ce que beaucoup de gens ne savent pas, c’est que Redis est une base de données primaire complète qui peut être utilisée pour stocker et persister plusieurs formats de données pour des applications complexes.
Exemple d’Application de Réseau Social Compliqué
Examinons une configuration courante pour une application microservices. Disons que nous avons une application de médias sociaux complexe avec des millions d’utilisateurs. Et disons que notre application microservices utilise une base de données relationnelle comme MySQL pour stocker les données. De plus, parce que nous collectons des tonnes de données quotidiennement, nous avons une base de données Elasticsearch pour un filtrage et une recherche rapides des données.
Maintenant, les utilisateurs sont tous connectés les uns aux autres, donc nous avons besoin d’une base de données graphique pour représenter ces connexions. De plus, notre application contient beaucoup de contenu multimédia que les utilisateurs partagent entre eux chaque jour, et pour cela, nous avons une base de données documentaire. Enfin, pour de meilleures performances de l’application, nous avons un service de mise en cache qui met en cache les données provenant d’autres bases de données et les rend accessibles plus rapidement.
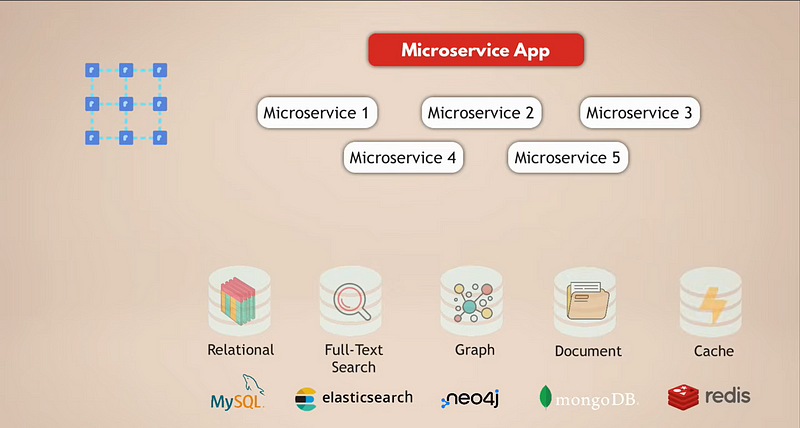
Il est maintenant évident que c’est une configuration assez complexe. Voyons quels sont les défis de cette configuration :
1. Déploiement et Maintenance
Tous ces services de données doivent être déployés, exécutés et maintenus. Cela signifie que votre équipe doit avoir une certaine connaissance de la façon de faire fonctionner tous ces services de données.
2. Échelle et Exigences en Infrastructure
Pour une haute disponibilité et de meilleures performances, vous voudriez mettre à l’échelle vos services. Chacun de ces services de données évolue différemment et a des exigences en infrastructure différentes, ce qui pourrait constituer un défi supplémentaire. Donc, dans l’ensemble, utiliser plusieurs services de données pour votre application augmente l’effort de maintenance de l’ensemble de votre configuration d’application.
3. Coûts Cloud
Bien sûr, en tant qu’alternative plus simple à l’exécution et à la gestion des services vous-même, vous pouvez utiliser les services de données gérés des fournisseurs de cloud. Mais cela pourrait être très coûteux car, sur les plateformes cloud, vous payez chaque service de données géré séparément.
4. Complexité de développement
5. Latence plus élevée
Pourquoi Redis simplifie cette complexité
Par rapport à une base de données multimodale comme Redis, vous résolvez la plupart de ces défis :
- Service de données unique. Vous exécutez et maintenez un seul service de données. Ainsi, votre application doit également communiquer avec un seul magasin de données, ce qui signifie une seule interface programmatique pour ce service de données.
- Latence réduite. La latence sera réduite en accédant à un seul point de données et en éliminant plusieurs sauts internes du réseau.
- Types de données multiples en un. Avoir une base de données comme Redis qui vous permet de stocker différents types de données (c’est-à-dire plusieurs types de bases de données en une) ainsi que de servir de cache résout de tels défis.
Comment Redis prend en charge plusieurs formats de données
Alors, voyons comment Redis fonctionne réellement. Tout d’abord, comment Redis prend-il en charge plusieurs formats de données dans une seule base de données ?
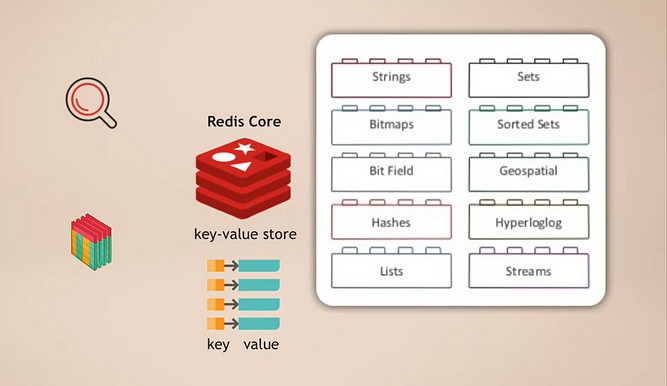
Redis Core et Modules
Le fonctionnement est le suivant : vous avez Redis core, qui est un magasin de valeurs-clés qui prend déjà en charge le stockage de plusieurs types de données. Ensuite, vous pouvez étendre ce cœur avec ce qu’on appelle des modules pour différents types de données, dont votre application a besoin pour différents usages. Par exemple :
- RedisSearch pour la fonctionnalité de recherche (comme Elasticsearch)
- RedisGraph pour le stockage de données graphiques
Une grande chose à propos de cela est que c’est modulaire. Ces différents types de fonctionnalités de base de données ne sont pas étroitement intégrés dans une seule base de données comme dans de nombreuses autres bases de données multimodales, mais plutôt, vous pouvez choisir exactement quelle fonctionnalité de service de données vous avez besoin pour votre application et ensuite ajouter ce module.
Mise en cache intégrée
Et, bien sûr, lorsque vous utilisez Redis comme base de données principale, vous n’avez pas besoin d’un cache supplémentaire car vous l’avez automatiquement prêt à l’emploi avec Redis. Cela signifie, encore une fois, moins de complexité dans votre application car vous n’avez pas besoin d’implémenter la logique pour gérer, peupler et invalider le cache.
Haute performance et tests plus rapides
Enfin, en tant que base de données en mémoire, Redis est super rapide et performant, ce qui, bien sûr, rend l’application elle-même plus rapide. De plus, cela rend également l’exécution des tests d’application beaucoup plus rapide, car Redis n’a pas besoin d’un schéma comme les autres bases de données. Ainsi, il n’a pas besoin de temps pour initialiser la base de données, construire le schéma, etc., avant d’exécuter les tests. Vous pouvez commencer avec une base de données Redis vide à chaque fois et générer des données pour les tests selon vos besoins. Des tests rapides peuvent vraiment augmenter votre productivité en développement.
Persistance des données dans Redis
Nous avons compris comment fonctionne Redis et tous ses avantages. Mais à ce stade, vous vous demandez peut-être : Comment une base de données en mémoire peut-elle persister les données? Car si le processus Redis ou le serveur sur lequel Redis s’exécute tombe en panne, toutes les données en mémoire sont perdues, n’est-ce pas ? Et si je perds les données, comment puis-je les récupérer ? En gros, comment puis-je être sûr que mes données sont en sécurité ?
La manière la plus simple d’avoir des sauvegardes de données est de répliquer Redis. Ainsi, si l’instance maître de Redis tombe en panne, les répliques continueront de fonctionner et auront toutes les données. Si vous disposez d’un Redis répliqué, les répliques auront les données. Mais bien sûr, si toutes les instances Redis tombent en panne, vous perdrez les données car il ne restera aucune réplique.
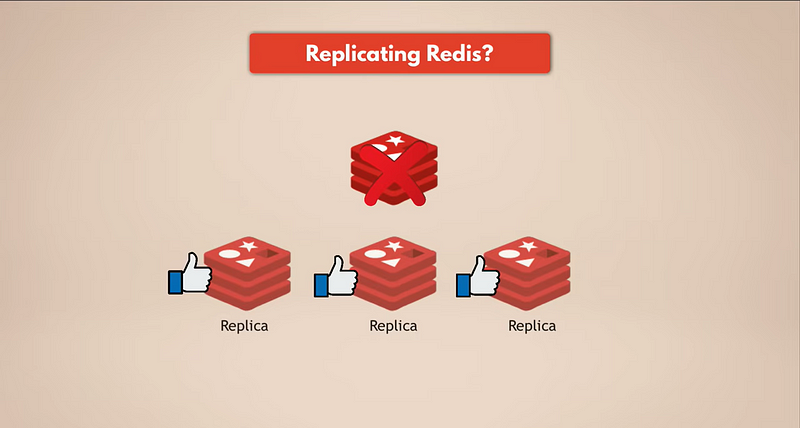
Nous avons besoin d’une vraie persistance.
Instantané (RDB)
Redis dispose de plusieurs mécanismes pour persister les données et les protéger. Le premier est les instantanés, que vous pouvez configurer en fonction du temps, du nombre de requêtes, etc. Les instantanés de vos données seront stockés sur un disque, que vous pouvez utiliser pour récupérer vos données si la base de données Redis est perdue. Mais notez que vous perdrez les dernières minutes de données, car vous faites généralement des instantanés toutes les cinq minutes ou toutes les heures, en fonction de vos besoins.
Journal des opérations (Append Only File)
En alternative, Redis utilise quelque chose appelé AOF, qui signifie Journal des opérations (Append Only File). Dans ce cas, chaque modification est enregistrée en continu sur le disque pour la persistance. Lors du redémarrage de Redis ou après une panne, Redis rejouera les logs du fichier Append Only File pour reconstruire l’état. Ainsi, l’AOF est plus durable mais peut être plus lent que les instantanés.
Combinaison d’instantanés et d’AOF
Et bien sûr, vous pouvez également utiliser une combinaison d’AOF et d’instantanés, où le fichier à ajout uniquement persiste les données de la mémoire sur le disque en continu, plus vous avez des instantanés réguliers entre les deux pour sauvegarder l’état des données au cas où vous auriez besoin de les récupérer. Cela signifie que même si la base de données Redis elle-même ou les serveurs, l’infrastructure sous-jacente où Redis est en cours d’exécution, échouent, vous avez toujours toutes vos données en sécurité et vous pouvez facilement recréer et redémarrer une nouvelle base de données Redis avec toutes les données.
Où se trouve ce stockage persistant?
Une question très intéressante est, où se trouve ce stockage persistant? Alors où se trouve ce disque qui contient vos instantanés et les logs du fichier à ajout uniquement? Sont-ils sur les mêmes serveurs où Redis est en cours d’exécution?
Cette question nous amène en réalité à la tendance ou à la meilleure pratique de la persistance des données dans les environnements cloud, qui est qu’il est toujours préférable de séparer les serveurs qui exécutent votre application et vos services de données du stockage persistant qui stocke vos données.
Avec un exemple spécifique : Si vos applications et services fonctionnent dans le cloud sur, disons, une instance EC2 d’AWS, vous devriez utiliser EBS ou Elastic Block Storage pour persister vos données au lieu de les stocker sur le disque dur de l’instance EC2. Parce que si cette instance EC2 tombe en panne, vous n’aurez accès à aucun de son stockage, que ce soit de la RAM ou du stockage sur disque ou autre. Donc, si vous souhaitez de la persistance et de la durabilité pour vos données, vous devez mettre vos données en dehors des instances sur un stockage réseau externe.
En conséquence, en séparant ces deux éléments, si l’instance du serveur échoue ou si toutes les instances échouent, vous avez toujours le disque et toutes les données qui s’y trouvent non affectées. Vous pouvez simplement lancer d’autres instances et récupérer les données de l’EBS, et c’est tout. Cela rend votre infrastructure beaucoup plus facile à gérer car chaque serveur est équivalent ; vous n’avez pas de serveurs spéciaux avec des données ou des fichiers spéciaux. Donc, vous ne vous souciez pas de perdre toute votre infrastructure car vous pouvez simplement en recréer une nouvelle et récupérer les données d’un stockage séparé, et vous êtes de nouveau opérationnel.
Pour revenir à l’exemple de Redis, le service Redis fonctionnera sur les serveurs et utilisera la RAM des serveurs pour stocker les données, tandis que les journaux de fichiers en appending et les instantanés seront persistés sur un disque en dehors de ces serveurs, rendant vos données plus durables.
Optimisation des coûts avec Redis on Flash
Maintenant, nous savons que vous pouvez persister des données avec Redis pour la durabilité et la récupération tout en utilisant de la RAM ou du stockage mémoire pour de bonnes performances et de la vitesse. Donc, la question que vous pourriez vous poser est : Stocker des données en mémoire n’est-il pas cher ? Parce que vous auriez besoin de plus de serveurs par rapport à une base de données qui stocke des données sur disque simplement parce que la mémoire est limitée en taille. Il y a un compromis entre le coût et les performances.
Eh bien, Redis a en fait une façon d’optimiser cela en utilisant un service appelé Redis on Flash, qui fait partie de Redis Enterprise.
Comment fonctionne Redis on Flash
C’est en fait un concept assez simple : Redis on Flash étend la RAM au disque flash ou au SSD, où les valeurs fréquemment utilisées sont stockées en RAM et celles utilisées moins fréquemment sont stockées sur SSD. Ainsi, pour Redis, c’est simplement plus de RAM sur le serveur. Cela signifie que Redis peut utiliser davantage de l’infrastructure sous-jacente ou des ressources du serveur sous-jacent en utilisant à la fois la RAM et le SSD pour stocker les données, augmentant la capacité de stockage sur chaque serveur, et vous permettant ainsi d’économiser des coûts d’infrastructure.
Évolutivité de Redis : Réplication et Sharding
Nous avons parlé du stockage des données pour la base de données Redis et de son fonctionnement, y compris les meilleures pratiques. Maintenant, un autre sujet très intéressant est de savoir comment nous pouvons mettre à l’échelle une base de données Redis ?
Réplication et haute disponibilité
Disons que mon instance Redis est à court de mémoire, donc les données deviennent trop importantes pour tenir en mémoire, ou Redis devient un goulot d’étranglement et ne peut plus traiter de demandes supplémentaires. Dans un tel cas, comment augmenter la capacité et la taille de mémoire de ma base de données Redis ?
Nous avons plusieurs options à ce sujet. Tout d’abord, Redis prend en charge le clustering, ce qui signifie que vous pouvez avoir une instance Redis primaire ou maître qui peut être utilisée pour lire et écrire des données, et vous pouvez avoir plusieurs répliques de cette instance primaire pour lire les données. De cette manière, vous pouvez faire évoluer Redis pour gérer plus de requêtes et, de plus, augmenter la haute disponibilité de votre base de données. Si le maître échoue, l’une des répliques peut prendre le relais, et votre base de données Redis peut continuer à fonctionner sans aucun problème.
Ces répliques contiendront toutes des copies des données de l’instance primaire. Donc, plus vous avez de répliques, plus vous aurez besoin d’espace mémoire. Et un serveur peut ne pas avoir suffisamment de mémoire pour toutes vos répliques. De plus, si vous avez toutes les répliques sur un seul serveur et que ce serveur échoue, votre base de données Redis entière est perdue, et vous aurez un temps d’arrêt. Au lieu de cela, vous souhaitez distribuer ces répliques entre plusieurs nœuds ou serveurs. Par exemple, votre instance maître sera sur un nœud et deux répliques sur les deux autres nœuds.
Partitionnement pour des ensembles de données plus volumineux
Eh bien, cela semble suffisant, mais que se passe-t-il si votre ensemble de données devient trop volumineux pour tenir en mémoire sur un seul serveur ? De plus, nous avons mis à l’échelle les lectures dans la base de données, donc toutes les requêtes se contentent de consulter les données, mais notre instance maître est toujours seule et doit toujours gérer toutes les écritures. Alors, quelle est la solution ici ?

Pour cela, nous utilisons le concept de sharding, qui est un concept général dans les bases de données et que Redis prend également en charge. Le sharding signifie essentiellement que vous prenez votre ensemble de données complet et le divisez en morceaux plus petits ou sous-ensembles de données, où chaque shard est responsable de son propre sous-ensemble de données.
Cela signifie qu’au lieu d’avoir une instance principale qui gère toutes les écritures de l’ensemble de données complet, vous pouvez le diviser en, disons, quatre shards, chacun d’eux étant responsable des lectures et des écritures d’un sous-ensemble des données. Chaque shard nécessite également moins de capacité mémoire car il ne possède qu’un quart des données. Cela signifie que vous pouvez distribuer et exécuter des shards sur des nœuds plus petits et, essentiellement, faire évoluer votre cluster horizontalement. Et, bien sûr, à mesure que votre ensemble de données grandit et que vous avez besoin de ressources encore plus importantes, vous pouvez re-sharder votre base de données Redis, ce qui signifie simplement que vous divisez vos données en morceaux encore plus petits et créez plus de shards.

Avoir plusieurs nœuds exécutant plusieurs répliques de Redis, qui sont tous shardés, vous offre une base de données Redis très performante et hautement disponible capable de gérer beaucoup plus de requêtes sans créer de goulets d’étranglement.
Maintenant, je dois noter ici que cette configuration est géniale, mais vous devrez la gérer vous-même, faire l’évolutivité, ajouter des nœuds, faire le sharding, puis le re-sharding, etc. Pour certaines équipes qui sont plus axées sur le développement d’applications et sur la logique métier plutôt que sur l’exécution et la maintenance des services de données, cela pourrait représenter beaucoup d’efforts indésirables. Donc, comme alternative plus facile, dans Redis Enterprise, vous obtenez ce type de configuration automatiquement car l’évolutivité, le sharding, etc. sont tous gérés pour vous.
Réplicabilité Globale Avec Redis : Déploiement Actif-Actif
Considérons un autre scénario intéressant pour les applications qui nécessitent une disponibilité et des performances encore plus élevées à travers plusieurs emplacements géographiques. Disons que nous avons un cluster de base de données Redis répliqué et fragmenté dans une région, dans le centre de données de Londres, en Europe. Mais nous avons les deux cas d’utilisation suivants :
- Nos utilisateurs sont répartis géographiquement, ils accèdent donc à l’application depuis le monde entier. Nous voulons distribuer nos services d’application et de données à l’échelle mondiale, proches des utilisateurs, pour offrir de meilleures performances à nos utilisateurs.
- Si le centre de données complet de Londres, en Europe, par exemple, tombe en panne, nous voulons basculer immédiatement vers un autre centre de données afin que le service Redis reste disponible. En d’autres termes, nous voulons des répliques de l’ensemble du cluster Redis dans des centres de données situés dans plusieurs emplacements géographiques ou régions.
Plusieurs Clusters Redis à Travers les Régions
Cela signifie qu’une seule donnée doit être répliquée vers de nombreux clusters répartis dans plusieurs régions, chaque cluster étant entièrement capable d’accepter des lectures et des écritures. Dans ce cas, vous auriez plusieurs clusters Redis qui agiront comme des instances Redis locales dans chaque région, et les données seront synchronisées entre ces clusters répartis géographiquement. Il s’agit d’une fonctionnalité disponible dans Redis Enterprise et appelée déploiement actif-actif car vous avez plusieurs bases de données actives dans différents emplacements.

Avec cette configuration, nous aurons une latence plus faible pour les utilisateurs. Et même si la base de données Redis dans une région tombe en panne, les autres régions ne seront pas affectées. Si la connexion ou la synchronisation entre les régions est interrompue pendant un court laps de temps en raison d’un problème réseau, par exemple, les clusters Redis de ces régions peuvent mettre à jour les données de manière indépendante, et une fois que la connexion est rétablie, ils peuvent resynchroniser ces changements.
Résolution des conflits avec les CRDTs
Maintenant, bien sûr, lorsque vous entendez cela, la première question qui peut vous venir à l’esprit est : Comment Redis résout-il les modifications dans plusieurs régions pour le même ensemble de données ? Donc, si les mêmes données changent dans plusieurs régions, comment Redis s’assure-t-il que les modifications de données d’une région ne sont pas perdues et que les données sont correctement synchronisées, et comment assure-t-il la cohérence des données ?
Plus précisément, Redis Enterprise utilise un concept appelé CRDTs, qui signifie types de données répliqués sans conflit, et ce concept est utilisé pour résoudre automatiquement les conflits au niveau de la base de données et sans perte de données. En gros, Redis lui-même dispose d’un mécanisme pour fusionner les modifications apportées au même ensemble de données à partir de sources multiples de manière à ce que aucune des modifications de données ne soit perdue et que tout conflit soit résolu correctement. Et comme vous l’avez appris, Redis prend en charge plusieurs types de données, chaque type de données utilisant ses propres règles de résolution des conflits de données, les plus optimales pour ce type de données spécifique.

En termes simples, au lieu de simplement écraser les changements d’une source et de rejeter tous les autres, tous les changements parallèles sont conservés et résolus intelligemment. Encore une fois, cela est fait automatiquement pour vous grâce à cette fonctionnalité de réplication géographique active-active, donc vous n’avez pas à vous en soucier.
Exécution de Redis dans Kubernetes
Et le dernier sujet que je veux aborder avec Redis est l’exécution de Redis dans Kubernetes. Comme je l’ai dit, Redis est un excellent choix pour des micro-services complexes qui doivent prendre en charge plusieurs types de données et qui ont besoin d’une mise à l’échelle facile d’une base de données sans se soucier de la cohérence des données. Et nous savons aussi que le nouveau standard pour l’exécution de microservices est la plateforme Kubernetes. Donc, exécuter Redis dans Kubernetes est un cas d’utilisation très intéressant et courant. Alors, comment cela fonctionne-t-il ?

Redis Open Source sur Kubernetes
Avec Redis open-source, vous pouvez déployer Redis répliqué en tant que chart Helm ou fichiers manifeste Kubernetes et, fondamentalement, en utilisant les règles de réplication et de mise à l’échelle dont nous avons déjà parlé, configurer et exécuter une base de données Redis hautement disponible. La seule différence serait que les hôtes où Redis s’exécutera seront des pods Kubernetes au lieu, par exemple, d’instances EC2 ou de tout autre serveur physique ou virtuel. Mais les mêmes concepts de partitionnement, de réplication et de mise à l’échelle s’appliquent également ici lorsque vous souhaitez exécuter un cluster Redis dans Kubernetes, et vous devrez essentiellement gérer cette configuration vous-même.
Opérateur Redis Enterprise
Cependant, comme je l’ai mentionné, de nombreuses équipes ne souhaitent pas fournir l’effort nécessaire pour maintenir ces services tiers car elles préfèrent investir leur temps et leurs ressources dans le développement d’applications ou d’autres tâches. Ainsi, avoir une alternative plus simple est également important ici. Redis Enterprise dispose d’un cluster Redis géré, que vous pouvez déployer en tant qu’opérateur Kubernetes.

Si vous ne connaissez pas les opérateurs, un opérateur dans Kubernetes est essentiellement un concept où vous pouvez regrouper toutes les ressources nécessaires pour faire fonctionner une certaine application ou un service afin que vous n’ayez pas à le gérer vous-même. Au lieu qu’un humain gère une base de données, vous avez essentiellement toute cette logique sous une forme automatisée pour gérer une base de données pour vous. De nombreuses bases de données ont des opérateurs pour Kubernetes, et chaque opérateur a, bien sûr, sa propre logique basée sur qui les a écrits et comment ils les ont écrits.
L’opérateur Redis Enterprise sur Kubernetes automatise spécifiquement le déploiement et la configuration de l’ensemble de la base de données Redis dans votre cluster Kubernetes. Il s’occupe également de la mise à l’échelle, des sauvegardes et de la récupération du cluster Redis si nécessaire, etc. Ainsi, il prend en charge l’ensemble de l’exploitation du cluster Redis à l’intérieur du cluster Kubernetes.
Conclusion
J’espère que vous avez beaucoup appris dans ce blog et que j’ai pu répondre à nombre de vos questions. Si vous souhaitez en savoir plus sur des technologies et concepts similaires, assurez-vous de me suivre car j’écris régulièrement des blogs sur l’IA, le DevOps et les technologies cloud.
De plus, commentez ci-dessous si vous avez des questions concernant Redis ou des suggestions de nouveaux sujets. Et sur ce, merci de votre lecture, et à bientôt dans le prochain blog.
Connectons-nous sur LinkedIn!
Source:
https://dzone.com/articles/redis-as-a-primary-database-for-complex-applications