













最初に、Redisとその使用方法、および現代の複雑なマイクロサービスアプリケーションに適している理由を見ていきます。Redisがモジュールを介して異なる目的のために複数のデータ形式を格納する方法について説明します。次に、メモリ内データベースとしてのRedisがデータを永続化しデータ損失から回復する方法について見ていきます。また、RedisがRedis on Flashを使用してメモリストレージコストを最適化する方法についても説明します。
次に、Redisのスケーリングや複数の地理的地域にわたるレプリケーションなど、非常に興味深い使用事例を見ていきます。最後に、マイクロサービスを実行するための最も人気のあるプラットフォームの1つがKubernetesであり、Kubernetesでステートフルアプリケーションを実行することが少し難しいため、Kubernetes上でRedisを簡単に実行する方法について見ていきます。
Redisとは?
Redisは実際には「Remote Dictionary Server」の略であり、メモリ内データベースです。多くの人々が他のデータベースの上にキャッシュとして使用して、アプリケーションのパフォーマンスを向上させてきました。しかし、多くの人が知らないことは、Redisが複雑なアプリケーションのために複数のデータ形式を格納および永続化するために使用できる完全な主要データベースであるということです。
複雑なソーシャルメディアアプリケーションの例
マイクロサービスアプリケーションの一般的なセットアップを見てみましょう。例えば、数百万人のユーザーを持つ複雑なソーシャルメディアアプリケーションがあるとします。そして、私たちのマイクロサービスアプリケーションがデータを保存するためにMySQLのようなリレーショナルデータベースを使用しているとします。さらに、毎日大量のデータを収集しているため、データを高速でフィルタリングおよび検索するためにElasticsearchデータベースを使用しています。
さて、ユーザーはすべて互いに接続されているため、これらの接続を表すためにグラフデータベースが必要です。さらに、アプリケーションにはユーザーが日々共有する多くのメディアコンテンツがあり、そのためにドキュメントデータベースを使用しています。最後に、アプリケーションのパフォーマンス向上のために、他のデータベースからデータをキャッシュし、より迅速にアクセス可能にするキャッシュサービスがあります。
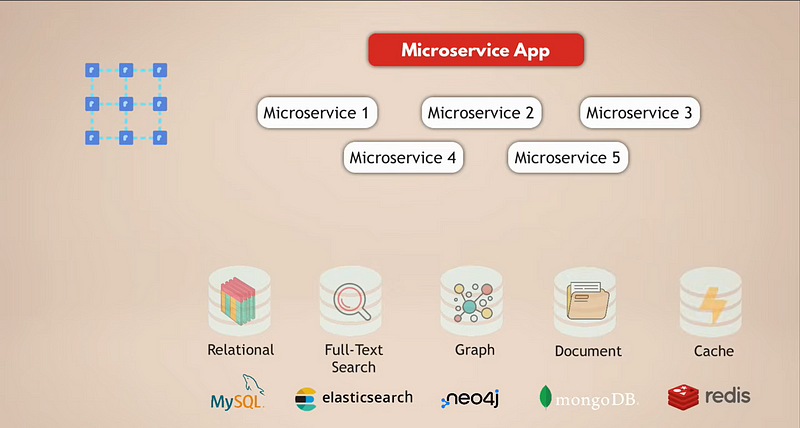
さて、これはかなり複雑なセットアップであることは明らかです。このセットアップの課題を見てみましょう:
1. デプロイメントとメンテナンス
これらのデータサービスはすべてデプロイされ、実行され、メンテナンスされる必要があります。つまり、チームはこれらのデータサービスを運用する方法についてある程度の知識を持っている必要があります。
2. スケーリングとインフラ要件
高可用性とより良いパフォーマンスのために、サービスをスケーリングしたいと思うでしょう。これらのデータサービスの各々は異なる方法でスケーリングし、異なるインフラ要件を持っており、それが追加の課題となる可能性があります。つまり、アプリケーション全体のセットアップを維持する努力が増加します。
3. クラウドコスト
もちろん、自分でランニングやサービスの管理を行うよりも簡単な代替手段として、クラウドプロバイダーから提供されるマネージドデータサービスを利用することができます。しかし、クラウドプラットフォームでは、各マネージドデータサービスごとに支払いが発生するため、非常に高額になる可能性があります。
4. 開発の複雑さ
5. 遅延の増加
Redisがこの複雑さを簡素化する理由
Redisのようなマルチモデルデータベースと比較すると、これらの課題のほとんどを解決できます:
- 単一のデータサービス。 1つのデータサービスのみを実行および維持します。そのため、アプリケーションも単一のデータストアとやり取りする必要があり、つまりそのデータサービスに対する1つのプログラムインターフェースのみが必要です。
- 遅延の軽減。単一のデータエンドポイントに移動し、いくつかの内部ネットワークホップを排除することで、遅延が軽減されます。
- 複数のデータタイプを1つに。 Redisのような1つのデータベースを持つことで、異なるタイプのデータを保存できる(つまり、1つのデータベース内に複数のデータベースを持つこともできる)さらにキャッシュとしても機能することによって、このような課題を解決できます。
Redisが複数のデータ形式をサポートする方法
では、Redisが実際にどのように機能するかを見てみましょう。まず、Redisは1つのデータベース内で複数のデータ形式をサポートしているのでしょうか?
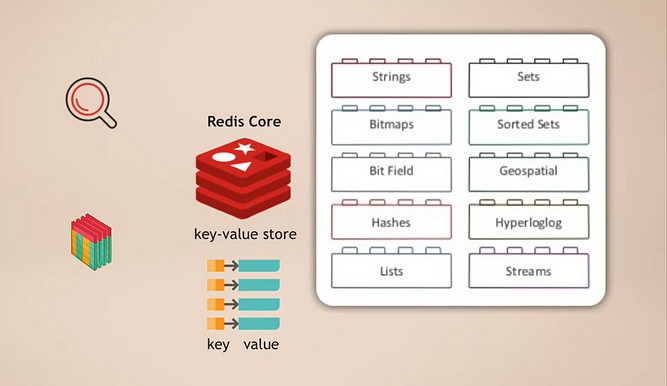
Redisコアとモジュール
動作の仕組みは、すでに複数の種類のデータの格納をサポートしているキー値ストアであるRedis coreを持っている、ということです。その後、異なるデータ型のためにアプリケーションが必要とするモジュールと呼ばれるもので、コアを拡張することができます。たとえば、
- RedisSearchは検索機能(Elasticsearchのようなもの)
- RedisGraphはグラフデータの格納
アプリケーションに必要なデータサービス機能を選択して追加できるため、この仕組みの素晴らしい点はモジュール化されていることです。
組み込みキャッシュ
そして、Redisを主要なデータベースとして使用する場合、追加のキャッシュは必要ありません なぜなら、Redisにはそれがデフォルトで自動的に備わっているからです。これはつまり、アプリケーションにおいて複雑さが減少するということで、キャッシュの管理、データの補充、および無効化のロジックを実装する必要がないためです。
高性能と高速なテスト
Redisはインメモリデータベースとして、超高速でパフォーマンスが良いため、アプリケーション自体も高速になります。さらに、他のデータベースとは異なりRedisにはスキーマが必要ないため、データベースの初期化やスキーマの構築などがテスト実行の前に必要ないため、アプリケーションテストの実行も非常に高速になります。必要に応じて空のRedisデータベースから始め、テスト用のデータを生成することができます。高速なテストは開発生産性を実際に向上させることができます。
Redisにおけるデータ永続性
Redisの動作とその利点を理解しましたが、この時点で疑問に思っているかもしれません:インメモリデータベースがデータを永続化する方法は何か?なぜなら、RedisプロセスやRedisが稼働しているサーバーが停止すると、メモリ中のすべてのデータが消えてしまうからですよね?そしてデータが失われた場合、どのように回復できるのでしょうか?つまり、自分のデータが安全であることをどのように確認できるのでしょうか?
データバックアップを持つ最も簡単な方法は、Redisをレプリケーションすることです。つまり、Redisのマスターインスタンスがダウンした場合、レプリカは引き続き稼働しており、すべてのデータを保持しています。レプリケーションされたRedisがあれば、レプリカにデータがあります。ただし、Redisインスタンスがすべてダウンした場合は、データが失われるため、残っているレプリカはありません。
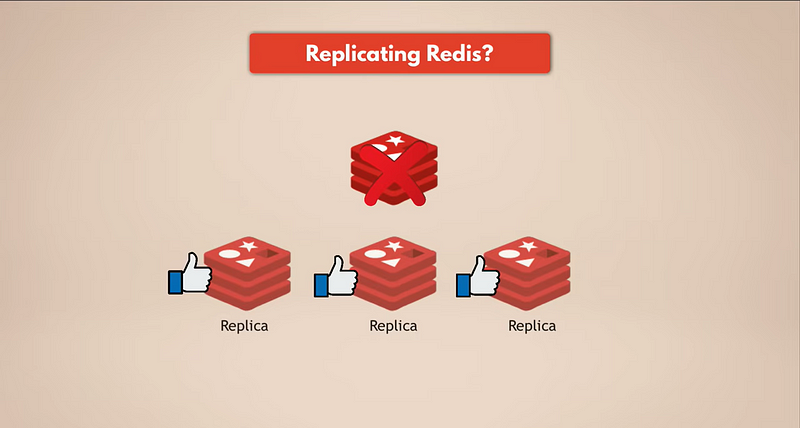
私たちは本当の永続性が必要です。
スナップショット(RDB)
Redisはデータを永続化し、安全に保つための複数のメカニズムを備えています。最初のものはスナップショットで、時間やリクエストの数に基づいて設定できます。データのスナップショットはディスクに保存され、Redisデータベース全体が失われた場合にデータを復元するために使用できます。ただし、通常、5分または1時間ごとにスナップショットを取得するため、最後の数分間のデータは失われることに注意してください。
AOF(Append Only File)
代替として、RedisはAOFというものを使用します。これはAppend Only Fileの略です。この場合、すべての変更が永続性のためにディスクに継続的に保存されます。Redisを再起動する際や停電後には、Append Only Fileのログを再生して状態を再構築します。したがって、AOFはより耐久性がありますが、スナップショットよりも遅くなる可能性があります。
スナップショットとAOFの組み合わせ
もちろん、AOFとスナップショットの両方の組み合わせを使用することもできます。この場合、Append Only Fileがメモリからディスクにデータを継続的に永続化し、その間に定期的なスナップショットを取得してデータの状態を保存します。これは、Redisデータベース自体やRedisが実行されている基盤となるインフラストラクチャがすべて失敗しても、すべてのデータが安全に保たれ、新しいRedisデータベースを簡単に再作成して再起動できることを意味します。
その永続ストレージはどこにありますか?
非常に興味深い質問は、その永続ストレージはどこにあるかということです。スナップショットやAppend Only Fileのログを保持しているディスクはどこにありますか?それらはRedisが実行されている同じサーバーにありますか?
この質問は、クラウド環境におけるデータ永続性のトレンドやベストプラクティスへと導きます。それは、アプリケーションとデータサービスを実行するサーバーを、データを保存するための永続ストレージから常に分離する方が良いということです。
具体的な例として、あなたのアプリケーションとサービスがクラウド上のAWS EC2インスタンスで動作しているとしましょう。その場合、データをEC2インスタンスのハードドライブに保存するのではなく、EBS(Elastic Block Storage)を使用してデータを永続化するべきです。なぜなら、そのEC2インスタンスがダウンした場合、RAMやディスクストレージなど、どのストレージにもアクセスできなくなるからです。したがって、データの永続性と耐久性を求めるのであれば、インスタンスの外部にデータを外部ネットワークストレージに配置する必要があります。
その結果、これら二つを分離することで、サーバーインスタンスが失敗したり、すべてのインスタンスが失敗したりしても、ディスクとその上のすべてのデータは影響を受けません。別のインスタンスを立ち上げて、EBSからデータを取得すれば、それで済みます。これにより、各サーバーが同等であり、特別なデータやファイルを持つ特別なサーバーがないため、インフラストラクチャの管理が非常に容易になります。したがって、全インフラストラクチャを失っても心配する必要はなく、新しいものを再作成し、別のストレージからデータを取得すれば再び動き出せるのです。
Redisの例に戻ると、Redisサービスはサーバー上で実行され、データを保存するためにサーバーのRAMを使用し、追加専用ファイルログとスナップショットはそれらのサーバーの外部のディスクに永続化されるため、データがより耐久性を持つようになります。
Redis on Flashでのコスト最適化
今では、Redisを使用してデータを永続化し、RAMまたはメモリストレージを使用して優れたパフォーマンスと速度を実現することができるということがわかっています。ですので、ここでお持ちの疑問は次のようなものかもしれません:メモリにデータを保存するのは高額ではないですか?なぜなら、メモリは容量に制限があるため、データをディスクに保存するデータベースと比較して、より多くのサーバーが必要になるからです。コストとパフォーマンスの間にはトレードオフがあります。
実際、Redisにはこれを最適化する方法があり、それがRedis on Flashと呼ばれるサービスであり、Redis Enterpriseの一部です。
Redis on Flashの動作
実際、これは非常にシンプルなコンセプトです:Redis on FlashはRAMをフラッシュドライブやSSDに拡張し、頻繁に使用される値はRAMに、あまり使用されない値はSSDに保存します。つまり、Redisにとっては、サーバー上のRAMが増えたことになります。これにより、Redisはデータを格納するためにRAMとSSDドライブの両方を使用して、データを格納するためのストレージ容量を増やし、それによってインフラストラクチャコストを削減できるようになります。
Redisのスケーリング:レプリケーションとシャーディング
Redisデータベースのデータストレージやそれがすべてどのように機能するかについて話しました。次に、非常に興味深いトピックとして、Redisデータベースをどのようにスケーリングするかについて考えてみましょう。
レプリケーションと高可用性
1つのRedisインスタンスがメモリを使い果たしてしまい、データをメモリに保持するには大きすぎるか、Redisがボトルネックとなってさらなるリクエストを処理できなくなった場合、どのようにしてRedisデータベースの容量とメモリサイズを増やすことができるでしょうか?
それにはいくつかのオプションがあります。まず第一に、Redisはクラスタリングをサポートしているため、プライマリまたはマスターRedisインスタンスを持つことができ、これを使用してデータの読み書きができます。また、そのプライマリインスタンスの複数のレプリカを持つことができ、これによりRedisをスケーリングしてより多くのリクエストを処理し、データベースの高可用性を向上させることができます。マスターが障害を起こした場合、レプリカの1つが引き継ぎを行い、Redisデータベースは基本的に問題なく機能を継続させることができます。
これらのレプリカはすべてプライマリインスタンスのデータのコピーを保持します。したがって、レプリカの数が増えれば増えるほど、必要なメモリスペースも増えます。そして1台のサーバーにすべてのレプリカが収まり切らない可能性があります。さらに、すべてのレプリカを1つのサーバーに配置し、そのサーバーが障害を起こした場合、Redisデータベース全体が消失し、ダウンタイムが発生します。その代わりに、これらのレプリカを複数のノードやサーバーに分散させたいと考えています。たとえば、マスターインスタンスは1つのノードにあり、他の2つのノードに2つのレプリカが配置されます。
大規模データセットのためのシャーディング
これは十分そうですが、1台のサーバーのメモリに収まりきれないほどデータセットが大きくなった場合はどうでしょうか?また、データベースの読み取りをスケールアップしているため、すべてのリクエストは基本的にデータをクエリしていますが、マスターインスタンスはまだ単独であり、すべての書き込みを処理する必要があります。では、ここでの解決策は何でしょうか?

そのため、データベース全般の概念であるシャーディングの概念を使用しています。Redisもサポートしています。シャーディングとは、完全なデータセットを小さなチャンクやデータのサブセットに分割し、各シャードが独自のデータサブセットに対して責任を持つということを基本的に意味します。
つまり、完全なデータセットへのすべての書き込みを処理する1つのマスターインスタンスを持つ代わりに、4つのシャードに分割し、各シャードがデータのサブセットへの読み取りと書き込みを担当します。各シャードもデータの四分の一しか持っていないため、メモリ容量も少なくて済みます。これにより、より小さなノード上でシャードを分散して実行し、クラスタを水平にスケーリングすることができます。そして、データセットが成長し、さらに多くのリソースが必要になると、Redisデータベースを再シャーディングすることができます。つまり、データをさらに小さなチャンクに分割し、より多くのシャードを作成するだけです。

複数のRedisのレプリカを実行する複数のノードを持ち、それらがすべてシャーディングされていると、ボトルネックを作成することなく、多くのリクエストを処理できる非常に高性能で高可用性のRedisデータベースが得られます。
ここで注記しておくと、この設定は素晴らしいですが、自分で管理する必要があり、スケーリング、ノードの追加、シャーディング、そしてリシャーディングなどを行う必要があります。アプリケーション開発やビジネスロジックに重点を置くチームにとって、望ましくない労力となるかもしれません。そのため、Redis Enterpriseでは、この種の設定が自動的に行われるため、スケーリング、シャーディングなどがすべて管理されます。
Redisにおけるグローバルレプリケーション:アクティブアクティブデプロイメント
複数の地理的な場所で、さらに高い可用性とパフォーマンスを必要とするアプリケーションの興味深いシナリオを考えてみましょう。例えば、イギリス、ロンドンのデータセンターにこのレプリケートされたシャーディングされたRedisデータベースクラスターがあるとしましょう。しかし、以下の2つのユースケースがあります。
- 私たちのユーザーは地理的に分散しているため、世界中からアプリケーションにアクセスしています。ユーザーの近くでアプリケーションとデータサービスをグローバルに分散させ、ユーザーにより良いパフォーマンスを提供したいと考えています。
- 例えば、イギリス、ロンドンのデータセンター全体がダウンした場合、Redisサービスを維持するために別のデータセンターへの即時切り替えを希望しています。言い換えれば、私たちは複数の地理的な場所や地域にあるデータセンターに全体のRedisクラスターのレプリカを持ちたいのです。
地域を跨ぐ複数のRedisクラスター
これは、単一のデータが複数の地域に分散した多くのクラスターにレプリケートされ、各クラスターが読み取りと書き込みを完全に受け入れることができることを意味します。その場合、各地域でローカルRedisインスタンスとして機能する複数のRedisクラスターがあり、データはこれらの地理的に分散したクラスター間で同期されます。これはRedis Enterpriseで利用可能な機能であり、異なる場所に複数のアクティブなデータベースがあるため、アクティブ-アクティブデプロイメントと呼ばれています。

このセットアップにより、ユーザーにとっては低遅延を実現します。また、ある地域のRedisデータベースが完全にダウンしても、他の地域には影響がありません。例えば、ネットワークの問題で地域間の接続や同期が一時的に切断された場合でも、これらの地域のRedisクラスタは独立してデータを更新でき、接続が再確立されると、それらの変更を再度同期できます。
競合解決とCRDT
さて、もちろん、これを聞いて最初に思い浮かぶ質問は次のようなものです:Redisは複数の地域で同じデータセットの変更をどのように解決するのか?つまり、同じデータが複数の地域で変更された場合、Redisはどのようにして各地域のデータ変更が失われず、データが正しく同期され、データの整合性を確保しているのでしょうか?
具体的には、Redis EnterpriseはCRDTという概念を使用しています。これは 競合のない複製データ型の略であり、この概念はデータベースレベルで自動的に競合を解決し、データ損失なしに使用されます。つまり、基本的にRedis自体には、複数のソースから同じデータセットに対して行われた変更をマージする仕組みがあり、データ変更が失われず、競合が適切に解決されるようになっています。そして、学んだように、Redisは複数のデータ型をサポートしているため、各データ型にはその特定のデータ型に最適なデータ競合解決ルールが適用されます。

単純に言えば、1つのソースの変更を上書きして他のすべてを破棄するのではなく、すべての並行する変更が保持され、知的に解決されます。このアクティブアクティブ地域レプリケーション機能により、これが自動的に行われるため、そのことを心配する必要はありません。
KubernetesでRedisを実行する
そして、Redisに関して取り上げたい最後のトピックはKubernetesでRedisを実行することです。私が言ったように、Redisは複数のデータ型をサポートし、データの整合性を気にすることなくデータベースを簡単にスケーリングする必要がある複雑なマイクロサービスに適しています。また、マイクロサービスを実行する新しい標準はKubernetesプラットフォームであることも知っています。そのため、KubernetesでRedisを実行することは非常に興味深く一般的なユースケースです。では、それはどのように機能するのでしょうか?

Kubernetes上のオープンソースRedis
オープンソースのRedisを使用すると、HelmチャートまたはKubernetesマニフェストファイルとして複製されたRedisを展開し、基本的に、すでに話したレプリケーションとスケーリングのルールを使用して、高い可用性のRedisデータベースを設定および実行できます。唯一の違いは、Redisが実行されるホストが、例えばEC2インスタンスや他の物理的または仮想サーバーの代わりにKubernetesポッドになることです。ただし、RedisクラスターをKubernetesで実行する場合も、同じシャーディング、レプリケーション、スケーリングの概念が適用され、基本的にはそのセットアップを自分で管理する必要があります。
Redis Enterprise Operator
しかし、私が述べたように、多くのチームは、アプリケーション開発や他のタスクに時間とリソースを投資したいので、これらのサードパーティサービスを維持するための努力をしたくありません。したがって、より簡単な代替手段がここでも重要です。Redis Enterpriseには、Kubernetesオペレーターとしてデプロイできる管理されたRedisクラスターがあります。

オペレーターについて知らない場合、Kubernetesにおけるオペレーターは、特定のアプリケーションやサービスを運用するために必要なすべてのリソースをまとめる概念です。これにより、自分で管理したり、運用したりする必要がなくなります。人間がデータベースを運用するのではなく、データベースを運用するためのすべてのロジックが自動化された形で存在します。多くのデータベースにはKubernetes用のオペレーターがあり、それぞれのオペレーターは、書いた人やその書き方に基づいて独自のロジックを持っています。
KubernetesオペレーターのRedis Enterpriseは、Kubernetesクラスター内のRedisデータベース全体のデプロイと構成を自動化します。また、スケーリング、バックアップの実施、必要に応じてRedisクラスターの回復なども担当します。したがって、Kubernetesクラスター内のRedisクラスターの完全な運用を引き受けます。
結論
このブログで多くのことを学び、多くの質問に答えることができたことを願っています。AI、DevOps、クラウド技術に関する同様の技術や概念をもっと学びたい場合は、私をフォローしてください。私は定期的にブログを書いています。
また、Redisに関する質問や新しいトピックの提案があれば、下にコメントしてください。それでは、読んでいただきありがとうございました。次のブログでお会いしましょう。
Let’s connect on LinkedIn!
Source:
https://dzone.com/articles/redis-as-a-primary-database-for-complex-applications